标签:实现 手动 情况 优先 百分比 内存 场景 左右 博弈
弹性伸缩是Kubernetes中被大家关注的一大亮点,在讨论相关的组件和实现方案之前。首先想先给大家扩充下弹性伸缩的边界与定义,传统意义上来讲,弹性伸缩主要解决的问题是容量规划与实际负载的矛盾。
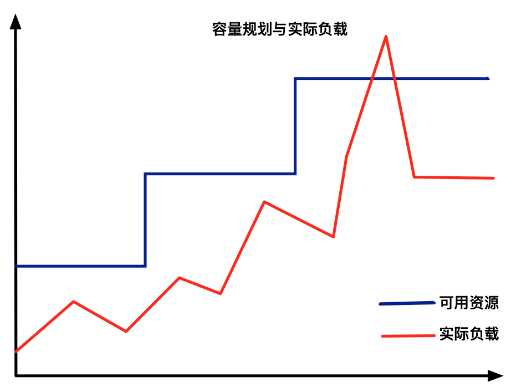
如上图所示,蓝色的水位线表示集群的容量随着负载的提高不断的增长,红色的曲线表示集群的实际的负载真实的变化。而弹性伸缩要解决的就是当实际负载出现激增,而容量规划没有来得及反应的场景。
常规的弹性伸缩是基于阈值的,通过设置一个资源缓冲水位来保障资源的充盈,通常15%-30%左右的资源预留是比较常见的选择。换言之就是通过一个具备缓冲能力的资源池用资源的冗余换取集群的可用。
这种方式表面上看是没有什么问题的,确实在很多的解决方案或者开源组件中也是按照这种方式进行实现的,但是当我们深入的思考这种实现方案的时候会发现,这种方式存在如下三个经典问题。
在一个Kubernetes集群中,通常不只包含一种规格的机器,针对不同的场景、不同的需求,机器的配置、容量可能会有非常大的差异,那么集群伸缩时的百分比就具备非常大的迷惑性。假设我们的集群中存在4C8G的机器与16C32G的机器两种不同规格,对于10%的资源预留,这两种规格是所代表的意义是完全不同的。
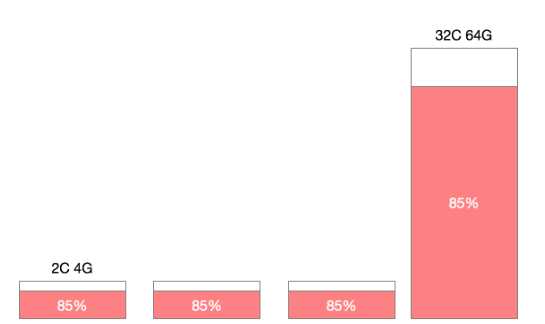
特别是在缩容的场景下,通常为了保证缩容后的集群不处在震荡状态,我们会一个节点一个节点或者二分法来缩容节点,那么如何根据百分比来判断当前节点是处在缩容状态就尤为重要,此时如果大规格机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢饥饿。如果添加判断条件,优先缩容小配置的节点,则有可能造成缩容后资源的大量冗余,最终集群中可能会只剩下所有的巨石节点。
还记得在没有使用容器前,是如何做容量规划的吗?一般会按照应用来进行机器的分配,例如,应用A需要2台4C8G的机器,应用B需要4台8C16G的机器,应用A的机器与应用B的机器是独立的,相互不干扰。到了容器的场景中,大部分的开发者无需关心底层的资源了,那么这个时候容量规划哪里去了呢?
在Kubernetes中是通过Request和Limit的方式进行设置,Request表示资源的申请值,Limit表示资源的限制值。既然Request和Limit才是容量规划的对等概念,那么这就代表着资源的实际计算规则要根据Request和Limit才更加准确。而对于每个节点预留资源阈值而言,很有可能会造成小节点的预留无法满足调度,大节点的预留又调度不完的场景。
集群的资源利用率是否可以真的代表当前的集群状态呢?当一个Pod的资源利用率很低的时候,不代表就可以侵占他所申请的资源。在大部分的生产集群中,资源利用率都不会保持在一个非常高的水位,但从调度来讲,资源的调度水位应该保持在一个比较高的水位。这样才能既保证集群的稳定可用,又不过于浪费资源。
如果没有设置Request与Limit,而集群的整体资源利用率很高这意味着什么?这表示所有的Pod都在被以真实负载为单元进行调度,相互之间存在非常严重的争抢,而且简单的加入节点也丝毫无法解决问题,因为对于一个已调度的Pod而言,除了手动调度与驱逐没有任何方式可以将这个Pod从高负载的节点中移走。那如果我们设置了Request与Limit而节点的资源利用率又非常高的时候说明了什么呢?很可惜这在大部分的场景下都是不可能的,因为不同的应用不同的负载在不同的时刻资源的利用率也会有所差异,大概率的情况是集群还没有触发设置的阈值就已经无法调度Pod了。
既然基于资源利用率的弹性伸缩有上述已知的三个问题,有什么办法可以来解决呢?随着应用类型的多样性发展,不同类型的应用的资源要求也存在越来越大的差异。弹性伸缩的概念和意义也在变化,传统理解上弹性伸缩是为了解决容量规划和在线负载的矛盾,而现在是资源成本与可用性之间的博弈。如果将常见的应用进行规约分类,可以分为如下四种不同类型:
比较常见的是网站、API服务、微服务等常见的互联网业务型应用,这种应用的特点是对常规资源消耗较高,比如CPU、内存、网络IO、磁盘IO等,对于业务中断容忍性差。
例如大数据离线计算、边缘计算等,这种应用的特点是对可靠性的要求较低,也没有明确的时效性要求,更多的关注点是成本如何降低。
定时运行一些批量计算任务是这种应用的比较常见形态,成本节约与调度能力是重点关注的部分。
例如闲时计算的场景、IOT类业务、网格计算、超算等,这类场景对于资源利用率都有比较高的要求。
单纯的基于资源利用率的弹性伸缩大部分是用来解决第一种类型的应用而产生的,对于其他三种类型的应用并不是很合适,那么Kubernetes是如何解决这个问题的呢?
Kubernetes将弹性伸缩的本质进行了抽象,如果抛开实现的方式,对于不同应用的弹性伸缩而言,该如何统一模型呢?Kubernetes的设计思路是将弹性伸缩划分为保障应用负载处在容量规划之内与保障资源池大小满足整体容量规划两个层面。简单理解,当需要弹性伸缩时,优先变化的应该是负载的容量规划,当集群的资源池无法满足负载的容量规划时,再调整资源池的水位保证可用性。而两者相结合的方式是无法调度的Pod来实现的,这样开发者就可以在集群资源水位较低的时候使用HPA、VPA等处理容量规划的组件实现实时极致的弹性,资源不足的时候通过Cluster-Autoscaler进行集群资源水位的调整,重新调度,实现伸缩的补偿。两者相互解耦又相互结合,实现极致的弹性。
在Kubernetes的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。如果我们从伸缩对象与伸缩方向两个方面来解读Kubernetes的弹性伸缩的话,可以得到如下的弹性伸缩矩阵。
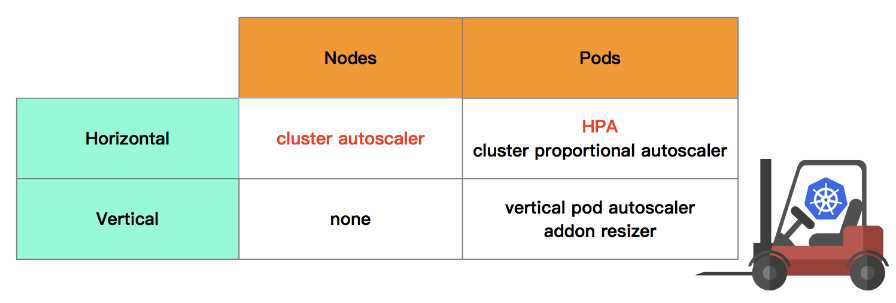
autoscaling/v1、autoscaling/v2beta1与autoscaling/v2beta2,其中autoscaling/v1只支持CPU一种伸缩指标,在autoscaling/v2beta1中增加支持custom metrics,在autoscaling/v2beta2中增加支持external metrics。在这五个组件中,cluster-autoscaler、HPA、cluster-proportional-autoscaler是目前比较稳定的组件,建议有相关需求的开发者进行选用。
对于百分之八十以上的场景,我们建议客户通过HPA结合cluster-autoscaler的方式进行集群的弹性伸缩管理,HPA负责负载的容量规划管理而cluster-autoscaler负责资源池的扩容与缩容。
在本文中,和大家主要讨论的是在云原生时代下弹性伸缩概念的延伸,以及Kubernetes社区是如何通过解耦的方式通过多个转职的组件实现了两个维度的弹性伸缩,在本系列后面的文章中会为一一解析每个弹性伸缩组件的相关原理与用法。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
Kubernetes 弹性伸缩全场景解析 (一)- 概念延伸与组件布局
标签:实现 手动 情况 优先 百分比 内存 场景 左右 博弈
原文地址:https://www.cnblogs.com/yunqishequ/p/10006896.html