标签:豆瓣 pen 免费 tree xpath 一般来说 path 使用 页面
一、简介
爬虫就是利用代码大量的将网页前端代码下载下来使用的一种程序,一般来说常见的目的为下:
1、商业分析使用:很多大数据公司都会从利用爬虫来进行数据分析与处理,比如说要了解广州当地二手房的均价走势就可以到房屋中介的网站里去爬取当地房源的价钱除以平方米
2、训练机器:机器学习需要大量的数据,虽然网络上有许多免费的库可以提供学习,不过对于部分机器他们需要的训练资料比较新,所以需要去爬取实时的数据
3、练习爬虫技术:很多网络爬虫其实没有什么商业目的性,只是程序员拿来练习用的
4、其他程序:像是搜索引擎之类的程序也是需要利用爬虫技术来完成他们的功能
一般的网页,尤其是大型的网页,都会进行反爬虫的机制,原因为下:
1、爬虫占用了大量的服务器资源,造成互联网企业的运维成本增加,并且会影响到正常用户的使用
2、部分商业信息是有价值的,不希望被商业对手拿去使用,比如说餐厅评论或是房源资讯
下图是我在网络上看到的爬虫与反爬虫简单介绍,我觉得做的挺好的
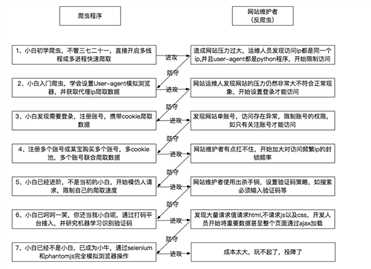
现在许多网站基于用户体验是不会需要用户登录的,更不需要输入验证码之类的,比较常见的是在前端和ID做不规律的变换,让你爬取困难,然后根据IP的浏览状况来封锁
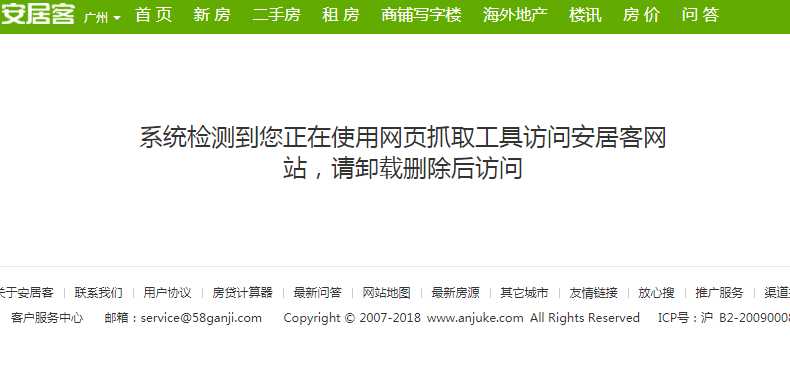
二、爬虫的基本步骤
爬虫的方式很多,但基本上脱离不了这几个步骤
1、找寻URL:每个网页都有个URL,爬虫首先要知道这个网页的URL才能去抓取这个网页的资料,URL里面最重要的就是它里面的ID,像是豆瓣里面,盗梦空间的ID为3541415,蝴蝶效应为1292343,阿凡达为1652587,所有如果我们写程序将ID0-9999999的页面全部爬取完,就可以获得所有豆瓣上的资料,但其实里面大部分的ID都是没有内容的页面,这会大幅度降低我们爬虫的效率,另外一种方式是利用前端代码里面的URL找寻目标,一般来说,像是淘宝首页,会有许多的URL可以抓取,而进入商品网页后又有相关商品的URL可以抓取,利用这种方式可以高效的抓取URL,但缺点是抓不全,而且容易陷入循环,抓取重复的URL。
下图为搜狐新闻的网页,利用查看可以很快的看到新闻URL的位置
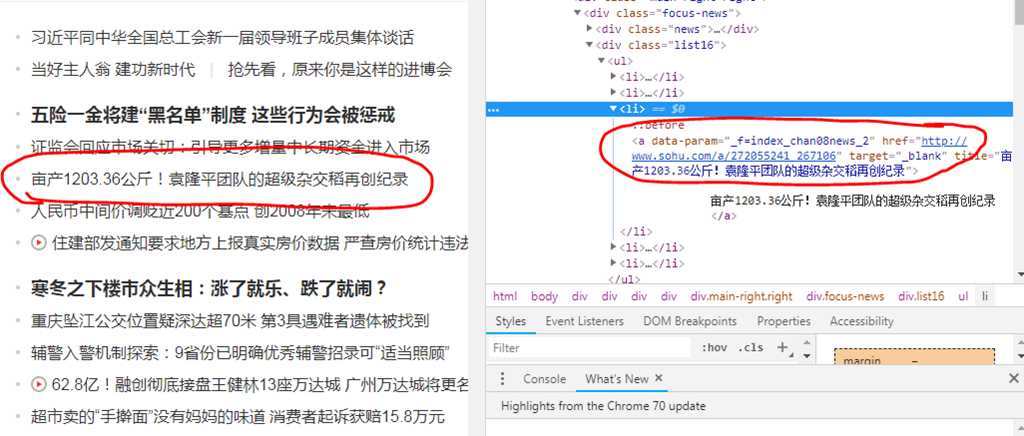
利用复制下几个新闻链接的XPATH,可以发现其规律,再利用XPATH去抓这些URL,这边由于搜狐在前端有加了反爬虫的机制,所以比较难一次爬全,需要多尝试几种XPATH才能获得首页所有的新闻链接,下面的代码可以帮助获取首页部分的新闻URL位置
def link_list(): url = ‘http://news.sohu.com/‘ data = requests.get(url).text s = etree.HTML(data) links = s.xpath(‘/html/body/div[1]/div[5]/div[1]/div/div[2]/div/div/ul/li/a/@href‘)
2、下载页面:利用URL找寻到页面后,将页面下载下来,python可以用requests组件来执行这个动作
url = ‘http://news.sohu.com/‘ data = requests.get(url).text
3、提取有用数据:由于网页前端含有大量的HTML标注代码,并且还包含了大量我们不需要的东西,像是我要获取房屋的均价,我只需要房屋的价钱跟面积就可以了,剩下的那些介绍我都不需要,这就需要利用一些组件来提取数据了,python里比较常见的是beautifulsoup跟lxml,下面是利用lxml来解析HTML再提取文章的标题 (需要先找到标题的XPATH)
s = etree.HTML(data) titles = s.xpath(‘/html/body/div[1]/div[5]/div[1]/div/div[2]/div/div/ul/li/a/text()‘)
4、储存数据:将数据提取出来当然是要找地方储存,我是储存在txt档里,当然也可以用其他格式储存,下面是将搜狐的URL用for循环跑了一遍,并将新闻的内容提取出来储存在txt里面以供使用
for link in links: content = requests.get(link).text s = etree.HTML(content) words = s.xpath(‘//*[@id="mp-editor"]/p/text()‘) print(words) f = open(‘news2.txt‘,‘a‘) for word in words: f = open(‘news2.txt‘,‘a‘) f.write(word) f.write("\n") f.write("---------------------------------------") f.close()
以下为抓取到的新闻标题与内容,只截取了部分,可以看到已经是纯文字了,而且是我们要的新闻内容

由于搜狐也是有前端反爬虫的保护,所以一开始在抓取内容的时候容易漏抓部分的内容,但多观察几篇的代码就可以找出它变化的规律,将所有的规律写入就可以提高抓取的完整度。

标签:豆瓣 pen 免费 tree xpath 一般来说 path 使用 页面
原文地址:https://www.cnblogs.com/yenpaul/p/9968015.html