标签:服务 本地 价值 roc 小学生 ext polar 方案 避免
POLARDB优势解读系列文章之——分钟级弹性无处不在的脉冲计算
阿里有双11,中国有春运,高考后有分数出来的那天,歌迷心中有周杰伦演唱会门票在线开售之时。。。。有人的地方就有江湖,有人的地方也有脉冲计算,这些热点事件背后都需要大量的计算资源给予支撑,而这些突然急需的计算资源就像脉冲一样,急迫而猛烈,我们称之为脉冲计算。不仅ECS服务器,数据库也需要应对这些突如其来的脉冲波动,才能保证整个系统的平滑稳定。
存储与计算分离
我们知道POLARDB一个最大的特点是存储与计算分离,所谓分离就是计算节点(DB Engine)和存储节点(DB Store)在不同的物理服务器上,任何落地到存储设备的I/O操作均为网络I/O。可能会有人问,走网络,延迟怎么样,性能好不好?在『性价比』这篇文章中简单介绍过借助PolarFS经过网络访问PolarStore的测试效果,与本地单副本SSD几乎持平,这里就不再赘述。
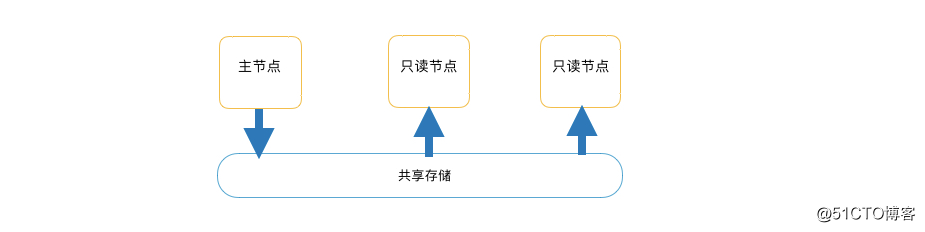
POLARDB的存储与计算分离的架构,除了可以降低存储成本,保证主备数据强一致、不丢数据之外,还带来了一个巨大的优势,就是让数据库的『弹性伸缩』变得极为简单、便捷。
做数据库弹性的挑战
虽然弹性伸缩是云的一大特点,很多人也正是看上这一点,才把自己的IT系统搬迁到云上。但数据库的弹性伸缩一直都是业界难题,不同于纯粹提供计算服务的ECS,数据库要想做好弹性需要应对这些问题:
首先,横向扩展难。数据库往往是业务系统的核心。数据必须流动、共享才有价值,因此在规模还不算很大的时候,数据库一般都是集中式部署,这样用起来简单,比如多个业务库的查询,一个SQL就出来了。所以,对于数据库很难通过横向增加服务器数量,达到线性的扩展能力。
其次,0宕机要求。数据库的核心地位决定了一旦数据库故障,真个业务就会瘫痪。因此数据库是一定要做高可用,屏蔽任何的硬件故障,来保障业务不间断。既要保障高可用,又要做弹性伸缩,就好像在高速飞行的飞机上换引擎,难度可想而知。
再次,数据比计算『重(zhong)』。数据库的本质是存数据,但数据本质上是存储在存储设备上的,当你发现存储设备I/O性能不够时,升级存储设备并不是一件容易的事。同样,假如数据和计算在同一台物理机时,这台物理机的CPU核数和主频,就决定了计算力的上限,很难扩容。
现在,当突破了存储与计算分离的性能瓶颈后,结合多节点共享同一份数据的架构设计,我们终于可以在数据库的弹性伸缩领域有了新的进展。
POLARDB的弹性优势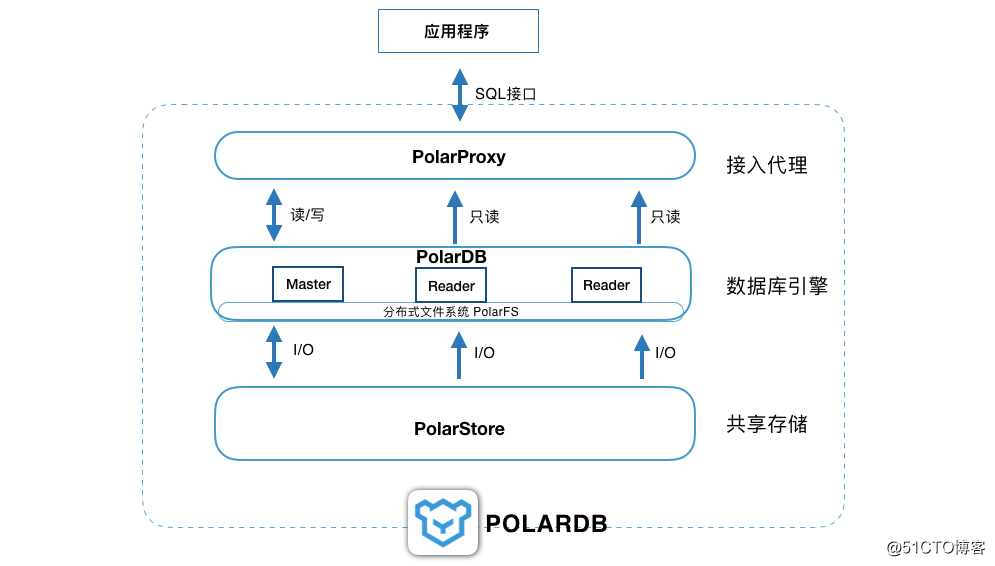
如上图,POLARDB是一个分层架构,从上层的代理PolarProxy提供了读写分离、SQL加速等功能,到中间的数据库引擎节点PolarDB构造了一写多读的数据库集群,再到底层的分布式存储PolarStore为上层提供多节点挂载的数据共享,每一层各司其职,共同构建了POLARDB云数据库集群。
从POLARDB产品定义上看,用户购买的节点数和规格大小(比如4核16G)指的是中间这一层PolarDB的配置,上层PolarProxy可以根据PolarDB的配置自适应调整,用户不需购买也不用关心性能和容量。底层PolarStore的容量是自动扩容,只须按照实际使用容量付费。
通常意义的扩展性,一般有纵向(Scale up)和横向(Scale out)和两种方式,纵向是指提升配置,横向是指配置不变,但增加节点。对于数据库来说,都是先纵向,比如4核不够升到8核。但终归会遇到瓶颈,一方面性能提升非线性,跟数据库引擎自身的设计和应用访问模型有关(比如MySQL的多线程设计,如果只有一个session,那么很难体现出多核的优势),另一方面,计算物理服务器配置有上限,存在天花板。因此终极手段还是横向扩展,增加节点数。
一句话概括,POLARDB横向最多可以到16个节点,纵向最高可到88核 ,存储容量动态扩展,毋须配置。
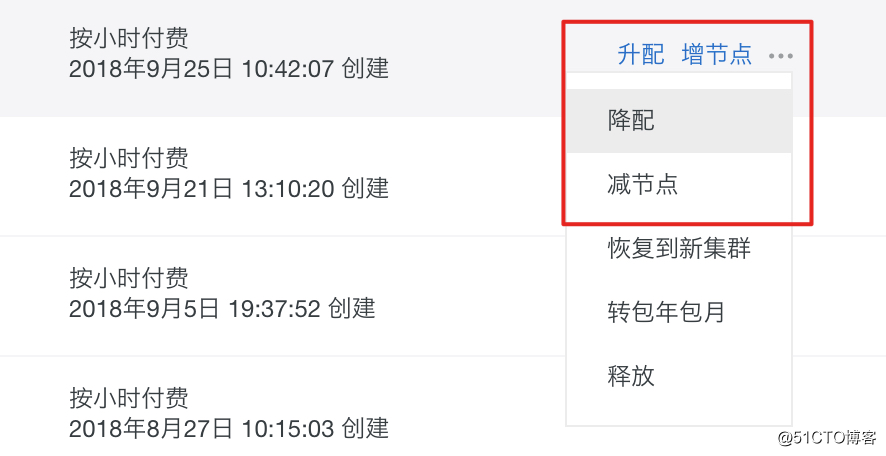

纵向扩展(升级/降级配置)
得益于存储与计算分离,我们可以单独升级或降级POLARDB数据库节点的配置,如果当前服务器资源不足,还可以快速地迁移到其他服务器,整个过程只需要5-10分钟(持续优化中),中间不需要任何的数据搬迁,只是如果涉及到跨机迁移,可能会有几十秒的连接闪断(未来,这个影响可以通过PolarProxy消除掉,升级对业务应用完全无影响)。
因为目前同一集群内的所有节点必须绑定升级,因此我们会采用非常柔和的Rolling Upgrade滚动升级的方式,通过控制升级的节奏、搭配主备切换来进一步减少不可用时间。
横向扩展(增/减节点)
由于存储是共享的,因此可以快速增加节点,而不需要任何的数据COPY。整个过程也只需要5-10分钟(持续优化中),如果是增加节点,对业务应用没有任何影响,如果是减少节点,那么仅对落到该节点执行的连接有影响,重练即可。
当增加节点之后,PolarProxy可以动态感知并自动加入到读写分离后端的读节点中,对于使用集群访问地址(读写分离地址)连接POLARDB的应用程序可以立马享受到更好的性能和吞吐。
毋须管理的存储空间
POLARDB的存储空间不需要关心,用多少付多少钱,每小时自动结算。
对于I/O能力,目前的设计是跟数据库节点的规格有关系,规格越大,IOPS和I/O吞吐量越高,在节点上对I/O有隔离和限制,避免多个数据库集群之间的I/O争抢。
本质上,数据是被保存在由大量服务器构成的存储池中,由于可靠性要求,每个数据块复制出3个副本,保存在不同机架的不同服务器上。存储池能够进行自我管理,动态扩容、平衡,避免存储碎片和数据热点。
典型场景
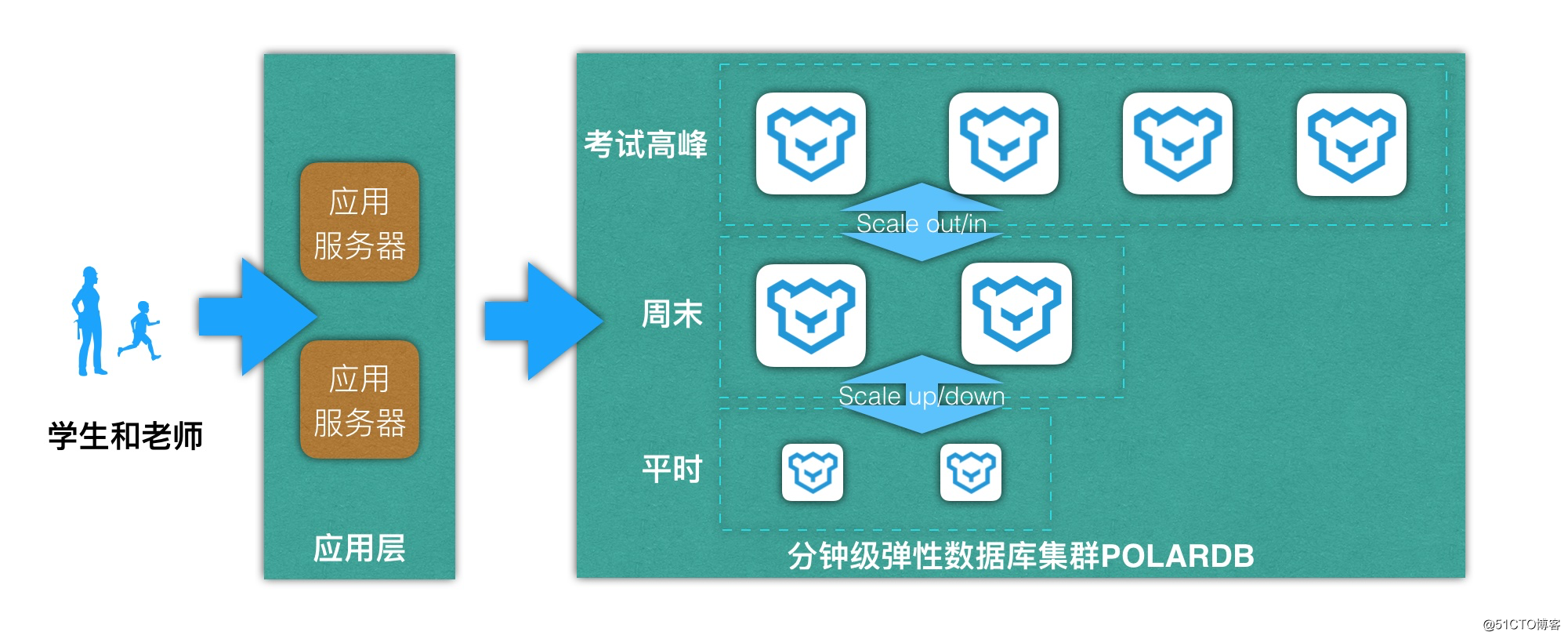
某位于北京的在线教育公司在云上部署了一个小学生在线答题考试系统,平时有5万到10万人在线,周末有20万,考试高峰期能达到50万到100万,数据规模500G以内。主要难点在于高用户并发访问,读写争用,I/O较高,如果一直买最高配置,成本又接受不了。通过使用POLARDB,借助快速弹性的能力,在高峰期临时增加数据库配置和集群规模,与之前的方案相比整体成本下降了70%。
标签:服务 本地 价值 roc 小学生 ext polar 方案 避免
原文地址:http://blog.51cto.com/14031893/2321155