标签:pac 接口 sock 规则 spl 承担 display attribute 工作
netty源码死磕8
Pipeline outbound 出站流程揭秘
简单回顾一下。
出站(outbound) 操作,通常是处于上层的Netty channel,去操作底层Java NIO channel/OIO Channel。
主要出站(outbound)操作如下:
1. 端口绑定 bind
2. 连接服务端 connect
3. write写通道
4. flush刷新通道
5. read读通道
6. 主动断开连接 disconnect
7. 主动关闭通道 close
最为常见,也是最容易理解的出站操作,是第3个操作 —— write写通道。
一个Netty Channel的write 出站操作 实例:
// server向 Channel写登录响应 ctx.channel().write(“恭喜,登录成功”); //....
对于出站操作,有相应的出站Handler处理器。
有四个比较重要的出站Handler类。
这个四个 Handler 相关的类结构图如下:

在抽象的ChannelOutboundHandler 接口中,定义了所有的出站操作的方法声明。
在ChannelOutboundHandlerAdapter 出站适配器中,提供了出站操作的默认实现。如果要实现定制的出站业务逻辑,继承ChannelOutboundHandlerAdapter 适配器即可。ChannelOutboundHandlerAdapter 面向的是通用的出站处理场景。
有一个特殊场景的出站处理器——HeadContext。先按下不表,稍候重点介绍。
虽然有专门的Handler,但是,并没有专门的出站Context上下文包裹器。
强调一下:
没有单独的出站上下文Context基类。出站和入站,复用了同一个上下文Context基类。它就是AbstractChannelHandlerContext。
在这个AbstractChannelHandlerContext基类中,定义了每一个出站操作的默认实现。
基本的出站方法如下:
AbstractChannelHandlerContext.bind(SocketAddress, ChannelPromise) AbstractChannelHandlerContext.connect(SocketAddress,SocketAddress, hannelPromise) AbstractChannelHandlerContext.write(Object, ChannelPromise) AbstractChannelHandlerContext.flush() AbstractChannelHandlerContext.read() AbstractChannelHandlerContext.disconnect(ChannelPromise) AbstractChannelHandlerContext.close(ChannelPromise)
赘述一遍:
Context类型的接口是ChannelHandlerContext,抽象的基类是AbstractChannelHandlerContext。
出站和入站的区分,通过基类AbstractChannelHandlerContext的两个属性来完成——outbound、intbound。
出站Context的两个属性的值是:
(1)AbstractChannelHandlerContext基类对象的属性outbound的值为false
(2)AbstractChannelHandlerContext基类对象的属性intbound值为true

Pipeline 的第一个节点HeadContext,outbound属性值为true,所以一个典型的出站上下文。
为什么说流逼哄哄呢?
因为:HeadContext不光是一个出站类型的上下文Context, 而且它完成整个出站流程的最后一棒。
不信,看源码:
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler
{
private final Unsafe unsafe;
HeadContext(DefaultChannelPipeline pipeline)
{
//父类构造器
super(pipeline, null, HEAD_NAME, false, true);
//...
}
}
在HeadContext的构造器中,调用super 方法去初始化基类AbstractChannelHandlerContext实例。
注意,第四个、第五个参数非常重要。
第四个参数false,此参数对应是是基类inbound的值,表示Head不是入站Context。
第五个参数true,此参数对应是是基类outbound的值,表示Head是一个出站Context。
所以,在作为上下文Context角色的时候,HeadContext是黑白分明的、没有含糊的。它就是一个出站上下文。
但是,顺便提及一下,HeadContext还承担了另外的两个角色:
(1)入站处理器
(2)出站处理器
所以,总计一下,其实HeadContext 承担了3个角色。
HeadContext作为Handler处理器的角色使用的时候,HeadContext整个Handler是一个两面派,承担了两个Handler角色:
(1)HeadContext是一个入站Handler。HeadContext 是入站流水线处理处理的起点。是入站Handler队列的排头兵。
(2)HeadContext是一个出站Handler。HeadContext 是出站流水线处理的终点,完成了出站的最后棒—— 执行最终的Java IO Channel底层的出站方法。
整个出站处理的流水线,是如何一步一步,流转到最后一棒的呢?
出站处理,起点在TailContext。
这一点,和入站处理的流程刚好反过来。

在Netty 的Pipeline流水线上,出站流程的起点是TailContext,终点是HeadContext,流水线执行的方向是从尾到头。
强调再强调:
出站流程,只有outbound 类型的 Context 参与。inbound 类型的上下文Context不参与(TailContext另说)。
上图中,橙色的是outbound Context ,是出站类型,肯定参与出站流程的。紫色的是inbound context,是入站类型的上下文Context。
上图中,橙色的Context有两个,分别是EncoderContext和HeaderContext两个Context。EncoderContext 负责出站报文的编码,一般将Java 对象编码成特定格式的传输数据包data package。HeaderContext 负责将数据包写出到Channel 通道。
在Pipeline创建的时候,加入Handler之前,Pipeline就是有两个默认的Context——HeadContext,和TailContext。
最初的Pipeline结构,如下图所示:

TailContext是出站起点,HeadContext是出站的终点。也就是说,Pipeline 从创建开始,就具已经备了Channel出站操作的能力的。
关键的问题是:作为出站的起点,为什么TailContext不是橙色呢?
首先,TailContext不是outbound类型,反而,是inbound入站类型的上下文包裹器。
其次,TailContext 在出站流水线上,仅仅是承担了一个启动工作,寻找出第一个真正的出站Context,并且,将出站的第一棒交给他。
总之,在出站流程上,TailContext作用,只是一把钥匙,仅此而已。
老规则,先上例子。
以最为常见、最好理解的出站操作——Netty Channel 出站write操作为例,将outbound处理出站流程做一个详细的描述。
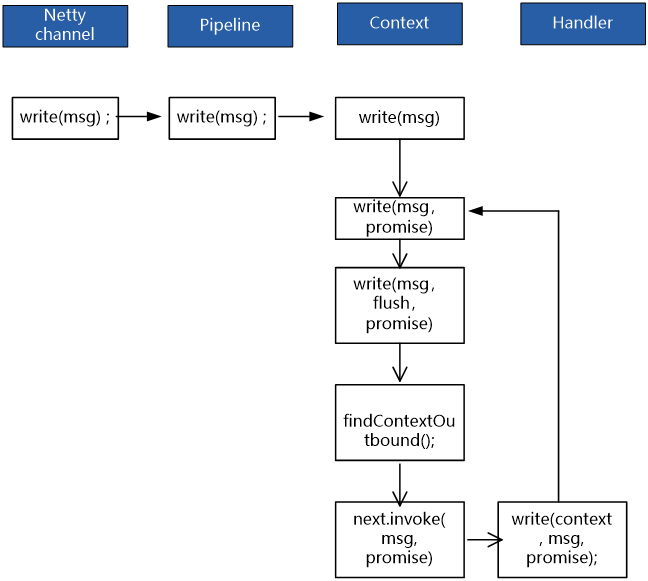
整个写出站的入站处理流程图,如下:
再看一次Netty Channel的write出站实例:
// server向客户 Channel写登录响应 ctx.channel().write(“恭喜,登录成功”); //....
写操作一般的源头是从Netty 的通道channel开始的。当服务器需要发送一个业务消息到客户端,会使用到之前打开的客户端通道channel,调用通道channel的出站写操作write方法,完成写操作。
这个write方法的Netty 源码,在基类AbstractChannel 实现了一个基础的版本。
代码如下:
public abstract class AbstractChannel extends DefaultAttributeMap implements Channel
{
//…
@Override
public ChannelFuture write(Object msg) {
return pipeline.write(msg);
}
//…
}
回忆一下通道和流水线的关系:一个通道一个pipeline流水线。一个流水线串起来一系列的Handler。
所以,通道将出站的操作,直接委托给了自己的成员——pipeline流水线。直接调用pipeline流水线的出站操作去完成。
也就是说,Channel 是甩手掌柜,将出站操作委托给了Pipeline。然而,Pipeline还是一个甩手掌柜。
Pipeline直接甩给了谁呢?
Pipeline 将出站操作,甩给双向链表的最后一个节点—— tail 节点。Pipeline的源码如下:
public class ChannelPipeline …..
{
//…
@Override
public final ChannelFuture write(Object msg) {
return tail.write(msg);
}
//…
}
TailContext 类的定义中,并没有实现 write写出站的方法。这个write(Object msg) 方法,定义在TailContext的基类——AbstractChannelHandlerContext 中。
代码如下:
abstract class AbstractChannelHandlerContext
extends DefaultAttributeMap implements ChannelHandlerContext
{
//……
@Override
public ChannelFuture write(Object msg) {
//….
return write(msg, newPromise());
}
@Override
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
//…
write(msg, false, promise);
return promise;
}
//……
@Override
public ChannelPromise newPromise() {
return new DefaultChannelPromise(channel(), executor());
}
//第三个重载的write
private void write(Object msg, boolean flush, ChannelPromise promise) {
//...
//找出下一棒 next
AbstractChannelHandlerContext next = findContextOutbound();
//....
//执行下一棒 next.invoke
next.invokeWrite(msg, promise);
//...
}
}
有三个版本的write重载方法:
ChannelFuture write(Object msg)
ChannelFuture write(Object msg,ChannelPromise promise)
ChannelFuture write(Object msg, boolean flush,ChannelPromise promise)
第一个调用第二个,第二个调用第三个。
第一个write 创建了一个ChannelPromise 对象,这个对象实例非常重要。因为Netty的write出站操作,并不一定是一调用write就立即执行,更多的时候是异步执行的。write返回的这个ChannelPromise 对象,是专门提供给业务程序,用来干预异步操作的过程。
可以通过ChannelPromise 实例,监听异步处理的是否结束,完成write出站正真执行后的一些业务处理,比如,统计出站操作执行的时间等等。
ChannelPromise 接口,继承了 Netty 的Future的接口,使用了Future/Promise 模式。这个是一种异步处理干预的经典的模式。疯狂创客圈另外开了一篇文章,专门讲述Future/Promise 模式。
第二个write,最为单薄。简单的直接调用第三个write,调用前设置flush 参数的值为false。flush 参数,表示是否要将缓冲区ByteBuf中的数据,立即写入Java IO Channel底层套接字,发送出去。一般情况下,第二个write设置了false,表示不立即发出,尽量减少底层的发送,提升性能。
第三个write,最为重要,也最为复杂。分成两步,第一步是找出下一棒 next,下一棒next也是一个出站Context。第二步是,执行下一棒的invoke方法,也即是next.invokeWrite(msg, promise);
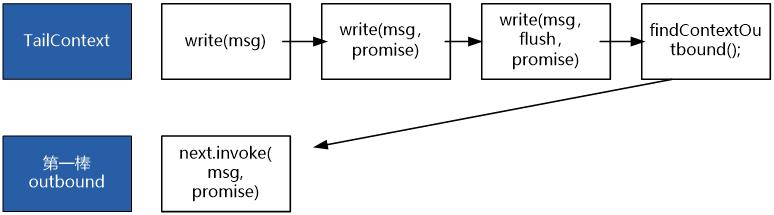
完成以上的三步操作,TailContext 终于将write出站的实际工作,交到了第一棒outbound Context的手中。
至此,TailContext终于完成的启动write流程的使命。
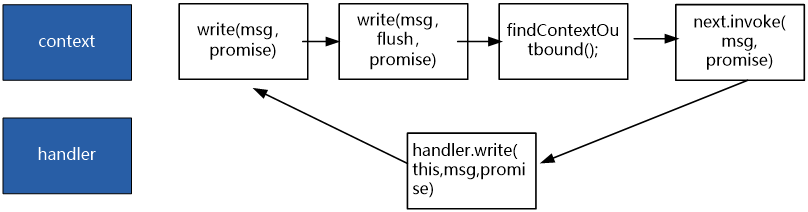
一般来说,Pipeline上会有多个OutBound Context(包裹着Handler),每一个OutBound Context 的处理,可以看成是大的流水处理中的一次小迭代。
每一个小迭代,有五个动作。
五个动作,具体如下:
(1)context.write(msg,promise)
(2)context.write(msg,flush,promise)
(3)context.findContextOutbound();
(4)next.invokeWrite(msg,promise)
(5)handler.write(this,msg,promise)
Context中的write(msg,promise)方法,是整个小迭代的起点。局部的流程图如下:
整个五个动作中,只有第五步在Handler中定义。其他的四步,都在Context中定义。
第一步、第二步的 write 方法在前面已经详细介绍过了。这两步主要完成promise实例的 创建,flush 参数的设置。
现在到了比较关键的步骤:第三步。这一步是寻找出站的下一棒。
出站流程的寻找下一棒的工作,和入站处理的寻找下一棒的方向,刚好反过来。
出站流程,查找的方向是从尾到头。这就用到的双向链表的指针是prev——向前的指针。具体来说,从当前的context开始,不断的使用prev指针,进行循环迭代查找。一直找到终点HeadContext,结束。
Netty源码如下:
abstract class AbstractChannelHandlerContext extends DefaultAttributeMap implements ChannelHandlerContext
{
//…
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
//…
}
每一次的查找,this表示当前的查询所在的context 节点,this.prev表示前一个context节点。
查找时,用到的双向链表的指针是prev——向前的指针。通过while循环,一直往Pipeline的前面查找,如果前面的context不是outbound出站上下文,则一直向前。直到,直到,一直到查找出下一个出站Context上下文为止。
最初的查找,从TailContext开始,this就是TailContext。后续的每一次查找,都是从当前的Context上下文开始的。
找到下一棒出站Context后,执行context的invokeWrite的操作。
源码如下:
abstract class AbstractChannelHandlerContext
extends DefaultAttributeMap implements ChannelHandlerContext
{
//……
private void invokeWrite(Object msg, ChannelPromise promise) {
//...
invokeWrite0(msg, promise);
//...
}
//……
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
}
context的invokeWrite操作,最终调用到了其所包裹的handler的write方法。完成 定义在handler中的业务处理动作。
默认的write 出站方法的实现,定义在ChannelOutboundHandlerAdapter 中。write方法的源码如下:
public class ChannelOutboundHandlerAdapter
extends ChannelHandlerAdapter
implements ChannelOutboundHandler
{
//……
@Override
public void write(ChannelHandlerContext ctx,
Object msg, ChannelPromise promise) throws Exception
{
ctx.write(msg, promise);
}
//……
}
Handler的write出站操作,已经到了一轮出站小迭代的最后一步。这个默认的write方法,简单的调用context. write方法,回到了小迭代的第一步。
换句话说,默认的ChannelOutboundHandlerAdapter 中的handler方法,是流水线的迭代一个一个环节前后连接起来,的关键的一小步,保证了流水线不被中断掉。
反复进行小迭代,迭代处理完中间的业务handler之后,就会走到流水线的HeadContext。
在出站迭代处理pipeline的最后一步, 会来到HeadContext。
HeadContext是如何完成最后一棒的呢?
上源码:
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler
{
private final Unsafe unsafe;
HeadContext(DefaultChannelPipeline pipeline) {
//父类构造器
super(pipeline, null, HEAD_NAME, false, true);
this.unsafe = pipeline.channel().unsafe();
//...
}
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
this.unsafe.write(msg, promise);
}
}
HeadContext 包含了一个unsafe 成员。 这个unsafe 成员,是一个只供在netty内部使用的类型。
unsafe 主要功能,就是完成对 Java NIO 底层Channel的写入 。
由此可见,在Netty中的三大上下文包裹器HeadContext、TailContext 、 DefaultChannelHandlerContext中,HeadContext是离 Java NIO 底层Channel最近的地方。三大包裹器,除了HeadContext,也没有谁包含Unsafe。对完成出站的最终操作职能来说,没有谁比HeadContext 更加直接。所以,这个出站处理的最后一棒,只能是HeadContext 了,呵呵。
至此为止,write出站的整个流水线流程,已经全部讲完。
从具体到抽象,我们再回到出站处理的通用流程。
基本上,在流程上,所有的出站事件的处理过程,是一致的。
为了方便说明,使用OUT_EVT符号代替一个通用出站操作。
通用的出站Outbound操作处理过程,大致如下:
(1)channel.OUT_EVT(msg);
(2)pipeline.OUT_EVT(msg);
(3)context.OUT_EVT(msg);
(4)context.OUT_EVT(msg,promise);
(5)context.OUT_EVT(msg,flush,promise);
(6)context.findContextOutbound();
(7)next.invoke(msg,flush,promise);
(8)handle.OUT_EVT(context,msg,promise);
(9)context.OUT_EVT(msg,promise);
上面的流程,如果短时间内看不懂,可以在回头看看write出站的实例。
标签:pac 接口 sock 规则 spl 承担 display attribute 工作
原文地址:https://www.cnblogs.com/crazymakercircle/p/9902299.html



{kind=link}
{kind=link}
{kind=link}