标签:不同的 指令 rem 表示 logical gre 双线 shift 速度
偶尔看到这样的一个算法,觉得还是蛮有意思的,花了将近10天多的时间研究了下相关代码。
以下为百度的结果:MLAA全称Morphological Antialiasing,意为形态抗锯齿是AMD推出的完全基于CPU处理的抗锯齿解决方案。对于游戏厂商使用的MSAA抗锯齿技术不同,Intel最新推出的MLAA将跨越边缘像素的前景和背景色进行混合,用第2种颜色来填充该像素,从而更有效地改进图像边缘的变现效果,这就是MLAA技术。
其实就是这个是由Intel的工程师先于2009年提出的技术,但是由AMD将其发发扬光大。
整个算法的渲染工作全部是交给CPU来完成,在这里GPU的作用只是将最终渲染出来的画面传给显示器。所以这项技术最大的优势是可以让GPU不再承担抗锯齿的工作,大大降低GPU在运行3D游戏时的压力。相对于以前的抗锯齿技术,MLAA采用Post-filtering(后滤波)机制,好处就在于可以按照颜色是否连续来驱动抗锯齿,而以前只能在初始边缘来抗锯齿。
也就是说这项技术可以在后期来修补那些由锯齿的图,因此我们可以想到其另外一些用处,后续会对这方面进行一个简单的扩展。


如上面两图,左侧图中树叶的边缘有明显的锯齿状图像,而右侧为经过MLAA算法处理后的图,边缘光滑了许多,而且其他部位未受任何的画质影响。
关于这方面的论文和资料主要有Morphological Antialiasing.pdf ,Intel官方还对改算法进行了一些额外的说明,详见:https://software.intel.com/sites/default/files/m/d/4/1/d/8/MLAA.pdf,并且附带了相关源代码,代码可从https://software.intel.com/zh-cn/articles/morphological-antialiasing-mlaa-sample处下载。我们重点来研读和改进下这部分代码。
下载代码后,找到\SAA-samples\SAA文件夹下的 MLAAPostProcess.h和MLAAPostProcess.cpp文件,这就是我们最关心的CPU实现的代码。
根据论文的描述,MLAA算法共包含3个步骤:
1、寻找在特定的图像像素之间的不连续性,在有些图像中梯度幅值较大的并不是边缘点。
2、确定预定模式,确定渲染的图像。
3、在预定模式中进行领里边缘色彩混合处理。确定模式中的相应模板。
下面的文章如果你没有看过代码或者没有看过论文,你根本不知道我在说什么。
第一步的计算连续性,在实现上实际是计算一个像素点和其右侧及下方一个像素的颜色差异绝对值的大小,如果某个点和其下方像素的 AbsDiff大于某个指定的阈值,则设置这个点为水平方向边缘的标记(EdgeFlagH),如果和其右侧像素的颜色差异大于阈值,则设置这个点为为垂直方向边缘的标记(EdgeFlagV)。一个点可以只是水平边缘或垂直边缘,也可以只是其中一个,或者两者都不是。
在获得连续性的基础上,第二步是沿着图像的某一个方向,比如宽度方向分析边缘的形状,这里可以有Z型,U形和L型,针对不同的形状我们有不同的处理方式。
最后,就是在获得形状后,按照一定的规则对这些比较硬性的拐角处(L和Z型都是直角的弯),进行融合和柔化。
由于MLAA算法的初衷是处理GPU初处理的图,因此其主要针对的图像必然是32位图像,而且图像的宽度和高度一般来说都是4的倍数,因此,在Intel给出的代码中我们可以看到都是处理BGRA格式的图像的。
具体到代码实时上,因为是和显示打交道的,因此 ,算法的实时性必须有可靠的保证,不然这个算法粗在的意义就会大打折扣,网络上说人有提供了改算法的GPU实现,但是同时又提到那个GPU代码还不如没有。我想也是,Intel作为改算法的提出者,所分享的代码确实还是相当又学习意义的,我这里来稍微分析下。
首先是不连续性的相关代码,对于32位图形,Intel只计算其BGR三通道和周边像素的差异,当三通道其中一个通道的差异绝对值大于16时,我们就认为这个点是某个方位的边缘处。另外,在Intel的代码中,其将这些标志信息直接隐藏到了BGRA的A通道中,这个可能于DDS格式有关,DDS格式有一些并没有用到所有的Alpha的8位信息。这样做的一个好处是不需要额外的内存用来保存边缘标志。
为了速度起见,同时考虑在CPU端运行,这部分可充分利用SSE进行优化。我们先贴出Intel的相关代码进行分析。
//-------------------------------------------------------------------------------------------------------------------
// This task analyzes the color buffer for discontinuities between pixels to set the edge flags in the work buffer.
//-------------------------------------------------------------------------------------------------------------------
void MLAAFindDiscontinuitiesTask(VOID* pvInfo, INT, UINT uTaskId, UINT)
{
MLAAData* pMLAATaskData = static_cast<MLAAData*>(pvInfo);
UINT* ColorBuffer = pMLAATaskData->pColorBuffer;
UINT BufferWidth = pMLAATaskData->uWidth;
UINT BufferHeight = pMLAATaskData->uHeight;
UINT BufferPitch = pMLAATaskData->uRowPitch; // in pixels, not bytes.
UINT TaskFirstRow = uTaskId * RowsOrColsPerTask;
UINT TaskLastRow = TaskFirstRow + RowsOrColsPerTask;
for(UINT iRow = TaskFirstRow; iRow < TaskLastRow; iRow += 4)
{
UINT BlockFirstRowOffset = iRow * BufferPitch;
for(UINT iCol = 0; iCol < BufferWidth; iCol += 4)
{
__m128i *PixelData = reinterpret_cast<__m128i*>(ColorBuffer + BlockFirstRowOffset + iCol);
// BufferPitch is in pixels i.e. 32-bit units, and PixelData points to a 128-bit data type...
UINT BufferPitch128 = BufferPitch/4;
// Load pixel block from color buffer. vPixels0 contains the 4 pixels indexed by iRow and iCol,
// vPixels1, the 4 pixels just below the pixels in vPixels0, and so on and so forth.
__m128i vPixels0 = _mm_load_si128(PixelData);
__m128i vPixels1 = _mm_load_si128(PixelData + BufferPitch128);
__m128i vPixels2 = _mm_load_si128(PixelData + 2*BufferPitch128);
__m128i vPixels3 = _mm_load_si128(PixelData + 3*BufferPitch128);
__m128i vPixels4 = (iRow == BufferHeight - 4) ?
vPixels3 // For the last block (vertically), add a virtual row by duplicating the last real block row.
: _mm_load_si128(PixelData + BufferPitch);
// zero alpha, we are using it to store discontinuity flags.
__m128i vZeroAlpha = _mm_set1_epi32(0x00FFFFFF);
vPixels0 = _mm_and_si128(vPixels0, vZeroAlpha);
vPixels1 = _mm_and_si128(vPixels1, vZeroAlpha);
vPixels2 = _mm_and_si128(vPixels2, vZeroAlpha);
vPixels3 = _mm_and_si128(vPixels3, vZeroAlpha);
// Check for horizontal pixel discontinuities, one row of 4 pixels checked per call.
// (we compare a row of 4 pixels with its bottom neighbor)
ComparePixelsSSE(vPixels0, vPixels1, EdgeFlagH);
ComparePixelsSSE(vPixels1, vPixels2, EdgeFlagH);
ComparePixelsSSE(vPixels2, vPixels3, EdgeFlagH);
ComparePixelsSSE(vPixels3, vPixels4, EdgeFlagH);
// Transpose pixel block so we can use ComparePixelsSSE to check for vertical discontinuities.
_MM_TRANSPOSE4_PS(
reinterpret_cast<__m128&>(vPixels0),
reinterpret_cast<__m128&>(vPixels1),
reinterpret_cast<__m128&>(vPixels2),
reinterpret_cast<__m128&>(vPixels3) );
vPixels4 = (iCol == BufferWidth - 4) ?
vPixels3 // For the last block (horizontally), add a virtual column by duplicating the last real column.
: _mm_setr_epi32(
* reinterpret_cast<UINT*>(PixelData + 1),
* reinterpret_cast<UINT*>(PixelData + BufferPitch128 + 1),
* reinterpret_cast<UINT*>(PixelData + 2*BufferPitch128 + 1),
* reinterpret_cast<UINT*>(PixelData + 3*BufferPitch128 + 1) );
// Now vPixels0..4 contains the block of pixel data in column order, e.g.
// vPixels0 now stores the leftmost column of 4 pixels, vPixels1 the 2nd leftmost one, etc.
// Now check for vertical pixel discontinuities, one column of 4 pixels checked per call.
// (we compare a column of 4 pixels with its neighbor on the right)
ComparePixelsSSE(vPixels0, vPixels1, EdgeFlagV);
ComparePixelsSSE(vPixels1, vPixels2, EdgeFlagV);
ComparePixelsSSE(vPixels2, vPixels3, EdgeFlagV);
ComparePixelsSSE(vPixels3, vPixels4, EdgeFlagV);
// Transpose back and store in color buffer the pixel data with added discontinuities flags.
_MM_TRANSPOSE4_PS(
reinterpret_cast<__m128&>(vPixels0),
reinterpret_cast<__m128&>(vPixels1),
reinterpret_cast<__m128&>(vPixels2),
reinterpret_cast<__m128&>(vPixels3) );
_mm_store_si128(PixelData, vPixels0);
_mm_store_si128(PixelData + BufferPitch128, vPixels1);
_mm_store_si128(PixelData + 2*BufferPitch128, vPixels2);
_mm_store_si128(PixelData + 3*BufferPitch128, vPixels3);
}
}
}
第一感觉就是代码的注释很丰富,不愧是大家制作,在解释这段代码之前,我们先来看看ComparePixelsSSE函数。
//--------------------------------------------------------------------------------------------------------------
// Given a row of 4 pixels, check for color discontinuities between a pixel and its neighbor.
// SSE implementation, so we process the 4 consecutive pixels at a time.
// If a discontinuity is detected, the flag passed as 3rd arg. is set in the alpha component of the pixel.
// vPixels0 is the vector of 4 pixels to be flagged if discontinuities are detected.
// vPixels1 is the vector of 4 neighbor pixels.
//--------------------------------------------------------------------------------------------------------------
inline void ComparePixelsSSE(__m128i& vPixels0, __m128i vPixels1, const INT EdgeFlag)
{
// Each byte of vDiff is the absolute difference between a pixel‘s color channel value, and the one from its neighbor.
__m128i vDiff = _mm_sub_epi8(_mm_max_epu8(vPixels0, vPixels1), _mm_min_epu8(vPixels0, vPixels1));
// We are only interested if the difference is greater than 16, and not interested in alpha differences.
const INT Threshold = 0x00F0F0F0;
__m128i vThresholdMask = _mm_set1_epi32(Threshold);
vDiff = _mm_and_si128(vDiff, vThresholdMask);
// Each of the four lanes of the selector is 0 if no discontinuity detected RGB, 0xFFFFFFFF else.
__m128i vSelector = _mm_cmpeq_epi32(vDiff, _mm_setzero_si128());
__m128i vEdgeFlag = _mm_set1_epi32(EdgeFlag);
vEdgeFlag = _mm_andnot_si128(vSelector, vEdgeFlag);
// vEdgeFlag now contains EdgeFlag for the pixels where a discontinuity was detected, 0 otherwise.
vPixels0 = _mm_or_si128(vPixels0, vEdgeFlag);
}
ComparePixelsSSE的作用就是比较8个BGRA像素的差异,如果像素的BGR差异值有一个大于阈值,则设置A的某个位为Flag。
第一行vDiff的计算就是计算差异值的绝对值,他一次性可以计算16个字节值的差异,因为SSE没有直接提供这样的函数,因此,这里使用max和min函数结合实现,也是非常的巧妙,其实还有另外一个方式可以实现这个功能,如下所示:
// 返回8位字节数数据的差的绝对值
inline __m128i _mm_absdiff_epu8(__m128i a, __m128i b)
{
return _mm_or_si128(_mm_subs_epu8(a, b), _mm_subs_epu8(b, a));
}
利用了饱和计算,同样也是十分的巧妙。后续测试表面上述方法速度似乎还能有一定的优势。
vDiff = _mm_and_si128(vDiff, vThresholdMask); 这一句结合__m128i vSelector = _mm_cmpeq_epi32(vDiff, _mm_setzero_si128());是这个函数的灵魂所在,我们注意到vThresholdMask对应的字节范围内数据的高4位都是1,低4位都为0,因此如果vDiff中某个值大于16(高4位有值不为1),则进行and运算后返回值必然不为0,4个字节中只要有一个不为0,组成的32位数也必然不为0,这样一个BGRA像素只要有一个通道有AbsDiff大于0的值,就可以通过_mm_cmpeq_epi32的比较(和0比较)返回值得以体现。
后面使用_mm_andnot_si128是因为我们_mm_cmpeq_epi32的函数在等于0时返回0xFFFFFF,而我们实际上在此时想让他为0x00000000,因为系统不提供_mm_cmpneq_epi32这样的函数,所以要先取反下(not),然后在和Flag进行And运算,特别需要注意的是,不想大多数的SSE函数,_mm_andnot_si128这个SSE函数对参数的顺序是铭感的,如果放错了位置,则无法得到正确的结果。 另外,这里const INT EdgeFlagH = (1 << 31)以及const INT EdgeFlagV = (1 << 30),Intel也是考虑的很好,第一,和他们进行and操作不会影响BGR的值,第二,后面还有一个技巧也和这个值有关。
最后的_mm_or_si128主要是考虑水平和垂直方向的边缘的综合识别。
虽然我们知道对32位数,SSE有_mm_cmpge_epi32这个比较函数,但是在这里确实无法直接使用他。
我们再来回头看MLAAFindDiscontinuitiesTask这个函数,他的核心是一次性读取4行4列共16个BGRA像素,占用4个XMM寄存器得大小,然后在函数内部一次性的计算出水平边缘和垂直边缘的标记,这样左一个核心的好处是能减少读取内存的次数。那么这里最灵活的运用就是_MM_TRANSPOSE4_PS这个宏的使用。我们看他的名字,就知道他是针对浮点进行转置使用,而我们的32位图像加载后是__m128i类型的,但是其实在计算机内部,不管你表面是浮点的还是整形的,都是把数据保存在XMM寄存上,因此,我们用reinterpret_cast或者_mm_castsi128_ps这样的一些语法糖来强制转换,让编译器能编译通过,_MM_TRANSPOSE4_PS这个照样可以处理整形的。
比如,_mm_castsi128_ps这个函数intel给出的解释是Cast vector of type __m128i to type __m128. This intrinsic is only used for compilation and does not generate any instructions, thus it has zero latency. 也就是说他并没有产生任何额外的指令,只是个语法糖。
当然,我们不用_MM_TRANSPOSE4_PS也可以用整形的unpack系列函数实现32位整形的转置,实测他们效率基本无区别。
话题扯得远了点,MLAAFindDiscontinuitiesTask中,首先一次性加载四行各4各像素后,一次进行水平方向的比较,水平比较完后,这样对这些数据进行转置,有可以继续进行垂直方向的比较,比较完成后,再转置回来,就一次性完成了水平和垂直方向的所有比较。因此,速度就能得到大幅的提高。
这一步的优化完成,第二步中我们要寻找不同的模式,其中一个关键的步骤就是寻找具有同一边缘标记的连续线段。这部分再函数里实现,如下所示:
//-----------------------------------------------------------------------------------------------------------------------------------------
// Given a range of pixels offsets [OffsetCurrentPixel, OffsetEndRow], walk this range to find a discontinuity line.
// We call a "separation line" or "discontinuity line" a sequence of consecutive pixels that all have the same edge flag set.
// The 3 return values are: the length of the separation line, and the offsets in the buffer of the first and last pixel of the line.
//-----------------------------------------------------------------------------------------------------------------------------------------
inline UINT FindSeparationLine(int& OutOffsetLineStart, int& OutOffsetLineEnd, UINT* WorkBuffer, UINT OffsetCurrentPixel, UINT OffsetEndRow, const INT EdgeFlag)
{
if (OffsetCurrentPixel >= OffsetEndRow)
{ // We are done scanning this row/column; no separation line left to find.
return 0;
}
// Find first extremity of the line... 找寻线的端头
OutOffsetLineStart = -1;
int Shift = (EdgeFlag == EdgeFlagV) ? 1 : 0;
for (;;)
{
__m128i PixelFlags = _mm_loadu_si128((__m128i*)(WorkBuffer + OffsetCurrentPixel));
PixelFlags = _mm_slli_epi32(PixelFlags, Shift);
// Creates a 4-bit mask from the edge flag of each of the 4 pixels
int HFlags = _mm_movemask_ps(_mm_castsi128_ps(PixelFlags));
if (HFlags)
{
unsigned long Index;
_BitScanForward(&Index, HFlags);
OffsetCurrentPixel += Index;
OutOffsetLineStart = OffsetCurrentPixel;
break;
}
OffsetCurrentPixel += 4; // None of the pixels had its flag set so we can jump ahead 4 pixels...
if (OffsetCurrentPixel >= OffsetEndRow)
{ // Done scanning this row/column, without finding a separation line.
OutOffsetLineStart = OutOffsetLineEnd = OffsetEndRow - 1;
return 0;
}
}
FindEndOffset:
// Now look for the second extremity of the line.
// We could use a SSE-based optimization as the one above, but it remains to be seen if it would help significantly the performance.
// (discontinuity lines tend to be short)
UINT LineLength = 1;
++OffsetCurrentPixel;
while ((OffsetCurrentPixel <= OffsetEndRow) && ((WorkBuffer[OffsetCurrentPixel] & EdgeFlag) != 0))
{
++LineLength;
++OffsetCurrentPixel;
}
OutOffsetLineEnd = OffsetCurrentPixel - 1;
return LineLength;
}
好像这段代码我稍微修改了下,源代码有对OffsetCurrentPixel不是4的整数倍做判断,其实那个判断是基于默认使用(__m128i *)这种方式加载变量到SSE寄存器是采用的_mm_load_si128(即16字节对齐有关),如果显式的使用_mm_loadu_si128则无需那样写。
我们看下这里的技巧主要在于_mm_movemask_ps的使用,在第一步不连续性的标记过程中,我们把边缘比较分别设置在低31位(水平边缘)和低30(垂直边缘)位中,因此,如果是寻找垂直边缘是,我们把整体向左移动移位,这个时候在他们强制转换为浮点数,此时_mm_movemask_ps就会根据XMM寄存中每个32位的浮点数的sign返回一个值,如果返回值的都为0,则表示4各数都为正数,说明这4个位置都没有我们需要寻找的标记,如果结果不为0,这个时候我们应该从低位到高位寻找到第一个不为0的位,他对应的索引就是第一个标记所在的位置,这种位寻找的函数在Intel里正好有提供,即本例的_BitScanForward函数。
这个方式在很多的优化或计算中都可以借鉴,确实是个不错的方法。
那么当找到第一个位置的标记后,我们就需要找到最后一个标记,一般情况下连续的统一标记不会太长,因此后续的寻找不需要借助SSE处理。
还有一个使用了SSE优化的地方就在于最后一步的融合地方,如下所示函数:
inline void MixColors(UINT* ColorBuffer, UINT OffsetDst, float Weight1, UINT Offset1, float Weight2, UINT Offset2)
{
// Load pixels and convert the bytes to dwords
__m128i Col1i = _mm_cvtsi32_si128(ColorBuffer[Offset1]);
__m128i Col2i = _mm_cvtsi32_si128(ColorBuffer[Offset2]);
__m128i Zero = _mm_setzero_si128();
Col1i = _mm_unpacklo_epi16(_mm_unpacklo_epi8(Col1i, Zero), Zero);
Col2i = _mm_unpacklo_epi16(_mm_unpacklo_epi8(Col2i, Zero), Zero);
// Convert to floats so the pixels can be multplied with the weights
__m128 Col1f = _mm_cvtepi32_ps(Col1i);
__m128 Col2f = _mm_cvtepi32_ps(Col2i);
Col1f = _mm_mul_ps(Col1f, _mm_set1_ps(Weight1));
Col2f = _mm_mul_ps(Col2f, _mm_set1_ps(Weight2));
Col1f = _mm_add_ps(Col1f, Col2f);
// Go back to byte from float
__m128i Coli = _mm_cvttps_epi32(Col1f);
Coli = _mm_packs_epi32(Coli, Coli);
Coli = _mm_packus_epi16(Coli, Coli);
// Store the weighted pixel
ColorBuffer[OffsetDst] = (ColorBuffer[OffsetDst] & 0xFF000000) | (_mm_cvtsi128_si32(Coli) & 0x00FFFFFF);
}
这个其实也很简单,就是4个字节数据乘以4个浮点数,然后累加,最后结果保存为字节数,并且要保留部分字节不变的一个过程,有兴趣的朋友可以自己研读下。
那么在Intel的代码中,还利用了TBB进行优化,将计算分成了多任务处理过程,另外,考虑垂直方向的cache命中率问题,将垂直计算过程使用转置后在调用水平方向的算法进行处理。
那么后面我在谈下这个代码里几个细节的东西。
(1)代码里有ComputeUpperBounds和ComputeLowerBounds函数,他们的主要作用是辅助确认模式,代码本身不难,但是如果你只去读函数本身,你会发现他的判断逻辑似乎说不通,类似下面这句这样的代码:
if (((WorkBuffer[BelowOffset] & OrthoEdgeFlag) != 0) && ((WorkBuffer[BelowOffset] & EdgeFlag) != 0))
你会感觉到应该不会出现这种情况啊,我在这里也看了半天,后来才发现,调用他们的代码在参数上动了手脚,比如下面这个:
ComputeUpperBounds(ui0, ui1, uh0, uh1,
ColorBuffer,
OffsetLineStart - 1, OffsetLineEnd, SeparationLineLength, StepToPreviousRow, BufferPitch, BufferPitch * Height, EdgeFlag);
我们注意OffsetLineStart - 1这里的减1,原来他并不是从找到的线条的第一个点开始,而是向前一个点,这样这个模式就容易理解了。
(2)在MLAABlendHTask以及MLAABlendVTask中,我们注意到都没有处理最后一行或一列像素,这是因为最后一行或最后一列按照前面的边缘计算模式,都只可能出现一种模式, 比如,最后一行,其水平边缘肯定是步成立的。因此,我们在这一行找不到Z或U这种模式,也就没有必要进行处理。
(3)在Intel的代码中,有个计算ComputeHc函数:
inline float ComputeHc(UINT* WorkBuffer, UINT PrimaryEdgeLength, UINT OffsetC1, UINT OffsetC2, UINT OffsetD2, UINT OffsetD3)
{
int C2 = SumColor(WorkBuffer[OffsetC2]);
int C1 = SumColor(WorkBuffer[OffsetC1]);
int D3 = SumColor(WorkBuffer[OffsetD3]);
int D2 = SumColor(WorkBuffer[OffsetD2]);
int D3D2Diff = D3 - D2;
int C1C2Diff = C1 - C2;
int D2C2Diff = D2 - C2;
return float(PrimaryEdgeLength * D2C2Diff + C1C2Diff + D3D2Diff) / (PrimaryEdgeLength * (C1C2Diff - D3D2Diff) + C1C2Diff + D3D2Diff);
}
我曾经在修改代码过程中,把UINT PrimaryEdgeLength改为INT PrimaryEdgeLength,结果对一个测试图像得到的结果就会发生不错,如下所示:


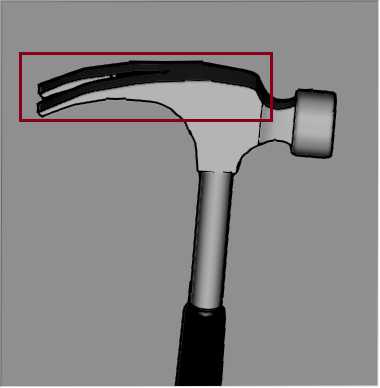
第一张为原图,第二张使用UINT的结果图,第三张为改为int后的结果图,很明显在红色方框部分的圆弧处依旧有较为明显的毛刺出现,而整体的代码只是个数据类型发生了改动。
我曾经弄了很久才发现这个问题出现在那个函数里,但是发现了后却一直不知道问题出现在那里,当我把参数改为int类型,输出了所有的PrimaryEdgeLength值,确认这里面确实没有任何的0或者负数,那按照我的想法不应该会出现这个问题,后来仔细搜索了下,原来问题还是处在数据类型上,因为编译器在同时存在无符号和有符号数计算时,是会将有符号数强制转换为无符号数的,即所谓的升格处理,上述代码里的D3D2Diff 都有可能有负数存在,因此,这中升格处理会使得计算结果完全偏离了我们的预想。
那在自己想一想,我们确认应该在这里使用int类型才对,但为什么我们却获得了不理想的效果呢,这里我认为是原文作者的一个观点有问题,即HC的计算里,原文有这句话:
To state the requirements for smooth transition between two shapes, we compute the same blended color twice, using parameters of
each shape:
即要保持平滑,而对黑白图像,HC就是固定值0.5f.
在Intel的代码里,存在好几处类似这样的代码:
if (BelowOffset + StepToNextRow < BufferSizeInPixels)
{
OutH1 = ComputeHc(WorkBuffer, LineLength - NSteps, BelowOffset + StepToNextRow + 1, BelowOffset + 1, BelowOffset, CurrentOffset);
}
else
{ // We are too close to the end of the buffer to be able to do the ComputeHc calculation, so use default hc value of 0.5
OutH1 = 0.5;
}
if ((OutH1 > 0) && (OutH1 < 1))
{ // If the computed value of hc is in the acceptable range, then we‘re done else keep walking
OutS1 = CurrentOffset;
break;
}
即如果通过ComputeHc计算的值不在0和1之间,就取值0.5,那么前面的使用UINT的情况基本计算出的值都离谱的很,很难在0和1之间,因此,程序最后都相当于直接取Hc等于0.5,而使用int时结果不理想,说明原作者的部分思路也不靠谱。 因此,我建议这部分直接使用0.5,去掉这个ComputeHc的过程,又能节省时间又能还有不错的效果,不晓得Intel的工程师有没有注意到这一点。
(4) 这个算法其实本身的计算量是不大的,因为一幅图像中需要修改的像素其实不多,另外,由于计算特性,基本上支持InPlace操作。
注意到Intel共享的代码确实还有很多局限性,只能处理32位,只能处理4个倍数大小的图像,还会破坏原始图像的Alpha通道,好像还有其他的不好的内存问题(符合前面的条件的图片运行也会挂),根据算法思路我重构了下代码,使得其能处理任意大小即灰度和24位图像。
第一,连续性检测。我们为了不破坏原始图像,重新定义一个Width*Height大小的字节空间来保存边缘信息。对于灰度图,可用如下代码搞定。
int BlockSize = 16, Block = (Width - 1) / BlockSize; // 垂直和水平方向比较同步进行,考虑到垂直方向比较时最后一列不能参与
__m128i T = _mm_set1_epi8(Threshold);
for (int Y = 0; Y < Height - 1; Y++) // 水平比较时最后一行像素不能参与
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePN = LinePS + Stride;
unsigned char *LinePM = Mask + Y * Width;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i SrcH1 = _mm_loadu_si128((__m128i *)(LinePS + X));
//__m128i SrcH2 = _mm_loadu_si128((__m128i *)(LinePS + X + 1));
__m128i SrcH2 = _mm_insert_epi8(_mm_srli_si128(SrcH1, 1), LinePS[X + 16], 15); // 似乎速度有没啥区别
__m128i SrcV1 = _mm_loadu_si128((__m128i *)(LinePN + X));
__m128i AbsDiffH = _mm_absdiff_epu8(SrcH1, SrcV1); // 水平方向比较,abs(Bottom - Current),似乎和常人了解的水平方向不一致
__m128i AbsDiffV = _mm_absdiff_epu8(SrcH1, SrcH2);; // 垂直方向比较,abs(Right - Current)
__m128i FlagH = _mm_and_si128(_mm_set1_epi8(EdgeFlagH), _mm_cmpge_epu8(AbsDiffH, T)); // 设置水平方向的标志位
__m128i FlagV = _mm_and_si128(_mm_set1_epi8(EdgeFlagV), _mm_cmpge_epu8(AbsDiffV, T)); // 设置垂直方向的标志位
_mm_storeu_si128((__m128i *)(LinePM + X), _mm_or_si128(FlagH, FlagV)); // 设置总的标志位
}
// ...............
}
这里我另外一种方式来做水平和垂直方向的优化,我们一次性只处理一行代码,但是在垂直方向比较时,单独往后加载一个像素,注意SrcH1和SrcH2 其实只有一个像素不同,因此,我尝试用_mm_insert_epi8来减少内存读取量,但同时增加了一个移位操作,实际测试和直接使用_mm_loadu_si128读取速度差异基本可忽略。由于使用的时字节变量来保存边缘信息,因此可使用字节比较_mm_cmpge_epu8的结果来进行位操作。
对于24位或者32位图像,这时我的处理方式是:
int BlockSize = 4, Block = (Width - 1) / BlockSize; // 垂直和水平方向比较同步进行,考虑到垂直方向比较时最后一列不能参与
__m128i T = _mm_set1_epi8(Threshold);
for (int Y = 0; Y < Height - 1; Y++) // 水平比较时最后一行像素不能参与
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePN = LinePS + Stride;
unsigned char *LinePM = Mask + Y * Width;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i SrcH1 = _mm_loadu_si128((__m128i *)(LinePS + X * 4));
__m128i SrcH2 = _mm_loadu_si128((__m128i *)(LinePS + X * 4 + 4));
__m128i SrcV1 = _mm_loadu_si128((__m128i *)(LinePN + X * 4));
__m128i AbsDiffH = _mm_absdiff_epu8(SrcH1, SrcV1); // 水平方向比较,abs(Bottom - Current),似乎和常人了解的水平方向不一致
__m128i AbsDiffV = _mm_absdiff_epu8(SrcH1, SrcH2); // 垂直方向比较,abs(Right - Current)
__m128i FlagH = _mm_andnot_si128(_mm_cmpeq_epi32(_mm_cmpge_epu8(AbsDiffH, T), _mm_setzero_si128()), _mm_set1_epi32(EdgeFlagH)); // 设置水平方向的标志位,注意_mm_andnot_si128是对参数的顺序敏感的,(~a) & b
__m128i FlagV = _mm_andnot_si128(_mm_cmpeq_epi32(_mm_cmpge_epu8(AbsDiffV, T), _mm_setzero_si128()), _mm_set1_epi32(EdgeFlagV)); // 设置垂直方向的标志位
_mm_storesi128_4char(LinePM + X, _mm_or_si128(FlagH, FlagV));// 设置总的标志位
}
// ..........
}
其实前面没提, Intel代码的Threshold默认设置为16,其实这是个特殊的值,如果要支持任意的阈值,则不能像ComparePixelsSSE那样做,只有像16,32,64等这样几个特殊的值才可以用(相反数高位连续的二进制都为1),要支持任意阈值,我们就可以像上面那样借助_mm_cmpge_epu8和_mm_cmpeq_epi32来共同实现。
在搜索水平线的时候,也同样需要更换一种技巧,如下所示:
__m128i PixelFlags = _mm_loadu_si128((__m128i*)(Mask + Y)); // 合理加载数据, 不能超出范围
int HFlags = _mm_movemask_epi8(_mm_cmpeq_epi8(_mm_and_si128(PixelFlags, Flag), Flag)); // _mm_movemask_epi8提取每个字节的最高位来组成一个16位数
if (HFlags != 0) // 说明在这16个元素里有部分标记是符合条件的
{
unsigned long Index;
_BitScanForward(&Index, HFlags); // 找到第一个位为1值得索引(从低到高位寻找),intel的bsf指令
OutOffsetLineStart = Y + Index;
goto FindEndOffset; // 寻找结束位置
}
基本的原理和之前的类似,只是要改改相关函数。
结合其他的优化技巧(比如转置使用SSE处理),目前我做到的速度是:720P的32位图像大约是8ms,1024P的图像大约是18ms。以上都是单核的处理结果,当然这个的时间其实还和图像本身的内容和复杂度有关。
从算法本身的角度来说,是支持并行执行的,如果采用双线程,应该还有个50%左右的提速,用于游戏后期的渲染应该是够了。
算法还有一些有意思的特征,由于识别模式的一些问题,对于同一个图像内容,旋转一定角度后,其处理的结果并不一定一样,比如下图:



第三图是对原图旋转180度后,进行本算法处理,然后在旋转180度后得到的结果,很明显,第三图的结果和第二图不一样,而且要好很多。
对于阈值的选择,这也是个问题,比如下图:



中间一幅图的阈值选择位16,明显感觉肩膀和衣服下边缘还有部分锯齿,而第三个图的阈值选择为32,则锯齿感又少了很多。
那么由于算法的内在特性和算法研发的背景,对于两个方向宽度都大于2个像素的锯齿,算法是无法解决的,比如下面右侧处理后的图基本无效果。


对于本身就已经光滑的边缘,这个算法一般也不会产生不好的效果,如下图所示:


左图的右半部分本身就是很光滑的,而左半部分又锯齿,处理后的右图,左半部分锯齿基本消失,而右半部分基本没变。
对于黑白图像,这个的去锯齿功能也比较显著。




那么我找了几个真正的游戏里的画面,尝试了下,后续的去锯齿效果,确实也能获得很好的结果:


由于这些图都是网络上下载的,一般都为JPG格式,本身经过了压缩,这样会引入噪音,会对边缘的识别有一定的影响,而如果是直接处理显卡输出的数据,则不会有任何的损失,因此,理论上会取得更好的效果。
测试见附件的SSE_Optimization_Demo的Other菜单。
Demo下载地址:https://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar

SSE图像算法优化系列二十四: 基于形态学的图像后期抗锯齿算法--MLAA优化研究。
标签:不同的 指令 rem 表示 logical gre 双线 shift 速度
原文地址:https://www.cnblogs.com/Imageshop/p/9903045.html