标签:http 为什么 org 一个 time 3.0 合并 系统 href
论文分析:
经典的语音增强(speech enhancement)方法有谱减法(spectral subtraction)、维纳滤波(Wiener filtering)、统计模型(statistical model-based methods)和子空间算法(subspace algorithms)。
论文结合GAN网络提出了SEGAN,并通过实验发现,SEGAN主要优势有以下三点:
1、提供一个快速语音增强过程,没有因果关系是必要的,因此没有像RNN那样的递归操作。
2、它基于原始音频做处理,没有提取特征,因此没有对原始数据做出明确的假设。
3、从不同的说话人和噪声类型中学习,并将他们合并到相同的共享参数中,这使得系统在这些维度上变得简单和一般化。
论文的第二部分,是介绍GAN的,如果有GAN的基础可以跳过这一节。GAN网络是一种对抗模型,可以将样本服从Z分布的样本映射到服从X分布的x。
关于GAN的更多解释:
有人说GAN强大之处在于可以自动的学习原始真实样本集的数据分布。为什么大家会这么说。
对于传统的机器学习方法,我们一般会先定义一个模型让数据去学习。(比如:假设我们知道原始数据是高斯分布的,只是不知道高斯分布的参数,这个时候我们定义一个高斯分布,然后利用数据去学习高斯分布的参数,最终得到我们的模型),但是大家有没有觉得奇怪,感觉你好像事先知道数据该怎么映射一样,只是在学习模型的参数罢了。
GAN则不同,生成模型最后通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律。有了这个规律,想生成人脸还不容易,然而这个规律我们事先是不知道的,我们也不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。
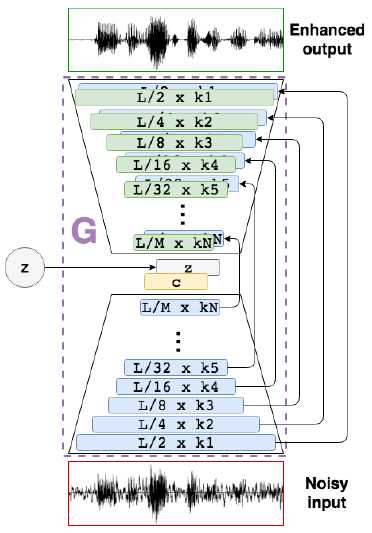
整个网路全部是由CNN组成,下图是生成器G,他是一个encooder-decoder。D的结构是encoder,上面接了一个降维层。将8*1024个参数降维8个。
encoder由步长为2的1维卷积层构成。16384×1, 8192×16, 4096×32, 2048×32, 1024×64, 512×64, 256×128, 128×128, 64×256,32×256, 16×512, and 8×1024。
SEGAN: Speech Enhancement Generative Adversarial Network
标签:http 为什么 org 一个 time 3.0 合并 系统 href
原文地址:https://www.cnblogs.com/LXP-Never/p/9986744.html