标签:text key 显示 os.path save result 不包含 print lib
最终目的:能通过输入关键字进行搜索,爬取相应的图片存储到本地或者数据库
首先打开百度图片的网站,搜索任意一个关键字,比如说:水果,得到如下的界面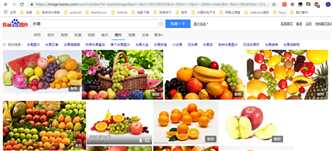
分析:
1、百度图片搜索结果的页面源代码不包含需要提取的图片信息,需要借助Chrome调试工具(F12调出)分析请求的URL地址
2、图片显示页面没有翻页按钮,但是页面一直往下拉会生成新的图片,这是典型的AJAX数据
F12打开调试工具,刷新网页,点击选中Network选项卡中的XHR标签(这个标签加载的就是AJAX请求),此时只能看到一条loginfo开头的信息,字面上可以理解为和登录相关的内容,先不管它
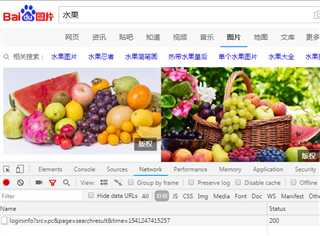
把网页往下拖动,可以看到有新的信息加载出来
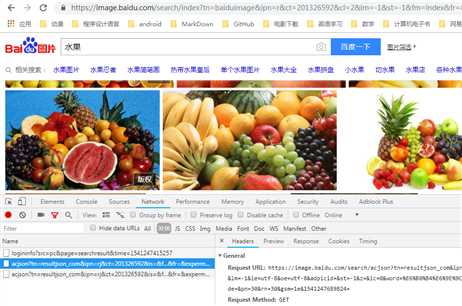
这些加载出来的都是以acjson开头的信息,点击之后查看Headers、Preview、Response标签,可以看出来这里面包含了我们需要的图片信息
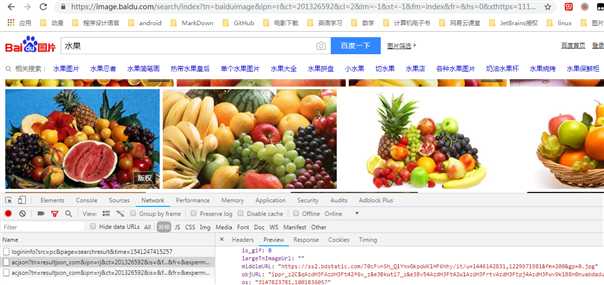
对比一下这几条信息的headers中Request URL可以得出参数中有三个值在变化,一个psm,一个pn,还有一个14。。。开头的数字,经过测试可以发现,实际上pn的值是最关键的,它影响翻页,其他两个可有可无。(对比url建议用一些在线代码对比工具,要不然眼睛要瞎)
下面开始写代码:
一、请求网页,获取html文本(百度图片有防盗链,加个Referer)
# 获取动态页面返回的文本
def get_page_html(page_url):
headers = {
‘Referer‘: ‘https://image.baidu.com/search/index?tn=baiduimage‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36‘
}
try:
r = requests.get(page_url, headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
return r.text
else:
print(‘请求失败‘)
except Exception as e:
print(e)
二、使用正则表达式提取真实图片的地址(选的是小图,大图在objURL里,需要经过简单的解密)
# 从文本中提取出真实图片地址
def parse_result(text):
url_real = re.findall(‘"thumbURL":"(.*?)",‘, text)
return url_real
三、请求图片的url,返回content(图片信息需要以二进制写入)
# 获取图片的content
def get_image_content(url_real):
headers = {
‘Referer‘: url_real,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36‘
}
try:
r = requests.get(url_real, headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
return r.content
else:
print(‘请求失败‘)
except Exception as e:
print(e)
四、保存图片(因为是测试,我写的是绝对地址,正常需要用相对地址)
# 将图片的content写入文件
def save_pic(url_real, content):
root = ‘D://baiduimage//‘
path = root + url_real.split(‘/‘)[-1]
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
with open(path, ‘wb‘) as f:
f.write(content)
print(‘图片{}保存成功,地址在{}‘.format(url_real, path))
else:
pass
五、定义一个主函数(百度图片每次最多请求30张,即使改了其他请求参数也最多60张)
# 主函数
def main():
keyword = input(‘请输入你要查询的关键字: ‘)
‘‘‘
按照标准, URL 只允许一部分 ASCII 字符(数字字母和部分符号),其他的字符(如汉字)是不符合 URL 标准的。
所以 URL 中使用其他字符就需要进行 URL 编码。python3中使用urllib.parse.quote进行编码
‘‘‘
keyword_quote = urllib.parse.quote(keyword)
depth = int(input("请输入要爬取的页数(每页30张图): "))
for i in range(depth):
url = ‘https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord+=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&word={}&z=&ic=0&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&step_word={}&pn={}&rn=30&gsm=1e&1541136876386=‘.format(
keyword_quote, keyword_quote, i * 30)
html = get_page_html(url)
real_urls = parse_result(html)
for real_url in real_urls:
content = get_image_content(real_url)
save_pic(real_url, content)
六、最后写一个函数入口
# 函数入口
if __name__ == ‘__main__‘:
main()
当然,实现整个过程最好是先把整体的框架写好,那样思路最清晰。
关于百度图片的爬取就到这里,源代码地址:传送门
标签:text key 显示 os.path save result 不包含 print lib
原文地址:https://www.cnblogs.com/sjfeng1987/p/9902077.html