标签:where 可视化 指针 目的 -- 逻辑 drop 存储过程 字符
1.存储过程

1.1体会封装
(1)创建一个存储过程
create PROCEDURE p1() -- 声明一个存储过程,begin和end之间就是sql语句的集合。 BEGIN insert into goods VALUES(null, ‘why‘, ‘50‘); select * from goods; END
(2)调用存储过程,之后想要使用begin和end之间的sql语句,就可以像调函数一样使用
-- 调用存储过程,执行了创建存储过程时begin和end之间的语句 call p1();
1.2体会参数
(1)
-- 三个参数类型 -- in 表示参数只能传进来,输入型参数 -- out 表示输出型参数 -- inout 表示输入输出型参数 -- 默认不给参数参数类型则是in输入型参数 create PROCEDURE p2(in i int, inout names VARCHAR(50)) -- 声明一个存储过程,带参数的,in表示输入型参数,i为参数名,int为i这个参数的数据类型 BEGIN -- 参数2:inout表示输入输出型参数,names是参数名,varchar(50)表示names这个参数的数据类型是字符串格式的长度最长为50 update goods set name = names where id = i; select names; -- 查询看一下names这个变量的值
select name into names from goods where id = 1; -- into的意思是将查询出来的name值赋值给names这个变量
END set @names = ‘大鹅‘; -- 定义一个变量names,赋值为大鹅,目的是给下面的调用用 call p2(4, @names); -- 调用p2这个存储过程,因为第二个参数是inout输入输出型参数,所以一定要进来一个之前被set过的变量,并加@,其实就像C语言中的指针。 select @names; -- 查看一下这个names参数被带出来的值 大鹅

(2)into关键字只能将查询出来的一个值赋值给一个变量,不能查询出来多个赋值给多个变量
1.3体会控制
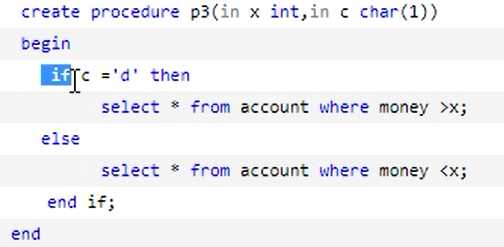
-- 如果flag为true则查询goods表中比nums小商品记录 -- 如果flag为false则查询goods表中比nums大的商品记录 -- if 条件结束后要加end if,判断是否相等要用=号而不是== create PROCEDURE p(int flag char(5), in nums int) BEGIN if flag = ‘true‘ THEN select * from goods where num < nums; ELSEIF flag = ‘false‘ THEN select * from goods where num > nums; ELSE select * from goods; end if; END call p(‘true‘, 20);
1.4 体会循环,使用存储过程做1 ~ 100的累加和
create PROCEDURE p4(in count int, out result_sum int) BEGIN declare i int DEFAULT 0; -- 使用declare声明一个变量i,默认值是0 DECLARE sum int; set sum = 0; -- 使用set设置sum这个变量的值为0 while i <= count DO set sum = sum + i; set i = i + 1; end WHILE; set result_sum = sum; -- 设置result_sum = sum END set he = 0; call p4(100, @he); select @he;
1.5查看和删除存储过程
show PROCEDURE status; -- 查看当前创建的存储过程 drop PROCEDURE p4; -- 删除p4存储过程
如果存储过程写错了,在命令行下只能删除这个存储过程,然后在重新创建一个来达到修改的目的。如果是在Navicat for mysql可视化ide中,则可以在函数中,设计函数来改存储过程的逻辑代码。



存储过程建议sql语句在几百行左右才会用,并且跟账目相关的特别严谨的才会用到存储过程,普通的项目应该是用不到
标签:where 可视化 指针 目的 -- 逻辑 drop 存储过程 字符
原文地址:https://www.cnblogs.com/whylinux/p/9925727.html