标签:orm image .com 决策 learn sub mat 估计 无法
生成学习算法
目前为止,我们主要讲解了条件概率模型p(y|x,θ)的学习算法。接下来,我们将讨论其他的学习算法。接下来举个例子,比如现在遇到一个分类问题,基于一些特征来判断一个动物是大象 (y = 1) 还是小狗 (y = 0)。基于给定的数据集,我们可以采用logistic回归或者感知器学习的方法来寻找一条直线(称之为决策边界)把大象和小狗分割开割开来。之后预测新的动物时,只要判断它在决策边界的哪一边就可以预测其所属分类。
现在有另外一种方法。首先是查看大象的数据,然后建立一个什么是大象的模型,之后查看小狗的数据,建立一个什么是小狗的模型。之后,遇到新的动物,只要分别代入两个模型中,看更像小狗还是大象就可以分类了。
通过训练集合来学习p(y | x)的学习算法称之为判别学习算法(discriminative learning algorithms),而通过训练集合来学习得到p(x | y)的学习算法则称之为生成学习算法(generative learning algorithms)。对于上大象和小狗的例子,p(x | y=0)表征了小狗的特征分布。
在知道了类的先验概率(class priors)p(y)之后,根据贝叶斯规则(Bayes rule),可以得到:p(y | x) = p(x | y) p(y) / p(x),其中分母p(x) = p(x | y=1)p(y = 1) + p(x | y =0) p(y = 0) (全概率公式)。如果只是为了预测(判断哪一个p(y | x)更大),我们就不需要计算分母,只需要比较分子的大小就可以。
多元正态分布,又称为多元高斯分布,它的均值μ ∈ Rn,它的方差Σ称为方差矩阵(covariance matrix), Σ ∈ Rn*n,是一个对称矩阵,表示为Ν (μ, Σ),表示如下:
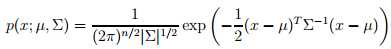
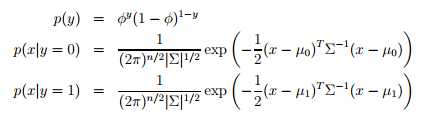
这里,需要注意我们的假设条件中有两个不同的μ(分别为μ0 μ1), 但是Σ却只有一个(特征之间的方差)。之后,采用最大似然估计,可以得到:
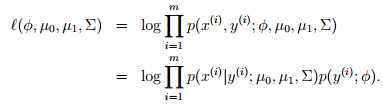
通过求解最大似然估计,我们得到各个参数的估计值(实际推导过程中,可以把样本分成1-k,k-m分别表示结果为0和1的结果,这样能够将复杂的表达式简单化,其中k=):
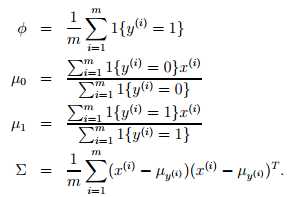
形象的来说,该算法可以表述如下:对于用于训练集合得到的两个高斯分布,他们具有相同的轮廓和等高线(因为方差矩阵相同),而均值不同。我们也可以看到决策边界p(y = 1|x) = 0.5,将两个类分开。
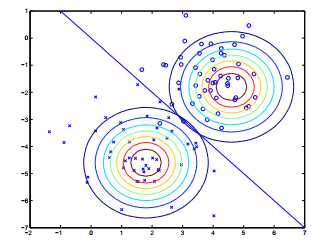
GDA模型和logistic回归模型具有相似的关系,即如果我们把概率质量p(y = 1|x; φ, μ0, μ1, Σ)看成是x的一个函数,那么我们可以用如下公式来表述:
p(y = 1|x; φ, μ0, μ1, Σ) =1 / (1 + exp(?θTx)
如果p(x|y)服从多元正态分布(且Σ相同),那么p(y|x)可以使用logistic函数。相反,如果p(y|x)是logistic函数,那么p(x|y)未必服从多元正态分布。这说明GDA比logistic对数据集的假设要求更强。特别的,如果p(x|y)服从多元正态分布(且Σ相同),那么采用GDA将是渐进有效(asymptotically efficient)的。通俗的讲,就是随着样本量的增加,分类精度将会增加。换句话说,如果样本量足够大的话,那么没有任何方法能够比GDA更准确的描述p(y|x)。此外,即使数据集较小,我们也认为GDA模型更优于logistic 回归。
如果对数据集有较弱的假设,那么logistic回归鲁棒性(robust)更强,而且对不正确的数据分布假设也不会过于敏感。总结的说,GDA有更强的模型假设,对于服从模型假设或近似于假设的数据而言,GDA更依赖于数据的有效性。而logistic回归具有较弱的模型假设,而且对于模型假设偏差鲁棒性更好。此外,如果数据集分布不服从正态分布,那么logistic回归通常优于GDA。
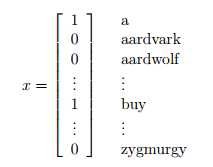
来表示一封邮件的特征,即邮件中是否包含字典中的单词。然而,通常情况下,我们不使用字典(所有单词都用的话,特征太多),而是使用一定的方法从训练集合中找出合适的单词(有的时候需要使用停用词(stop words)或者tf-idf等方法来选择合适的特征)。对于x中的所有单词,我们称之为词汇表(vocabulary),特征属性的大小就是词汇表中词汇的个数。在得到我们的特征向量(feature vector)之后,我们开始构建生成学习算法。
假设我们有50000个单词,那么我们首先要构建p(x|y),其中x ∈ {0, 1}50000(x is a 50000维向量,值仅含0和1)。如果我们通过明确的分布来描述x(直接构建p(x|y)),那么我们需要250000个结果,即250000-1维向量的参数,将会有特别多的参数。为了方便p(x|y)建模,我们需要做出一个很强的假设:对于给定的y,xi 条件独立(conditionally independent即特征之间相互独立),该假设称之为朴素贝叶斯假设(Naive Bayes (NB) assumption),因此该模型又称之为朴素贝叶斯分类(Naive Bayes classifier)。举例子而言,对于给定的邮件比如垃圾邮件,那么特征单词buy是否出现并不影响特征单词price的出现。因此,有:
p(x1, . . . , x50000|y) = p(x1|y)p(x2|y, x1)p(x3|y, x1, x2) · · · p(x50000|y, x1, . . . , x49999)
= p(x1|y)p(x2|y)p(x3|y) · · · p(x50000|y) =
在第二步转换过程中,我们使用了NB假设。需要注意的是,即使贝叶斯有很强的假设要求,但是该方法在很多问题上(特征并非完全条件独立)仍然后较好的结果。
对于训练集合{(x(i), y(i)); i =1, . . . , m},我们的模型参数主要有
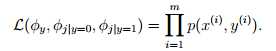
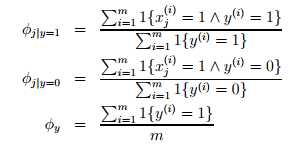
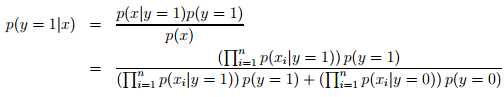
此外,我们也可以扩展NB模型。比如x=1,2,3…k,那么我们可以使用多项分布来替代伯努力分布。如果x是连续变量,可以将x离散化。当原始数据是连续型的,且不能很好的满足多元正态分布,此时采用离散化后,使用贝叶斯分类(相比于GDA),通常会有较好的结果。
对于很多问题,采用朴素贝叶斯方法都能够取得很好的结果,但是有些情况则需要对朴素贝叶斯分类进行一定的优化,尤其是在文本分类领域。接下来,我们讨论朴素贝叶斯方法在使用过程存在的缺陷,并探讨如何去优化。
仍然考虑垃圾邮件分类问题。比如在预测一封信邮件是否是垃圾邮件过程中,特征单词中的第3500个单词nips恰好在训练集合中从来没有出现,那么通过最大似然估计得到的φ35000|y如下:
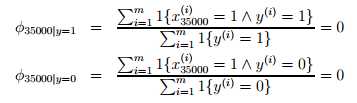
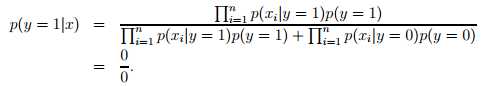
因为单词nips从来没有出现,因此垃圾邮件和非垃圾邮件的条件概率均为0,因此在计算是否是垃圾邮件的后验概率中,因为分子中存在一个0项,导致最终结果无法判断。
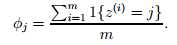
我们知道该方法存在一定缺陷,因此采用拉普拉斯平滑(Laplace smoothing)进行优化,即在分子中加1(即默认每一个值都已经出现过一次),考虑左右的频率和为1,因此分母加上k(k个值),如下:
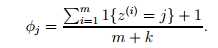
标签:orm image .com 决策 learn sub mat 估计 无法
原文地址:https://www.cnblogs.com/kexinxin/p/9904397.html