标签:while 循环 ESS href 源代码 com substr gen rac 出现
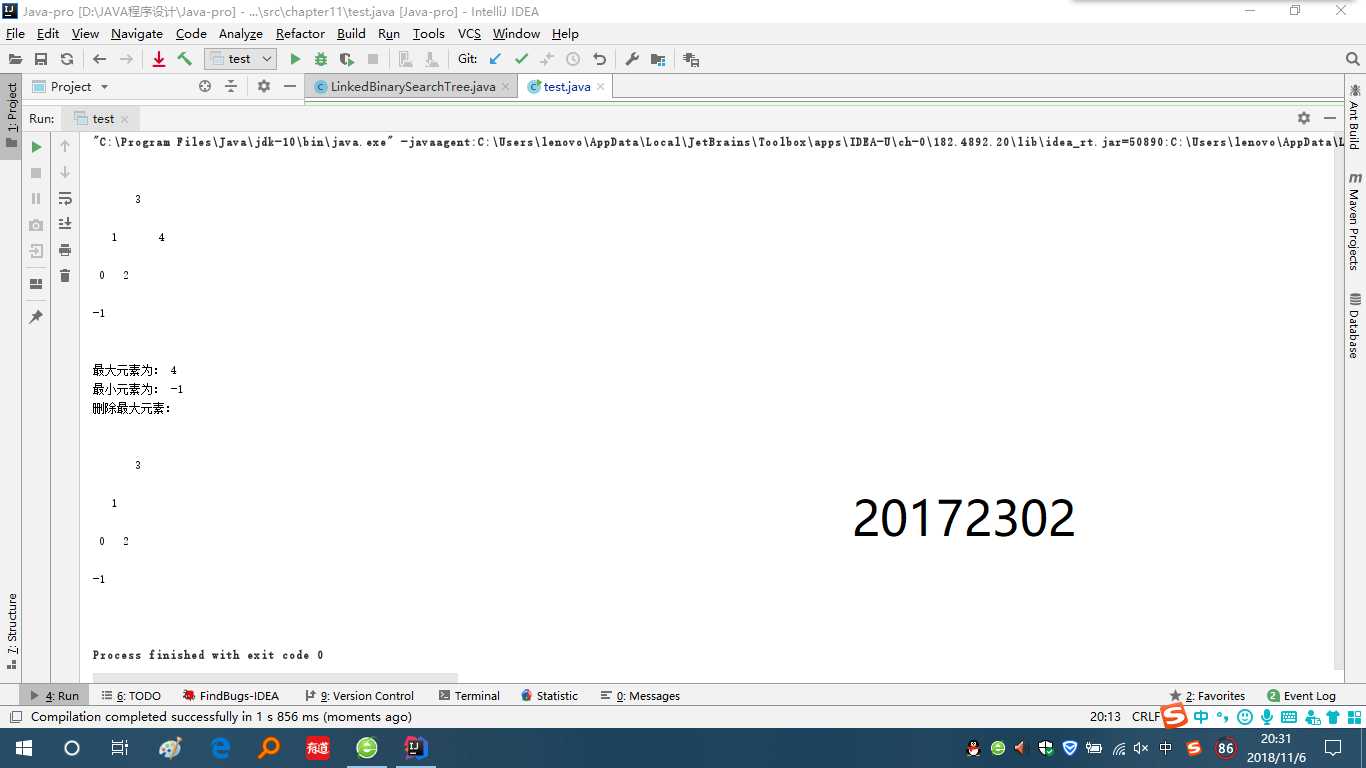
(1)参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder;用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
(2)基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二?树的功能,比如给出中序HDIBEMJNAFCKGL和先序ABDHIEJMNCFGKL,构造出附图中的树;用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
(3)自己设计并实现一颗决策树;提交测试代码运行截图,要全屏,包含自己的学号信息
(4)输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果;提交测试代码运行截图,要全屏,包含自己的学号信息
(5)完成PP11.3;提交测试代码运行截图,要全屏,包含自己的学号信息
(6)参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。(C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
这里的方法编写在学习树时都有写过,所以直接编写了测试类,实验结果如图
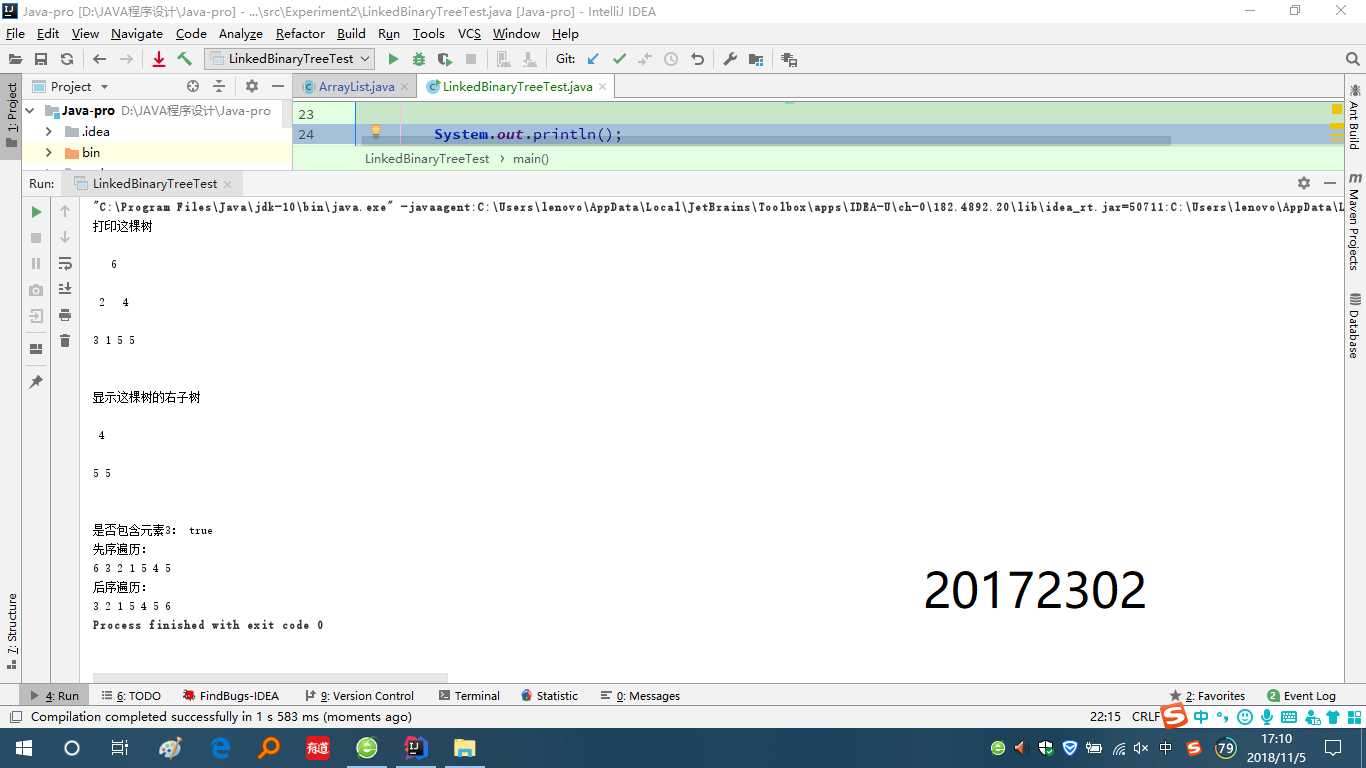
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二?树的功能,这个需要新建类,类中写了公有方法generate0,generate0再去调用私有方法generate,
这个主要是利用传进来的先序和中序的字符串,确定根结点,然后再确定其左右孩子,接下来递归该过程,直至将该字符串读取完成。
实验结果截图:
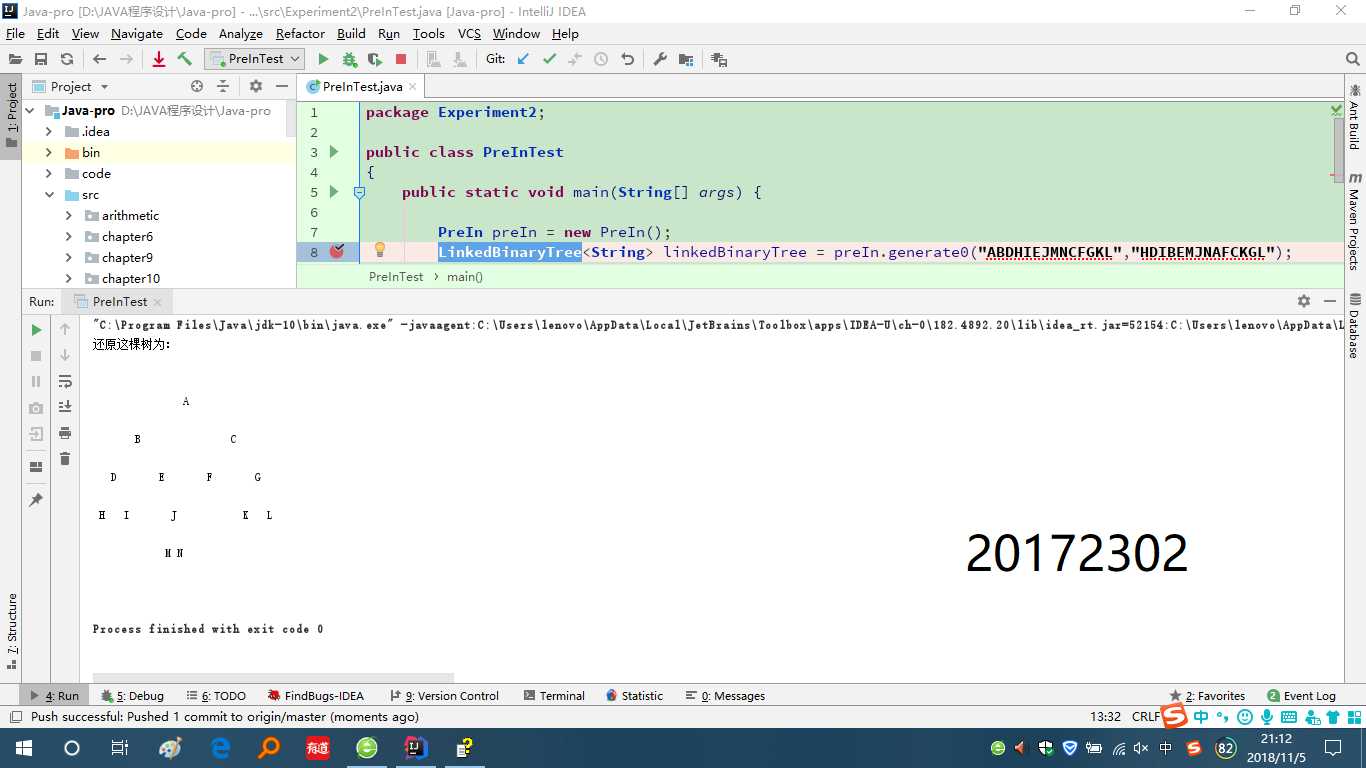
自己设计并实现一颗决策树,设计了一棵决策树去确定1至6之间的某个数。
11
Is the number greater than 3?
Is the number greater than 2?
Is the number greater than 4?
Is the number greater than 1?
Is the number greater than 5?
The number is 1.
The number is 2.
The number is 3.
The number is 4.
The number is 5.
The number is 6.
3 5 6
1 3 7
4 9 10
2 8 4
0 1 2实验结果见图:
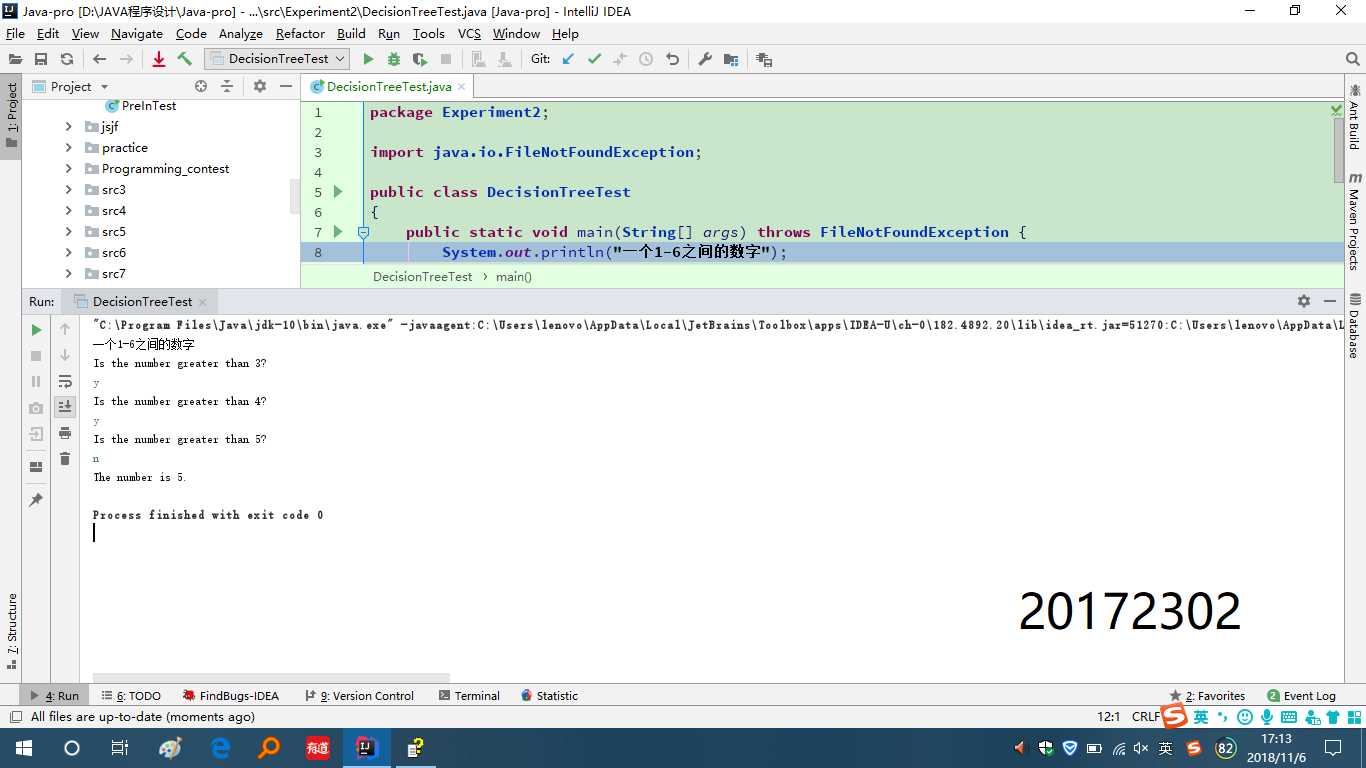
输入中缀表达式,使用树将中缀表达式转换为后缀表达式,这里是使用两个栈,一个是操作符栈,另一个是操作数栈,其中操作数栈是操作数是以树的类型进行存储的。实验结果见图:
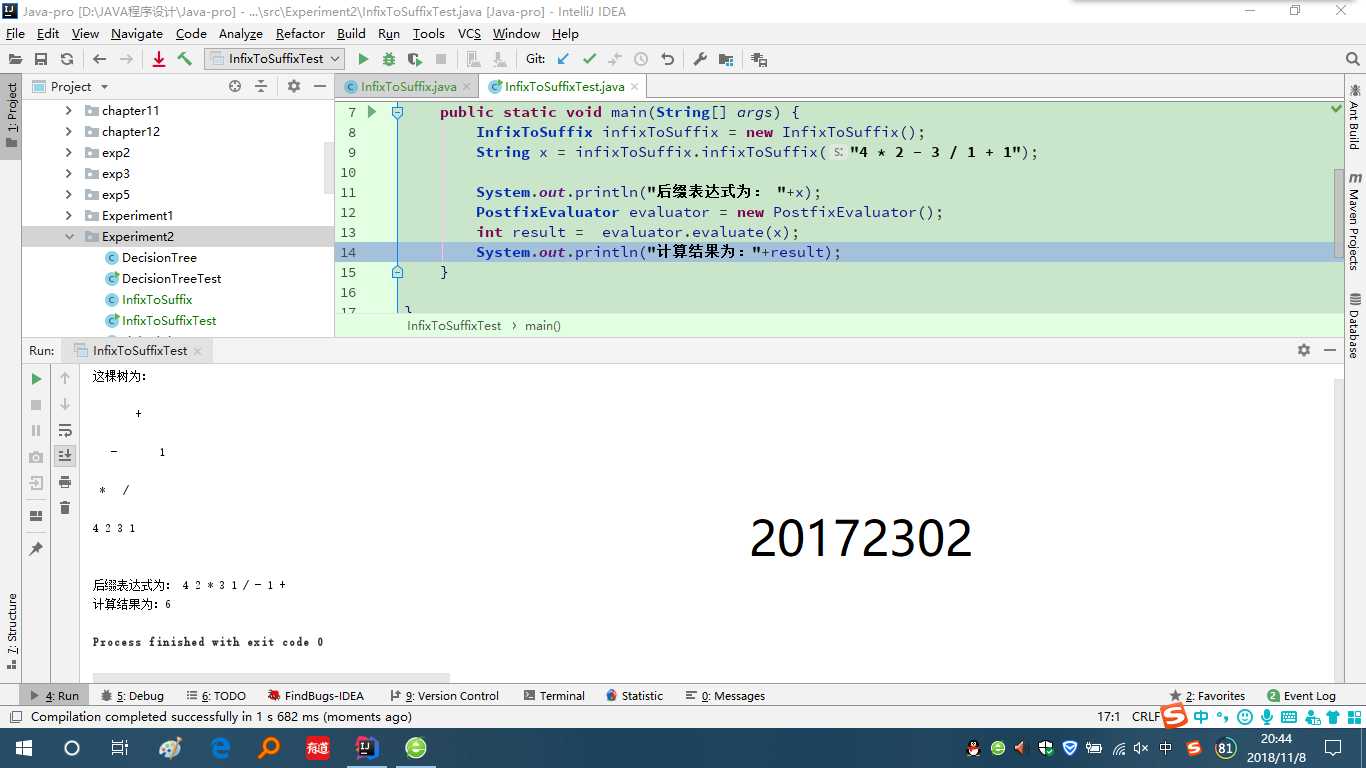
完成PP11.3;11.3在之前已经做过,测试了一次完成。
看了一下TreeMap和Hashmap的源代码,一个3000多行,一个2400多行,放弃了,太多了。于是从网上找资料看了一些个的源码分析,这里写一些。
1.继承结构
下面是HashMap与TreeMap的继承结构:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
可以看出它们都继承了AbstractMap。而HashMap是直接实现的Map,TreeMap实现的是NavigableMap(Cloneable和Serializable忽略)。
2.TreeMap
TreeMap是NavbagableMap的实现,底层基于红黑树。这个Map按照Comparable将键值排序,或者按照在创建Map时提供的Compartor。
TreeMap的底层是基于红黑树的实现,所以像get、put、remove、containsKey这些方法都会花费log(n)的时间复杂度。这儿不会着重于红黑树的具体实现以及转换,只要知道TreeMap的基本思路就可以了。
(1)put操作
public V put(K key, V value) {
Entry<K,V> t = root;
// 1.如果根节点为 null,将新节点设为根节点
if (t == null) {
compare(key, key);
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
// 2.为 key 在红黑树找到合适的位置
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
} else {
// 与上面代码逻辑类似,省略
}
Entry<K,V> e = new Entry<>(key, value, parent);
// 3.将新节点链入红黑树中
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 4.插入新节点可能会破坏红黑树性质,这里修正一下
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
从put方法可以看到,有几步流程:
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
// 查找操作的核心逻辑就在这个 while 循环里
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}从上面可以看到,get()方法的流程:
3.HashMap
HashMap是基于Hash table实现的Map,它实现了Map中所有的可选的操作,并且允许key或value为null,近似的等价于Hashtable(除了HashMap是非同步并且允许null值);它不保证元素的顺序;如果插入的元素被Hash函数正确的分散在不同的桶(槽,bucket)中,get和put操作都只需要常量时间。
(1)put操作
public V put(K key, V value) {
//传入key的hash值,对hashCode值做位运算
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果tab为null,则通过resize初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//计算key的索引,如果为当前位置为null,直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//如果当前位置不为null
Node<K,V> e; K k;
//如果相同直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果是红黑树节点,添加节点到红黑树,如果过程中发现相同节点则覆盖
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果是链表节点
else {
for (int binCount = 0; ; ++binCount) {
//如果
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//找到相同节点则覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//结构变化次数+1
++modCount;
//如果size超过最大限制,扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}put()操作的主要是如下几个步骤:
首先判断Node[]数组table是否为空或null,如果是空那么进行一次resize,这次resize只是起到了一次初始化的作用。
根据key的值计算hash得到在table中的索引i,如果table[i]==null则添加新节点到table[i],然后判断size是否超过了容量限制threshold,如果超过进行扩容。
如果在上一步table[i]不为null时,判断table[i]节点是否和当前添加节点相同(这里使用hash和equals判断,因此需要保证hashCode()方法和equals()方法描述的一致性),如果相同则覆盖该节点的value。
如果上一步判断table[i]和当前节点不同,那么判断table[i]是否为红黑树节点,如果是红黑树节点则在红黑树中添加此key-value。
如果上一步判断table[i]不是红黑树节点则遍历table[i]链表,判断链表长度是否超过8,如果超过则转为红黑树存储,如果没有超过则在链表中插入此key-value。(jdk1.8以前使用头插法插入)。在遍历过程中,如果发现有相同的节点(比较hash和equals)就覆盖value。
维护modCount和size等其他字段。
(2)get操作
public V get(Object key) {
Node<K,V> e;
//传入key的hash
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//这里访问(n - 1) & hash其实就是jdk1.7中indexFor方法的作用
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//判断桶索引位置的节点是不是相同(通过hash和equals判断),如果相同返回此节点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//判断是否是红黑树节点,如果是查找红黑树
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//如果是链表,遍历链表
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//如果不存在返回null
return null;
}问题1:做实验2时我的树打印的始终是不完整的,只有A—J这些个元素,后面的元素就是消失了。
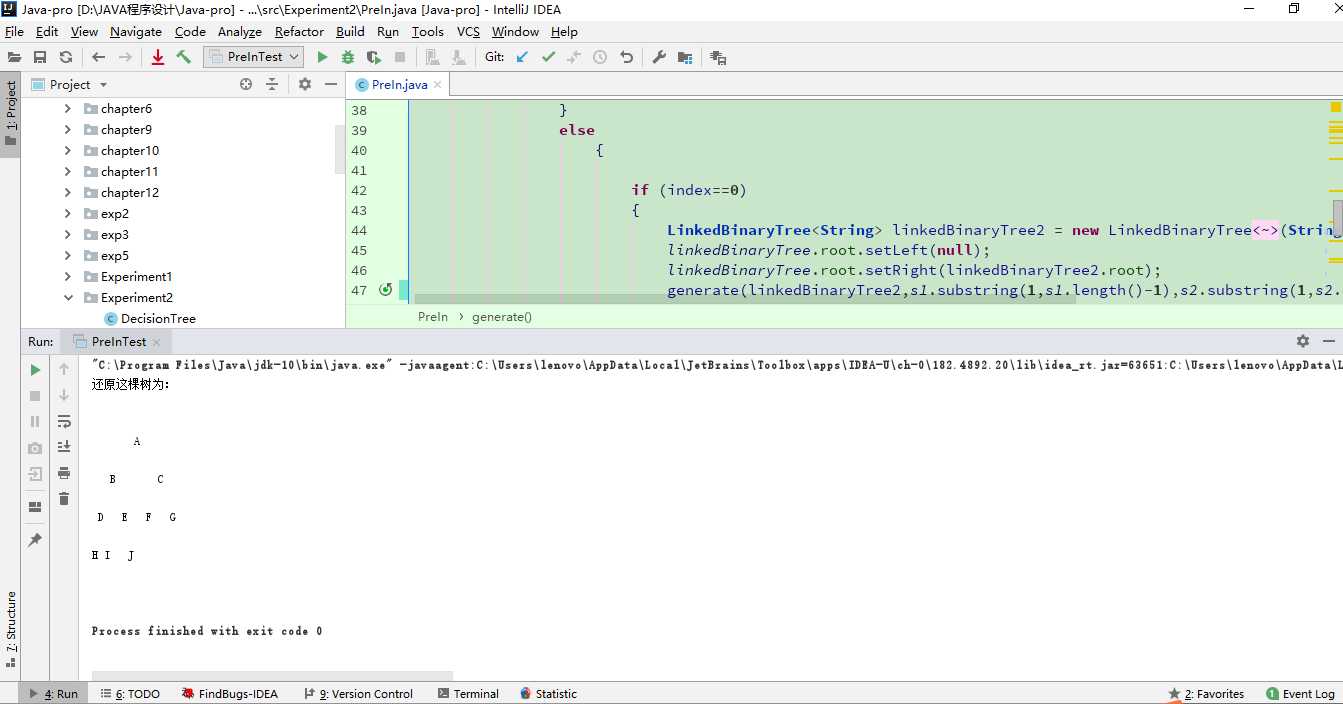
问题1解决方案:通过Debug,第二次时发现了问题,原来是我substring方法用的有问题,查看API中substring方法的具体介绍:
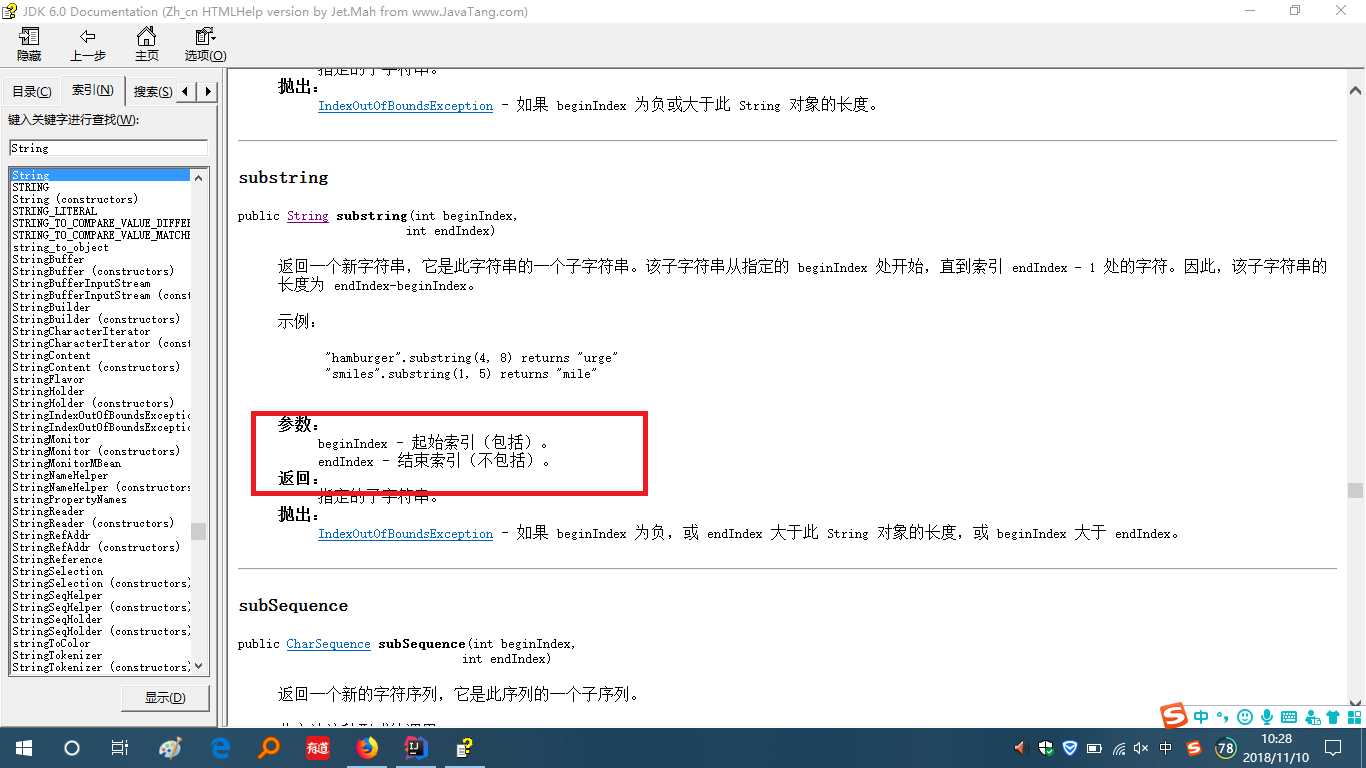
? ? ? ?它的参数是包括起始索引,但不包括终止索引,而我在编写过程当中是默认了它是起始索引和终止索引都包括在内,这就会导致遗漏了一部分的元素,因此出现了这个问题,在原来的基础上把终止索引加1后即可解决该问题。
问题2:实验4,实验4想了好久都没有一点思路,我不清楚怎么去使用树,在哪使用树,树是用来存储什么的?
if (isOperator(m)) {
if (m.equals("*") || m.equals("/"))
stack.push(m);
else if (stack.empty())
stack.push(m);
else {
while (!stack.isEmpty()) {
String s1 = String.valueOf(stack.pop());
LinkedBinaryTree operand3 = linkedBinaryTreeStack.pop();
LinkedBinaryTree operand4 = linkedBinaryTreeStack.pop();
LinkedBinaryTree<String> linkedBinaryTree1 =
new LinkedBinaryTree<String>(s1, operand4, operand3);
linkedBinaryTreeStack.push(linkedBinaryTree1);
if (stack.isEmpty())
break;
}
stack.push(m);
}
}? ? ? ?如果它是乘或除可以直接入栈,而当它是加或减时,需要把栈里的比它优先级高的取出来,取出来的时候需要同时从数栈里取出两个操作数,构成一棵新的树,再放入树的栈中,循环直至栈中没有元素,然后再把该操作符放入栈中,这样就可以实现了。
20172302 《Java软件结构与数据结构》实验二:树实验报告
标签:while 循环 ESS href 源代码 com substr gen rac 出现
原文地址:https://www.cnblogs.com/hzy0628/p/9932266.html