标签:写用 api 9.png 完整 贪婪模式 后台 color 服务 \n
## 大纲:
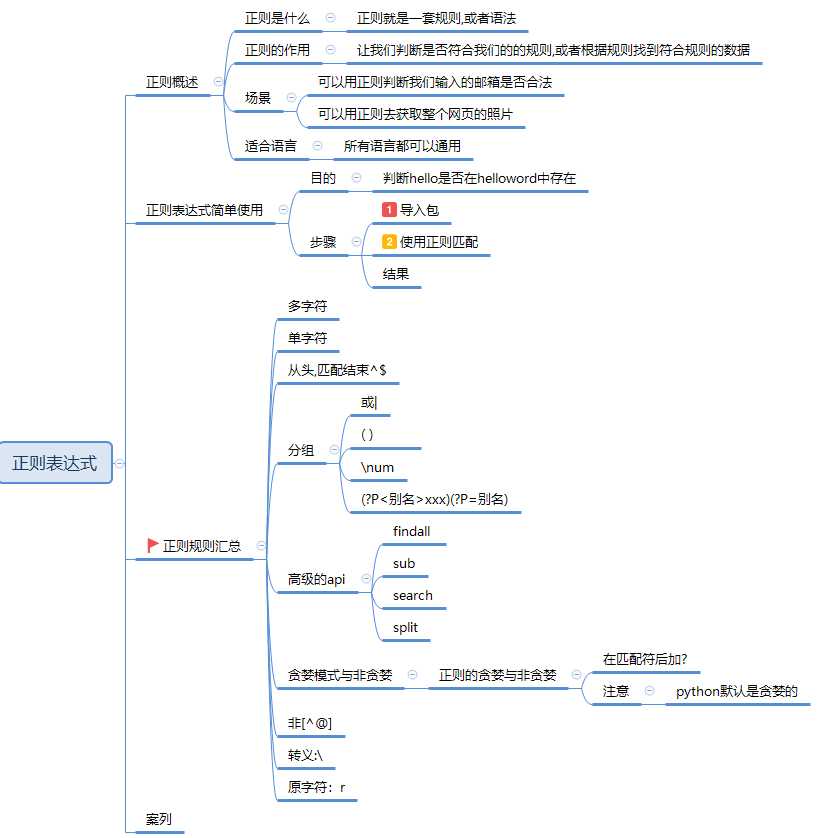
## 一、正则概述
1.正则是什么
正则就是一套规则,或者语法
2.正则的作用
让我们判断是否符合我们的的规则,或者根据规则找到符合规则的数据
3.使用场景
可以用正则判断我们输入的邮箱是否合法
可以用正则去获取整个网页的照片
4.适合语言
所有语言都可以通用
## 二、正则表达式简单使用
题目:判断hello是否在helloword中存在
步骤:
1.导入包
2.使用正则匹配

## 三、正则规则汇总:
**1. 单字符(一般大写用的特别少)**
. 匹配任意1个字符(除了\n)
[ ] 匹配[ ]中列举的字符[ab456c][a-z]
\d 匹配数字,即0-9
\D 匹配非数字,即不是数字
\s 匹配空白,即 空格,tab键\t,\n
\S 匹配非空白
\w 匹配单词字符,即a-z、A-Z、0-9、_,国家的文字
\W 匹配非单词字符
```
# . 匹配任意1个字符(除了\n)
# --判断包含速度与激情字符串的
# print(re.match("用户速度与激情.8", ‘用户速度与激情 8‘).group())
# print(re.match("用户速度与激情.", ‘用户速度与激情_‘).group())
# [ ] 匹配[ ]中列举的字符[ab456c][a-z]
# 格式1:[单个值,...]
# 判断用户只想看1,4,8的速度与激情
print(re.match(‘速度与激情[148]‘, ‘速度与激情4‘).group())
# 格式2:[范围,...]
# 判断用户只看1到8的速度与激情
# print(re.match(‘速度与激情[1-8]‘, ‘速度与激情8‘).group())
# 格式3:[数字字符]
# 判断用户输入的速度与激情1到8或者速度与激情a-h
# print(re.match(‘速度与激情[1-8a-h]‘, ‘速度与激情e‘).group())
# \d 匹配数字,即0-9
# print(re.match(‘用户速度与激情\d‘, "用户速度与激情8").group())
# \D 匹配非数字,即不是数字
# print(re.match(‘用户速度与激情\D‘, "用户速度与激情\n").group())
# \s 匹配空白,即 空格,tab键\t,\n
# --判断用户速度与激情 8
# print(re.match("用户速度与激情\s8", "用户速度与激情\n8").group())
# \S 匹配非空白
# print(re.match(‘用户速度与激情\D‘, "用户速度与激情\n").group())
# \w 匹配单词字符,即a-z、A-Z、0-9、_,汉字也可以匹配,其他的国家的语言也可以匹配
# 判断用户输入包含速度与激情
# print(re.match("速度与激情\w", "速度与激情四"))
# print(re.match("速度与激情\w", "速度与激情かないで"))
# \W 匹配非单词字符(用的少)
print(re.match("\W", "&"))
```
**2. 多字符(一般大写用的特别少)**
\* 匹配前一个字符出现0次或者无限次,即可有可无
\+ 匹配前一个字符出现1次或者无限次,即至少有1次
? 匹配前一个字符出现1次或者0次,即要么有1次,要么没有
{m} 匹配前一个字符出现m次 \d{3}
{m,n} 匹配前一个字符出现从m到n次 \d{4,6}
```
# * 匹配前一个字符出现0次或者无限次,即可有可无
# 表示0或者无限次
# 匹配一段文字或者没有输入文字
str = """今天天气不错
我们可以出去运动一下!
"""
print(re.match(‘.*‘, str).group())
# re.S 这个让我们的.匹配所有的数据(即忽略换行,匹配全文)
print(re.match(‘.*‘, str, re.S).group())
# + 匹配前一个字符出现1次或者无限次,即至少有1次,不能为空
print(re.match(‘.+‘, ‘ ‘).group())
# ? 匹配前一个字符出现1次或者0次,即要么有1次,要么没有
# 用来表示有一个字符或者没有字符
# 用户输入的电话号码有时有‘-‘有时没有
# 例:02112345678 或者 021-12345678
print(re.match(‘021-?\d{8}‘, ‘021-12345678‘).group())
print(re.match(‘021-?\d{8}‘, ‘02112345678‘).group())
# {m} 匹配前一个字符出现m次 \d{3}
# 判断电话号码是否021 - 开头的后面8位电话号码
# 例: 021 - 12345678
# 判断电话号
print(re.match(‘021-\d{8}‘, ‘021-12345678‘).group())
# {m,n} 匹配前一个字符出现从m到n次 \d{4,6}
题目:# 匹配速度与激情1,速度与激情12
print(re.match(‘速度与激情\d{1,2}‘, ‘速度与激情12‘).group())
```
**3. 匹配开头结尾**
^ 匹配字符串开头
$ 匹配字符串结尾
**3.1 ^ 匹配字符串开头**
```
# 需求:匹配以数字开头的数据
import re
# 匹配以数字开头的数据
match_obj = re.match("^\d.*", "3hello")
if match_obj:
# 获取匹配结果
print(match_obj.group())
else:
print("匹配失败")
运行结果:
3hello
```
**3.2 $ 匹配字符串结尾**
```
# 需求: 匹配以数字结尾的数据
import re
# 匹配以数字结尾的数据
match_obj = re.match(".*\d$", "hello5")
if match_obj:
# 获取匹配结果
print(match_obj.group())
else:
print("匹配失败")
运行结果:
hello5
```
**4. 分组**
| 匹配左右任意一个表达式
( ) 将括号中字符作为一个分组
\num 引用分组num匹配到的字符串
(?P<name>) 分组起别名
(?P=name) 引用别名为name分组匹配到的字符串
**4.1. | 或**
\* 匹配前一个字符出现0次或者无限次,即可有可无
```
# | 相当于python中的or
# 案例:匹配出163或者126的邮箱
import re
str = "liuyang@163.com"
str2 = "liuyang@126.com"
# |或者的意思
print(re.match(‘.{4,20}@(163|126)\.com‘, str).group())
print(re.match(‘.{4,20}@(163|126)\.com‘, str2).group())
```
**4.2 ( )还可以单独取出匹配的某一部分数据**
```
# 案例:取出邮箱的类型(只要163,126),后期可以编计用户那个邮箱用的多
# str = "liuyang@126.com"
print(re.match(".{4,20}@(163|126)\.com", str).group())
print(re.match(".{4,20}@(163|126)\.com", str).group(0))
print(re.match(".{4,20}@(163|126)\.com", str).group(1))
```
**4.3 \num用来取第几组用()包裹的数据 \1取第一个内部的括号位置的值**
```
# 格式(xxx)\1 :\1表示获取(xxx)的值
# 1.案例<html>hh</html> # 这个一定是有字母,开始跟结束的字母必须一样
print(re.match("<([a-zA-Z]+)>.*</[a-zA-Z]+>", ‘<html>hh</html>‘).group())
print(re.match("<([a-zA-Z]+)>.*</\\1>", ‘<html>hh</html>‘).group(0))
# 2.案例<html><body>hh</body></html>
str = ‘<html><body>hh</body></html>‘
# print(re.match("<([a-zA-Z]+)><[a-zA-Z]+>.*</[a-zA-Z]+></[a-zA-Z]+>", str).group())
# print(re.match("<([a-zA-Z]+)><[a-zA-Z]+>.*</[a-zA-Z]+></[a-zA-Z]+>", str).group(1))
# print(re.match("<([a-zA-Z]+)><([a-zA-Z]+)>.*</[a-zA-Z]+></[a-zA-Z]+>", str).group(2))
# print(re.match("<([a-zA-Z]+)><([a-zA-Z]+)>.*</\\2></\\1>", str).group())
```
**4.4 给分组取别名:(?P<别名>xxx)(?P=别名)**
```
# 使用别名给分组取别名,了解一下
# 格式:(?P<别名>xxx)(?P=别名)
# 案例<html><body>hh</body></html>
print(re.match("<(?P<name1>[a-zA-Z]+)><(?P<name2>[a-zA-Z]+)>.*</(?P=name2)></(?P=name1)>", str).group())
```
## **四、高级的api:**
**findall**
```
# 查询结果集
# findall
# 案例: 统计出python、c、c + +相应文章阅读的次数
# 数据: "python = 9999, c = 7890, c++ = 12345"
# 返回一个列表
print(re.findall("\d+", ‘python = 9999, c = 7890, c++ = 12345‘))
```
**sub**
```
# 替换数据
# sub
# 案例: 将匹配到的阅读次数换成998
# 数据: "python = 997"
# re.sub("替换的规则","想替换成的内容","被替换的内容")
# 只要匹配都替换
print(re.sub(‘\d+‘, ‘998‘, ‘python = 997‘))
print(re.sub(‘\d+‘, ‘998‘, ‘python = 997,c++ = 7676‘))
```
**search**
```
# 查询结果
# search 不会从头开始匹配,只要匹配到数据就结束
# 案例:匹配出文章阅读的次数中的次数
# 数据:"阅读次数为 9999"
import re
# search这个只查找一次
print(re.search(‘\d+‘, "阅读次数为 9999").group())
print(re.search(‘\d+‘, "阅读88次数为 9999").group())
```
**split**
```
# 字符串切割
# split
# 切割字符串“info:xiaoZhang 33 shandong”, 根据:或者空格
print(re.split(":|\s", "info:xiaoZhang 33 shandong"))
```
## **五、正则的贪婪模式与非贪婪**
在匹配符后加?
注意:python默认是贪婪的
例子:
场景liuyang@163.com liuyang@163.com,我们想取到第一个邮箱
```
import re
# 贪婪
# 多字符之后加一个?这个非贪婪
str = "liuyang@163.com liuyang@163.com \nliuyang@163.com"
print(re.match(‘.+@163\.com‘, str).group())
print(re.match(‘.+?@163\.com‘, str).group())
print(re.match(‘.*?@163\.com‘, str).group())
print(re.match(‘.+?‘, str).group())
```
## **六、非[^@]**
[^字符]这个是固定的一个语法,这个意思就是非
如果写字符串有可能会有错,他会去匹配一个字符串出错
例子:
场景liuyang@163.com liuyang@163.com,我们想取到第一个邮箱
```
# [^字符]字符 非字符
import re
str = "liuyang@163.com liuyang@163.com"
print(re.match(‘.{4,20}@163\.com‘, str).group())
print(re.match(‘[^@]+@163\.com‘,str).group())
# 一般只填一个字符
print(re.match(‘[^bc]‘, ‘c‘).group())
```
## ****七、转义:\\****
```
# \进行转义
# 在正则特殊的符号, 想以字符串的形式使用使用转义
# 匹配出163的邮箱地址,且 @ 符号之前有4到20位字符, 以.com结尾
import re
str = "liuyang@163.com"
print(re.match(‘.{4,20}@163\.com‘, str).group())
```
## **八、r原字符使用**
```
# r原字符
import re
print("\\")
print("\\\\")
print(re.match(‘\\\\‘, ‘\\‘).group())
print(re.match(‘\\\\\\\\‘, ‘\\\\‘).group())
```
## **九、案例:**
爬取岗位职责的信息:
```
str = """
<div>
<p>岗位职责:</p>
<p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p>
<p><br></p>
<p>必备要求:</p>
<p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p>
<p> <br></p>
<p>技术要求:</p>
<p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p>
<p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p>
<p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p>
<p>4、掌握NoSQL、MQ,熟练使用对应技术解决方案 </p>
<p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>
<p> <br></p>
<p>加分项:</p>
<p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p>
</div>
"""
import re
print(re.sub(‘<.+?>|\s| ‘, ‘‘, str))
```
标签:写用 api 9.png 完整 贪婪模式 后台 color 服务 \n
原文地址:https://www.cnblogs.com/ss-h/p/9955722.html
{kind=link}