标签:行数据 介绍 验证 for tle png 结果 激活 清除
昨天配置了tensorflow的gpu版本,今天开始简单的使用一下
主要是看了一下tensorflow的tutorial 里面的 IMDB 电影评论二分类这个教程
教程里面主要包括了一下几个内容:下载IMDB数据集,显示数据(将数组转换回评论文本),准备数据,建立模型(隐层设置,优化器和损失函数的配置),建立一个验证集,训练模型,评估模型,显示训练精度和损失图。
代码我已经完全上传到我的github中去了 https://github.com/OnesAlone/deepLearning/blob/master/two_classification_with_movie_review.ipynb
大部分内容均有注释
下面我简单介绍一下:
首先导入需要的工具包,包括tensorflow,keras,numpy,再下载imdb数据集
import tensorflow as tf from tensorflow import keras import numpy as np imdb = keras.datasets.imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
下载完成后可以用
len(train_data[0]), len(train_data[1])
检查一下是否下载完成

接下来是将整形数组转换为原始的影评(对于训练模型来说没有影响)
# 字典:用于将数字转向单词
word_index = imdb.get_word_index()
# key值不变,value值加3,并新增了4个键值对
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0 # 用来将每一个sentence扩充到同等长度
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # 未知,可能是生僻单词或是人名
word_index["UNUSED"] = 3
# 将键值对的键与值互换
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
# 转译为原句
def decode_review(text):
return ‘ ‘.join([reverse_word_index.get(i,‘?‘) for i in text])
输入
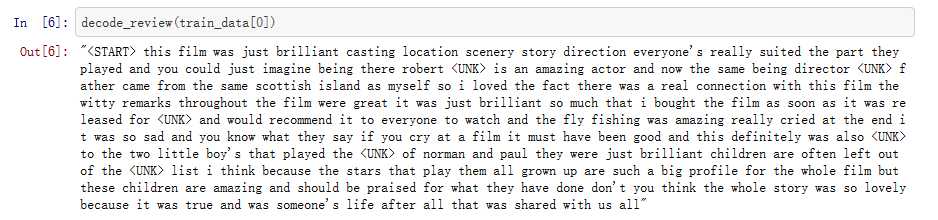
decode_review(train_data[0])
确认一下是否可以转化,转化结果如下所示
接下来对数据进性预处理
因为每一个sequence的长度不一致,为了将其输入到神经网络中,需要将他们的维度做一下预处理,有两种方式
第一种:one-hot编码 将每一个sequence转译成num_words(10000)个 0s和 1s,代表每一个单词是否出现过,这种方式仅统计是否出现和不统计词频,且是内存密集型的编码,总计会有num_words * num_reviews 大小的matrix
第二种:扩展整数数组让他们拥有相同的长度,这样每一个sequence会有共同的max_length(256),总计会占用 max_length*num_reviews大小
教程内采用第二种,在sequence后面扩充0
train_data = keras.preprocessing.sequence.pad_sequences(train_data,value=word_index["<PAD>"],padding=‘post‘,maxlen=256) test_data = keras.preprocessing.sequence.pad_sequences(test_data,value=word_index["<PAD>"],padding=‘post‘,maxlen=256)
接下来构建模型
输入数据是单词组合,标签是0或者1
先进行数据稀疏稠密化,因为sequence里面的word_index值是[0~10000]内稀疏的,所以将每一个单词用一个16维的向量代替;input(1024,256)output(1024,256,16)
再通过均值的池化层,将每一个sequence做均值,类似于将单词合并 ;input(1024,256,16),output(1024,16)
全连接层采用relu激活函数;input(1024,16),output(1024,16)
全连接层采用sigmoid激活函数;input(1024,16),output(1024,1)
vocab_size = 10000 model = keras.Sequential() model.add(keras.layers.Embedding(vocab_size,16)) model.add(keras.layers.GlobalAveragePooling1D()) model.add(keras.layers.Dense(16,activation=tf.nn.relu)) model.add(keras.layers.Dense(1,activation=tf.nn.sigmoid)) model.summary()
因为采用了sigmoid激活函数,所以损失函数不能用mse均方误差,因为在sigmoid函数的两端梯度很小,会使w和b更新很慢 ,所以采用交叉熵代价函数(cross-entropy cost function)
model.compile(optimizer=tf.train.AdamOptimizer(),loss=‘binary_crossentropy‘,metrics=[‘accuracy‘])
构建训练集
x_val =train_data[:10000] partial_x_train = train_data[10000:] y_val = train_labels[:10000] partial_y_train = train_labels[10000:]
开始训练模型,并将训练模型过程中的一些参数如训练精度和交叉验证精度等保存在history中
history = model.fit(partial_x_train,partial_y_train,epochs=40,batch_size=1024,validation_data=(x_val,y_val),verbose=1)
评估模型
results = model.evaluate(test_data, test_labels) results

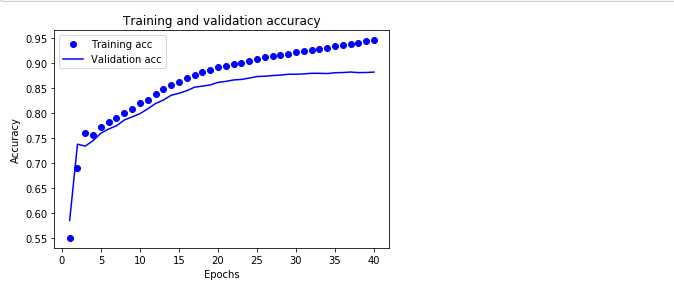
可以看到精度大概在87%
最后通过matplot显示训练过程中的一些参数
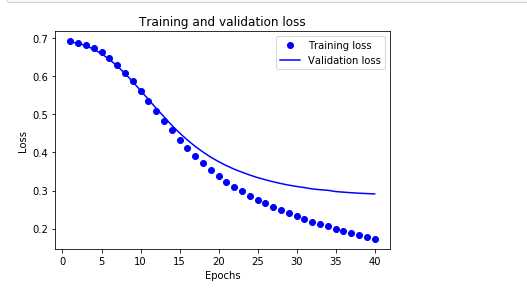
import matplotlib.pyplot as plt acc = history.history[‘acc‘] val_acc = history.history[‘val_acc‘] loss = history.history[‘loss‘] val_loss = history.history[‘val_loss‘] epochs = range(1, len(acc) + 1) plt.plot(epochs, loss, ‘bo‘, label=‘Training loss‘) plt.plot(epochs, val_loss, ‘b‘, label=‘Validation loss‘) plt.title(‘Training and validation loss‘) plt.xlabel(‘Epochs‘) plt.ylabel(‘Loss‘) plt.legend() plt.show()
plt.clf() # 清除图表 acc_values = history_dict[‘acc‘] val_acc_values = history_dict[‘val_acc‘] plt.plot(epochs, acc, ‘bo‘, label=‘Training acc‘) plt.plot(epochs, val_acc, ‘b‘, label=‘Validation acc‘) plt.title(‘Training and validation accuracy‘) plt.xlabel(‘Epochs‘) plt.ylabel(‘Accuracy‘) plt.legend() plt.show()
交叉熵代价函数具有非负性和当真实输出与期望输出相近的时候,代价函数接近于零
标签:行数据 介绍 验证 for tle png 结果 激活 清除
原文地址:https://www.cnblogs.com/leaveMeAlone/p/9902683.html