标签:blog http os ar for sp div 2014 art
最近想做一个小web应用,就是把豆瓣读书和亚马逊等写有书评的网站上关于某本书的打分记录下来,这样自己买书的时候当作参考。
这篇日志这是以豆瓣网为例,只讨论简单的功能。
这很好处理,找到网站的搜索框,然后填入相关信息,提交后查看url即可。
这里以豆瓣为例,当我在http://book.douban.com页面的搜索框中输入 现代操作系统 后得到下面的url:
http://book.douban.com/subject_search?search_text=%E7%8E%B0%E4%BB%A3%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F&cat=1001
这样就知道如何向服务器提交查询请求了,注意search_text后面的一串字符只是编码不同(。。。)。
详见下面代码:
book_name = ‘现代操作系统‘ douban_book = ‘http://book.douban.com/subject_search?‘ search = [(‘search_text‘,‘现代操作系统‘),(‘cat‘,‘1001‘)] getbook = douban_book + urllib.urlencode(search) content = urllib2.urlopen(getbook).read()
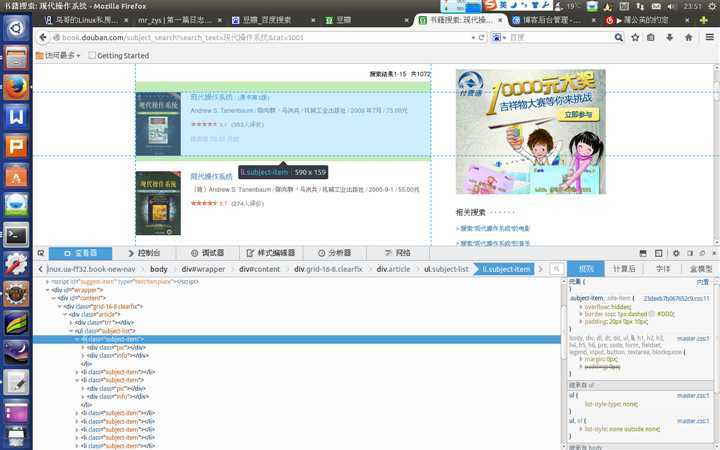
代码写的很乱,一些语法还不是很熟悉。我是以写代码来学习Python的,什么不懂就查什么。
# -*- coding: utf-8 -*-
import urllib2
import urllib
from sgmllib import SGMLParser
class BookInfo(SGMLParser):
def reset(self):
SGMLParser.reset(self)
# 标记对应的标签
self.is_subject = 0
self.is_subject_info = 0
self.is_subject_h2 = 0
self.is_subject_pub = 0
self.is_subject_star = 0
self.temp = {} # 一个字典,保存暂时的信息
self.info = [] # 一个列表,保存所有的信息
# li标签开始出现
def start_li(self,attrs):
if ‘subject-item‘ in [v for k, v in attrs if k == ‘class‘]:
self.is_subject = 1
# li标签结束
def end_li(self):
self.is_subject = 0
def start_h2(self,attrs):
if self.is_subject == 1 and ‘‘ in [v for k,v in attrs if k == ‘class‘]:
self.is_subject_h2 = 1
def end_h2(self):
self.is_subject_h2 = 0
def start_div(self,attrs):
attr = ‘‘
for k,v in attrs:
if k == ‘class‘:
attr = v
break
if attr == ‘info‘ and self.is_subject == 1:
self.is_subject_info = 1
elif attr == ‘pub‘ and self.is_subject_info == 1:
self.is_subject_pub = 1
elif attr == ‘star clearfix‘ and self.is_subject_info == 1:
self.is_subject_star = 1
else:
pass
def end_div(self):
if self.is_subject_star == 0:
if self.is_subject_pub == 0:
self.is_subject_info = 0
self.info.append(self.temp)
self.temp = {}
else:
self.is_subject_pub = 0
else:
self.is_subject_star = 0
def handle_data(self,data):
if self.is_subject_h2:
string = data.strip()
if len(string):
if ‘name‘ in self.temp:
self.temp[‘name‘] = self.temp[‘name‘] + string
else:
self.temp[‘name‘] = string
#print string
elif self.is_subject_pub:
string = data.strip()
if len(string):
if ‘pub‘ in self.temp:
self.temp[‘pub‘] = self.temp[‘pub‘]+string
else:
self.temp[‘pub‘] = string
elif self.is_subject_star:
string = data.strip()
if len(string):
if ‘star‘ in self.temp:
self.temp[‘star‘] = self.temp[‘star‘] + string
else:
self.temp[‘star‘] = string
#print string
else:
pass
book_name = ‘现代操作系统‘
douban_book = ‘http://book.douban.com/subject_search?‘
search = [(‘search_text‘,‘现代操作系统‘),(‘cat‘,‘1001‘)]
getbook = douban_book + urllib.urlencode(search)
print getbook
content = urllib2.urlopen(getbook).read()
fobj = open(‘book.txt‘,‘w‘)
fileobj = open(‘books.txt‘,‘w‘)
book = BookInfo()
book.feed(content)
for books in book.info:
for item in books:
print ‘*************************************************‘
print ‘书名:%s‘ % books[‘name‘]
if ‘pub‘ in books:
print ‘出版信息:%s‘ % books[‘pub‘]
if ‘star‘ in books:
print ‘评价:%s‘ % books[‘star‘]
break
fobj.write(content)
fobj.close()
fileobj.close()
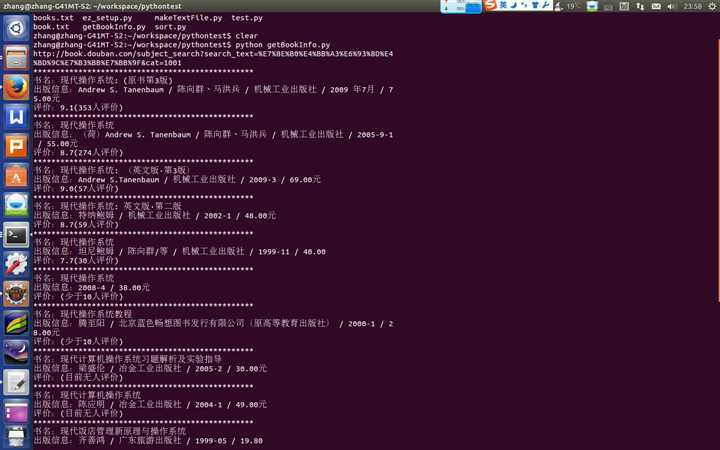
这只是开头的第一步,以后的日子里不断的学习和实践。。。
-end-
标签:blog http os ar for sp div 2014 art
原文地址:http://www.cnblogs.com/mr-zys/p/4019973.html