标签:其他 最小堆 列表 方便 ali 根据 过程 分析 第一个
https://img2018.cnblogs.com/blog/1333004/201811/1333004-20181110144559856-530051268.gif

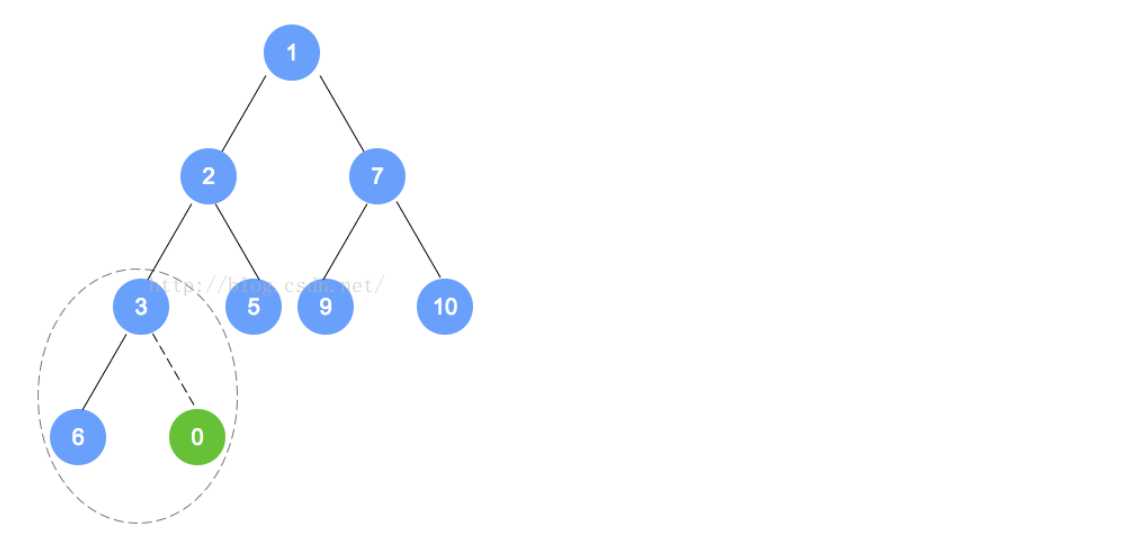
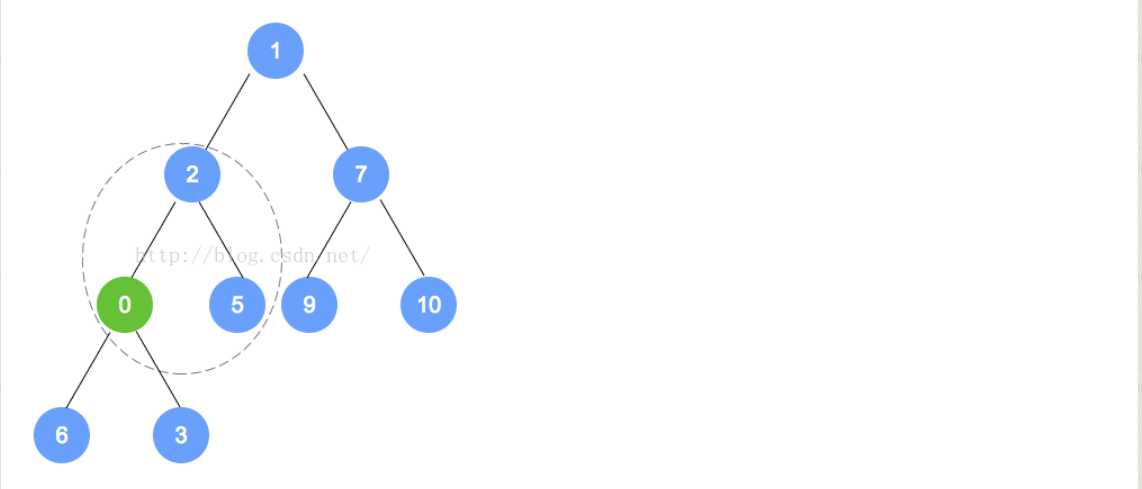
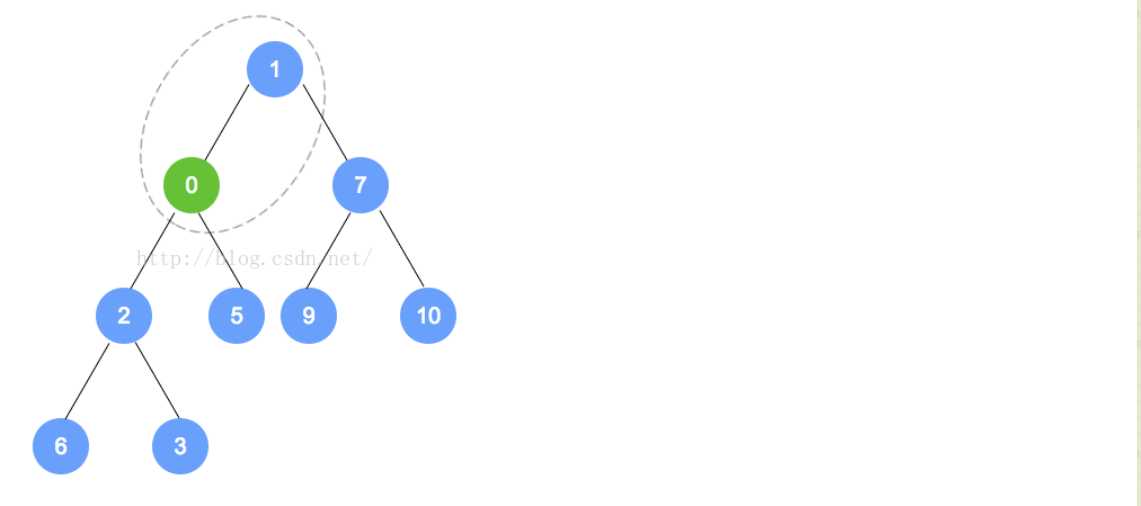
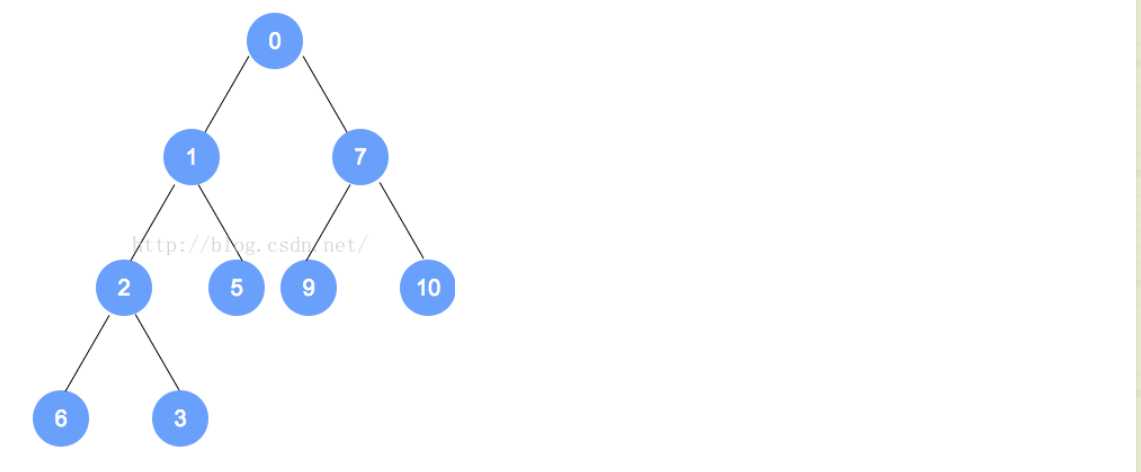
public PrioritizedObject(T element, int priority)
{
this.element = element;//元素
this.priority = priority;//优先级
arrivalOrder = nextOrder;//放入队列的顺序
nextOrder++;
}public int compareTo(PrioritizedObject obj)
{
int result;
if (priority > obj.getPriority())
result = 1;
else if (priority < obj.getPriority())
result = -1;
else if (arrivalOrder > obj.getArrivalOrder())
result = 1;
else
result = -1;
return result;
}链表实现和数组实现的removeMin操作的复杂度同为o(logn)
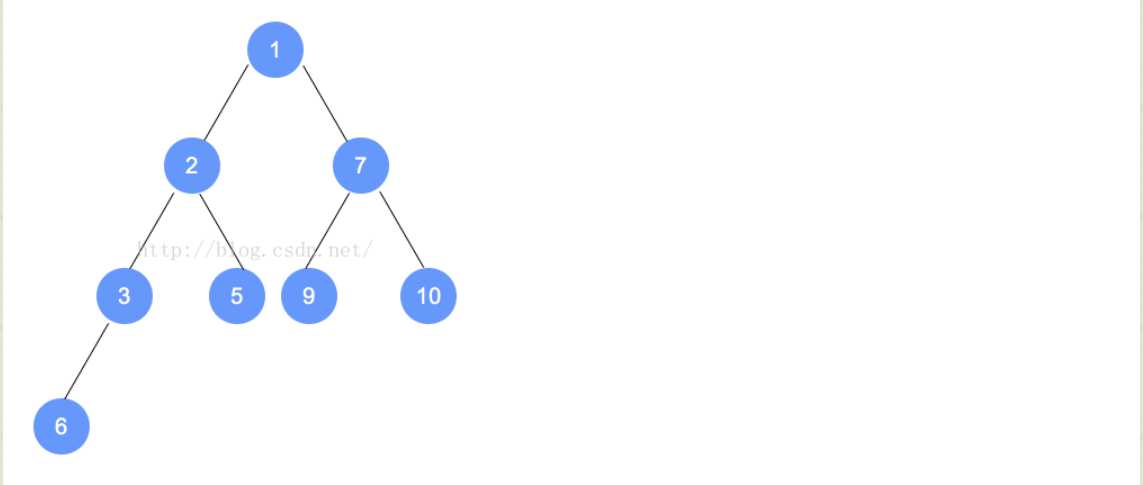
public HeapNode lastNode;在二叉树的数组实现中,树的根位于位置0处,对于每一结点n,n的左孩子将位于数组的2n+1位置处,n的右孩子将位于数组的2(n+1)位置处
heapSort方法的两部分构成:添加列表的每个元素,然后一次删除一个元素
就堆排序来说,老师在上课的时候讲的很详细,而且因为它是有最小堆和最大堆的,根部要不是最小元素,要不是最大元素,因此,堆排序的关键就是通过不断的移动,将最值放在根处,然后利用remove根处元素的方法,将元素删除出来,再对剩余的堆进行重排序,然后继续删除根部,而这个过程,每删除的元素排列出来就是我们所需要的升序或者降序,即堆排序完成
堆排序我们也可以用数组的知识进行理解。因为我们在数组实现堆时,已经知道了对于一个根结点,其左右孩子的确定所在位置,所以我们可以利用比较和互换,进行排序,其实原理和上一条是相同的。
无论是用列表还是数组进行堆排序,他们的复杂度相同,都是o(nlogn)
对于列表进行堆排序来说:在前面的学习中,我们知道,无论是addElement还是removeMin它们的复杂度都是o(logn)。但是我们要注意的是,这个复杂度是在添加或者删除一个元素的情况下的复杂度。而我们进行排序的时候,是需要添加且删除n个元素的,因此,我们分别要进行这两个操作n次,以满足对n个元素进行排序。所以最终复杂度为2nlogn,即o(nlogn)
对于数组进行堆排序来说:从数组中第一个非叶子的结点开始,将它与其孩子进行比较和互换(如有必要)。然后在数组中往后操作,直到根。对每个非叶子的结点,最多要求进行两次比较操作,所以复杂度为o(n)。但是要使用这种方式从堆中删除每个元素并维持堆的属性时,其复杂度仍为o(nlogn)。因此,即使这种方式的效率稍好些,约等于2*n+logn,但其复杂度仍为o(nlogn)。
问题1解决方案:
队列就是先进先出的一种形式,而优先级实际上就是根据某种标准进行排序,高级的就先排,对于相同级别的就根据先进先出的队列的要求进行排序,优先级队列也叫优先权队列。
对于优先级队列的特点:
1.优先级队列是0个或多个元素的集合,每个元素都有一个优先权或值。
2.当给每个元素分配一个数字来标记其优先级时,可设较小的数字具有较高的优先级,这样更方便地在一个集合中访问优先级最高的元素,并对其进行查找和删除操作。
3.对优先级队列,执行的操作主要有:(1)查找,(2)插入,(3)删除。
4.在最小优先级队列中,查找操作用来搜索优先权最小的元素,删除操作用来删除该元素。
5.在最大优先级队列中,查找操作用来搜索优先权最大的元素,删除操作用来删除该元素。
注:我们在删除之后,要根据要求对之后的元素进行重新的排列,这个时候,我们可能出现多种的相同优先权,所以,这个时候就应该根据队列的要素,进行先进先出的进行排序,因此这也提醒我们,我们在写代码时,我们要对进入队列的顺序进行记录。
6.插入操作均只是简单地把一个新的元素加入到队列中。
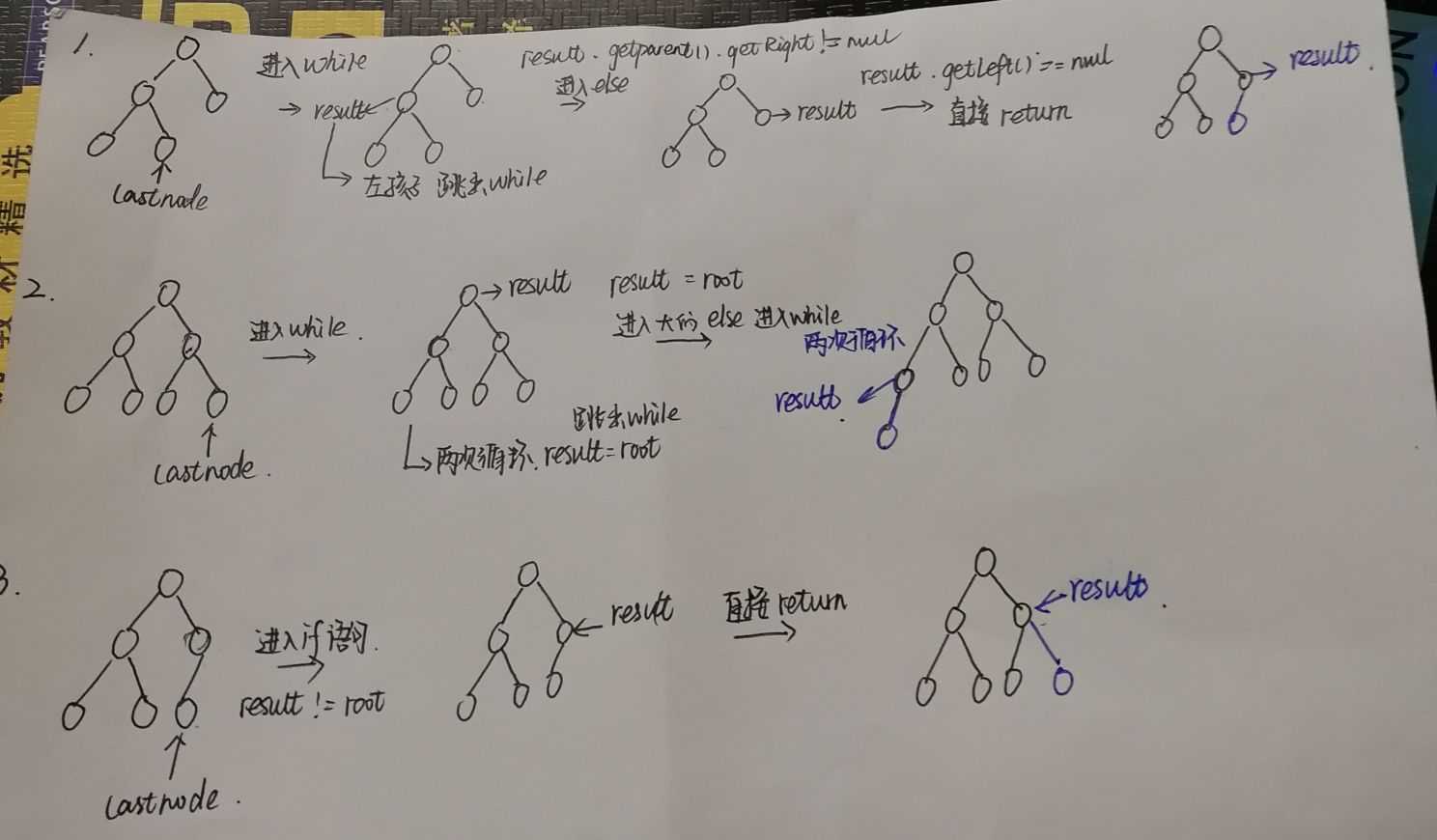
private HeapNode<T> getNextParentAdd() {
HeapNode<T> result = lastNode;
while ((result != root) && (result.getParent().getLeft() != result))
result = result.getParent();
if (result != root)
if (result.getParent().getRight() == null)
result = result.getParent();
else {
result = (HeapNode<T>) result.getParent().getRight();
while (result.getLeft() != null)
result = (HeapNode<T>) result.getLeft();
}
else
while (result.getLeft() != null)
result = (HeapNode<T>) result.getLeft();
return result;
}
问题1:在进行ArrayHeap的测试时,出现这样的情况,它删除之后,后面总是多出来一个数字,不知道为什么?
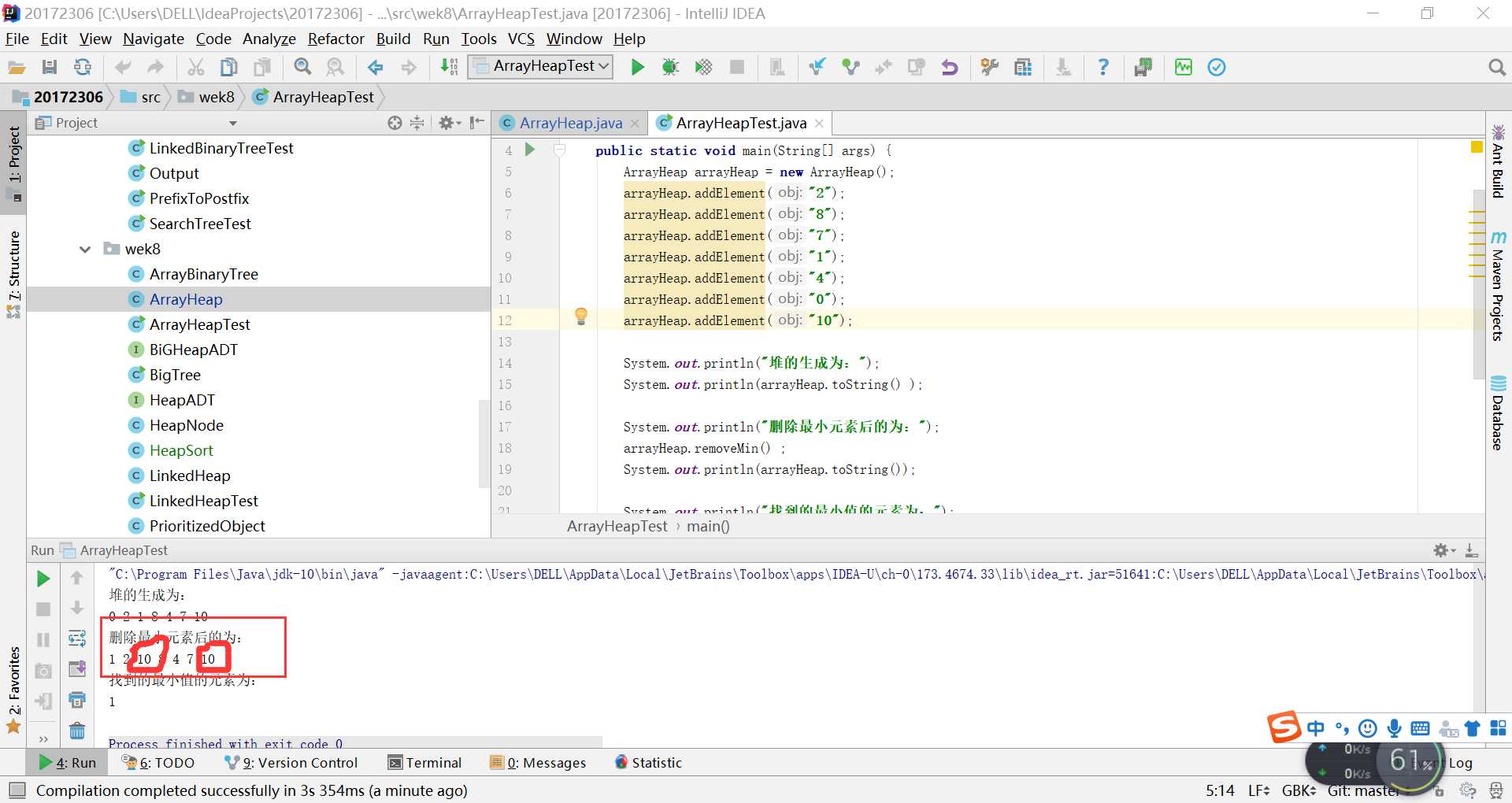
tree[count - 1] = null;然后我把它加上就正常了
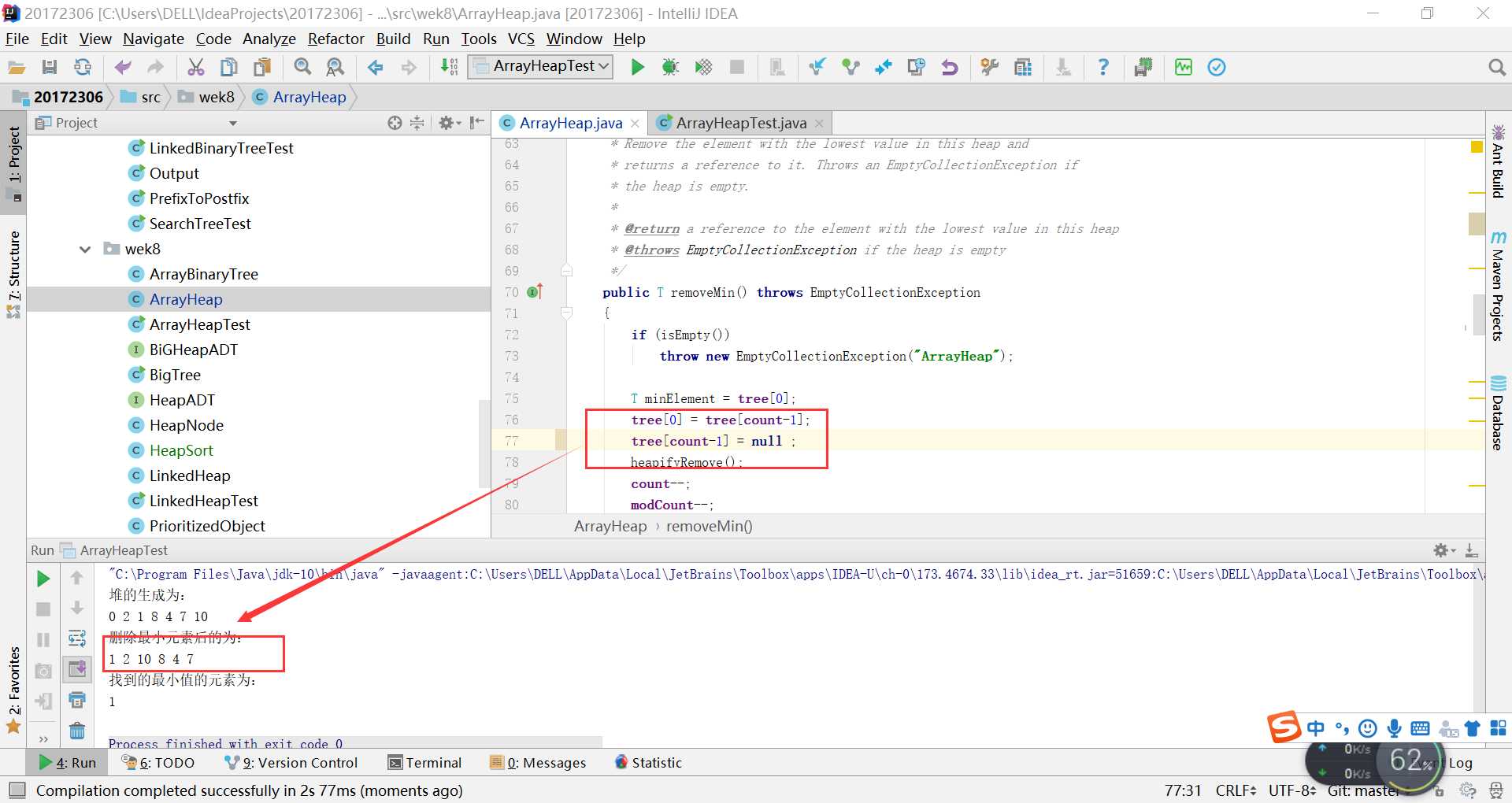
后来他给我讲原因:
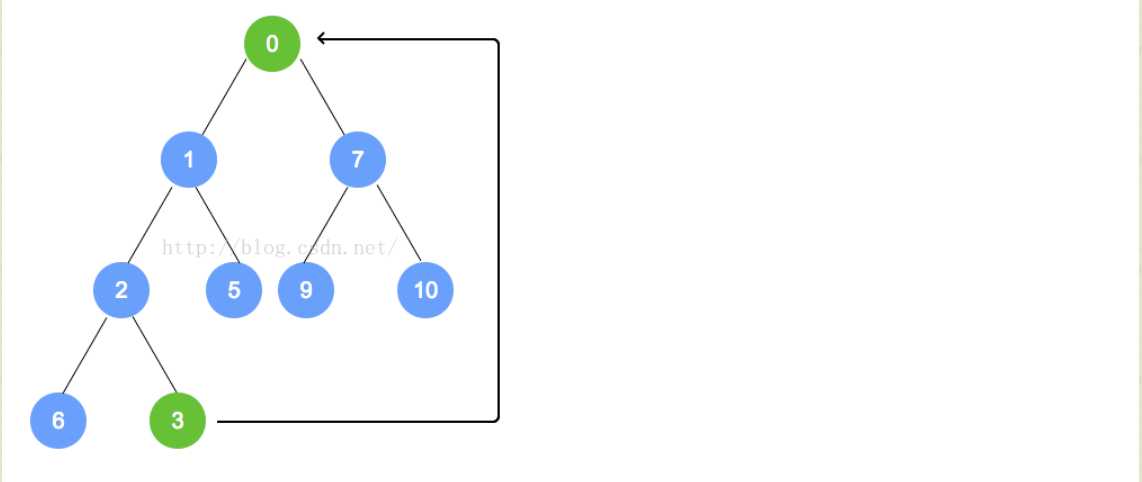
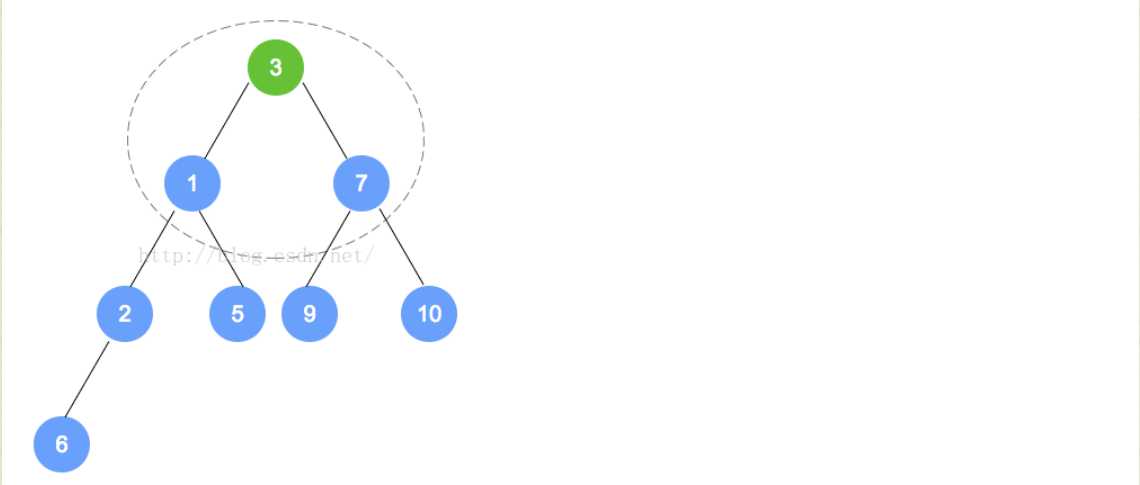
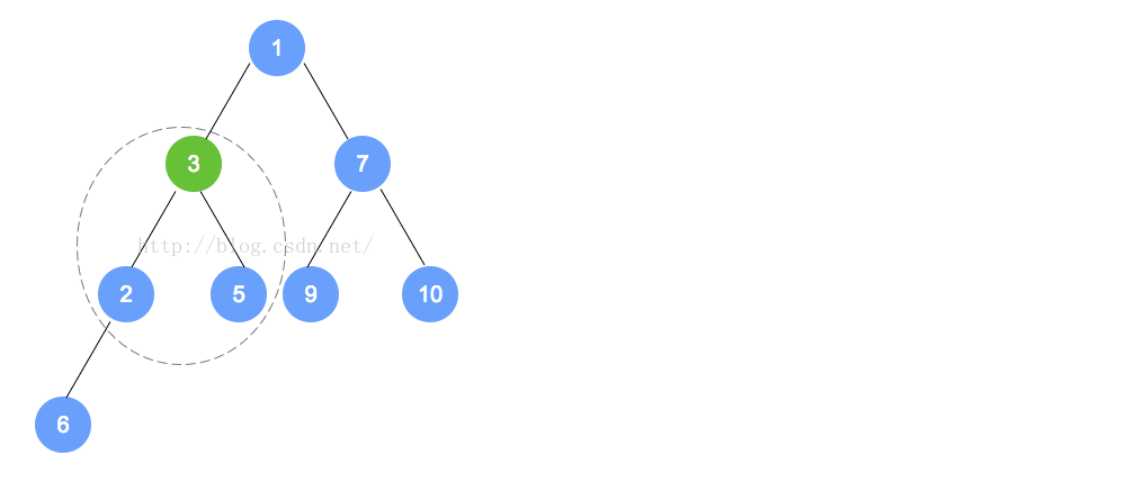
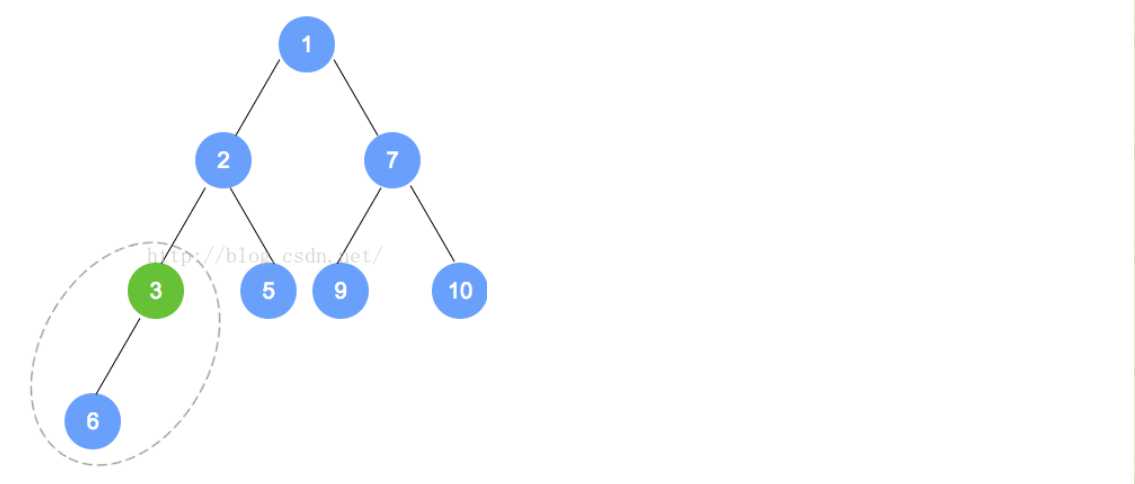
T minElement = tree[0];//最小的元素是根结点,也就是数组的0位置处
tree[0] = tree[count-1];//这个时候,将最末叶子结点放在了根结点处,准备进行重排序
tree[count-1] = null ;//将放在上面的那个最末叶子结点去掉,否则就会多出来
heapifyRemove();//进行重排序(statistics.sh脚本的运行结果截图)

这个是马虎的,我后来看IDEA知道了compareTo返回的是boolean型
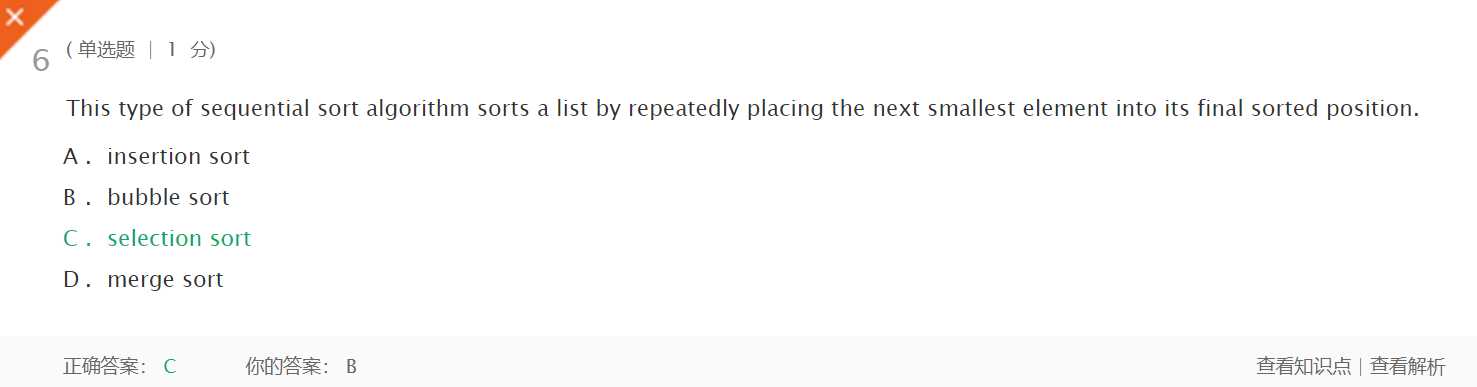
选择排序算法通过反复地将某一特定值放在它的列表中的最终已排序位置从而完成对某一列表值的排序
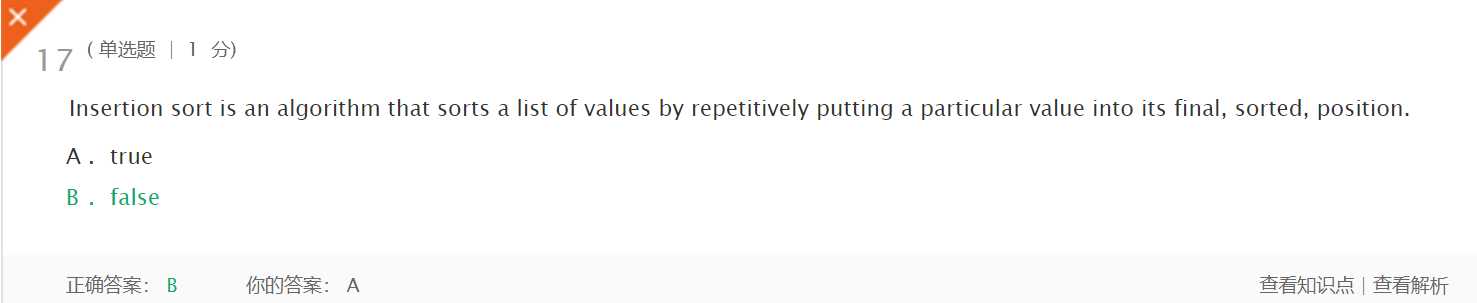
插入排序算法通过反复地将某一特定值插入到该列表某个已排序的子集中来完成对列表值的排序
第十二章老师讲的比较简略,主要讲了堆排序的内容,说是很有用的,而且我也听懂了,哈哈哈!| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 6/6 | |
| 第二周 | 985/985 | 1/1 | 18/24 | |
| 第三周 | 663/1648 | 1/1 | 16/40 | |
| 第四周 | 1742 /3390 | 2/2 | 44/84 | |
| 第五周 | 933/4323 | 1/1 | 23/107 | |
| 第六周 | 1110/5433 | 2/2 | 44/151 | |
| 第七周 | 1536/6969 | 1/1 | 56/207 | |
| 第八周 | / | 2/2 | 60/267 |
20172306 2018-2019-2 《Java程序设计与数据结构》第八周学习总结
标签:其他 最小堆 列表 方便 ali 根据 过程 分析 第一个
原文地址:https://www.cnblogs.com/lc1021/p/9923432.html
{kind=link}