标签:针对 几何 min tin 心得 处理 表示 种类 微软雅黑
朴素贝叶斯算法
在结束生成算法模型之前,我们将一种专门用于文本分类的算法。对于分类问题,朴素贝叶斯算法通常效果很好,而对于文本分类而言,则有更好的模型。
对于文本分类,之前提到的朴素贝叶斯算法又称之为多元伯努力事件模型(multi-variate Bernoulli event model)。模型分析,在之前已经讨论过了。这里,我们解释一下如何理解数据的生成呢?在该模型中,我们假设邮件是按照先验概率(p(y))随机发送邮件或垃圾邮件到用户手里的,之后遍历词汇表,以伯努力分布生成该邮件单词(特征向量,同时假设了各个单词在邮件中出现的概率是条件独立),之后根据p(xi= 1|y) =φi|y进行后验概率的计算,得到p(y)(只要计算后验概率的分子即可,各个类分母均相等,用于归一化)。该模型中,x取值仅有{0,1},且生成特征的方式是以遍历词汇表的方式。
对于新模型中的参数如下,注意这里假设了对于所有的j(j是样本的下标), p(xj|y)的值均相等(生成哪个单词的概率分布并不依赖于该样本在整体中的位置),其中k表示具体的单词。
φk|y=1 = p(xj=k | y=1)(对于每一个j)
φk|y=0 = p(xj=k | y=0) )(对于每一个j)
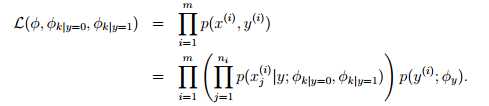
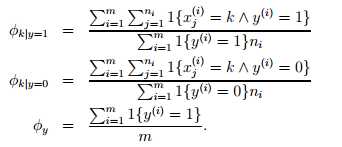
该结果显示,φk|y=1 的分子是单词k在每一封垃圾邮件中的出现次数的总和,分母是每一封垃圾邮件长度的总和;φy分子表示垃圾邮件个数,分母表示样本总数。
如果采用拉普拉斯平滑,那么结果如下,即在分子中加1,在分母中加上词汇表长度:
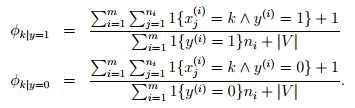
在许多分类问题中,尽管可能不一定是最优模型,贝叶斯模型也是最值得第一个尝试的模型,因为他相对简单且容易解释。
在文本分类的过程中,通常情况下多项事件模型比朴素贝叶斯模型要好,因为他考虑了词语出现的次数。当然,研究者仍存在争论。在文本分类中,仍然是非常优秀的。当然,考虑了词语的顺序等等,也会提高分类效果,如马尔可夫链模型,但只是很细微提高。
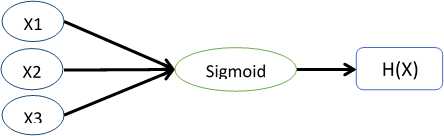
其中,Xi是输入的特征变量,中间的sigmoid函数用计算单元的形式表示,最终输出结果。而神经网络就是将这些简单的单元组合起来,如下图所示:
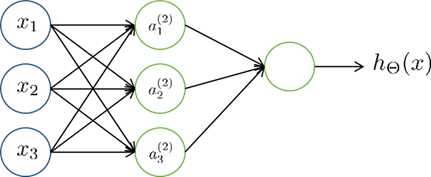
其中,a1,a2,a3是中间单元的计算输出。通常,我们也会在输入特征中则加x0=1,这样更吻合实际的logistic回归。这里,我们取函数g来表示sigmoid函数,则有下式:
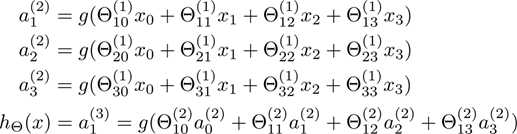
首先我们从间隔开始说起。这里先从直观的角度去看间隔和分类的效果,之后再正式的推倒。考虑一下logistic回归,概率p(y=1 | x;θ) 是等于hθ(x) = g(θTX) 的,如果hθ(x)大于0.5(或者等价于θTX大于0),那么我们就预测分类结果是1,反之则预测为0。现在我们考虑一个训练样本y=1,如果θTX越大,那么hθ(x) = p(y = 1|x; w, b) 越大,因此我们越有信心(confidence)判断结果为1。通俗的说,如果θTx ? 0,那么我们就有十足的信心认为y=1,同样如果θTx ? 0,那么我们就有十足的信心认为y=0。因此,对于所有的训练集合,如果我们找到了合适的参数,使得在y(i) =1的样本中 θTx(i) ? 0,而在y(i) =0的样本中 θTx(i) ? 0,这就暗示了我们有很大的信心说这是一个好的分类器。这个想法看起来很通俗直观,之后我们会用正式的表达式表示函数间隔。
这里我们正式的表示函数间隔(functional margin)和几何间隔(类似于点到直线距离公式,但有区别)。对于一个训练样本(x(i), y(i)),函数间隔为
如果y(i) = 1,为了让函数间隔?γ(i)越大(即预测为y=1类的信心愈大),那么我们希望wTx + b是一个非常大的正数。相反,如果y(i) = -1,为了让函数间隔?γ(i)越大,那么我们希望wTx + b是一个非常小的负数。此外,如果y(i)(wTx + b) > 0,则说明该样本的分类预测正确。因此,函数间隔?γ(i)越大,则说明我们越有信心得到一个正确的分类结果。
对于一个选择了函数g(仅有结果{-1,1})的线性分类器,有一个特征使得他并不能很好的度量信心。对于g,如果我们把w和b分别用2w和2b来替换,那么g就可以表示为g(2wTx + 2b),但是这对hw,b(x)没有任何影响,因为hw,b(x)仅依赖于正负号。但是对于间隔来说却是翻倍了,换句话说我们不需要考虑实际的样本,而仅通过改变w和b的值就可以无限的扩大间隔。因此,直觉上我们希望通过归一化如||w||2= 1来解决这个问题。我们之后在进行讨论归一化的问题。
上面的函数间隔定义是针对于一个样本,而对于给定的数据集S = {(x(i), y(i)); i = 1, . . . , m},这里我们定义的函数间隔为有所间隔中最小的间隔:
现在我们讨论一下几何间隔(geometric margins),考虑下图:
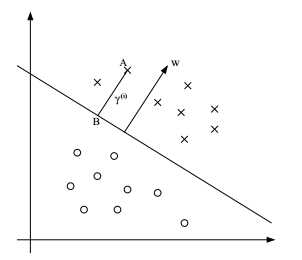
对应(w, b)的决策边界如图所示,其中w正交于超平面。(对于直线 wT x+b=0,方向为 )。对于表示训练集合中输入特征x(i)且分类为y(i) =1的A点而言,它到决策边界的距离为 γ(i),即线段AB。那么我们如何求得γ(i)呢?我们知道w/||w|| 表示B到A的单位向量,即方向向量w的单位向量。对于已知A点是x(i),那么B点的输入为:x(i) - γ(i) *( w/||w||) (即由A点按照向量w的反方向移动γ(i)个单位之后得到B点)。同时,我们知道B点在决策边界上,满足决策边界方程。因此有:
wT ( x(i) - γ(i) *(w/||w||) ) + b = 0
因为wTw/||w|| = ||w||,因此求得γ(i) = (wT/||w|| ) x(i) + b / ||w|| 。这里求得的距离是针对y=1的A点,距离γ是正数。如果是在决策边界的另一侧呢?
更普遍的说,我们定义几何距离(geometric margin),对于给定的训练样本(x(i) ,y(i) ),几何距离如下:
γ(i) = y(i) ( (wT / ||w|| ) x(i) + b / ||w|| )
最后,对于给定的训练集合S = {(x(i), y(i)); i = 1, . . . , m},这里我们定义的几何间隔为有所几何间隔中最小的间隔:
标签:针对 几何 min tin 心得 处理 表示 种类 微软雅黑
原文地址:https://www.cnblogs.com/kexinxin/p/9904402.html