标签:with rect orm 进制 透明 join temp minimal 报警系统
目录:select * 这样的查询。
隔离性:要求一个事务对数据库的修改,在未完成提交之前对于其他事务是不可见的。
使用传统机械硬盘
使用RAID卡+传统机械硬盘
主要的RAID级别:
如何选择RAID级别:
| 等级 | 特点 | 是否冗余 | 盘数 | 读取 | 写入 |
|---|---|---|---|---|---|
| RAID0 | 便宜快速危险 | 否 | N | 快 | 快 |
| RAID1 | 高速读简单安全 | 有 | 2 | 快 | 慢 |
| RAID5 | 安全成本折中 | 有 | N+1 | 快 | 取决于最慢的硬盘 |
| RAID10 | 昂贵高速安全 | 有 | 2N | 快 | 快 |
使用SSD和PCIe卡
SSD(固态硬盘):
固态存储PCIe技术:
固态存储的使用场景:
使用网络存储NAS或SAN
网络存储的使用场景:
内核相关参数:/etc/sysctl.conf
net.core.somaxconn=65535
net.core.netdev_max_backlog=65535
net.ipv4.tcp_max_syn_backlog=65535
net.ipv4.tcp_fin_timeout=10
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=1
net.core.wmem_default=87380
net.core.wmem_max=16777216
net.core.rmem_default=87380
net.core.rmem_max=16777216
net.ipv4.tcp_keepalive_time=120
net.ipv4.tcp_keepalive_intvl=30
net.ipv4.tcp_keepalive_probes=3
kernel.shmmax=4294967295 # 用于定义单个共享内存段的最大值,
# 这个参数应该设置的足够大, 以便能在一个共享内存段中容纳下整个InnoDB缓冲池
# 对于x64的系统, 可取的最大值为物理内存的大小减去1字节,建议值为大于物理内存的一半
vm.swappiness=0 # 该参数当内存不足时对性能产生比较明显的影响, 设置内存交换区大小
# 0表示除非Linux内核非虚拟内存完全满了, 否则就不使用交换区
资源限制:/etc/security/limit.conf
该文件是Linux PAM,也就是插入式认证模块的配置文件, 打开文件数的限制。参数:
磁盘调度策略:/sys/block/devname/queue/scheduler
默认是使用cfq策略
noop(电梯式调度策略), 实现了一个FIFO队列, 像电梯一样对IO请求进行组织, 当有一个新的请求到来时, 将会合并到最近的请求之后
以此来保证同一请求同一个介质。noop倾向饿死读而利于写, 一次noop对于闪存设备,RAM,嵌入式系统是最好的选择。
deadline(截止时间调度策略)确保在一个时间内服务请求, 这个截止时间是可以调整的, 而默认读期限短于写期限。
这样就会防止写操作因为不能被读取而饿死的现象, deadline对数据库类应用是最好的选择。
anticipatory(预料IO调度策略)本质上与deadline一样, 但是最后一个读操作后要等待6毫秒才能继续进行其他的IO请求进行调度。
写入流合并成为一个大的写入流, 用写入延时换区最大的写入吞吐量, 这种策略适合于写入较多的环境,比如文件服务器,该策略对数据环境表现较差
## 5. 文件系统对性能的影响
* 文件系统的选择依赖于操作系统,实际上Windows只有一种文件系统——NTFS
* Linux系统支持EXT3、EXT4、XFS等,但是XFS性能更高
* EXT3/4系统的挂载参数:
```html
配置文件:/etc/fstab
data=writeback|ordered|journal
wirteback对于InnoDB引擎来说是最好的
noatime和nodiratime用来禁止记录时间Mysql存储引擎层:改成定义了一堆接口,用户可以开发第三方引擎。存储引擎是针对于表的而不是库的。
MyISAM存储引擎
frm文件用来记录表结构
特性:
myisampack -b -f xxx.MYI进行压缩。MAX_Rows和AVG_ROW_LENGTH参数。InnoDB存储引擎
InnoDB有自己的表空间:
innodb_file_per_file。TableName.ibd。ibdataN,N表示一个数字。系统表空间和独立表空间如何选择?
innodb_file_per_file默认是off。如何将系统表空间转换为独立表空间?
mysqldump导出所有数据, 存储过程/触发器/视图也要导出。什么是锁?
查看InnoDB状态检查:
show engine innodb status;
CSV存储引擎
Archive存储引擎
Memory存储引擎
max_heap_table_size参数决定, 对于已经存在的数据表是不生效的。create temporary table来创建。Federated存储引擎
engine=federated connection=‘mysql://UserName[:PassWord]@HostName[:PortName]/DBName/TableName‘;MariaDB [(none)]> show engines;
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Percona-XtraDB, Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| FEDERATED | YES | FederatedX pluggable storage engine | YES | NO | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| Aria | YES | Crash-safe tables with MyISAM heritage | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
10 rows in set (0.00 sec)Mysql获取配置信息路径
mysqld_safe --datadir=/data/sql_data。mysqld --help --verbose | grep -A 1 ‘Default options‘ /etc/my.cnfMysql配置参数的作用域
set global 参数名=参数值;和set @@global.参数名 := 参数值;set [session] 参数名=参数值;和set @@session.参数名=参数值;内存相关的配置参数(需要时才会分配,而且是为每个线程分配的)
sort_buffer_size设置排序需要的内存。join_buffer_size设置连接缓冲区的内存。read_buffer_size设置全表扫描时需要的内存大小。read_rnd_buffer_size设置索引缓冲区的大小。innodb_buffer_pool_size定义了InnoDB缓存池的大小。key_buffer_size是为MyISAM缓存池设置大小的,该引擎只会缓存索引,数据还会依赖于操作系统的缓存select sum(index_length) from information_schema.tables where engine=‘myisam‘;IO相关的配置参数
InnoDB存储引擎:
innodb_log_file_size控制事务日志的大小。innodb_log_files_in_groups控制事务日志的个数。innodb_log_file_size x innodb_log_files_in_groups。innodb_log_buffer_size控制日志缓存区的大小。innodb_flush_log_at_trx_commit控制刷新日志缓冲区的频率:
innodb_flush_method=O_DIRECT,对于Linux系统建议使用该选项,避免操作系统和InnoDB都对数据进行缓存。innodb_file_per_table=1, 控制InnoDB的表空间。innodb_doublewrite=1, 控制是否使用双写缓存,启用后稍微影响性能,但是安全性提高。MyISAN存储引擎:
delay_key_write:
安全相关参数配置:
expire_logs_days指定自动清理binlog的天数。max_allowed_packet控制Mysql可以接受的包大小。skip_name_resolve禁用DNS查找。sysdate_is_now确保sysdate()函数返回确定性日期。read_only禁止非super权限的用户写入权限。skip_slave_start禁用slave自动恢复。sql_mode设置Mysql所使用的SQL模式,默认很宽松的。
strict_trans_tablesno_engine_subtitutionno_size_dateno_zero_in_dateonly_full_group_by其他常用参数
sync_binlog控制Mysql如何向磁盘刷新binlog,默认使用操作系统刷新策略。tmp_table_size和max_heap_table_size控制内存临时表大小。max_connections控制允许的最大连接数, 通常设置为2000。数据库的结构和SQL优化(影响最大)
总体优化步骤:
对整个系统进行测试:
对Mysql进行基准测试:
mysqlslap,在Mysql5.1之后自带的工具
--auto-generate-sql,由系统自动生成SQL脚本进行测试。--auto-generate-sql-add-autoincrement在生成的表中增加自增ID。--auto-generate-sql-load-type指定测试找那个使用的查询类型。--auto-generate-sql-write-number指定初始化数据时生成的数据量。--concurrency指定并发线程的数量,逗号分隔多个并发。--engine指定测试表的存储引擎,逗号分隔多个引擎。--no-drop指定不清理测试数据。--iterations指定测试运行的次数。--number-of-queries指定每一个线程的查询数量。--debug-info指定输出额外的内存及CPU统计信息。--number-int-cols指定测试表中INT类型列的数量。--number-char-cols指定测试表中CHAR类型列的数量。--create-schema指定用于执行测试的数据库的名字。--query用于自定义SQL的脚本。only-print并不运行测试脚本,而是把生成的脚本打印出来。sysbench
安装:
./autogen.sh脚本./configure --with-mysql-includes=/usr/local/mysql/include --with-mysql-libs=/usr/local/mysql/libmake && make install常用参数:
--test用于指定所要执行的测试类型:
--mysql-db用于指定基准测试的数据库名。--mysql-table-engine用于指定所使用的存储引擎。--oltp-tables-count执行测试的表的数量。--oltp-table-size指定每个表中的数据行数。--num-threads指定测试的并发线程数量。--max-time指定最大测试时间。--report-interval指定间隔多长时间输出一次统计信息。--mysql-user指定执行测试的Mysql用户。--mysql-password指定执行测试的Mysql用户的密码。prepare用于准备测试数据。run用于实际进行测试。cleanup用于清理测试数据。第一范式:
第三范式:
范式化的优点:
范式化的缺点:
定义表的命名规范
选择合适的存储引擎
| 存储引擎 | 事务支持 | 锁粒度 | 主要应用 | 缺点 |
|---|---|---|---|---|
| MyISAM | 不支持 | 支持并发插入的表级锁 | 查询、插入 | 读写频繁的操作 |
| MRG_MYISAM | 不支持 | 支持并发插入的表级锁 | 分段归档、数据仓库 | 全局查找过多的场景 |
| InnoDB | 支持 | 支持MVCC的行级锁 | 事务处理 | 无 |
| Archive | 不支持 | 行级锁 | 日志记录、只支持插入、查询 | 需要随机读取、更新、删除 |
| Ndb Cluster | 支持 | 行级锁 | 高可用性 | 大部分应用 |
字段数据类型的选择
实现在不同服务器上数据分布
实现数据读取的负载均衡
增加数据安全性
Mysql服务层日志
Mysql存储引擎层日志
在binlog中记录的日志都是成功执行过的日志。
二进制日志的记录格式
如果同一条SQL对N条数据进行修改,基于段的日志之后记录1条,基于行的会记录N条。
SBR 基于段的格式binlog_format=SATEMENT(Mysql5.7之前默认使用的格式)
RBR 基于行的日志格式binlog_format=ROW
binlog_row_image=[FULL|MINIMAL|NOBLOB]SBR+RBR 混合日志格式binlog_format=MINED
binlog_row_image=MINIMAL根据复制日志的方式可以分为:
基于日志点的复制
create user ‘repl‘@‘IP地址段‘ identified by ‘密码‘;。grant replication slave on *.* to ‘repl‘@‘IP地址段‘;。bin_log=存储目录。server_id=100。bin_log=存储目录。server_id=101。relay_log=存储目录。log_slave_update=on可选。read_only=on可选。change master to master_host=‘主服务器IP地址‘, master_password=‘主服务器密码‘, master_log_file=‘主服务器日志文件名称‘, master_log_pos=偏移量;。bin_log=存储目录。server_id=100。gtid_mode=on。enforce-gtid-console和log-slave-updates=on。server_id=101。relay_log=存储目录。gtid_mode=on和enforce-gtid-consistency。log-slave-updates=on建议。read_only=on建议。master_info_repository=表名建议。relay_log_info_repository=表名建议。change master to master_host=‘主服务器IP地址‘, master_password=‘主服务器密码‘ , master_auto_position=偏移量;。基于日志点复制的优缺点:
基于GTID复制的优缺点:
一主多从复制拓扑
主主复制拓扑(主备方式和主主方式)
主主方式注意事项:
auto_increment_increment=2 // 控制自增列ID步长和auto_increment_offest=1|2 // 控制自增列ID起始数值,一台为1,一台为2server_id。log_slave_updates参数。read_only参数。set binlog_row_image=minimal;stop slave;
set global slave_parallel_type=‘logical_clock‘;
set global slave_parallel_workers=4;
start slave;server_id和server_uuid, 比如多个从库使用相同的server_uuid问题max_allow_packet设置引起的主从复制错误高可用是指通过尽量缩短因为日常维护(计划)或者是突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。
通常使用服务器正常可用的时间和全年时间产生的百分比来表示高可用程度。
造成不可用的常见因素:
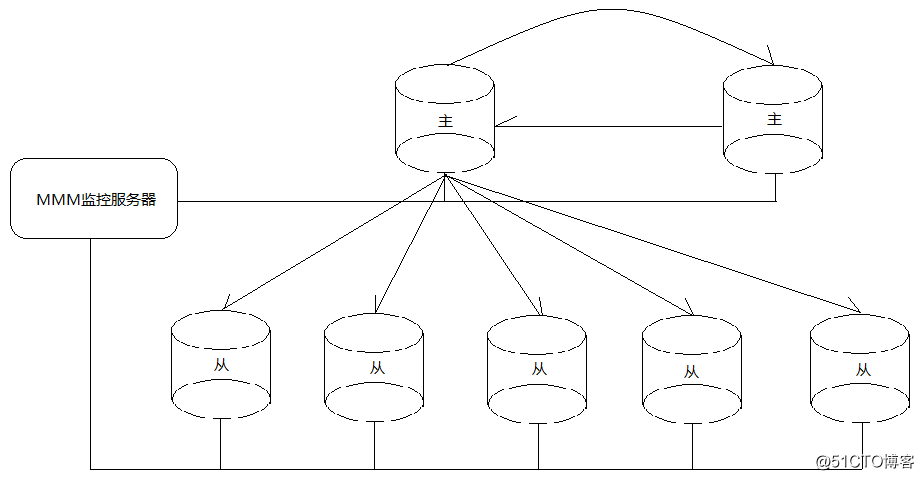
方式:
mysql-proxy(高并发情况下可能会崩溃)或maxScale(由MariaDB公司提供)。中间件可以根据SQL的语法分析出世读操作还是写操作来实现负载均衡,但是存储过程等并不能分析出来。使用中间件对程序是透明的,程序不需要进行调整。数据库查询处理能力依赖于中间件。对延迟敏感业务无法自动在主库中执行。LVS、HAProxy、MaxScale,硬件可以使用F5。建立联合索引如何选择索引列的顺序?
覆盖索引,包含需要查询的所有行的值
无法使用覆盖索引的情况
使用索引扫描来优化排序
使用BTree索引模拟Hash索引优化查询
利用索引优化锁
删除重复和冗余的索引
analyze table 表名,InnoDB存储引擎执行该命令不会锁表只是粗略估算值。optimize table 表名,使用不当会导致锁表。slow_query_log。启动停止记录慢查询日志。slow_query_log_file。指定慢查询日志记录存储路径及文件。long_query_time。指定记录慢查询日志SQL执行时间的阈值。默认值为10秒。通常改为0.0001秒比较合适。log_queries_not_using_indexs。是否记录未使用索引的SQL。mysqldumpslow。pt-query-digest。information_schema数据库中的processlist表。服务器检查是否可以在查询缓存中命中该SQL,通过对大小写敏感的哈希查找实现的。
query_cache_type指定查询缓存是否可用。在一个比较繁忙的系统中建议关闭查询缓存。query_cache_size指定查询缓存的内存大小。query_cache_limit指定查询缓存可用存储的最大值。query_cache_wlock_invalidate指定数据表被锁定以后是否返回缓存中的数据。query_cache_min_res_init指定查询缓存分配的内存块最小单位。根据执行计划,调用存储引擎API来查询数据。
set profiling=1启动profile,这是一个session级别的设置show profiles来查看每一个查询所消耗总时间的信息show profile for query ID来查询第ID个阶段所消耗的时间information_schema引擎
update `setup_instruments` set enabled=‘YES‘, TIMED=‘YES‘ where name like ‘stage%‘;
update `setup_consumers` set enabled=‘YES‘ where name like ‘events%‘;pt-online-schema-change工具实现。not in和 <>查询auto_increment_increment的值等于分片的数量,auto_increment_offset设置为不同的值对数据库服务可用性进行监控
mysqladmin -umonitor_user -p -h ping来确认是否可以建立网络连接telnet ip db_port来确认是否可以建立网络连接read_only来确认是否可以读写对数据库性能进行监控
show variables like ‘max_connections‘;获取最大连接值show global status like ‘Threads_connected‘;获取已经连接的线程数对主从复制进行监控
show slave status;来判断Slave_IO_Running和Slave_SQL_Running监控主从复制链路的状态。Seconds_Bebind_Master,但是数据不是特别准确。pt-table-checker来验证主从复制的数据是否一致。标签:with rect orm 进制 透明 join temp minimal 报警系统
原文地址:http://blog.51cto.com/xvjunjie/2314152