标签:电子 不同的 图形 mat xxxxxx 字符 xxxx 表示 基本
在开发过程中我们往往会遇到很多中文乱码的问题,而要解决这个问题无非抓住编码和解码的一致性问题,但理解其背后的原因及定位问题,还需要了解现有的编码基础知识。
数据在计算机中存储格式都是用0和1表示的。编码是信息从一种形式或格式转换为另一种形式的过程,通俗点讲就是就是将我们看到的文字、图片等信息按照某种规则存储在计算机中;解码是编码的逆过程,它是将存储在计算机的二进制转换为我们可以看到的文字、图片等信息,它体现的是视觉上的刺激。
在编码和解码中,他们就如加密、解密一般,他们一定会遵循某个规则,如果两者规则不一致就会出现乱码,这就是乱码的根源。
字符是可使用多种不同字符方案或代码页来表示的抽象实体,它是一个单位的字形、类字形单位或符号的基本信息,也是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符是指计算机中使用的字母、数字、字和符号,包括:1、2、3、A、B、C、~!·#¥%……—*()——+等等。在 ASCII 编码中,一个英文字母字符存储需要1个字节。在 GB 2312 编码或 GBK 编码中,一个汉字字符存储需要2个字节。在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
字符是各种文字和符号的总称,而字符集则是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同。而计算机要准确的处理各种字符集文字,需要进行相应的字符编码,以便计算机能够识别和存储各种文字。
常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。
计算机中的信息包括数据信息和控制信息,然而不管是那种信息,他们都是以二进制编码的方式存入计算机中,但是他们是如何存放和显示而不会出错?这个时候字符编码就起到了重要作用,字符编码是一套规则,一套建立在符合集合与数字系统之间的对应关系之上的规则,它是信息处理的基本技术。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧英语,它是现今最通用的单字节编码系统。
ASCII使用7位或者8位来表示128或者256种可能的字符。标准的ASCII码则是使用7位二进制数来表示所有的大小写字母、数字、标点符合和一些控制字符,其中:
0~31、127(共33个)是控制字符或者通信专用字符,如控制符:LF(换行)、CR(回车)、DEL(删除)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等。ASCII值为8、9、10、13分别表示退格、制表、换号、回车字符。
32~126(共95个)字符,32为空格、48~57为阿拉伯数字、65~90为大写字母、97~122为小写字母,其余为一些标点符号和运算符号!
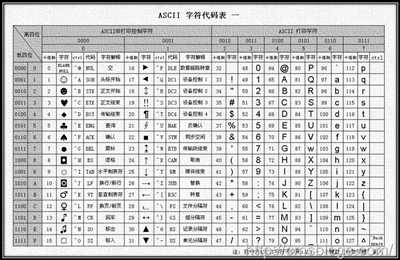
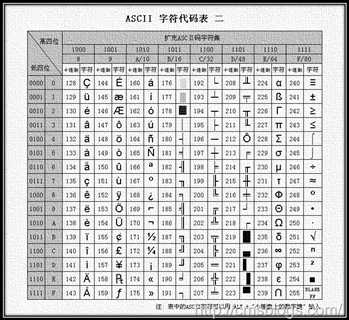
对于欧美国家来说,ASCII能够很好的满足用户的需求,但是我们的汉字达到将近10万,显示中文的常用字符编码有:GB2312、GBK、GB18030。
1)GB2312
在GB2312中,GB2312共收录6763个汉字,其中一级汉字3755个,二级汉字3008个,还收录了拉丁字母、希腊字母、日文等682个全角字符。
2)GBK
GBK是GB2312的扩展,他向下与GB2312兼容,,向上支持 ISO 10646.1 国际标准,是前者向后者过渡过程中的一个承上启下的标准。同时它是使用双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),首字节在 81-FE 之间,尾字节在 40-FE 之间,共23940个码位,共收录了21003个汉字。
3)GB18030
1)Unicode
Unicode又称为统一码、万国码、单一码,它是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。可以想象Unicode作为一个“字符大容器”,它将世界上所有的符号都包含其中,并且每一个符号都有自己独一无二的编码,这样就从根本上解决了乱码的问题。所以Unicode是一种所有符号的编码[2]。
Unicode为了和它们相互兼容,其首256字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息[1]。
2)Unicode转换格式
一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
Unicode是字符集,它主要有UTF-8、UTF-16、UTF-32三种实现方式。由于UTF-8是目前主流的实现方式,UTF-16、UTF-32相对而言使用较少。
UTF-8
UTF-8是一种针对Unicode的可变长度字符编码,可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的系统无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
UTF-8使用一到四个字节为每个字符编码,编码规则如下:
转换表如下:
|
Unicode |
UTF-8 |
|
0000 ~007F |
0XXX XXXX |
|
0080 ~07FF |
110X XXXX 10XX XXXX |
|
0800 ~FFFF |
1110XXXX 10XX XXXX 10XX XXXX |
|
1 0000 ~1F FFFF |
1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX |
|
20 0000 ~3FF FFFF |
1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
|
400 0000 ~7FFF FFFF |
1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
根据上面的转换表,理解UTF-8的转换编码规则就变得非常简单了:第一个字节的第一位如果为0,则表示这个字节单独就是一个字符;如果为1,连续多少个1就表示该字符占有多少个字节。
以汉字"严"为例,演示如何实现UTF-8编码。
已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
标签:电子 不同的 图形 mat xxxxxx 字符 xxxx 表示 基本
原文地址:https://www.cnblogs.com/chenloveslife/p/9998335.html