标签:要求 aaa item art success roc for windows 分享
在之前写拉勾网的爬虫的时候,总是得到下面这个结果(真是头疼),当你看到下面这个结果的时候,也就意味着被反爬了,因为一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会禁止这个IP的访问:

对于拉勾网,我们要找到职位信息的ajax接口倒是不难(如下图),问题是怎么不得到上面的结果。
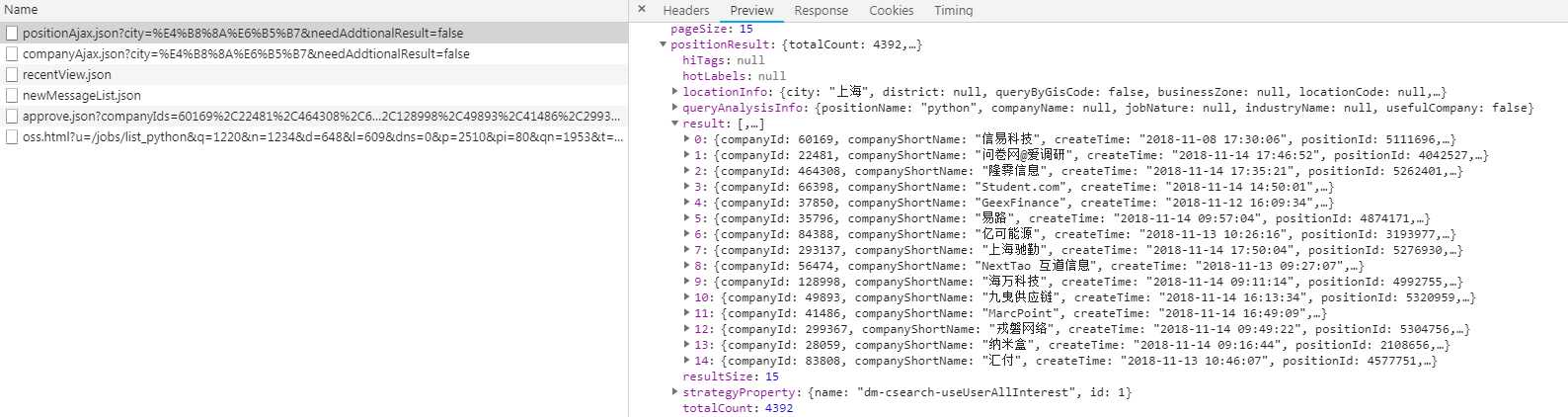
要想我们的爬虫不被检测出来,我们可以使用代理IP,而网上有很多提供免费代理的网站,比如西刺代理、快代理、89免费代理等等,我们可以爬取一些免费的代理然后搭建我们的代理池,使用的时候直接从里面进行调用就好了。然后通过观察可以发现,拉勾网最多显示30页职位信息,一页显示15条,也就是说最多显示450条职位信息。在ajax接口返回的结果中可以看到有一个totalCount字段,而这个字段表示的就是查询结果的数量,获取到这个值之后就能知道总共有多少页职位信息了。对于爬取下来的结果,保存在MongoDB数据库中。
proxies.py(爬取免费代理并验证其可用性,然后生成代理池)
1 import requests 2 import re 3 4 5 class Proxies: 6 def __init__(self): 7 self.proxy_list = [] 8 self.headers = { 9 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) " 10 "Chrome/45.0.2454.101 Safari/537.36", 11 ‘Accept-Encoding‘: ‘gzip, deflate, sdch‘, 12 } 13 14 # 爬取西刺代理的国内高匿代理 15 def get_proxy_nn(self): 16 proxy_list = [] 17 res = requests.get("http://www.xicidaili.com/nn", headers=self.headers) 18 ip_list = re.findall(‘<td>(\d+\.\d+\.\d+\.\d+)</td>‘, res.text) 19 port_list = re.findall(‘<td>(\d+)</td>‘, res.text) 20 for ip, port in zip(ip_list, port_list): 21 proxy_list.append(ip + ":" + port) 22 return proxy_list 23 24 # 验证代理是否能用 25 def verify_proxy(self, proxy_list): 26 for proxy in proxy_list: 27 proxies = { 28 "http": proxy 29 } 30 try: 31 if requests.get(‘http://www.baidu.com‘, proxies=proxies, timeout=2).status_code == 200: 32 print(‘success %s‘ % proxy) 33 if proxy not in self.proxy_list: 34 self.proxy_list.append(proxy) 35 except: 36 print(‘fail %s‘ % proxy) 37 38 # 保存到proxies.txt里 39 def save_proxy(self): 40 # 验证代理池中的IP是否可用 41 print("开始清洗代理池...") 42 with open("proxies.txt", ‘r‘, encoding="utf-8") as f: 43 txt = f.read() 44 # 判断代理池是否为空 45 if txt != ‘‘: 46 self.verify_proxy(txt.strip().split(‘\n‘)) 47 else: 48 print("代理池为空!\n") 49 print("开始存入代理池...") 50 # 把可用的代理添加到代理池中 51 with open("proxies.txt", ‘w‘, encoding="utf-8") as f: 52 for proxy in self.proxy_list: 53 f.write(proxy + "\n") 54 55 56 if __name__ == ‘__main__‘: 57 p = Proxies() 58 results = p.get_proxy_nn() 59 print("爬取到的代理数量", len(results)) 60 print("开始验证:") 61 p.verify_proxy(results) 62 print("验证完毕:") 63 print("可用代理数量:", len(p.proxy_list)) 64 p.save_proxy()
在middlewares.py中添加如下代码:
1 class LaGouProxyMiddleWare(object): 2 def process_request(self, request, spider): 3 import random 4 import requests 5 with open("具体路径\proxies.txt", ‘r‘, encoding="utf-8") as f: 6 txt = f.read() 7 proxy = "" 8 flag = 0 9 for i in range(10): 10 proxy = random.choice(txt.split(‘\n‘)) 11 proxies = { 12 "http": proxy 13 } 14 if requests.get(‘http://www.baidu.com‘, proxies=proxies, timeout=2).status_code == 200: 15 flag = 1 16 break 17 if proxy != "" and flag: 18 print("Request proxy is {}".format(proxy)) 19 request.meta["proxy"] = "http://" + proxy 20 else: 21 print("没有可用的IP!")
然后还要在settings.py中添加如下代码,这样就能使用代理IP了:
1 SPIDER_MIDDLEWARES = { 2 ‘LaGou.middlewares.LaGouProxyMiddleWare‘: 543, 3 }
在item.py中添加如下代码:
1 import scrapy 2 3 4 class LaGouItem(scrapy.Item): 5 city = scrapy.Field() # 城市 6 salary = scrapy.Field() # 薪水 7 position = scrapy.Field() # 职位 8 education = scrapy.Field() # 学历要求 9 company_name = scrapy.Field() # 公司名称 10 company_size = scrapy.Field() # 公司规模 11 finance_stage = scrapy.Field() # 融资阶段
在pipeline.py中添加如下代码:
1 import pymongo 2 3 4 class LaGouPipeline(object): 5 def __init__(self): 6 conn = pymongo.MongoClient(host="127.0.0.1", port=27017) 7 self.col = conn[‘Spider‘].LaGou 8 9 def process_item(self, item, spider): 10 self.col.insert(dict(item)) 11 return item
在spiders文件夹下新建一个spider.py,代码如下:
1 import json 2 import scrapy 3 import codecs 4 import requests 5 from time import sleep 6 from LaGou.items import LaGouItem 7 8 9 class LaGouSpider(scrapy.Spider): 10 name = "LaGouSpider" 11 12 def start_requests(self): 13 # city = input("请输入城市:") 14 # position = input("请输入职位方向:") 15 city = "上海" 16 position = "python" 17 url = "https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false&city={}".format(city) 18 headers = { 19 "Referer": "https://www.lagou.com/jobs/list_{}?city={}&cl=false&fromSearch=true&labelWords=&suginput=".format(codecs.encode(position, ‘utf-8‘), codecs.encode(city, ‘utf-8‘)), 20 "Cookie": "_ga=GA1.2.2138387296.1533785827; user_trace_token=20180809113708-7e257026-9b85-11e8-b9bb-525400f775ce; LGUID=20180809113708-7e25732e-9b85-11e8-b9bb-525400f775ce; index_location_city=%E6%AD%A6%E6%B1%89; LGSID=20180818204040-ea6a6ba4-a2e3-11e8-a9f6-5254005c3644; JSESSIONID=ABAAABAAAGFABEFFF09D504261EB56E3CCC780FB4358A5E; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1534294825,1534596041,1534596389,1534597802; TG-TRACK-CODE=search_code; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1534599373; LGRID=20180818213613-acc3ccc9-a2eb-11e8-9251-525400f775ce; SEARCH_ID=f20ec0fa318244f7bcc0dd981f43d5fe", 21 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36" 22 } 23 data = { 24 "first": "true", 25 "pn": 1, 26 "kd": position 27 } 28 res = requests.post(url, headers=headers, data=data) 29 # 获取相关职位结果数目 30 count = res.json()[‘content‘][‘positionResult‘][‘totalCount‘] 31 # 由于最多显示30页,也就是最多显示450条职位信息 32 page_count = count // 15 + 1 if count <= 450 else 30 33 for i in range(page_count): 34 sleep(5) 35 yield scrapy.FormRequest( 36 url=url, 37 formdata={ 38 "first": "true", 39 "pn": str(i + 1), 40 "kd": position 41 }, 42 callback=self.parse 43 ) 44 45 def parse(self, response): 46 try: 47 # 解码并转成json格式 48 js = json.loads(response.body.decode(‘utf-8‘)) 49 result = js[‘content‘][‘positionResult‘][‘result‘] 50 item = LaGouItem() 51 for i in result: 52 item[‘city‘] = i[‘city‘] 53 item[‘salary‘] = i[‘salary‘] 54 item[‘position‘] = i[‘positionName‘] 55 item[‘education‘] = i[‘education‘] 56 item[‘company_name‘] = i[‘companyFullName‘] 57 item[‘company_size‘] = i[‘companySize‘] 58 item[‘finance_stage‘] = i[‘financeStage‘] 59 yield item 60 except: 61 print(response.body)
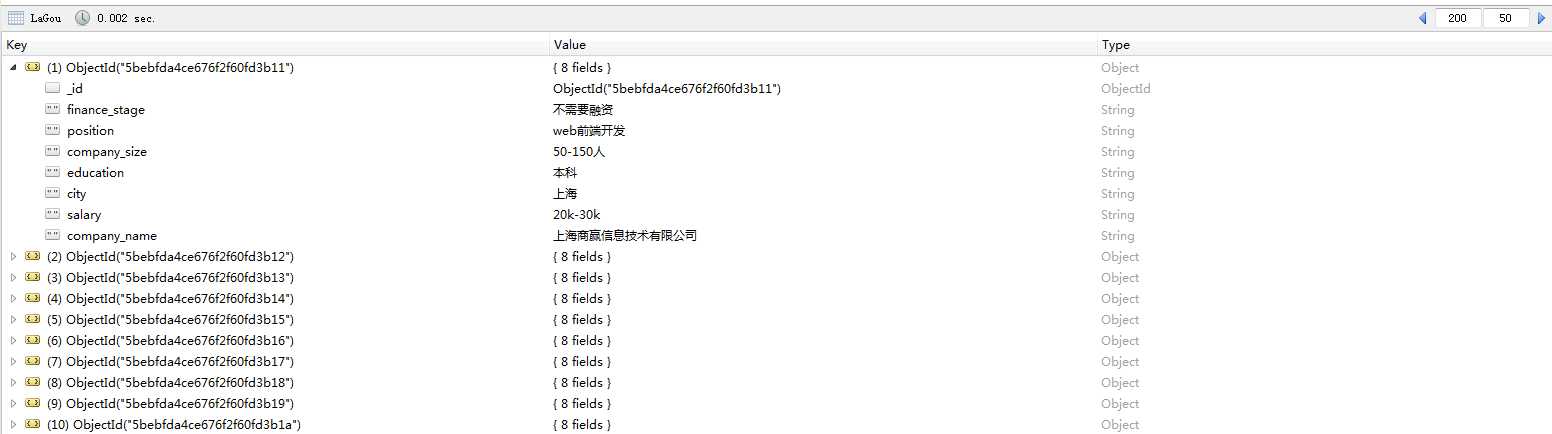
由于使用的是免费代理,短时间内就失效了,所以会碰上爬取不到数据的情况,所以推荐使用付费代理。
完整代码已上传到GitHub:https://github.com/QAQ112233/LaGou
标签:要求 aaa item art success roc for windows 分享
原文地址:https://www.cnblogs.com/TM0831/p/9959900.html