标签:最大的 成本 search 分割 出现 UNC 目标 数字 路径
顺序最小化算法
考虑这样一个问题,如果输入X是房子的面积,我们要使用回归方法预测房子的价格。从样本点的分布中,我们看到三次方程(即使用x,x2,x3进行回归曲线拟合)能够更好的拟合数据。为了区分这两组不同的变量(前者为x,后者为(x,x2,x3)),我们称问题的特征x为原始特征(attribute)。当我们把原始特征扩展到一些新的变量的时候,我们称这些新生成的变量为输入特征(features,当然,不同的人对这两种变量也存在不同的命名。但英文中主要采用attribute和feature进行区分)。我们使用φ 表示特征映射(feature mapping),即把原始特征映射到特征。对于刚才的例子,φ = [x,x2,x3]T.
考虑下面一个例子,x,z∈ Rn,K(x, z) = (xTz)2 ,对于该式,我们可以转换如下:
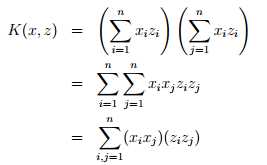
因此,我们看出K(x, z) = φ(x)Tφ(z) 中,特征映射φ 是(这里仅展示对于n=3的情况),φ = [ x1x1, x1x2, x1x3, x2x1, x2x2, x2x3, x3x1, x3x2, x3x3 ]T 。
这里注意的是,如果计算高维度φ(x)情况下的时间复杂度为O(n2),而实际K(x, z)只需要要计算原始特征的内积方法即可(上面推导的结果,时间复杂度为O(n))。
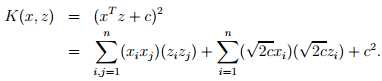
现在,我们采用一些不同的视角来看核函数。直观上来看,如果φ(x) φ(z)越接近,那么K(x, z) = φ(x)Tφ(z) 也会越大。相反,如果φ(x) φ(z)越分开,那么K(x, z)也会越小。因此,我们可以认为从某种程度上而言,表示了φ(x) φ(z)的相似性,或者说x和z的相似性。
鉴于该直观,假设现在正在解决一个机器学习问题,我们想到了一个核方法K(x,z),而该核方法能够合理的测量x和z的相似性。
举例子而言,K(x, z)= exp(-||x-z||2 / (2σ2)) 。这是一个合理的测量xz间的相似度,当x和z越相近的时候值越接近1,当x和z越分开的时候值越接近于0 。那么我们可以定义这样的K作为SVM中的一个核方法吗?当然,在这里例子中答案是肯定的(该核称之为高斯核(Gaussian kernel),又称为径向基函数(Radial Basis Function 简称RBF,它能够把原始特征映射到无穷维)。更广的说,给定一个函数K,我们如何判定是否是有效的核函数?即对于特征映射φ,是否使得所有的x, z均有K(x, z) = φ(x)Tφ(z)?
如果K是一个有效核,那么Kij = K(X(i),x(j)) =φ(X(i))Tφ(x(j)) =φ(,x(j))Tφ(,x(i)) = K(X(j),x(i)) = Kji 因此核矩阵K一定是对称的。此外,令φk(x) 表示向量φ(x)的第k个值,对于任意向量z,有如下:
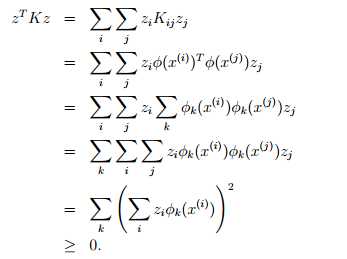
给定一个函数K,除了试图找到一个与之对应的特征映射φ外,该定理提供了另一种测试K是否是有效核的方法。
这里举一些核方法的例子。比如对于手写数字识别,输入是16*16的像素的手写数字0-9的图片,我们需要一个模型来判断一个图片上的数据是多少。采用简单的线性核函数K(x, z) = (xTz)d 或者高斯核,SVM在该问题上都能得到非常好的结果。这是一个非擦汗那个令人吃惊的结果,因为输入特征x是一个256维的向量(各个像素点的值),而系统并没有任何先验知识,甚至不知道哪个像素点和哪个点连在一起。另外一个例子是,我们试图分类的对象是字符串(比如说,x是一串氨基酸列表,可以组成蛋白质),对于很多学习算法而言,很难组成一个合理的特征集,尽管不同的字符串有不同的长度。然而,我们使用特征映射φ(x)为特征向量,表示x中长度为k的子字符的出现次数。如果我们英文字母组成的字符串,那么就会有26K个这样的子字符串。因此,φ(x)就是一个26K维度的向量,即使对于中等的k,这也是非常大的(264≈ 460000) 。可是,使用字符匹配算法,有效的计算K(x,z) =φ(x)T φ(z),使得我们能够在这么高维度特征空间下实现而不用直接的在高维度下计算。
此外,需要注意的事情是核方法不仅仅是在SVM中有着重要的地位。对于任何机器学习算法,你都可以把输入特征的内积<x,z>使用核方法改写成K(x,z),使得算法在高维度下也能很高效的工作。比如把核方法应用在感知器上得到一个核感知器算法。在以后降到的很多算法都会接受核方法。
为了使算法能够更好的适应非线性数据集和减少对异常值的敏感性,我们前的最优化式子做出一些改变(使用正则化? (regularization)):
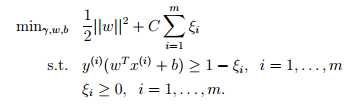
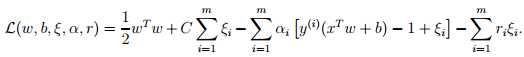
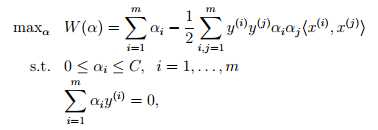
对比之前的公式,我们仍然有 w = ,之后解决了对偶问题之后,我们可以同样通过下式得到我们的预测结果。
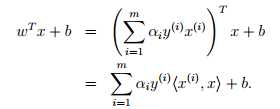
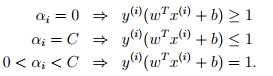
这里我们认为W只是αi 的函数,这里先不考虑这个问题和SVM有什么关系。我们目前已经掌握了两种优化算法:梯度下降法和牛顿法。这里我们使用新的算法,称之为坐标上升法。
αi = arg maxαi Max W(α1, α2, . . . , αm) }}
在该算法最里层的循环里,我们保持其他的变量(αj (j !=i))不变,仅更新αi,即认为W仅受αi 影响,而不受αj (j !=i) 的影响。该循环按照α1, α2, . . . , αm, α1, α2, . . . 的顺序不断的循环优化。当然,我们也可以按照自定义顺序去循环,比如按照下一个是能够使得W(α) 增长最大的变量。
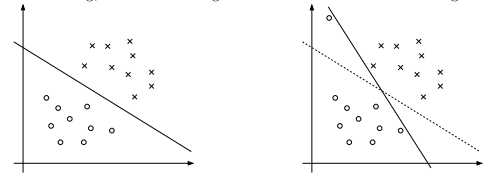
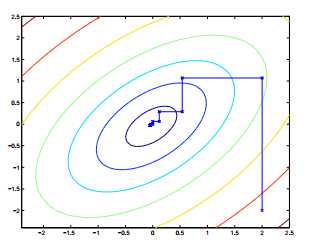
如果函数W能够在该循环中有效的得到最优解,那么坐标上升法将是一个相当有效的算法。下图是坐标上升的一个过程:途中椭圆是指我们要优化的二次函数的等高线。坐标上升法起始点在 (2,-2) ,图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
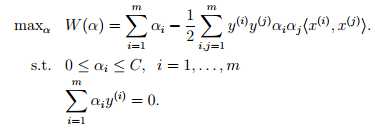
即需要解决的是在参数 { α1, α2, . . . , αm } 上求的最大值W的问题,其中x,y均是已知数,而C是由我们预先设定的,也是已知。
我们先假设αi 满足了上式优化问题的约束,根据坐标上升法,我们首先固定α2, . . . , αm 不变,然后在α1 上面求得W的极值,并更新α1 。但是,这个思路有问题,因为固定了α1以外的所有参数,那么根据 = 0 得到α1y(1) = - (这里的y(1) ∈ {?1, 1},(y(1))2= 1,因此可以直接移动到等式右边),即得到是一个α1固定值。
因此,如果我们想要更新αi的话,必须至少选择两个参数进行更新以满足约束条件。这就促生了SMO(Sequential Minimal Optimization)算法,主要步骤如下:
我们先认为αi满足约束条件满足为0 ≤ αi ≤C i=1, …, m和 = 0,这里先限制 α2,…, αm固定,现在需要有重新优化W(α1, α2,…αm),其中变量仅有α1和α2 ,根据约束条件,我们有α1y(1) + α2 y(2) = - 。该等式的右边是固定值,我们可以用 ζ 来表示,那么等式可以表示为α1y(1) + α2 y(2) =ζ 。当y(1)和y(2)异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线,斜率为1。之后,我们可以用下图来表示在α1 和 α2上的约束关系。
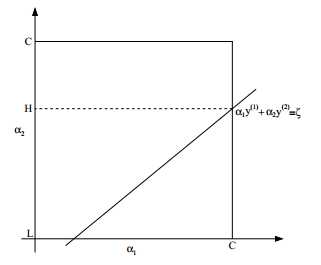
从约束条件看,α1和α2一定在正方形[0, C]×[0, C]里面,且一定在图中直线α1y(1) + α2 y(2) =ζ 上。从中我们可以得到:L ≤ α2 ≤ H;否则(α1, α2) 就不能同时满足正方形和直线约束。这个例子中L=0,不过这取决于直线的位置,不同的位置L和H值不一样,即会存在一个较大的值H和较小的值L。我们将α1用α2 表示:α1= ( ζ - α2 y(2)) y(1)。因此,W(α) 可以表示如下:W (α1, α2, . . . , αm) = W ((ζ ? α2y(2))y(1), α2, . . . , αm)。
固定 α3, . . . , αm不变,之后w就只是关于α2的函数,即可以表示为aα22+bα2+c。如果我们忽略正方形的边界约束(即L ≤ α2 ≤ H),可以很容易通过导数为0求得最大化W的α2 值。我们使用α2new,unclipped 表示最终的α2结果。如果考虑了边界的话,那么结果如下:
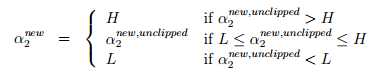
在得到α2new之后,可以很容易得到α1new。以下是关于Platt的论文http://research.microsoft.com/en-us/um/people/jplatt/smo-book.pdf。也可以参考斯坦福的笔记http://cs229.stanford.edu/materials/smo.pdf。
标签:最大的 成本 search 分割 出现 UNC 目标 数字 路径
原文地址:https://www.cnblogs.com/kexinxin/p/9904416.html