标签:内存缓存 sharding sch splay weight cat ase acid 大数
先在服务器上创建三个数据库
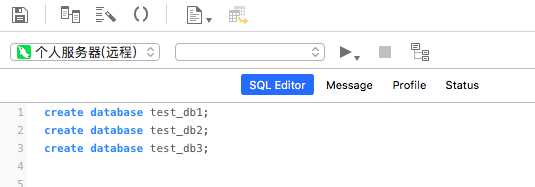

create database test_db1; create database test_db2; create database test_db3;
然后将配置 上面创建的三个库为 mycat 的数据源
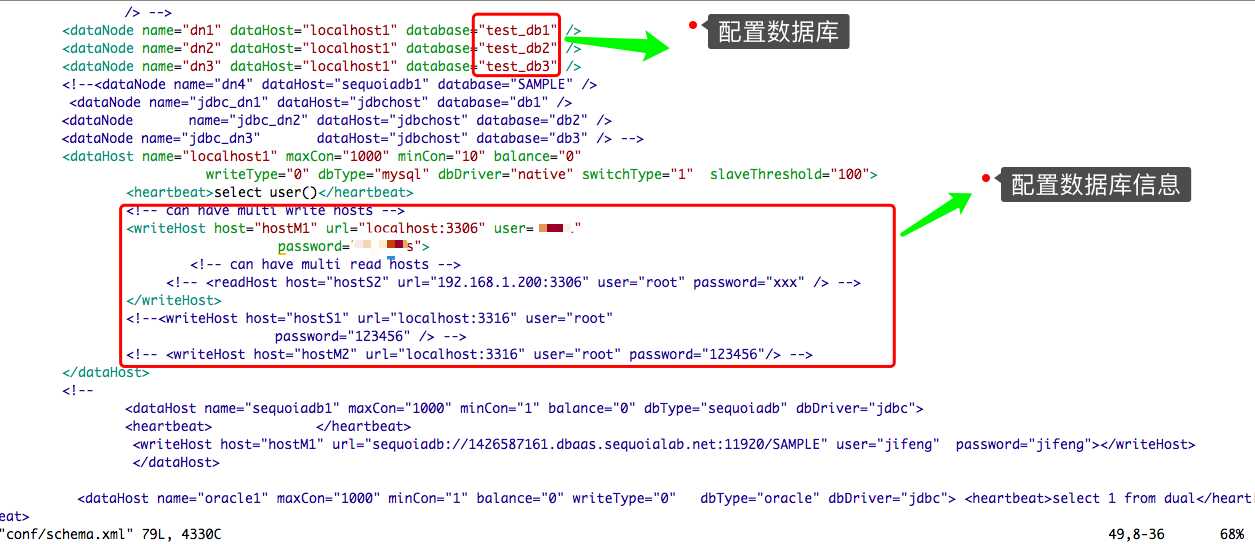
conf/schema.xml 设置 user 表 , 数据节点分别为上面设置的 dn1,dn2,dn3, 分片规则为id根据 auto-sharding-long 的规则划分到某个数据节点
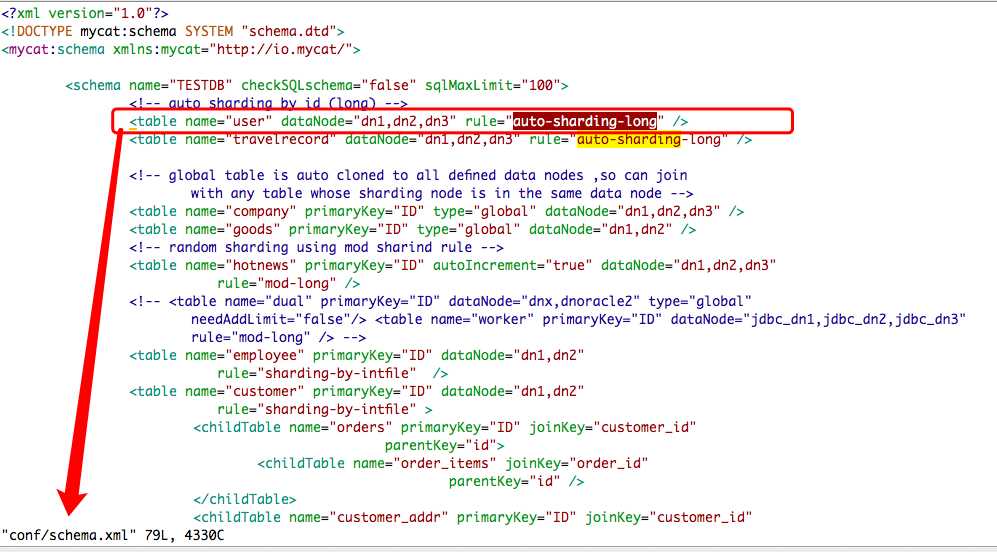
在 conf/rule.xml 中找到 auto-sharding-long 的规则

接着在此文件中搜索 rang-long 会查到规则存放在 autopartition-long.txt
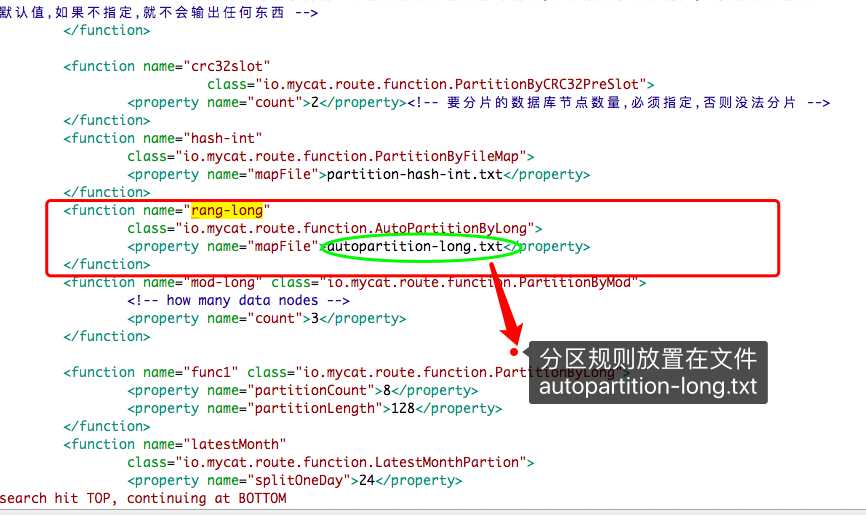
conf/autopartition-long.txt (每个分区存500万条)
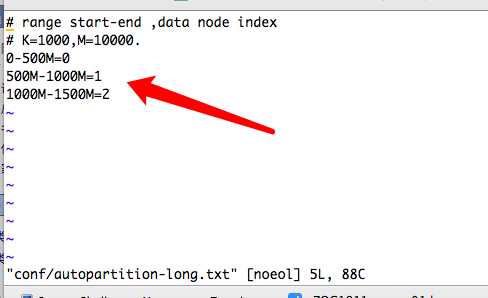
解析为:
id 1 - 5000000 时,放入数据节点索引0
id 5000001 - 10000000 时,放入数据节点索引1
id 1000001 - 15000000 时,放入数据节点索引2
*** 如果插入的数据超过 1500万条时,就需要扩容了,再加个节点 ,依次类推
启动 mycat:

测试 mycat:
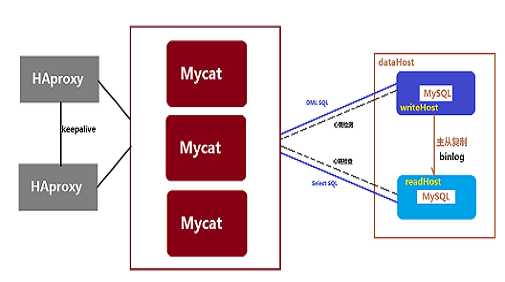
应用中如何使用,官网已经说明了,直接连接 mycat 应用就好了,相当于 mycat 代理了 MySQL ,以后操作 MySQL 先经过 mycat
https://github.com/MyCATApache/Mycat-Server

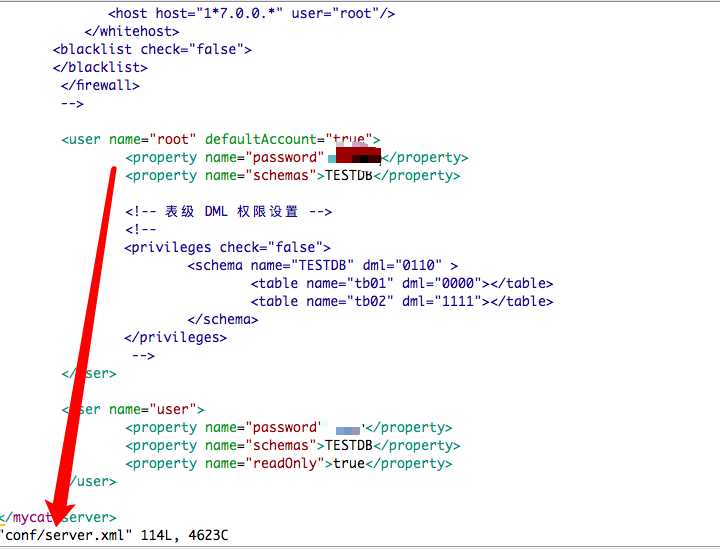
账号密码就是 conf/server.xml 配置的账号密码
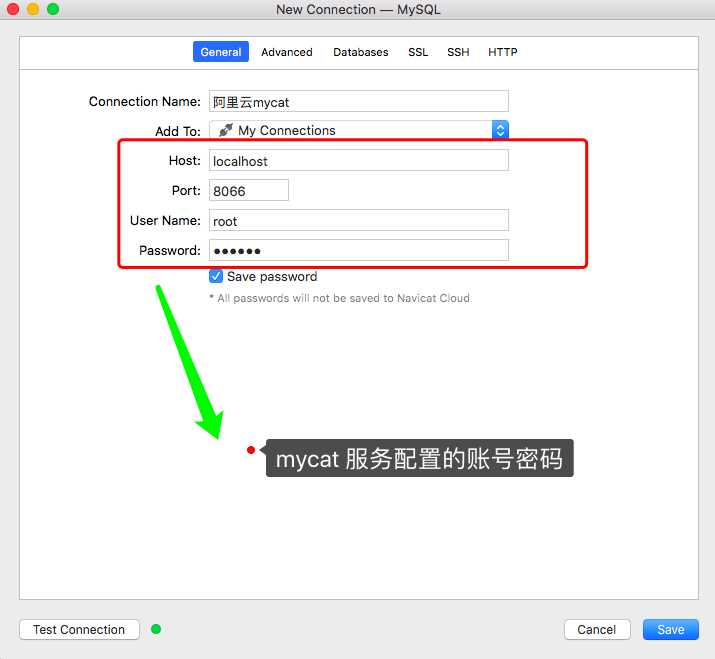
在 mycat 管理的 TESTDB 数据库下执行如下 SQL 语句
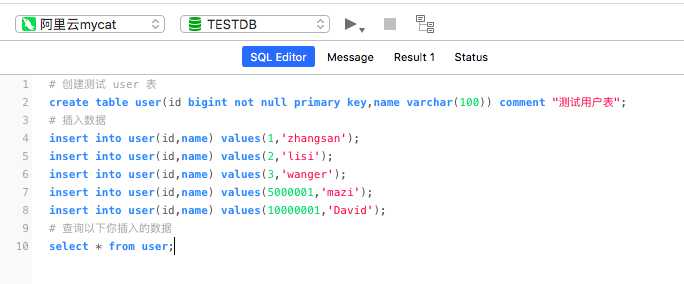
# 创建测试 user 表 create table user(id bigint not null primary key,name varchar(100)) comment "测试用户表"; # 插入数据 insert into user(id,name) values(1,‘zhangsan‘); insert into user(id,name) values(2,‘lisi‘); insert into user(id,name) values(3,‘wanger‘); insert into user(id,name) values(5000001,‘mazi‘); insert into user(id,name) values(10000001,‘David‘); # 查询以下你插入的数据 select * from user;
执行以上语句,会发现
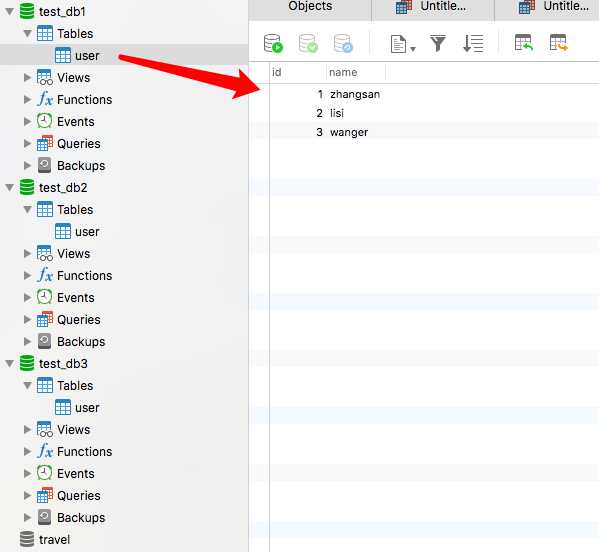
test_db1、test_db2、test_db3 这三个数据库都创建了一张 user 表;
test_db1.user 表中有插入的前3条数据
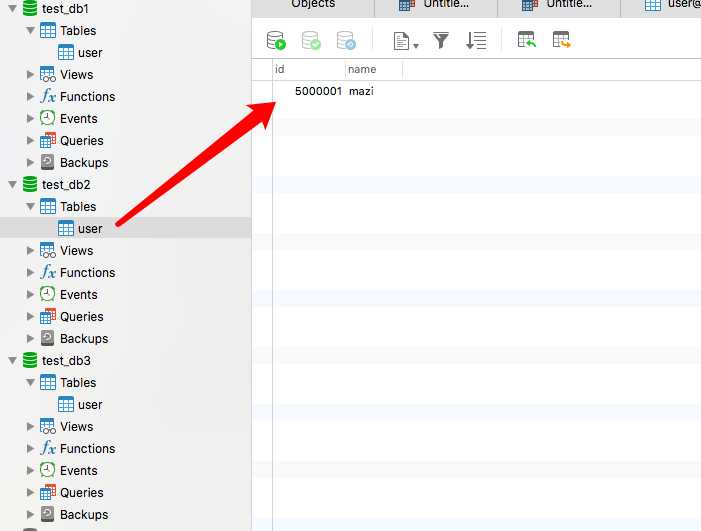
test_db2.user 表中有插入的第4条数据
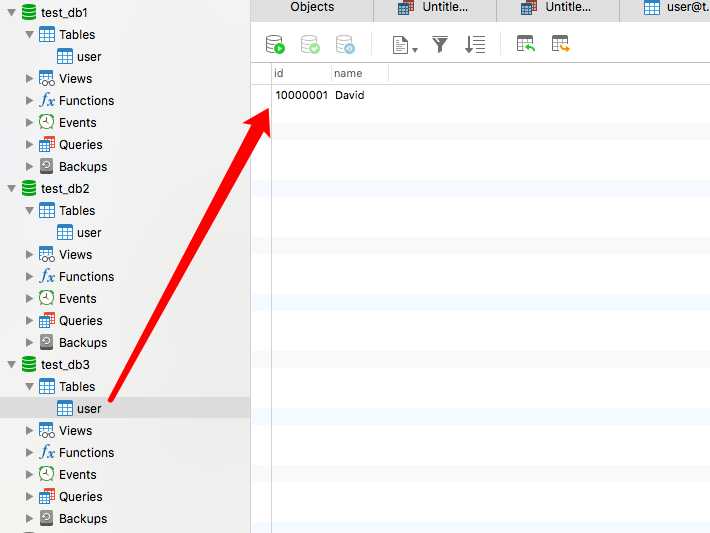
test_db3.user 表中有插入的第5条数据
上面一个简单的插入查询就完成。
标签:内存缓存 sharding sch splay weight cat ase acid 大数
原文地址:https://www.cnblogs.com/liugx/p/9936234.html
