标签:var 识别 ssi div 文章 paint one 页面 判断
在之前的文章中,我们已经提到过团队在UI自动化这方面的尝试,我们的目标是实现基于 单一图片到代码 的转换,在这个过程不可避免会遇到一个问题,就是为了从单一图片中提取出足够的有意义的结构信息,我们必须要拥有从图片中切割出想要区块(文字、按钮、商品图片等)的能力,而传统切割算法遇到复杂背景图片往往就捉襟见肘了(见下图),这个时候,我们就需要有能力把复杂前后景的图片划分为各个层级图层,再交给切割算法去处理,拿到我们期望的结构信息。
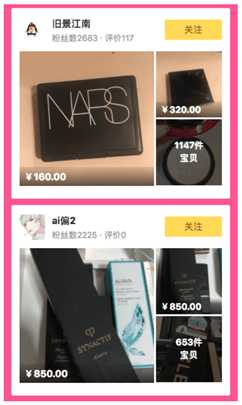
经过传统切割算法处理,会无法获取图片结构信息,最终只会当成一张图片处理。
在业界,图片前后景分离一直是个很麻烦的命题,业界目前比较普遍采用的解决方案是计算机视觉算法提取,或是引入人工智能来解决,但直到现在,都没有百分百完美的解决方案。那是否能引入AI来解决这个问题呢,我们来看一下,目前使用AI并拿到比较不错结果的解法是fcn+crf,基本上能够把目标物体的前景轮廓框出来,但缺点也很明显:
在考虑到使用AI伴随的问题之外,咱们也一起来思考下,难道AI真的是解决前后景分离的最佳解法吗?
其实不是的,我们知道,一个页面,或者说设计稿,一个有意义的前景,是具有比较明显特征的,比如说:
让我们一起来验证下这个思路的可行性。
在尝试了非常的多计算机视觉算法之后,你会发现,没有一种算法是能够解决掉这个问题的,基本上是可能一种算法,在某种场景下是有效的,到了另外一个场景,就又失效了,而且就算是有效的场景,不同颜色复杂度下,所需要的最佳算法参数又是不相同的。如果case by case来解决的话,可以预期未来的工程会变得越来越冗杂且不好维护。
那是不是可以这样呢,找到尽可能多的前景区域,加一层过滤器过滤掉前景可能性低的,再加一层层级分配器,对搜索到的全部前景进行前后层级划分,最后对图像进行修复,填补空白后景。
咱们先来看看效果,以下查找前景的过程:

为了避免有的前景被忽略(图片大部分是有多层的,前景里面还会嵌套前景),所以一个前景被检测到之后不会去隐藏它,导致会出现一个前景被多次检测到的情况,不过这块加一层层级分配算法就能解决了,最终得到出来的分离结果如下:
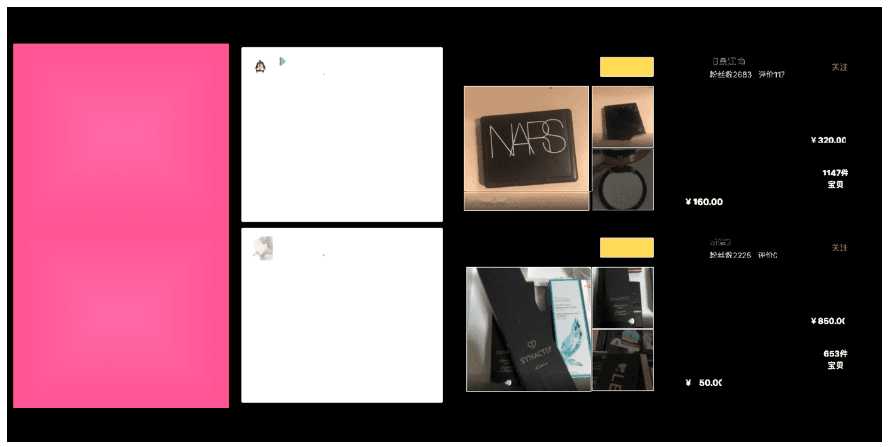
来看看例子,以下左图是闲鱼首页,右图是基于OCR给出的文字位置信息对文字区域进行标记(图中白色部分),可以看到,大致上位置是准确的 但比较粗糙 无法精确到每个文字本身 而且同一行的不同文字片段 OCR会当成一行去处理。
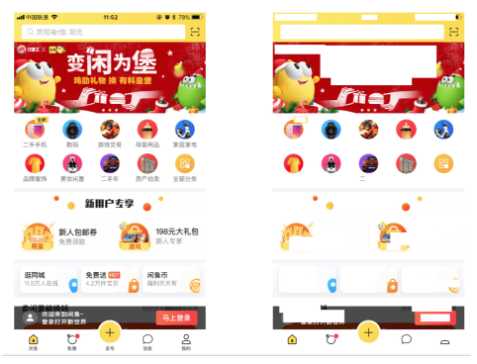
同时,也会有部分非文字的部分 也被当成文字,比如图中的banner文案:
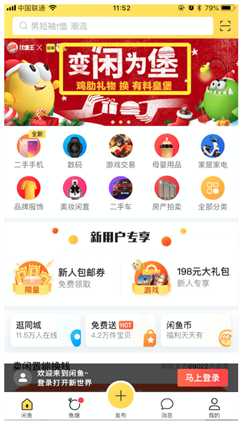
对以上结果标注的位置进行切割,切割出尽可能小的单个文字区域,交给CNN判断,该文字是否是可编辑的文字,还是属于图片文案,后者将当作图片进行处理,以下是CNN代码:
"""
ui基础元素识别
"""
# TODO 加载模型
with ui_sess.as_default():
with g2.as_default():
tf.global_variables_initializer().run()
# Loads label file, strips off carriage return
ui_label_lines = [line.rstrip() for line in tf.gfile.GFile("AI_models/CNN/ui-elements-NN/tf_files/retrained_labels.txt")]
# Unpersists graph from file
with tf.gfile.FastGFile("AI_models/CNN/ui-elements-NN/tf_files/retrained_graph.pb", ‘rb‘) as f:
ui_graph_def = tf.GraphDef()
ui_graph_def.ParseFromString(f.read())
tf.import_graph_def(ui_graph_def, name=‘‘)
# Feed the image_data as input to the graph and get first prediction
ui_softmax_tensor = ui_sess.graph.get_tensor_by_name(‘final_result:0‘)
# TODO 调用模型
with ui_sess.as_default():
with ui_sess.graph.as_default():
# UI原子级元素识别
def ui_classify(image_path):
# Read the image_data
image_data = tf.gfile.FastGFile(image_path, ‘rb‘).read()
predictions = ui_sess.run(ui_softmax_tensor, {‘DecodeJpeg/contents:0‘: image_data})
# Sort to show labels of first prediction in order of confidence
top_k = predictions[0].argsort()[-len(predictions[0]):][::-1]
for node_id in top_k:
human_string = ui_label_lines[node_id]
score = predictions[0][node_id]
print(‘%s (score = %s)‘ % (human_string, score))
return human_string, score如果是纯色背景,文字区域很好抽离,但如果是复杂背景就比较麻烦了。举个例子:

基于以上,我们能拿到准确的文本信息,我们逐一对各个文本信息做处理,文本的特征还是比较明显的,比如说含有多个角点,在尝试了多种算法:Harris角点检测、Canny边缘检测、SWT算法,KNN算法(把区域色块分成两部分)之后,发现KNN的效果是最好的。代码如下:
Z = gray_region.reshape((-1,1))
Z = np.float32(Z)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=cv2.kmeans(Z,K,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((gray_region.shape))抽离后结果如下:

使用卷积核对原图进行卷积,该卷积核可以强化边缘,图像平滑区域会被隐藏。
conv_kernel = [
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]
]卷积后,位与操作隐藏文字区域,结果如下:

对卷积后的图,加一层降噪处理,首先把图像转为灰度图,接着二值化,小于10像素值的噪点将被隐藏,最后使用cv2.connectedComponentsWithStats()算法消除小的噪点连通区域。
我们基于前面拿到的文字信息,选中文字左上角坐标,以这个点为种子点执行漫水填充算法,之后我们会得到一个区域,我们用cv2.findContours()来获取这个区域的外部轮廓,对轮廓进行鉴别,是否符合有效前景的特征,之后对区域取反,重新执行cv2.findContours()获取轮廓,并鉴别。
如果文字在轮廓内部,那拿到的区域将不会包含该区域的border边框,如果文字在轮廓外部,就能拿到包含边框的一整个有效区域(边框应该隶属于前景),所以咱们要判断文字和轮廓的位置关系(cv2.pointPolygonTest),如果在内部,会使轮廓往外扩散,知道拿到该轮廓的边框信息为止。
基于前面的步骤,我们会拿到非常多非常多的轮廓,其实绝大部分是无效轮廓以及重复检测到的轮廓,咱们需要加一层鉴别器来对这些轮廓进行过滤,来判断它是否是有效前景。
我们会预先定义我们认为有意义的形状shape,比如说矩形、正方形、圆形,只要检测到的轮廓与这三个的相似度达到了设定的阀值要求,并且轮廓中还包含了文字信息,我们就认为这是一个有意义的前景,见代码:
# TODO circle
circle = cv2.imread(os.getcwd()+‘/fgbgIsolation/utils/shapes/circle.png‘, 0)
_, contours, _ = cv2.findContours(circle, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
self.circle = contours[0]
# TODO square
square = cv2.imread(os.getcwd()+‘/fgbgIsolation/utils/shapes/square.png‘, 0)
_, contours, _ = cv2.findContours(square, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
self.square = contours[0]
# TODO rect
rect = cv2.imread(os.getcwd()+‘/fgbgIsolation/utils/shapes/rect.png‘, 0)
_, contours, _ = cv2.findContours(rect, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
self.rect = contours[0]多次尝试之后 发现score设置为3的效果是最好的。代码如下:
# TODO 检测图形相似度
def detect(self, cnt):
shape = "unidentified"
types = [self.square, self.rect, self.circle]
names = [‘square‘, ‘rect‘, ‘circle‘]
for i in range(len(types)):
type = types[i]
score = cv2.matchShapes(type, cnt, 1, 0.0) # score越小越相似
# TODO 一般小于3是有意义的
if score<3:
shape = names[i]
break
return shape, score单一匹配shape相似度的鲁棒性还是不够健壮,所以还引入了其他过滤逻辑,这里不展开。
可以预见的,我们传入的图片只有一张,但我们划分图层之后,底层的图层肯定会出现“空白”区域,我们需要对这些区域进行修复。
需要修复的区域只在于重叠(重叠可以是多层的)的部分,其他部分我们不应该去修复。计算重叠区域的解决方案沿用了mask遮罩的思路,我们只需要计算当前层有效区域和当前层之上层有效区域的交集即可,使用cv2.bitwise_and
# mask是当前层的mask layers_merge是集合了所有前景的集合 i代表当前层的层级数
# inpaint_mask 是要修复的区域遮罩
# TODO 寻找重叠关系
UPPER_level_mask = np.zeros(mask.shape, np.uint8) # 顶层的前景
UPPER_level_mask = np.where(layers_merge>i, 255, 0)
UPPER_level_mask = UPPER_level_mask.astype(np.uint8)
_, contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 查找当前层的每个前景外轮廓
overlaps_mask = np.zeros(mask.shape, np.uint8) # 当前层的所有前景的重叠区域
for cnt in contours:
cnt_mask = np.zeros(mask.shape, np.uint8)
cv2.drawContours(cnt_mask, [cnt], 0, (255, 255, 255), cv2.FILLED, cv2.LINE_AA)
overlap_mask = cv2.bitwise_and(inpaint_mask, cnt_mask, mask=UPPER_level_mask)
overlaps_mask = cv2.bitwise_or(overlaps_mask, overlap_mask)
# TODO 将当前层重叠区域的mask赋值给修复mask
inpaint_mask = overlaps_mask使用修复算法cv2.INPAINT_TELEA,算法思路是:先处理待修复区域边缘上的像素点,然后层层向内推进,直到修复完所有的像素点。
# img是要修复的图像 inpaint_mask是上面提到的遮罩 dst是修复好的图像
dst = cv2.inpaint(img, inpaint_mask, 3, cv2.INPAINT_TELEA)本文大概介绍了通过计算机视觉为主,深度学习为辅的图片复杂前后景分离的解决方案,除了文中提到的部分,还有几层轮廓捕获的逻辑因为篇幅原因,未加展开,针对比较复杂的case,本方案已经能够很好的实现图层分离,但对于更加复杂的场景,比如边缘颜色复杂度高,噪点多,边缘轮廓不明显等更复杂的case,分离的精确度还有很大的提升空间。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
标签:var 识别 ssi div 文章 paint one 页面 判断
原文地址:https://www.cnblogs.com/yunqishequ/p/9994234.html