标签:des style blog http color io os ar java
1 环境准备
安装java-1.6(jdk)
安装ssh
1.1 安装jdk
(1)下载安装jdk
在/usr/lib下创建java文件夹,输入命令:
cd /usr/environment
mkdir java
输入命令:
sudo apt-get install sun-java6-jdk
下载后执行安装文件
(2)配置环境变量
输入命令:
sudo gedit /etc/environment
将如下内容加入其中:
JAVA_HOME=/usr/lib/java/jdk1.6.0_45 PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:
/usr/lib/java/jdk1.6.0_45/bin:/usr/lib/java/jdk1.6.0_45:/home/ylf/hadoop/bin:/home/ylf/hadoop/sbin" CLASSPATH=/usr/lib/java/jdk1.6.0_45/lib:/usr/lib/java/jdk1.6.0_45/jre/lib
其中path部分是在你原有的path变量基础上加入你所安装的jdk路径。
执行如下命令使得配置生效:
source /etc/environment
(3)验证java是否安装成功
输入命令:
java -version
1.2 配置ssh免密码登录
输入命令:
sudo apt-get install ssh
配置可以无密码登陆本机:
在当前用户目录下新建隐藏文件.ssh,输入命令:
mkdir .ssh
接下来,输入命令:
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
这个命令会在.ssh文件夹下创建两个文件id_dsa及id_dsa.pub,这是一对私钥和公钥,然后把id_dsa.pub(公钥)追加到授权的key里面去,输入命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
验证ssh已安装成功及无密码登陆本机,输入命令:
ssh -version
显示结果:
Bad escape character ‘rsion‘.
这显示ssh已经安装成功。
登陆ssh,输入命令:
ssh localhost
第一次登陆可能会询问是否继续链接,输入yes即可,以后登陆直接登进去。
显示结果:
Welcome to Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-32-generic x86_64) * Documentation: https://help.ubuntu.com/ Last login: Sun Oct 12 13:27:58 2014 from localhost
2.安装hadoop2.4.0
2.1 下载hadoop2.4.0
从官网上下载hadoop-2.4.0.tar.gz
2.2 解压hadoop-2.4.0.tar.gz,并重命名为hadoop
tar xzvf hadoop-2.4.0.tar.gz
mv hadoop-2.4.0 hadoop
2.3 配置环境变量
sudo gedit /etc/environment
在文件中加入:
HADOOP_HOME=/home/ylf/hadoop PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:
/usr/lib/java/jdk1.6.0_45/bin:/usr/lib/java/jdk1.6.0_45:/home/ylf/hadoop/bin:/home/ylf/hadoop/sbin"
其中path为原有的path变量中加入hadoop的路径。
执行如下命令,使之生效:
source /etc/environment
2.4单机模式配置
单机模式不用任何配置就可以直接进行测试。
运行hadoop自带的wordcount实例,统计一批文本文件中单词出现的次数
bin/hadoop jar /usr/local/hadoop2.4.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar wordcount input output
其中input已经上传至hdfs中,上传命令:
./bin/hdfs dfs -put input /input
2.5 伪分布式模式
2.5.1 修改配置文件
在当前用户目录下创建文件夹hadoop_tmp,输入命令:
mkdir hadoop_tmp
配置文件都在安装目录的etc/hadoop下
修改hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}改为你自己安装的jdk路径:
export JAVA_HOME=/usr/lib/java/jdk1.6.0_45
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/ylf/hadoop_tmp</value>
</property>
</configuration>
修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ylf/hadoop/dfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ylf/hadoop/dfs/datanode</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>localhost:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/home/ylf/hadoop/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/home/ylf/hadoop/mapred/local</value>
<final>true</final>
</property>
</configuration>
修改yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
<description>hostname of Resource Manager</description>
</property>
</configuration>
修改slaves文件
localhost
默认就是localhost,所以不用修改。
启动伪分布式模式:
第一次启动都要格式化下数据文件,命令:
./bin/hdfs namenode -format
启动hadoop,命令:
./sbin/start-all.sh
查看,命令:
jps
结果:
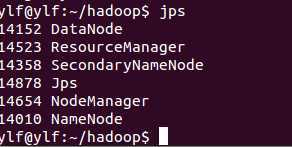
表示启动成功。
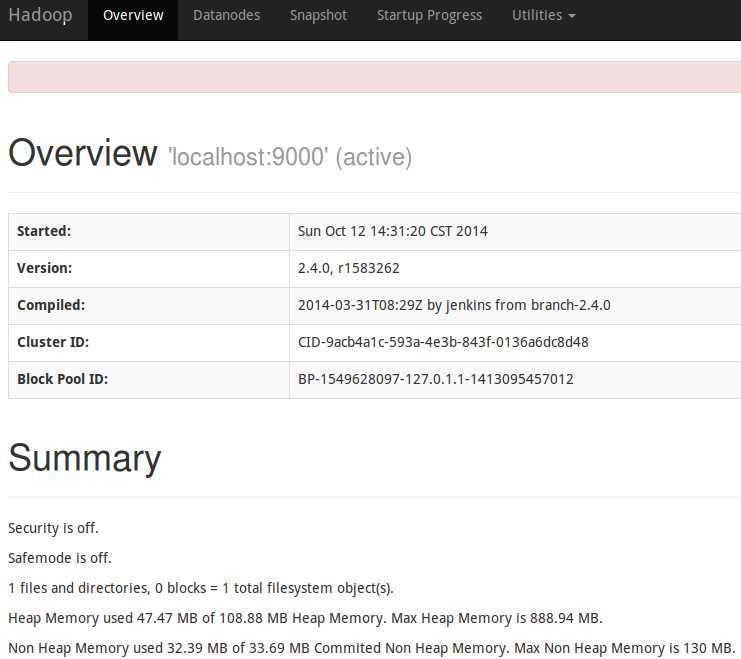
2.6 web访问端口
| NameNode | 50070 |
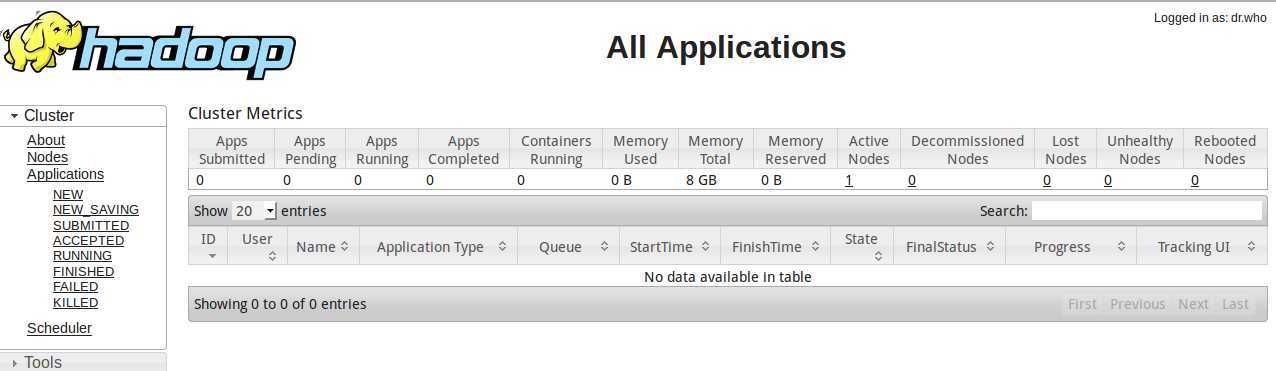
| ResourceManager | 8088 |
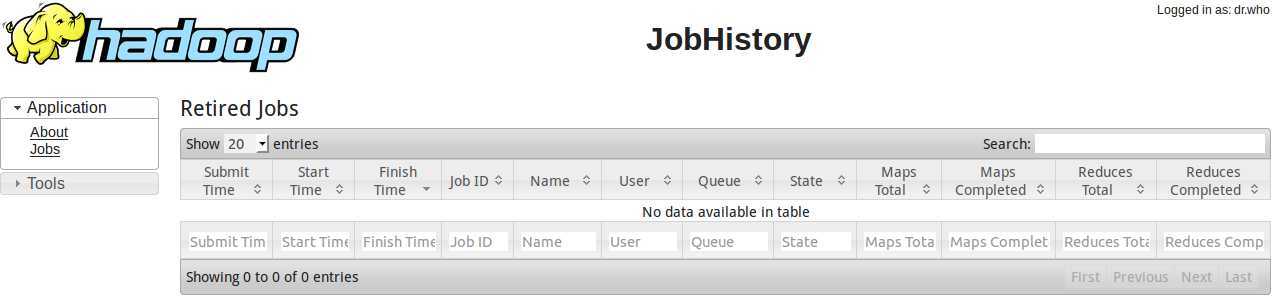
| MapReduce JobHistory Server | 19888 |
访问http://localhost:50070
访问http://localhost:8088
其中19888端口要启动JobHistoryServer进程,启动命令如下:
./sbin/mr-jobhistory-daemon.sh start historyserver
然后访问http://localhost:19888
到此为止,hadoop的伪分布式安装配置讲解完毕。
标签:des style blog http color io os ar java
原文地址:http://www.cnblogs.com/yanglf/p/4020555.html