标签:code nan scribe 存储 hdfs color 切换 users over
在使用hive shell之前我们需要先安装hive,并启动hdfs
请参考:https://www.cnblogs.com/lay2017/p/9973298.html
我们先进入安装目录
cd /usr/local/hadoop/hive/apache-hive-1.2.2-bin
使用Hive命令启动hive shell
hive
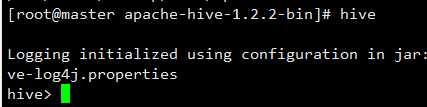
查看一下数据库,发现有一个默认的default
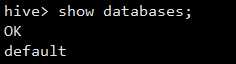
我们需要创建一个新的test数据库

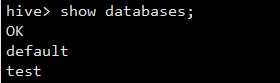
再看一下数据库,test数据库已经创建完成了
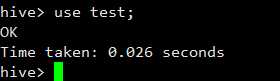
我们切换到test数据库
创建一张t_user表,你会看到创建表的语句显得似乎很麻烦,这么长一句
CREATE TABLE users(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘ LINES TERMINATED BY ‘\n‘ STORED AS TEXTFILE;
我们分开来看,建表的简单语句,如
create t_user(id int, name String);
而每一列分隔符就是
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘
每行的分隔符就是
LINES TERMINATED BY ‘\n‘
最后存储的文件格式就是txt
STORED AS TEXTFILE;
为了更清楚建表语句为什么这么建,我们在/tmp目录下建立一个user.txt,内容如下(注意:每个单词之间是空格分隔,每行是\n分隔,这也是为什么我们在建立hive的表的时候需要配置它的格式,因为我们在读取txt数据的时候需要按照格式进行读取,否则你将查询到一堆的null)
1 lay 2 marry 3 gary
然后我们在hive shell中,把该txt数据给加载到hive中
load data local inpath ‘/tmp/user.txt‘ overwrite into table t_user; // 加载本地数据到t_user表中
然后我们查询一下t_user表中的数据,如下
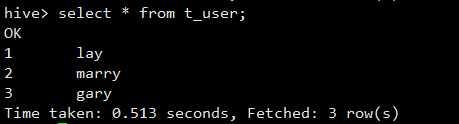
数据就像关系型数据库一样展示,这就是hive的SQL简单查询功能
create database test; // 创建数据库 drop database test; // 删除数据库 drop database test cascade; // 强制删除数据库 show databases; // 列出所有数据库 use test; // 使用数据库 create t_user(id int, name String); // 创建表 CREATE TABLE users(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘ LINES TERMINATED BY ‘\n‘ STORED AS TEXTFILE; // 按照格式创建表,否则load data无法正常读取数据 describe t_user; // 查询表结构 drop table t_user; // 删除表 alter table t_user add columns(age int); // 更改表,新增列 load data local inpath ‘/tmp/user.txt‘ overwrite into table t_user; // 加载本地数据到t_user表中 load data inpath ‘/tmp/user.txt‘ overwrite into table t_user; // 从hdfs加载数据到t_user表中
标签:code nan scribe 存储 hdfs color 切换 users over
原文地址:https://www.cnblogs.com/lay2017/p/9973370.html