标签:优化 lines color 历史 工程师 course ssi 设立 resid

作者: Enoch Kan
编译: Mika
本文为 CDA 数据分析师原创作品,转载需授权
几十年来,研究人员和开发人员一直在争论,进行数据科学和数据分析,Python和R语言哪种才是更好的选择。近年来,数据科学在生物技术、金融和社交媒体等多个行业迅速发展。数据科学的重要性不仅得到了业内人士的认可,而且还得到了许多学术机构的认可,目前越来越多的学校都开始设立数据科学学位。
随着开源技术的迅速取代了传统的闭源技术,Python和R语言在数据科学中变得越来越受欢迎。
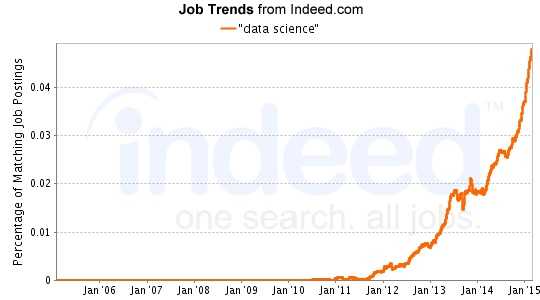
数据科学就业增长图——Indeed.com
1. 简介
Python由Guido van Rossum发明,于1991年首次发布。Python 2.0于2000年发布,8年后Python 3.0发布。Python 3.0有一些主要的语法修正,与Python 2.0不兼容。但是,2to3等Python库可以在两个版本之间自动的转换。Python 2.0计划在2020年停止使用。
R语言由Ross Ihaka和Robert Gentleman于1995年发明。R语言最初是由S语言的一种实现,后者由John Chambers于1976年发明。R语言首个稳定的测试版本1.0.0于2000年发布。目前,由R开发核心团队维护,最新的稳定版本为3.5.1。与Python不同,R在过去没有需要语法转化的重大变化。

Guido van Rossum (左) Ross Ihaka (中) Robert Gentleman (右)
Python和R都拥有庞大的用户群体支持。根据Stack Overflow在2017年的调查显示,近45%的数据科学家使用Python作为主要的编程语言。另一方面,11.2%的数据科学家使用R语言。
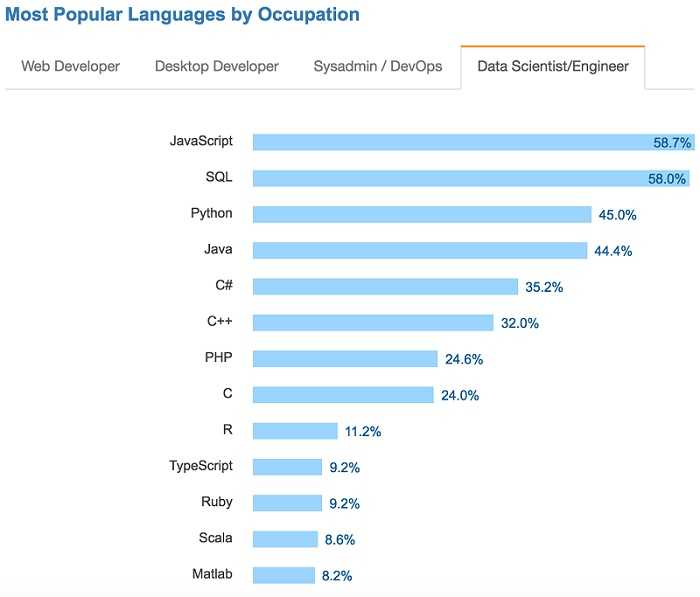
2017年开发者调查报告——Stack Overflow
值得注意的是,关于Python,特别是Jupyter Notebook在近年来备受追捧。虽然Jupyter Notebook可以用于Python之外的语言,但它主要用于在浏览器中记录和展示Python程序,用于Kaggle等数据科学竞赛。根据Ben Frederickson进行的一项调查显示,Jupyter Notebook在Github上的月活跃用户(MAU)的占比在2015年后大幅上升。
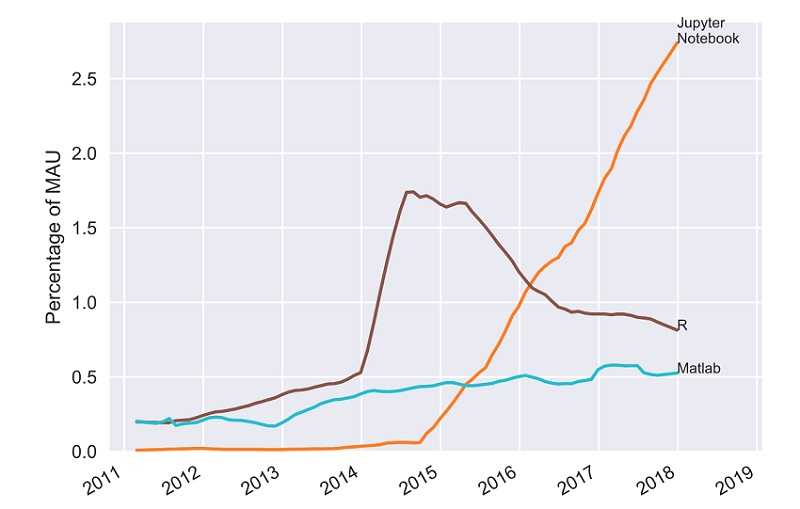
GitHub用户对编程语言的排名——Ben Frederickson
随着近年来Python越来越受欢迎,我们观察到在Github上使用R语言的月活跃用户比例有所下降。
尽管如此,这两种语言在数据科学家、工程师和分析师中仍然非常受欢迎。
2. 可用性
R最初用于研究和学术领域,如今它已不仅仅是一种统计语言。R可以从CRAN(Comprehensive R Archive Network)上轻松下载。CRAN还可用作包管理器,可以下载超过1万多个包。R Studio等流行的开源集成开发环境(IDE)都可以用来运行R语言。
作为统计学专业的人,我承认在Stack Overflow上R语言有非常强大的用户群体。在本科学习期间,我遇到的许多R相关问题都可以在=Stack Overflow的R语言标签找到答案。如果你刚开始学习R语言,Coursera等在线课程上都有提供R以及Python的初级课程。
在本地计算机上设置Python工程环境也很容易。事实上,最近Mac 上安装了内置的Python 2.7以及几个有用的库。如果你像我一样是Mac用户,我推荐你看Brian Torres-Gil的相关指南:
Definitive Guide to Python on Mac OSX https://medium.com/@briantorresgil/definitive-guide-to-python-on-mac-osx-65acd8d969d0
你还可以在Python的官网下载PyPI和Anaconda等开源Python包管理系统。同样,Anaconda也支持R语言。 当然,大多数人更喜欢直接使用CRAN管理包。比起R语言,PyPI或Python通常有更多的包。但是,并不是每个都适用于统计和数据分析。
3. 可视化
Python和R都具有出色的可视化库。由R Studio的首席科学家Hadley Wickham创建的ggplot2 如今是R历史上最受欢迎的数据可视化软件包之一。我非常喜欢ggplot2的各种功能和自定义。与基础的R图形相比,ggplot2允许用户在更高的抽象级别自定义绘图组件。ggplot2提供的50多种图像适用于各种行业,我最喜欢的图包括日历热图,层次树图和集群图。关于如何使用ggplot2,Selva Prabhakaran有很棒的教程可供参考。
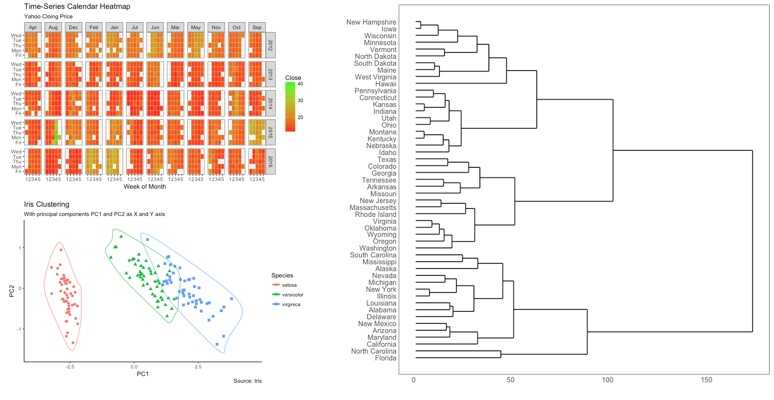
ggplot2中的日历热图(左上角)、集群图(左下)和层次树图(右下)
Python也有出色的数据可视化库。Matplotlib及其seaborn扩展对可视化和生成统计图很有帮助。我推荐你查看George Seif的相关可视化文章,以便更好地理解Matplotlib。
与R的ggplot2类似,matplotlib能够创建各种各样的图,比如直方图、向量场流线图、雷达图等。Matplotlib最出色功能之一可能就是地形山体阴影效果,在我看来它比R raster的`hillShade()`功能更强大。
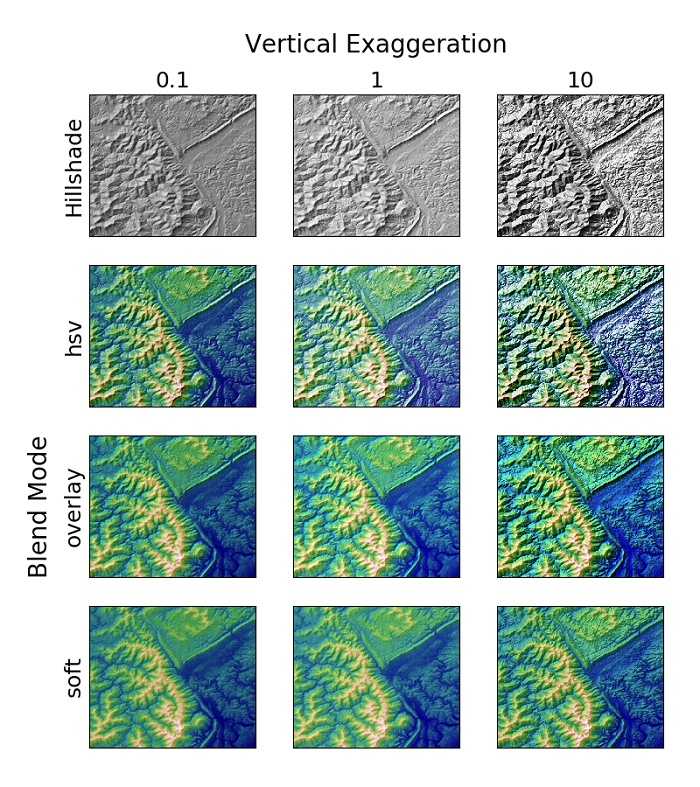
Matplotlib的山体阴影效果
R和Python都有Leaflet.js的包装, Leaflet.js是用Javascript编写的交互式地图模块。Leaflet.js是我用过最好的开源GIS技术之一,因为它提供了与OpenStreetMaps和Google Maps的无缝集成。你还可以使用Leaflet.js轻松创建气泡图、热图和等值线图。我强烈建议你试试绝对Python和R的Leaflet.js的包装,与Basemap和其他GIS库相比,这个更容易安装。
Plotly对于Python和R都是很棒的图形库。Plotly(或Plot.ly)是用Python和Django框架构建的。它的前端是用JavaScript构建的,并集成了Python、R、MATLAB、Perl、Julia、Arduino和REST。如果你想构建web应用来展示可视化,我建议你试试Plotly,因为它有带滑块和按钮的交互式图表。
使用鸢尾花数据集的Plotly相关图
4. 预测分析
Python和R都有强大的预测分析库。在高水平的预测建模中很难比较两者的表现。R语言是专门用作统计语言编写的,因此与Python相比,用R进行搜索与统计建模要更容易。
在谷歌中搜索`logistic regression in R`能得到6千万个结果,这是搜索`logistic regression in Python`的37倍。但是,具有软件工程背景的数据科学家使用Python更容易,因为毕竟R是由统计学家编写的。同时我还发现,与其他编程语言相比,R和Python同样易于理解。
对于Python和R哪个更适合进行预测分析,Kaggle用户NanoMathias进行了非常相识的调查。他得出结论,在数据科学家和分析师中,Python和R用户数量基本相同。他的研究中还发现,编程经验超过12年的人更倾向于选择R而不是Python。这表明程序员选择R或Python进行预测分析只不过是他们的个人喜好。
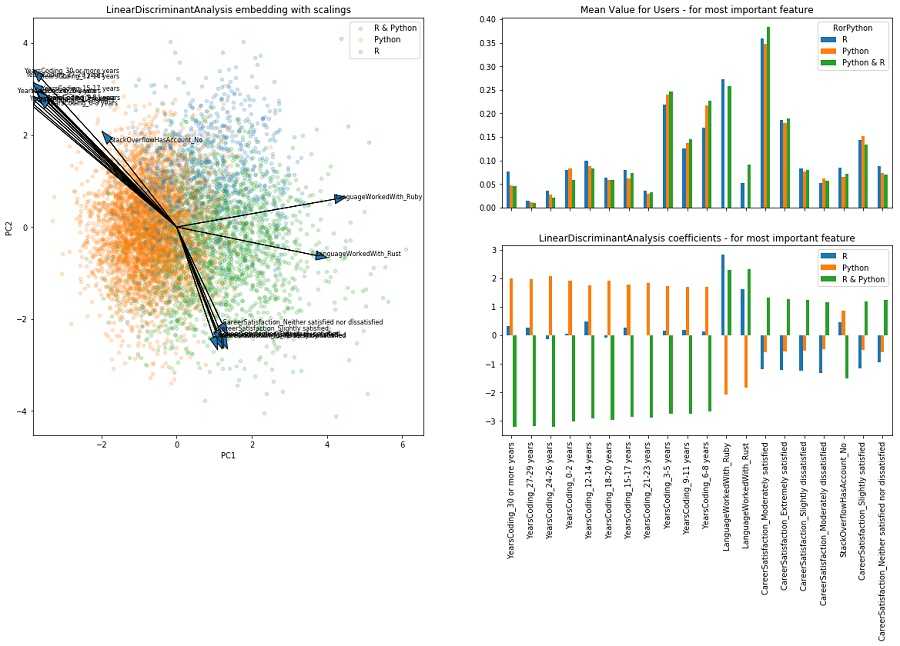
嵌入缩放的线性判别分析,R和Python用户
因此人们普遍认为这两种语言在预测方面能力相似。但真是如此吗?
让我们使用R和Python将逻辑回归模型拟合到鸢尾花数据集,并计算其预测的准确性。之所以选择鸢尾花数据集是因为它体积小,数据缺失少。在此我没有进行探索性数据分析和特征工程,我简单地做了80-20的训练测试的分割,用预测器来匹配逻辑回归模型。
```
library(datasets)
#load data
ir_data<- iris
head(ir_data)
#split data
ir_data<-ir_data[1:100,]
set.seed(100)
samp<-sample(1:100,80)
ir_train<-ir_data[samp,]
ir_test<-ir_data[-samp,]
#fit model
y<-ir_train$Species; x<-ir_train$Sepal.Length
glfit<-glm(y~x, family = ‘binomial‘)
newdata<- data.frame(x=ir_test$Sepal.Length)
#prediction
predicted_val<-predict(glfit, newdata, type="response")
prediction<-data.frame(ir_test$Sepal.Length, ir_test$Species,predicted_val, ifelse(predicted_val>0.5,‘versicolor‘,‘setosa‘))
#accuracy
sum(factor(prediction$ir_test.Species)==factor(prediction$ifelse.predicted_val...0.5...versicolor....setosa..))/length(predicted_val)
```

R的glm模型准确率达到95%,还不错。
```
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
#load data
traindf = pd.read_csv("~/data_directory/ir_train")
testdf = pd.read_csv("~/data_directory/ir_test")
x = traindf[‘Sepal.Length‘].values.reshape(-1,1)
y = traindf[‘Species‘]
x_test = testdf[‘Sepal.Length‘].values.reshape(-1,1)
y_test = testdf[‘Species‘]
#fit model
classifier = LogisticRegression(random_state=0)
classifier.fit(x,y)
#prediction
y_pred = classifier.predict(x_test)
#confusion matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print confusion_matrix
#accuracy
print classifier.score(x_test, y_test)
```

Python sklearn的逻辑回归模型准确率达到90%
使用R stat `glm`函数和Python scikit-learn的 `LogisticRegression` ,我将两个逻辑回归模型拟合到鸢尾花数据集的随机子集。在模型中,我们只使用了一个预测器`sepal length`来预测花朵种类 `species`。两种型号都达到了90%以上的精度,其中R语言的效果更好。然而,这不足以证明R具有比Python更好的预测模型,逻辑回归只是Python和R构建的众多预测模型中的一个。
Python超过R的一个方面是其出色的深度学习模块。流行的Python深度学习库包括Tensorflow、Theano和Keras,而且这些库有很多文本教程,同时Siraj Raval在Youtube上也发布了多个教程。
说实话,我宁愿花一个小时在Keras上对深度卷积神经网络进行编程,而不是花费半天时间来弄清楚如何在R中实现它们。同时Igor Bobriakov也有很多这方面的文章,我也推荐你去看看。
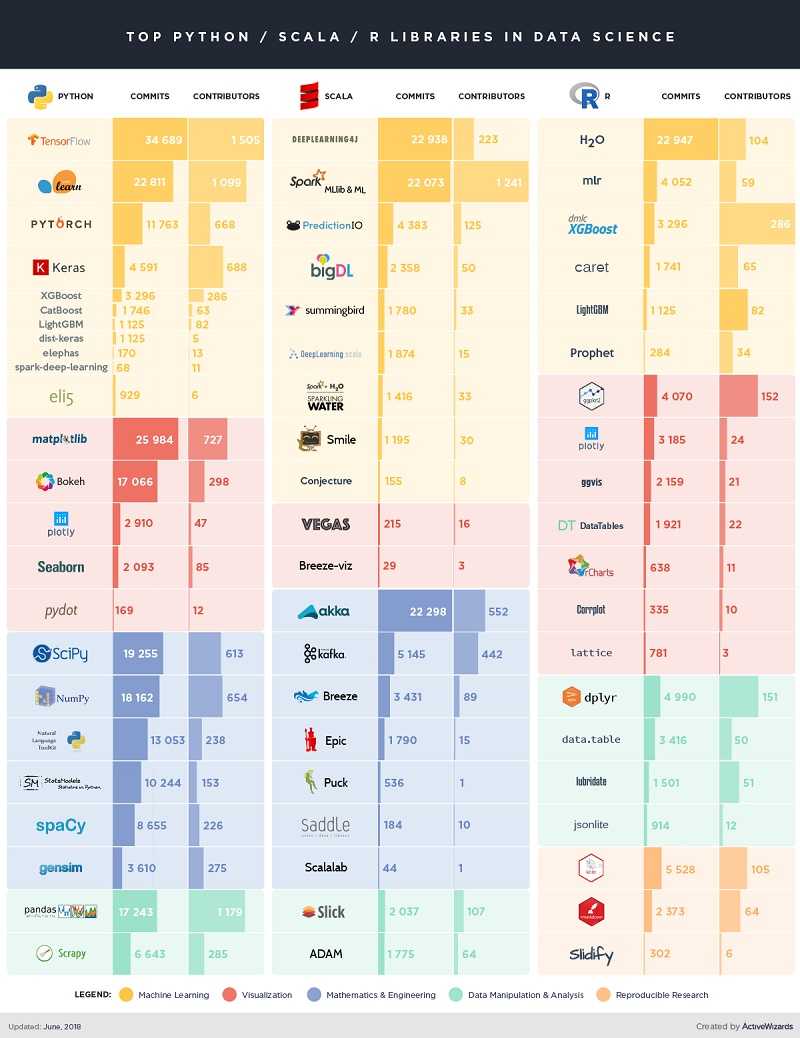
比较Python、R和Scala的顶级数据科学库——Igor Bobriakov
5. 性能
测量编程语言的速度通常会有些偏差。每种语言都有针对特定任务的内置优化插件(例如R语言对统计分析能进行优化)。可以通过多种不同方式完成对Python和R进行性能测试。我在Python和R中编写了两个简单的脚本,用来比较Yelp的学术用户数据集的加载时间,该数据集略大于2GB。
R
```
require(RJSONIO)
start_time <- Sys.time()
json_file <- fromJSON("~/desktop/medium/rpycomparison/yelp-dataset/yelp_academic_dataset_user.json")
json_file <- lapply(json_file, function(x) {
x[sapply(x, is.null)] <- NA
unlist(x)
})
df<-as.data.frame(do.call("cbind", json_file))
end_time <- Sys.time()
end_time - start_time
#Time difference of 37.18632 secs
```
Python
```
import time
import pandas as pd
start = time.time()
y1 = pd.read_json(‘~/desktop/medium/rpycomparison/yelp-dataset/yelp_academic_dataset_user.json‘, lines = True)
end = time.time()
print("Time difference of " + str(end - start) + " seconds"
#Time difference of 169.13606596 seconds
```
R加载json文件几乎比Python快5倍。众所周知,Python的加载时间比R快,正如Brian Ray的测试所证明的那样。让我们看看两个程序如何处理大型.csv文件,因为.csv是一种常用的数据格式。我们稍微修改上面的代码来加载 Seattle Library Inventory 数据集,大小约为4.5GB。
Seattle Library Inventory数据集
https://www.kaggle.com/city-of-seattle/seattle-library-collection-inventory/version/15
R
```
start_time <- Sys.time()
df <- read.csv("~/desktop/medium/library-collection-inventory.csv")
end_time <- Sys.time()
end_time - start_time
#Time difference of 3.317888 mins
```
Python
```
import time
import pandas as pd
start = time.time()
y1 = pd.read_csv(‘~/desktop/medium/library-collection-inventory.csv‘)
end = time.time()
print("Time difference of " + str(end - start) + " seconds")
#Time difference of 92.6236419678 seconds
```
与Python 的pandas相比,R加载4.5GB的.csv文件的时间是前者的两倍。虽然pandas主要是用Python编写的,但是库中更关键的部分是用Cython和C语言编写的。这可能会对加载时间产生些影响,具体取决于数据格式。
下面让我们做一些有趣的事情。
Bootstrapping是一种从群体中随机重新采样的统计方法。这是一个耗时的过程,因为我们必须反复重新采样数据以进行多次迭代。以下代码分别测试R和Python中进行引导10万次bootstrapping所需的重复的运行时:
R
```
#generate data and set boostrap size
set.seed(999)
x <- 0:100
y <- 2*x + rnorm(101, 0, 10)
n <- 1e5
#model definition
fit.mod <- lm(y ~ x)
errors <- resid(fit.mod)
yhat <- fitted(fit.mod)
#bootstrap
boot <- function(n){
b1 <- numeric(n)
b1[1] <- coef(fit.mod)[2]
for(i in 2:n){
resid_boot <- sample(errors, replace=F)
yboot <- yhat + resid_boot
model_boot <- lm(yboot ~ x)
b1[i] <- coef(model_boot)[2]
}
return(b1)
}
start_time <- Sys.time()
boot(n)
end_time <- Sys.time()
#output time
end_time - start_time
#Time difference of 1.116677 mins
```
Python
```
import numpy as np
import statsmodels.api as sm
import time
#generate data and set bootstrap size
x = np.arange(0, 101)
y = 2*x + np.random.normal(0, 10, 101)
n = 100000
X = sm.add_constant(x, prepend=False)
#model definition
fitmod = sm.OLS(y, X)
results = fitmod.fit()
resid = results.resid
yhat = results.fittedvalues
#bootstrap
b1 = np.zeros((n))
b1[0] = results.params[0]
start = time.time()
for i in np.arange(1, 100000):
resid_boot = np.random.permutation(resid)
yboot = yhat + resid_boot
model_boot = sm.OLS(yboot, X)
resultsboot = model_boot.fit()
b1[i] = resultsboot.params[0]
end = time.time()
#output time
print("Time difference of " + str(end - start) + " seconds")
#Time difference of 29.486082077 seconds
```
R花了几乎两倍的时间来运行bootstrap。鉴于Python通常被视为“慢”编程语言,这是相当令人惊讶的。我开始后悔在完成本科统计学作业时使用R语言而不是Python。

结论
本文仅讨论了Python和R之间的根本区别。就个人而言,我会根据手头的任务选择使用Python或R语言。最近,数据科学家一直在努力将Python和R 结合使用。在不久的将来,很有可能会出现第三种语言,并最终比Python和R更受到欢迎。作为数据科学家和工程师,我们有责任跟上最新技术并保持创新。
那么你又更喜欢Python还是R语言呢?请给我们留言吧!!
标签:优化 lines color 历史 工程师 course ssi 设立 resid
原文地址:https://www.cnblogs.com/CDA-JG/p/9909231.html