标签:重点 duplicate 垃圾回收器 ted tree png ide 二叉查找树 其他
| 本周学习了二叉树的另一种有序扩展?是什么呢?你猜对了!ヾ(?°?°?)??就是堆。本章将讲解堆的链表实现and数组实现,以及往堆中添加元素或从堆中删除元素的算法;还将介绍对的一些用途,包括基本使用和优先队列。 |
堆中的操作:

addElement方法将给定的Comparable元素添加到堆的恰当位置处,且维持该堆的完全性属性和有序属性。
- Little Tip:完全树你还记得吗?完全二叉树就是所有叶子都位于h或者h-1层,其中h为log2(n),且n为树中的元素数目,h层的所有叶子都位于该树的左边,那么该树被认为是完全的。
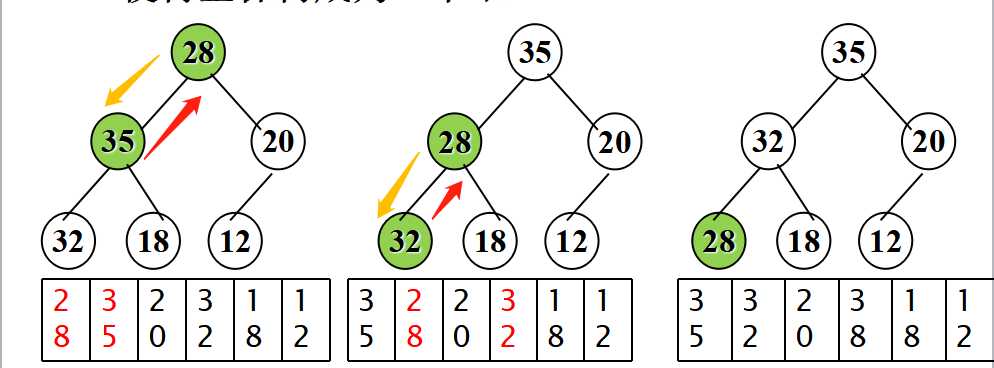
其次,具有相同优先级的项目使用先进先出方法来确定其排序。
public HeapNode lastNode;总结:链表实现和数组实现的addElement方法和removeElement方法时间复杂度都是O(logn)。但是,数组的实现还是更高效一些,因为在addElement操作中数组实现不用去确定插入双亲的结点,在removeElement操作中数组实现不需要确定新的最末一片叶子。
private HeapNode<T> getNextParentAdd()
{
HeapNode<T> result = lastNode;
while ((result != root) && (result.getParent().getLeft() != result))
result = result.getParent();
if (result != root)
if (result.getParent().getRight() == null)
result = result.getParent();
else
{
result = (HeapNode<T>)result.getParent().getRight();
while (result.getLeft() != null)
result = (HeapNode<T>)result.getLeft();
}
else
while (result.getLeft() != null)
result = (HeapNode<T>)result.getLeft();
return result;
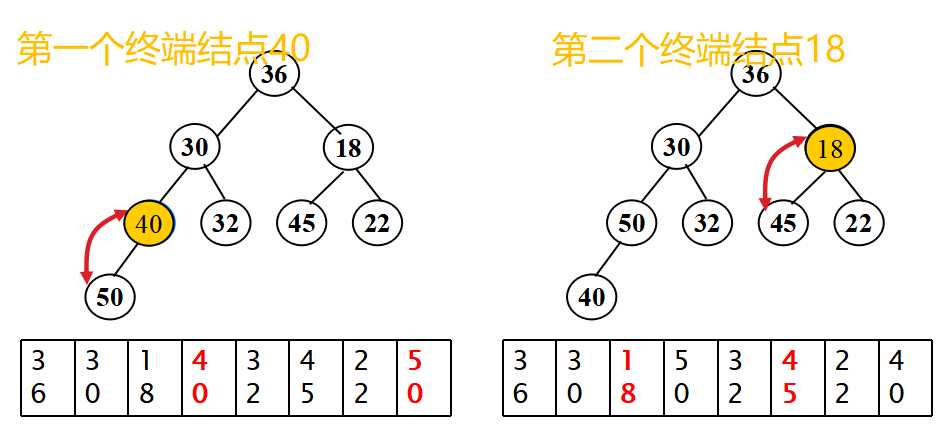
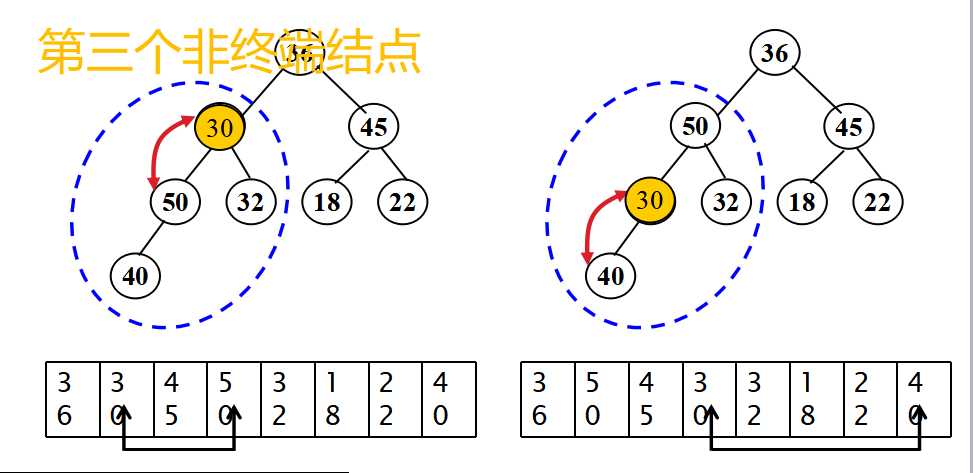
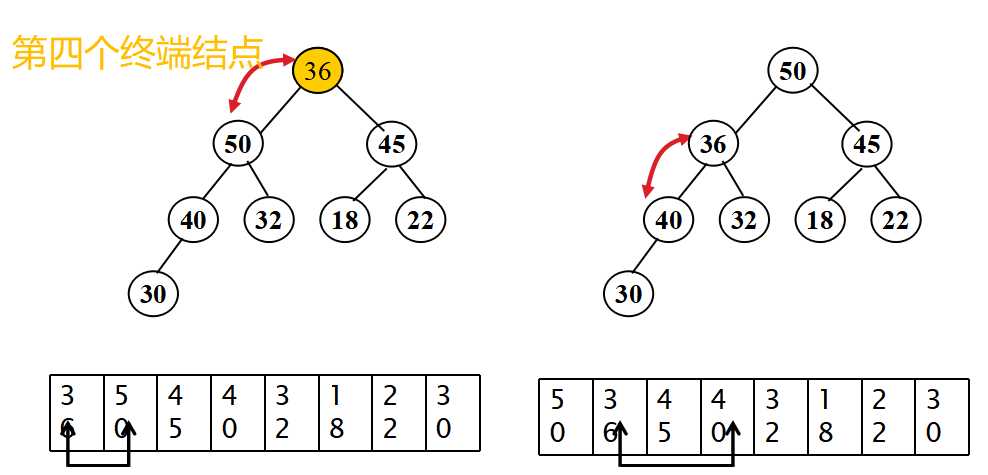
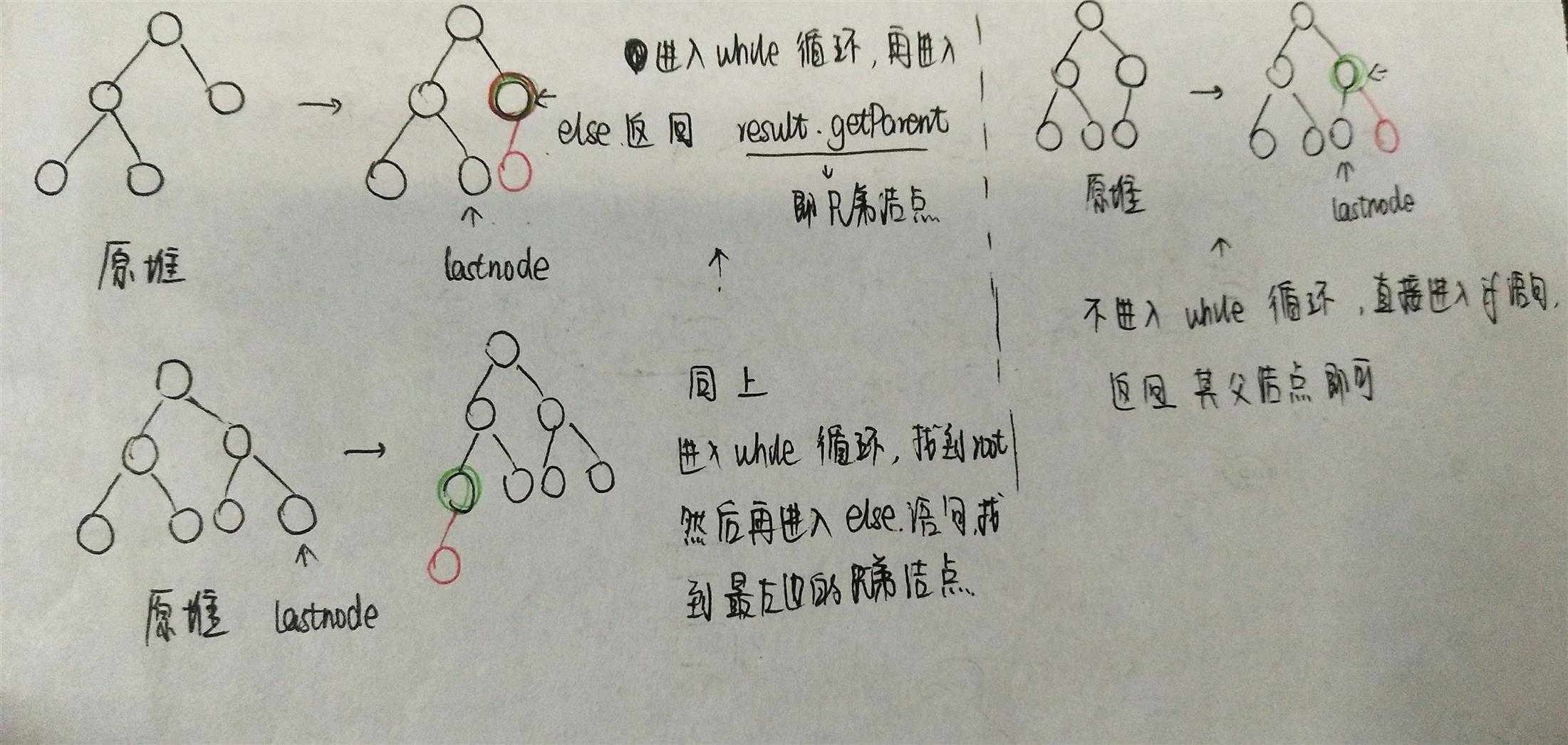
}这段代码是返回将要插入结点的双亲结点的方法,当时我和仇夏讨论的是有两种情况。因为我们知道插入操作为了保证树的完全性,所以要在h层的从左开始数的第一个空结点插入或者在h+1层的最左边插入(如果树是满的话),但是在循环体中不满足我们的要求。
问题的重点是“下一个将要插入结点的双亲结点”,之前一直理解的是新插入结点的双亲结点,所以当然不对。在理解正确之后,画出几种插入的可能情况,再跟着上述代码理解几遍,就慢慢清晰明朗了。
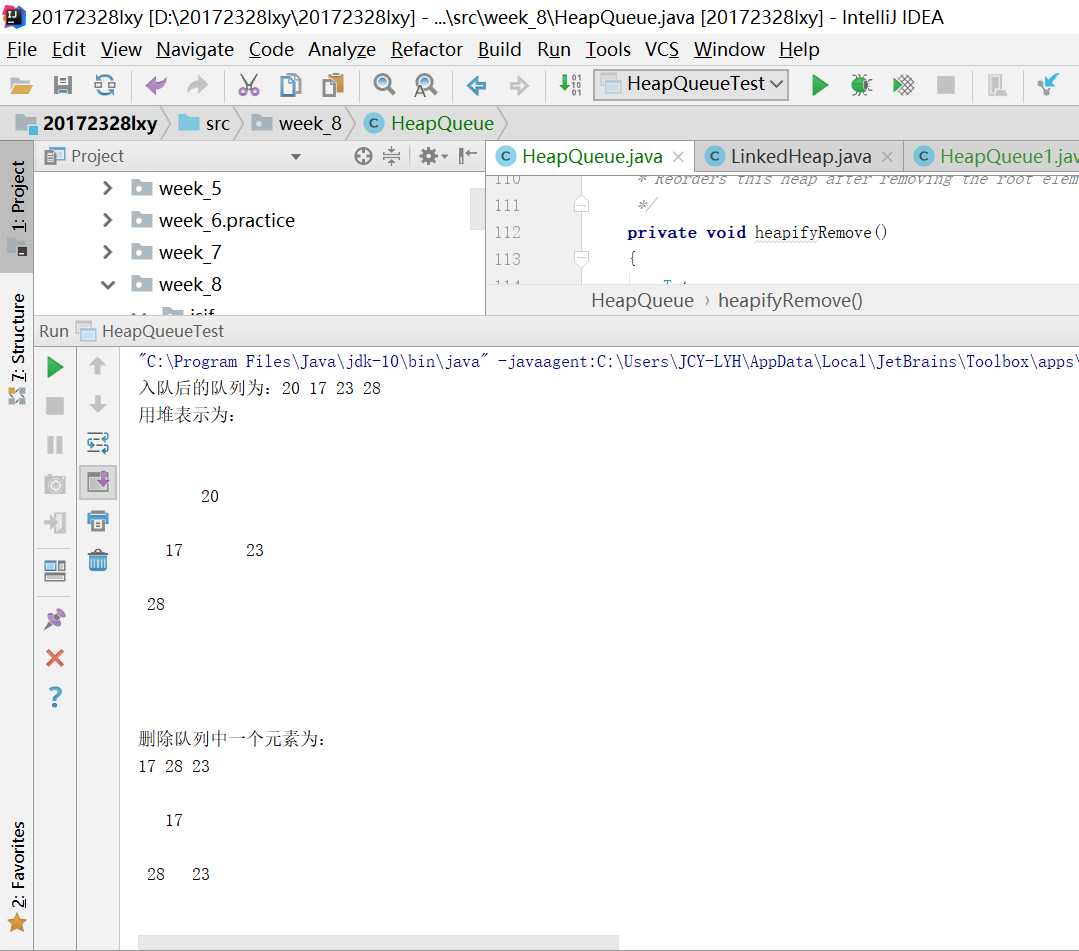
int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。首先,我先用链表实现的堆来实现队列。通过在enqueue方法中调用addElement方法,就能够实现队列的入队,但是在入队后进行了堆的插入中的排序?队列是符合先进先出原则的,那么我就修改了堆中的插入方法,将其中的排序删掉。同理,当出队时也不应该去考虑排序的问题。但是当我删除掉删除的排序后,再执行删除队列中前两个元素,我却发现删除的并不一定是队列的前两个值,反而删除掉了最开始跟的值和最末一个叶子,这是由堆的性质决定的。所以想要保持先进先出,我们就要找到堆顶的左孩子然后删除。所以我们需要改变一下堆中的排序方法。链表的实现方法很麻烦,而且要改变删除的排序算法需要考虑很多种情况,在做了两小时还是不能完整正确的情况下,让我们把目光投向数组。
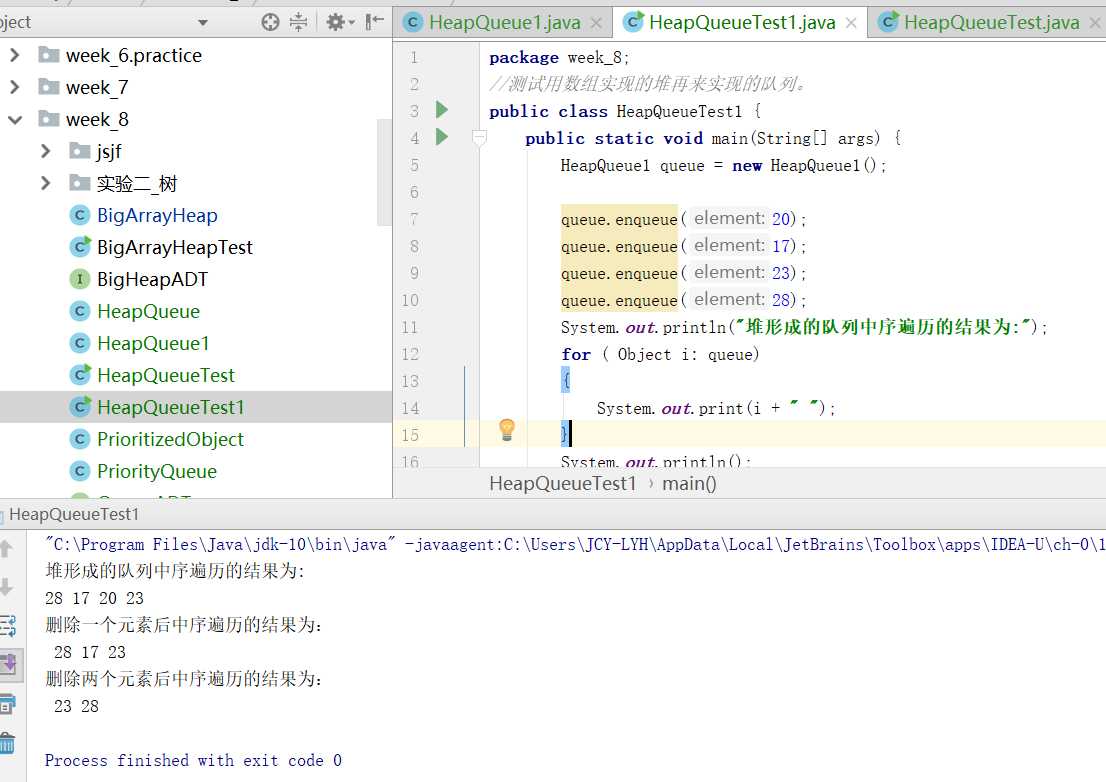
数组中只需要将删除后的最末结点变成null就可以达到效果。
Crossing miles of frustrations and rivers a raging,picking up stones I found along the way.
怕不轻松,怕太轻松。
再也不用觉得工作日长,因为每天好像都是工作日。想忙里偷闲就忙里偷闲,想抓紧做事就抓紧做事。
我将每天告诉自己:请对专业课程更加虔诚一点。
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | |
|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 |
| 第一周 | 0/0 | 1/1 | 8/8 |
| 第二周 | 621/621 | 1/2 | 12/20 |
| 第三周 | 678/1299 | 1/3 | 10/30 |
| 第四周 | 2734/4033 | 1/4 | 20/50 |
| 第五周 | 1100/5133 | 1/5 | 20/70 |
| 第六周 | 1574/6707 | 2/7 | 15/85 |
| 第七周 | 1803/8510 | 1/8 | 20/105 |
| 第八周 | 2855/11365 | 2/10 | 25/130 |
20172328 2018-2019《Java软件结构与数据结构》第八周学习总结
标签:重点 duplicate 垃圾回收器 ted tree png ide 二叉查找树 其他
原文地址:https://www.cnblogs.com/LXY462283007/p/9939573.html