标签:hard link bubuko ice 现在 pass 存放位置 while pos sage
docker network create --subnet=192.168.0.0/16 staticnet
docker run -d --privileged -v `pwd`/mysql_data:/data -p 3001:3306 --name mysql5-master --hostname mysql5-master --net staticnet --ip 192.168.0.101 eiki/mysql:5.7.23 /usr/sbin/init docker run -d --privileged -v `pwd`/mysql_data:/data -p 3002:3306 --name mysql5-slave --hostname mysql5-slave --net staticnet --ip 192.168.0.102 eiki/mysql:5.7.23 /usr/sbin/init docker run -d --privileged -v `pwd`/mysql_data:/data -p 3003:3306 --name mysql5-s2 --hostname mysql5-s2 --net staticnet --ip 192.168.0.103 eiki/mysql:5.7.23 /usr/sbin/init docker run -d --privileged -v `pwd`/mysql_data:/data -p 7032:6032 -p 6080:6080 --name proxysql2 --hostname proxysql2 --net staticnet --ip 192.168.0.202 eiki/proxysql:latest /usr/sbin/init docker run -d --privileged -v `pwd`/mysql_data:/data -p 6032:6032 -p 7080:6080 --name proxysql --hostname proxysql --net staticnet --ip 192.168.0.201 eiki/proxysql:latest /usr/sbin/init 其中6032是管理端口,6033是程序端口,6080是http端口
MySQL安装过程略
[mysql] prompt = [\\u@\\h][\\d]>\\_ port = 3306 socket = /usr/local/mysql/mysql.sock [mysqld] user = mysql port = 3306 server-id = 1 pid-file = /usr/local/mysql/mysqld.pid socket = /usr/local/mysql/mysql.sock basedir = /usr/local/mysql datadir = /usr/local/mysql/data log-bin = master-bin log-bin-index = master-bin.index relay_log_purge = 0 #以下两个参数不加,从执行change不可以指定channel(ERROR 3077 (HY000)) master_info_repository =table relay_log_info_repository =table
[mysql] prompt = [\\u@\\h][\\d]>\\_ port = 3306 socket = /usr/local/mysql/mysql.sock [mysqld] user = mysql port = 3306 server-id = 101 pid-file = /usr/local/mysql/mysqld.pid socket = /usr/local/mysql/mysql.sock basedir = /usr/local/mysql datadir = /usr/local/mysql/data relay-log-index = slave-relay-bin.index relay-log = slave-relay-bin relay_log_purge = 0 #以下两个参数不加,从执行change不可以指定channel(ERROR 3077 (HY000)) master_info_repository =table relay_log_info_repository =table
create user repl@‘192.168.0.%‘ identified by ‘repl‘; grant replication slave on *.* to repl@‘%‘; flush privileges;
mysqldump --master-data=2 --single-transaction -R --triggers -A > all.sql
其中--master-data=2代表备份时刻记录master的Binlog位置和Position,--single-transaction意思是获取一致性快照,-R意思是备份存储过程和函数,--triggres的意思是备份触发器,-A代表备份所有的库。更多信息请自行mysqldump --help查看。
[root@mysql5-master ~]# head -n 30 all.sql | grep ‘CHANGE MASTER TO‘ -- CHANGE MASTER TO MASTER_LOG_FILE=‘mysql-bin.000010‘, MASTER_LOG_POS=112;
scp all.sql root@192.168.0.102:/data/ scp all.sql root@192.168.0.102:/data/
mysql -uroot -p < /data/all.sql
CHANGE MASTER TO MASTER_HOST=‘192.168.0.101‘,MASTER_USER=‘repl‘,MASTER_PASSWORD=‘repl‘,MASTER_LOG_FILE=‘master-bin.000007‘,MASTER_LOG_POS=739 for channel ‘s1‘;
start slave for channel ‘s1‘;
show slave status\G;
[root@s1 ~]# mysql -e ‘show slave status\G‘ | egrep ‘Slave_IO|Slave_SQL‘
Slave_IO_State: Waiting for master to send event
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
另外一个从节点搭建复制环境,操作和上面一样
[root@s1 ~]# mysql -e ‘set global read_only=1‘ [root@s1 ~]# [root@s2 ~]# mysql -e ‘set global read_only=1‘ [root@s2 ~]#
创建管理账号(主库执行)
grant replication slave,reload,create user,super on *.* to mats@‘%‘ identified by ‘mats‘ with grant option;
至此一主两从架构搭建完毕
openssh的安装步骤: yum -y install openssh* systemctl start sshd

ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.102 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.103 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.201 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.202 ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.101 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.103 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.201 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.202 ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.101 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.102 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.201 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.202 ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.101 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.102 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.103 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.202 ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.101 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.102 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.103 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.201
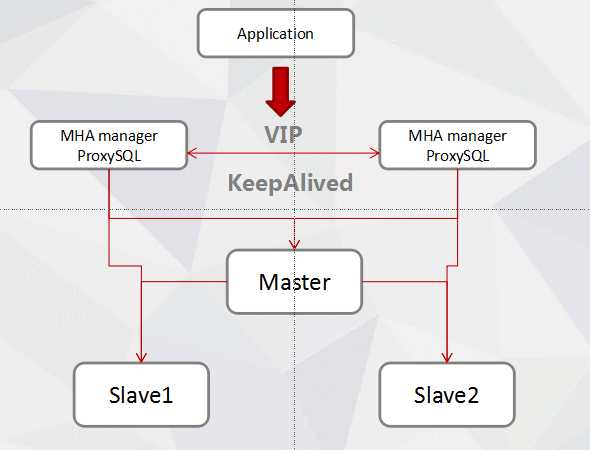
角色 ip地址 主机名 server_id 类型 Monitor host 192.168.0.201 ProxySQL - 监控复制组 Master 192.168.0.101 master 1 写入 Candicate master 192.168.0.102 s1 101 读 Slave 192.168.0.103 s2 102 读
其中master对外提供写服务,备选master(实际的slave,主机名s1)提供读服务,slave也提供相关的读服务,一旦master宕机,将会把备选master提升为新的master,slave指向新的master
官方网址
Manager:https://github.com/yoshinorim/mha4mysql-manager
Node: https://github.com/yoshinorim/mha4mysql-node
https://github.com/yoshinorim/mha4mysql-manager/wiki
参考来源:https://www.cnblogs.com/gomysql/p/3675429.html
git clone https://github.com/yoshinorim/mha4mysql-manager git clone https://github.com/yoshinorim/mha4mysql-node
yum install glib2-devel libpcap-devel libnet-devel cmake gc++ gcc gcc-c++ make git yum install gcc gcc-c++ kernel-devel perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes perl-Module-Install -y
cd mha4mysql-node-0.58 perl Makefile.PL make && make install
安装完成后会在/usr/local/bin目录下生成以下脚本文件:
[root@mysql5-master src]# ll /usr/local/bin total 80 -r-xr-xr-x. 1 root root 17639 Nov 14 15:46 apply_diff_relay_logs -r-xr-xr-x. 1 root root 7138 Nov 14 15:43 config_data -r-xr-xr-x. 1 root root 4807 Nov 14 15:46 filter_mysqlbinlog -r-xr-xr-x. 1 root root 4371 Nov 14 15:43 json_pp lrwxrwxrwx. 1 root root 26 Nov 14 17:02 mysql -> /usr/local/mysql/bin/mysql lrwxrwxrwx. 1 root root 32 Nov 14 17:02 mysqlbinlog -> /usr/local/mysql/bin/mysqlbinlog -r-xr-xr-x. 1 root root 13649 Nov 14 15:43 prove -r-xr-xr-x. 1 root root 8337 Nov 14 15:46 purge_relay_logs -r-xr-xr-x. 1 root root 7525 Nov 14 15:46 save_binary_logs
cd mha4mysql-node-0.58 perl Makefile.PL make && make install
安装完成后会在/usr/local/bin目录下面生成以下脚本文件
[root@proxysql 3306]# ll /usr/local/bin total 92 -r-xr-xr-x. 1 root root 17639 Nov 14 15:52 apply_diff_relay_logs -r-xr-xr-x. 1 root root 4807 Nov 14 15:52 filter_mysqlbinlog -rw-r--r--. 1 root root 74 Nov 14 16:36 load_cnf -r-xr-xr-x. 1 root root 1995 Nov 14 15:54 masterha_check_repl -r-xr-xr-x. 1 root root 1779 Nov 14 15:54 masterha_check_ssh -r-xr-xr-x. 1 root root 1865 Nov 14 15:54 masterha_check_status -r-xr-xr-x. 1 root root 3201 Nov 14 15:54 masterha_conf_host -r-xr-xr-x. 1 root root 2517 Nov 14 15:54 masterha_manager -r-xr-xr-x. 1 root root 2165 Nov 14 15:54 masterha_master_monitor -r-xr-xr-x. 1 root root 2373 Nov 14 15:54 masterha_master_switch -r-xr-xr-x. 1 root root 5172 Nov 14 15:54 masterha_secondary_check -r-xr-xr-x. 1 root root 1739 Nov 14 15:54 masterha_stop -r-xr-xr-x. 1 root root 8337 Nov 14 15:52 purge_relay_logs -r-xr-xr-x. 1 root root 7525 Nov 14 15:52 save_binary_logs
复制相关脚本到/etc/mha/scripts目录(软件包解压缩后就有了,不是必须,因为这些脚本不完整,需要自己修改,这是软件开发着留给我们自己发挥的,如果开启下面的任何一个脚本对应的参数,而对应这里的脚本又没有修改,则会抛错,自己被坑的很惨)
mkdir -p /data/mha/3306/log mkdir -p /etc/mha/scripts cp /data/mha4mysql-manager-master/samples/scripts/* /etc/mha/scripts
[root@proxysql 3306]# ll /etc/mha/scripts total 36 -rwxr-xr-x. 1 root root 150 Nov 14 17:53 manager.sh -rwxr-xr-x. 1 root root 2169 Nov 14 17:27 master_ip_failover #自动切换时vip管理的脚本,不是必须,如果我们使用keepalived的,我们可以自己编写脚本完成对vip的管理,比如监控mysql,如果mysql异常,我们停止keepalived就行,这样vip就会自动漂移 -rwxr-xr-x. 1 root root 10369 Nov 14 17:38 master_ip_online_change #在线切换时vip的管理,不是必须,同样可以可以自行编写简单的shell完成 -rwxr-xr-x. 1 root root 11867 Nov 14 16:41 power_manager #故障发生后关闭主机的脚本,不是必须 -rwxr-xr-x. 1 root root 1360 Nov 14 16:41 send_report #因故障切换后发送报警的脚本,不是必须,可自行编写简单的shell完成。
cat >> /etc/masterha_default.cnf << EOF [server default] user=root password=abc123 ssh_user=root repl_user=repl repl_password=repl ping_interval=1 #master_binlog_dir= /var/lib/mysql,/var/log/mysql secondary_check_script=masterha_secondary_check -s 192.168.0.101 -s 192.168.0.102 -s 192.168.0.103 master_ip_failover_script="/etc/mha/scripts/master_ip_failover" master_ip_online_change_script="/etc/mha/scripts/master_ip_online_change" report_script="/etc/mha/scripts/send_report" EOF
cat >>/data/mha/3306/mha.cnf << EOF [server default] manager_workdir=/data/mha/3306 manager_log=/data/mha/3306/manager.log [server1] hostname=192.168.0.101 candidate_master=1 master_binlog_dir="/usr/local/mysql/data" [server2] hostname=192.168.0.102 candidate_master=1 master_binlog_dir="/usr/local/mysql/data" [server3] hostname=192.168.0.103 master_binlog_dir="/usr/local/mysql/data" #表示没有机会成为master no_master=1 EOF
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/local/bin/mysqlbinlog ln -s /usr/local/mysql/bin/mysql /usr/local/bin/mysql
cat >> /etc/mha/scripts/master_ip_failover << EOF
#!/usr/bin/env perl
use strict;
use warnings FATAL => ‘all‘;
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = ‘192.168.0.88/24‘; #设置VIP
my $key = ‘1‘;
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; #注意网卡,根据实际情况改写
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; #注意网卡,根据实际情况改写
GetOptions(
‘command=s‘ => \$command,
‘ssh_user=s‘ => \$ssh_user,
‘orig_master_host=s‘ => \$orig_master_host,
‘orig_master_ip=s‘ => \$orig_master_ip,
‘orig_master_port=i‘ => \$orig_master_port,
‘new_master_host=s‘ => \$new_master_host,
‘new_master_ip=s‘ => \$new_master_ip,
‘new_master_port=i‘ => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
EOF
cat >> /etc/mha/scripts/master_ip_online_change << EOF
#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => ‘all‘;
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofday tv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_host, $orig_master_ip,
$orig_master_port, $orig_master_user,
$new_master_host, $new_master_ip, $new_master_port,
$new_master_user,
);
my $vip = ‘192.168.0.88/24‘; # Virtual IP
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
my $ssh_user = "root";
my $new_master_password=‘abc123‘;
my $orig_master_password=‘abc123‘;
GetOptions(
‘command=s‘ => \$command,
#‘ssh_user=s‘ => \$ssh_user,
‘orig_master_host=s‘ => \$orig_master_host,
‘orig_master_ip=s‘ => \$orig_master_ip,
‘orig_master_port=i‘ => \$orig_master_port,
‘orig_master_user=s‘ => \$orig_master_user,
#‘orig_master_password=s‘ => \$orig_master_password,
‘new_master_host=s‘ => \$new_master_host,
‘new_master_ip=s‘ => \$new_master_ip,
‘new_master_port=i‘ => \$new_master_port,
‘new_master_user=s‘ => \$new_master_user,
#‘new_master_password=s‘ => \$new_master_password,
);
exit &main();
sub current_time_us {
my ( $sec, $microsec ) = gettimeofday();
my $curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec );
}
sub sleep_until {
my $elapsed = tv_interval($_tstart);
if ( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my $dbh = shift;
my $my_connection_id = shift;
my $running_time_threshold = shift;
my $type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless ($type);
my @threads;
my $sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command = $ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time < $running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect" );
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if ( $command eq "stop" ) {
## Gracefully killing connections on the current master
# 1. Set read_only= 1 on the new master
# 2. DROP USER so that no app user can establish new connections
# 3. Set read_only= 1 on the current master
# 4. Kill current queries
# * Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master.. ";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
#$orig_master_handler->disable_log_bin_local();
#print current_time_us() . " Drpping app user on the orig master..\n";
#FIXME_xxx_drop_app_user($orig_master_handler);
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(except SUPER) can write
print current_time_us() . " Set read_only=1 on the orig master.. ";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries can complete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
## Terminating all threads
print current_time_us() . " Killing all application threads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
print current_time_us() . " done.\n";
#$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
# 1. Create app user with write privileges
# 2. Moving backup script if needed
# 3. Register new master‘s ip to the catalog database
# We don‘t return error even though activating updatable accounts/ip failed so that we don‘t interrupt slaves‘ recovery.
# If exit code is 0 or 10, MHA does not abort
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
#$new_master_handler->disable_log_bin_local();
print current_time_us() . " Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
#print current_time_us() . " Creating app user on the new master..\n";
#FIXME_xxx_create_app_user($new_master_handler);
#$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
die;
}
EOF
cat >> /etc/mha/scripts/send_report << EOF #!/usr/bin/perl # Copyright (C) 2011 DeNA Co.,Ltd. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; either version 2 of the License, or # (at your option) any later version. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => ‘all‘; use Getopt::Long; #new_master_host and new_slave_hosts are set only when recovering master succeeded my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body ); GetOptions( ‘orig_master_host=s‘ => \$dead_master_host, ‘new_master_host=s‘ => \$new_master_host, ‘new_slave_hosts=s‘ => \$new_slave_hosts, ‘subject=s‘ => \$subject, ‘body=s‘ => \$body, ); # Do whatever you want here exit 0; EOF
[root@s1 ~]# mysql -e ‘set global relay_log_purge=0‘ [root@s2 ~]# mysql -e ‘set global relay_log_purge=0‘
注意:
MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式)
MHA节点中包含了pure_relay_logs命令工具,它可以为中继日志创建硬链接,执行SET GLOBAL relay_log_purge=1,等待几秒钟以便SQL线程切换到新的中继日志,再执行SET GLOBAL relay_log_purge=0。
pure_relay_logs脚本参数如下所示:
--user mysql 用户名 --password mysql 密码 --port 端口号 --workdir 指定创建relay log的硬链接的位置,默认是/var/tmp,由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继日志文件被删除 --disable_relay_log_purge 默认情况下,如果relay_log_purge=1,脚本会什么都不清理,自动退出,通过设定这个参数,当relay_log_purge=1的情况下会将relay_log_purge设置为0。清理relay log之后,最后将参数设置为OFF。
cat >> purge_relay_log.sh << EOF #!/bin/bash user=root passwd=123456 port=3306 log_dir=‘/data/masterha/log‘ work_dir=‘/data‘ purge=‘/usr/local/bin/purge_relay_logs‘ if [ ! -d $log_dir ] then mkdir $log_dir -p fi $purge --user=$user --password=$passwd --disable_relay_log_purge --port=$port --workdir=$work_dir >> $log_dir/purge_relay_logs.log 2>&1 EOF
添加到crontab定期执行
[root@s1 ~]# crontab -l 0 4 * * * /bin/bash /root/purge_relay_log.sh
purge_relay_logs脚本删除中继日志不会阻塞SQL线程。下面我们手动执行看看什么情况。
[root@s1 ~]# purge_relay_logs --user=root --password=123456 --port=3306 -disable_relay_log_purge --workdir=/data/ 2014-04-20 15:47:24: purge_relay_logs script started. Found relay_log.info: /data/mysql/relay-log.info Removing hard linked relay log files server03-relay-bin* under /data/.. done. Current relay log file: /data/mysql/server03-relay-bin.000002 Archiving unused relay log files (up to /data/mysql/server03-relay-bin.000001) ... Creating hard link for /data/mysql/server03-relay-bin.000001 under /data//server03-relay-bin.000001 .. ok. Creating hard links for unused relay log files completed. Executing SET GLOBAL relay_log_purge=1; FLUSH LOGS; sleeping a few seconds so that SQL thread can delete older relay log files (if it keeps up); SET GLOBAL relay_log_purge=0; .. ok. Removing hard linked relay log files server03-relay-bin* under /data/.. done. 2014-04-20 15:47:27: All relay log purging operations succeeded.
检查MHA Manger到所有MHA Node的SSH连接状态
[root@proxysql 3306]# masterha_check_ssh --conf=/data/mha/3306/mha.cnf Fri Nov 16 11:26:15 2018 - [info] Reading default configuration from /etc/masterha_default.cnf.. Fri Nov 16 11:26:15 2018 - [info] Reading application default configuration from /data/mha/3306/mha.cnf.. Fri Nov 16 11:26:15 2018 - [info] Reading server configuration from /data/mha/3306/mha.cnf.. Fri Nov 16 11:26:15 2018 - [info] Starting SSH connection tests.. Fri Nov 16 11:26:16 2018 - [debug] Fri Nov 16 11:26:15 2018 - [debug] Connecting via SSH from root@192.168.0.101(192.168.0.101:22) to root@192.168.0.102(192.168.0.102:22).. Fri Nov 16 11:26:16 2018 - [debug] ok. Fri Nov 16 11:26:16 2018 - [debug] Connecting via SSH from root@192.168.0.101(192.168.0.101:22) to root@192.168.0.103(192.168.0.103:22).. Fri Nov 16 11:26:16 2018 - [debug] ok. Fri Nov 16 11:26:17 2018 - [debug] Fri Nov 16 11:26:16 2018 - [debug] Connecting via SSH from root@192.168.0.102(192.168.0.102:22) to root@192.168.0.101(192.168.0.101:22).. Fri Nov 16 11:26:16 2018 - [debug] ok. Fri Nov 16 11:26:16 2018 - [debug] Connecting via SSH from root@192.168.0.102(192.168.0.102:22) to root@192.168.0.103(192.168.0.103:22).. Fri Nov 16 11:26:16 2018 - [debug] ok. Fri Nov 16 11:26:18 2018 - [debug] Fri Nov 16 11:26:16 2018 - [debug] Connecting via SSH from root@192.168.0.103(192.168.0.103:22) to root@192.168.0.101(192.168.0.101:22).. Fri Nov 16 11:26:17 2018 - [debug] ok. Fri Nov 16 11:26:17 2018 - [debug] Connecting via SSH from root@192.168.0.103(192.168.0.103:22) to root@192.168.0.102(192.168.0.102:22).. Fri Nov 16 11:26:17 2018 - [debug] ok. Fri Nov 16 11:26:18 2018 - [info] All SSH connection tests passed successfully.
通过masterha_check_repl脚本查看整个集群的状态
[root@proxysql 3306]# masterha_check_repl --conf=/data/mha/3306/mha.cnf
Fri Nov 16 11:27:25 2018 - [info] Reading default configuration from /etc/masterha_default.cnf..
Fri Nov 16 11:27:25 2018 - [info] Reading application default configuration from /data/mha/3306/mha.cnf..
Fri Nov 16 11:27:25 2018 - [info] Reading server configuration from /data/mha/3306/mha.cnf..
Fri Nov 16 11:27:25 2018 - [info] MHA::MasterMonitor version 0.58.
Fri Nov 16 11:27:26 2018 - [info] GTID failover mode = 0
Fri Nov 16 11:27:26 2018 - [info] Dead Servers:
Fri Nov 16 11:27:26 2018 - [info] Alive Servers:
Fri Nov 16 11:27:26 2018 - [info] 192.168.0.101(192.168.0.101:3306)
Fri Nov 16 11:27:26 2018 - [info] 192.168.0.102(192.168.0.102:3306)
Fri Nov 16 11:27:26 2018 - [info] 192.168.0.103(192.168.0.103:3306)
Fri Nov 16 11:27:26 2018 - [info] Alive Slaves:
Fri Nov 16 11:27:26 2018 - [info] 192.168.0.102(192.168.0.102:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabled
Fri Nov 16 11:27:26 2018 - [info] Replicating from 192.168.0.101(192.168.0.101:3306)
Fri Nov 16 11:27:26 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Nov 16 11:27:26 2018 - [info] 192.168.0.103(192.168.0.103:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabled
Fri Nov 16 11:27:26 2018 - [info] Replicating from 192.168.0.101(192.168.0.101:3306)
Fri Nov 16 11:27:26 2018 - [info] Not candidate for the new Master (no_master is set)
Fri Nov 16 11:27:26 2018 - [info] Current Alive Master: 192.168.0.101(192.168.0.101:3306)
Fri Nov 16 11:27:26 2018 - [info] Checking slave configurations..
Fri Nov 16 11:27:26 2018 - [info] Checking replication filtering settings..
Fri Nov 16 11:27:26 2018 - [info] binlog_do_db= , binlog_ignore_db=
Fri Nov 16 11:27:26 2018 - [info] Replication filtering check ok.
Fri Nov 16 11:27:26 2018 - [info] GTID (with auto-pos) is not supported
Fri Nov 16 11:27:26 2018 - [info] Starting SSH connection tests..
Fri Nov 16 11:27:29 2018 - [info] All SSH connection tests passed successfully.
Fri Nov 16 11:27:29 2018 - [info] Checking MHA Node version..
Fri Nov 16 11:27:29 2018 - [info] Version check ok.
Fri Nov 16 11:27:29 2018 - [info] Checking SSH publickey authentication settings on the current master..
Fri Nov 16 11:27:29 2018 - [info] HealthCheck: SSH to 192.168.0.101 is reachable.
Fri Nov 16 11:27:30 2018 - [info] Master MHA Node version is 0.58.
Fri Nov 16 11:27:30 2018 - [info] Checking recovery script configurations on 192.168.0.101(192.168.0.101:3306)..
Fri Nov 16 11:27:30 2018 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/usr/local/mysql/data --output_file=/var/tmp/save_binary_logs_test --manager_version=0.58 --start_file=master-bin.000003
Fri Nov 16 11:27:30 2018 - [info] Connecting to root@192.168.0.101(192.168.0.101:22)..
Creating /var/tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /usr/local/mysql/data, up to master-bin.000003
Fri Nov 16 11:27:30 2018 - [info] Binlog setting check done.
Fri Nov 16 11:27:30 2018 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Fri Nov 16 11:27:30 2018 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user=‘root‘ --slave_host=192.168.0.102 --slave_ip=192.168.0.102 --slave_port=3306 --workdir=/var/tmp --target_version=5.7.23-log --manager_version=0.58 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Fri Nov 16 11:27:30 2018 - [info] Connecting to root@192.168.0.102(192.168.0.102:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to slave-relay-bin.000002
Temporary relay log file is /usr/local/mysql/data/slave-relay-bin.000002
Checking if super_read_only is defined and turned on.. not present or turned off, ignoring.
Testing mysql connection and privileges..
mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Fri Nov 16 11:27:30 2018 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user=‘root‘ --slave_host=192.168.0.103 --slave_ip=192.168.0.103 --slave_port=3306 --workdir=/var/tmp --target_version=5.7.23-log --manager_version=0.58 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Fri Nov 16 11:27:30 2018 - [info] Connecting to root@192.168.0.103(192.168.0.103:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to slave-relay-bin.000002
Temporary relay log file is /usr/local/mysql/data/slave-relay-bin.000002
Checking if super_read_only is defined and turned on.. not present or turned off, ignoring.
Testing mysql connection and privileges..
mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Fri Nov 16 11:27:30 2018 - [info] Slaves settings check done.
Fri Nov 16 11:27:30 2018 - [info]
192.168.0.101(192.168.0.101:3306) (current master)
+--192.168.0.102(192.168.0.102:3306)
+--192.168.0.103(192.168.0.103:3306)
Fri Nov 16 11:27:30 2018 - [info] Checking replication health on 192.168.0.102..
Fri Nov 16 11:27:30 2018 - [info] ok.
Fri Nov 16 11:27:30 2018 - [info] Checking replication health on 192.168.0.103..
Fri Nov 16 11:27:30 2018 - [info] ok.
Fri Nov 16 11:27:30 2018 - [info] Checking master_ip_failover_script status:
Fri Nov 16 11:27:30 2018 - [info] /etc/mha/scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.0.101 --orig_master_ip=192.168.0.101 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.0.88/24===
Checking the Status of the script.. OK
Fri Nov 16 11:27:30 2018 - [info] OK.
Fri Nov 16 11:27:30 2018 - [warning] shutdown_script is not defined.
Fri Nov 16 11:27:30 2018 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
[root@proxysql 3306]#
[root@proxysql 3306]# masterha_check_status --conf=/data/mha/3306/mha.cnf mha is stopped(2:NOT_RUNNING).
vi manager.sh nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /data/mha/3306/manager.log 2>&1 & ./manager.sh
启动参数介绍:
--remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面我设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。
vip配置可以采用两种方式,一种通过keepalived的方式管理虚拟ip的浮动;另外一种通过脚本方式启动虚拟ip的方式(即不需要keepalived或者heartbeat类似的软件)。
(一)使用脚本管理VIP 的方式, 修改master_ip_failover 脚本,使用脚本管理VIP:
通过配置/etc/mha/scripts/master_ip_failover实现
(二)keepalived方式管理虚拟ip
下载软件进行并进行安装(两台master,准确的说一台是master,另外一台是备选master,在没有切换以前是slave):
[root@master ~]# wget http://www.keepalived.org/software/keepalived-1.2.12.tar.gz

tar xf keepalived-1.2.12.tar.gz cd keepalived-1.2.12 ./configure --prefix=/usr/local/keepalived make && make install cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ mkdir /etc/keepalived cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
(2)配置keepalived的配置文件,在master上配置(192.168.0.101)
[root@master ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
saltstack@163.com
}
notification_email_from dba@dbserver.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MySQL-HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.88
}
}
[root@192.168.0.50 ~]#
其中router_id MySQL HA表示设定keepalived组的名称,将192.168.0.88这个虚拟ip绑定到该主机的eth1网卡上,并且设置了状态为backup模式,将keepalived的模式设置为非抢占模式(nopreempt),priority 150表示设置的优先级为150。下面的配置略有不同,但是都是一个意思。
在候选master上配置(192.168.0.60)
[root@192.168.0.60 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
saltstack@163.com
}
notification_email_from dba@dbserver.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MySQL-HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 120
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.88
}
}
[root@192.168.0.60 ~]#
(3)启动keepalived服务,在master上启动并查看日志
[root@192.168.0.50 ~]# /etc/init.d/keepalived start Starting keepalived: [ OK ] [root@192.168.0.50 ~]# tail -f /var/log/messages Apr 20 20:22:16 192 Keepalived_healthcheckers[15334]: Opening file ‘/etc/keepalived/keepalived.conf‘. Apr 20 20:22:16 192 Keepalived_healthcheckers[15334]: Configuration is using : 7231 Bytes Apr 20 20:22:16 192 kernel: IPVS: Connection hash table configured (size=4096, memory=64Kbytes) Apr 20 20:22:16 192 kernel: IPVS: ipvs loaded. Apr 20 20:22:16 192 Keepalived_healthcheckers[15334]: Using LinkWatch kernel netlink reflector... Apr 20 20:22:19 192 Keepalived_vrrp[15335]: VRRP_Instance(VI_1) Transition to MASTER STATE Apr 20 20:22:20 192 Keepalived_vrrp[15335]: VRRP_Instance(VI_1) Entering MASTER STATE Apr 20 20:22:20 192 Keepalived_vrrp[15335]: VRRP_Instance(VI_1) setting protocol VIPs. Apr 20 20:22:20 192 Keepalived_vrrp[15335]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.0.88 Apr 20 20:22:20 192 Keepalived_healthcheckers[15334]: Netlink reflector reports IP 192.168.0.88 added Apr 20 20:22:25 192 Keepalived_vrrp[15335]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.0.88
发现已经将虚拟ip 192.168.0.88绑定了网卡eth1上。
(4)查看绑定情况
[root@192.168.0.50 ~]# ip addr | grep eth1
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 192.168.0.50/24 brd 192.168.0.255 scope global eth1
inet 192.168.0.88/32 scope global eth1
[root@192.168.0.50 ~]#
在另外一台服务器,候选master上启动keepalived服务,并观察
[root@192.168.0.60 ~]# /etc/init.d/keepalived start ; tail -f /var/log/messages Starting keepalived: [ OK ] Apr 20 20:26:18 192 Keepalived_vrrp[9472]: Registering gratuitous ARP shared channel Apr 20 20:26:18 192 Keepalived_vrrp[9472]: Opening file ‘/etc/keepalived/keepalived.conf‘. Apr 20 20:26:18 192 Keepalived_vrrp[9472]: Configuration is using : 62976 Bytes Apr 20 20:26:18 192 Keepalived_vrrp[9472]: Using LinkWatch kernel netlink reflector... Apr 20 20:26:18 192 Keepalived_vrrp[9472]: VRRP_Instance(VI_1) Entering BACKUP STATE Apr 20 20:26:18 192 Keepalived_vrrp[9472]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Netlink reflector reports IP 192.168.80.138 added Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Netlink reflector reports IP 192.168.0.60 added Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Netlink reflector reports IP fe80::20c:29ff:fe9d:6a9e added Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Netlink reflector reports IP fe80::20c:29ff:fe9d:6aa8 added Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Registering Kernel netlink reflector Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Registering Kernel netlink command channel Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Opening file ‘/etc/keepalived/keepalived.conf‘. Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Configuration is using : 7231 Bytes Apr 20 20:26:18 192 kernel: IPVS: Registered protocols (TCP, UDP, AH, ESP) Apr 20 20:26:18 192 kernel: IPVS: Connection hash table configured (size=4096, memory=64Kbytes) Apr 20 20:26:18 192 kernel: IPVS: ipvs loaded. Apr 20 20:26:18 192 Keepalived_healthcheckers[9471]: Using LinkWatch kernel netlink reflector...
从上面的信息可以看到keepalived已经配置成功。
注意:
上面两台服务器的keepalived都设置为了BACKUP模式,在keepalived中2种模式,分别是master->backup模式和backup->backup模式。这两种模式有很大区别。在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
(5)MHA引入keepalived(MySQL服务进程挂掉时通过MHA 停止keepalived):
要想把keepalived服务引入MHA,我们只需要修改切换是触发的脚本文件master_ip_failover即可,在该脚本中添加在master发生宕机时对keepalived的处理。
编辑脚本/usr/local/bin/master_ip_failover,修改后如下,我对perl不熟悉,所以我这里完整贴出该脚本(主库上操作,192.168.0.50)。
在MHA Manager修改脚本修改后的内容如下(参考资料比较少):
#!/usr/bin/env perl
use strict;
use warnings FATAL => ‘all‘;
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = ‘192.168.0.88‘;
my $ssh_start_vip = "/etc/init.d/keepalived start";
my $ssh_stop_vip = "/etc/init.d/keepalived stop";
GetOptions(
‘command=s‘ => \$command,
‘ssh_user=s‘ => \$ssh_user,
‘orig_master_host=s‘ => \$orig_master_host,
‘orig_master_ip=s‘ => \$orig_master_ip,
‘orig_master_port=i‘ => \$orig_master_port,
‘new_master_host=s‘ => \$new_master_host,
‘new_master_ip=s‘ => \$new_master_ip,
‘new_master_port=i‘ => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
#`ssh $ssh_user\@cluster1 \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
现在已经修改这个脚本了,我们现在打开在上面提到过的参数,再检查集群状态,看是否会报错。
[root@192.168.0.20 ~]# grep ‘master_ip_failover_script‘ /etc/masterha/app1.cnf master_ip_failover_script= /usr/local/bin/master_ip_failover [root@192.168.0.20 ~]#
[root@192.168.0.20 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf Sun Apr 20 23:10:01 2014 - [info] Slaves settings check done. Sun Apr 20 23:10:01 2014 - [info] 192.168.0.50 (current master) +--192.168.0.60 +--192.168.0.70 Sun Apr 20 23:10:01 2014 - [info] Checking replication health on 192.168.0.60.. Sun Apr 20 23:10:01 2014 - [info] ok. Sun Apr 20 23:10:01 2014 - [info] Checking replication health on 192.168.0.70.. Sun Apr 20 23:10:01 2014 - [info] ok. Sun Apr 20 23:10:01 2014 - [info] Checking master_ip_failover_script status: Sun Apr 20 23:10:01 2014 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.0.50 --orig_master_ip=192.168.0.50 --orig_master_port=3306 Sun Apr 20 23:10:01 2014 - [info] OK. Sun Apr 20 23:10:01 2014 - [warning] shutdown_script is not defined. Sun Apr 20 23:10:01 2014 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
可以看见已经没有报错了。哈哈
/usr/local/bin/master_ip_failover添加或者修改的内容意思是当主库数据库发生故障时,会触发MHA切换,MHA Manager会停掉主库上的keepalived服务,触发虚拟ip漂移到备选从库,从而完成切换。当然可以在keepalived里面引入脚本,这个脚本监控mysql是否正常运行,如果不正常,则调用该脚本杀掉keepalived进程。
常用命令
检查整个复制环境状况 masterha_check_repl --conf=/data/mha/3306/mha.cnf 检查SSH配置 masterha_check_ssh --conf=/data/mha/3306/mha.cnf 检测当前MHA运行状态 masterha_check_status --conf=/data/mha/3306/mha.cnf 启动MHA vi manager.sh nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /data/mha/3306/manager.log 2>&1 & 停止MHA masterha_stop --conf=/data/mha/3306/mha.cnf
以上就是MHA 安装配置的全过程,以下进行简单的测试。
(1)failover 测试
手动kill 了master 上面的mysqld 进程,查看切换状态
日志待补全
以上是切换的全日志过程,我们可以看到MHA 切换主要经历以下步骤:
1.配置文件检查阶段,这个阶段会检查整个集群配置文件配置
2.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作(这个我这里还没有实现,需要研究)
3.复制dead maste和最新slave相差的relay log,并保存到MHA Manger具体的目录下
4.识别含有最新更新的slave
5.应用从master保存的二进制日志事件(binlog events)
6.提升一个slave为新的master进行复制
7.使其他的slave连接新的master进行复制
(2)手动switch
在许多情况下, 需要将现有的主服务器迁移到另外一台服务器上。 比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
注意,在线切换的时候应用架构需要考虑以下两个问题:
1.自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2.负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
执行切换
[root@manager tmp]# masterha_master_switch --conf=/data/mha/3306/mha.cnf --master_state=alive --new_master_host=192.168.0.102 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
其中参数的意思:
--orig_master_is_new_slave 切换时加上此参数是将原 master 变为 slave 节点,如果不加此参数,原来的 master 将不启动
--running_updates_limit=10000,故障切换时,候选master 如果有延迟的话, mha 切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover 时relay 日志的大小决定
参考来源:
http://www.cnblogs.com/gomysql/p/3675429.html
http://www.178linux.com/61111
https://www.cnblogs.com/rayment/p/7355093.html
MySQL 之 MHA + ProxySQL + keepalived 实现读写分离,高可用(一)
标签:hard link bubuko ice 现在 pass 存放位置 while pos sage
原文地址:https://www.cnblogs.com/EikiXu/p/9968454.html