标签:分析 应该 排名 搜索 file tee pat port get
今天爬取的百度的实时热点排行榜
按照惯例,先下载网站的内容到本地:
1 def downhtml(): 2 url = ‘http://top.baidu.com/buzz?b=1&fr=20811‘ 3 headers = {‘User-Agent‘:‘Mozilla/5.0‘} 4 r = requests.get(‘url‘,headers=headers) 5 with open(‘C:/Code/info_baidu.html‘,‘wb‘) as f: 6 f.write(r.content)
因为我习惯把网页整个抓到本地再来分析数据,所以会有这一步,后面会贴直接抓取并分析的代码。
开始分析数据:
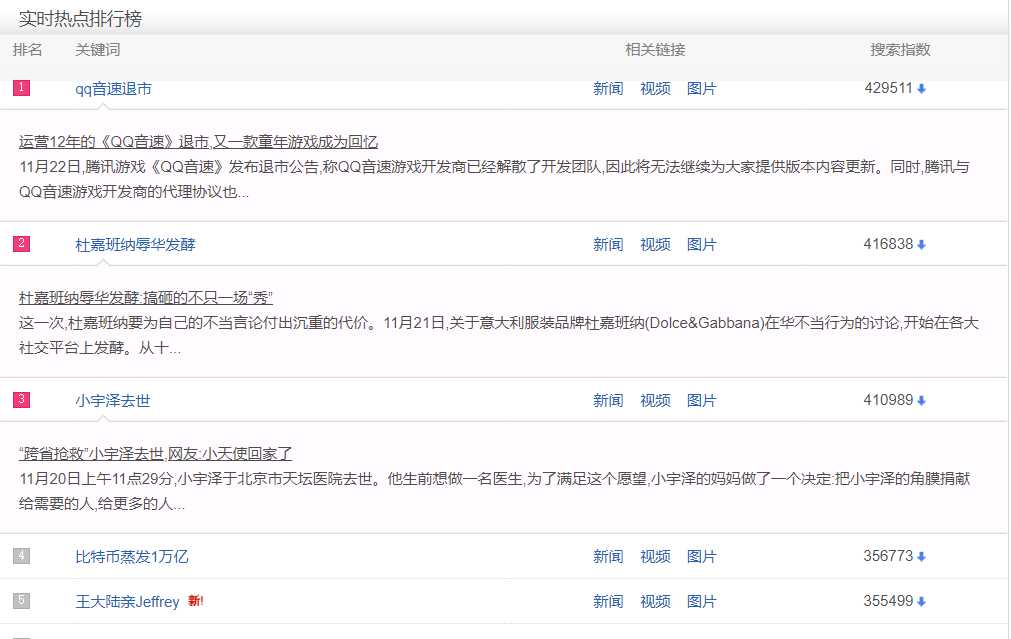
我想抓取的排名,关键词和搜索指数这三个值。
打开网页源代码:

发现每个标题的各个元素是一个个td被包装在一个tr标签里面,每一个标题都是一个tr(这里注意前三个标题的tr标签是有class=‘hideline’,而后面的则没有)
排名 :第一个td class=‘‘first‘
关键词:第二个td cass = ‘keyword‘
搜索指数:最后一个td class = ‘last‘
确定了我所需要的数据的位置了之后,可以开始写代码了。
写一个把打开本地html并返回给BeautifulSoup调用的函数:
def send_html():#把本地的html文件调给get_pages的BeautifulSoup path = ‘C:/Code/info_baidu.html‘ htmlfile= open(path,‘r‘) htmlhandle = htmlfile.read() return htmlhandle
这样,我就可以在下面的直接用本地html来测试,而不用每次都去请求百度的服务器了。
def get_pages(html): soup = BeautifulSoup(html,‘html.parser‘) all_topics=soup.find_all(‘tr‘)[1:]#切片
因为第一个tr装的是这些东西
<tr> <th width="50" class="first">排名</th> <th>关键词</th> <th width="30%" class="tc">相关链接</th> <th width="20%" class="last">搜索指数</th> </tr>
并不是排名第一的标题,所以我用切片把它过滤掉了。
然后开始挨个赋值:
def get_pages(html): soup = BeautifulSoup(html,‘html.parser‘) all_topics=soup.find_all(‘tr‘)[1:] for each_topic in all_topics: #print(each_topic) topic_times = each_topic.find(‘td‘,class_=‘last‘).get_text()#搜索指数 topic_rank = each_topic.find(‘td‘,class_=‘first‘).get_text()#排名 topic_name = each_topic.find(‘td‘,class_=‘keyword‘).get_text()#标题目 print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times))
这样按道理来说应该是可以输出了,但百度还是想给我一点难度。
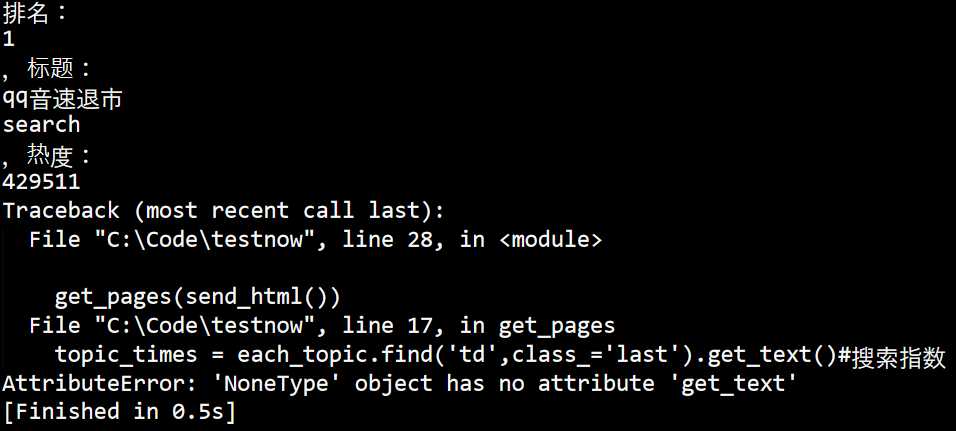
这里出现几个问题,
1:AttributeError: ‘NoneType‘ object has no attribute ‘get_text‘
2:输出的格式
3:只有一个值
按照惯例,第一个问题应该是里面多了一些不是Tag的类型,所以就来测试一下:
def get_pages(html): soup = BeautifulSoup(html,‘html.parser‘) all_topics=soup.find_all(‘tr‘)[1:] for each_topic in all_topics: #print(each_topic) topic_times = each_topic.find(‘td‘,class_=‘last‘)#搜索指数 print(type(topic_times))
输出如下:
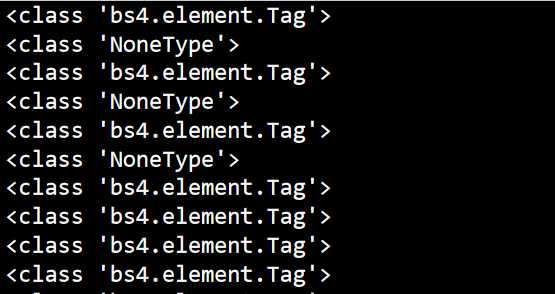
我们可以发现前几个值都参杂了NoneType(我去源代码看了一下,并不知道是什么导致的,等以后我知道了,再回来!)
因此,我们只要把NoneType给过滤掉就行。
def get_pages(html): soup = BeautifulSoup(html,‘html.parser‘) all_topics=soup.find_all(‘tr‘)[1:] for each_topic in all_topics: #print(each_topic) topic_times = each_topic.find(‘td‘,class_=‘last‘)#搜索指数 topic_rank = each_topic.find(‘td‘,class_=‘first‘)#排名 topic_name = each_topic.find(‘td‘,class_=‘keyword‘)#标题目 # print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times)) if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find(‘td‘,class_=‘first‘).get_text() topic_name = each_topic.find(‘td‘,class_=‘keyword‘).get_text() topic_times = each_topic.find(‘td‘,class_=‘last‘).get_text() print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times))
输出如下:

这样就解决了第一个问题,发现可以输出了,连第三个问题也解决了。
但第二个问题还在,这shit一般的格式让我很难受,导致这样的原因我猜是get_text时把一些空格符和换行符也一起输出了。
所以用replace()就应该可以解决了。
if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find(‘td‘,class_=‘first‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) topic_name = each_topic.find(‘td‘,class_=‘keyword‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) topic_times = each_topic.find(‘td‘,class_=‘last‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times))
输出如下:

哦吼,这样感觉就不错了。
但强迫症患者感觉还是很难受啊,这个热度(搜索指数)的格式也太乱了。
经过一番搜索,网友的力量还是很强大的啊哈哈哈,马上就有办法了。
if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find(‘td‘,class_=‘first‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) topic_name = each_topic.find(‘td‘,class_=‘keyword‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) topic_times = each_topic.find(‘td‘,class_=‘last‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) #print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times)) tplt = "排名:{0:^4}\t标题:{1:{3}^15}\t热度:{2:^7}" print(tplt.format(topic_rank,topic_name,topic_times,chr(12288)))
输出如下:
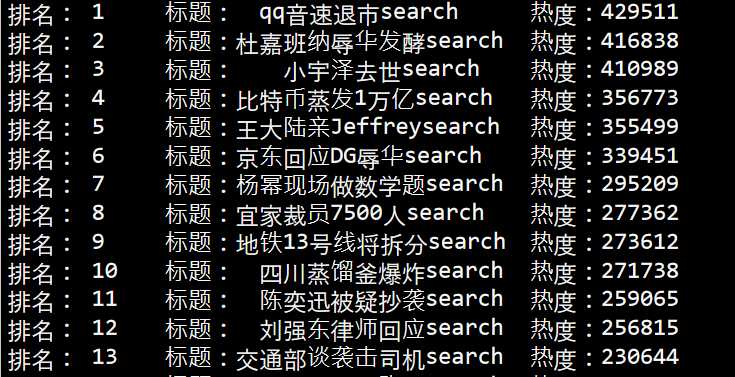
本强迫症患者终于满足了哈哈。
附上总代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 6 def send_html():#把本地的html文件调给get_pages的BeautifulSoup 7 path = ‘C:/Code/info_baidu.html‘ 8 htmlfile= open(path,‘r‘) 9 htmlhandle = htmlfile.read() 10 return htmlhandle 11 12 def get_pages(html): 13 soup = BeautifulSoup(html,‘html.parser‘) 14 all_topics=soup.find_all(‘tr‘)[1:] 15 for each_topic in all_topics: 16 #print(each_topic) 17 topic_times = each_topic.find(‘td‘,class_=‘last‘)#搜索指数 18 topic_rank = each_topic.find(‘td‘,class_=‘first‘)#排名 19 topic_name = each_topic.find(‘td‘,class_=‘keyword‘)#标题目 20 if topic_rank != None and topic_name!=None and topic_times!=None: 21 topic_rank = each_topic.find(‘td‘,class_=‘first‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 22 topic_name = each_topic.find(‘td‘,class_=‘keyword‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 23 topic_times = each_topic.find(‘td‘,class_=‘last‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 24 #print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times)) 25 tplt = "排名:{0:^4}\t标题:{1:{3}^15}\t热度:{2:^7}" 26 print(tplt.format(topic_rank,topic_name,topic_times,chr(12288))) 27 28 if __name__ ==‘__main__‘: 29 get_pages(send_html())
。
。
。
还有直接爬取不用下载网页的总代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def get_html(url,headers): 6 r = requests.get(url,headers=headers) 7 r.encoding = r.apparent_encoding 8 return r.text 9 10 11 def get_pages(html): 12 soup = BeautifulSoup(html,‘html.parser‘) 13 all_topics=soup.find_all(‘tr‘)[1:] 14 for each_topic in all_topics: 15 #print(each_topic) 16 topic_times = each_topic.find(‘td‘,class_=‘last‘)#搜索指数 17 topic_rank = each_topic.find(‘td‘,class_=‘first‘)#排名 18 topic_name = each_topic.find(‘td‘,class_=‘keyword‘)#标题目 19 if topic_rank != None and topic_name!=None and topic_times!=None: 20 topic_rank = each_topic.find(‘td‘,class_=‘first‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 21 topic_name = each_topic.find(‘td‘,class_=‘keyword‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 22 topic_times = each_topic.find(‘td‘,class_=‘last‘).get_text().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 23 #print(‘排名:{},标题:{},热度:{}‘.format(topic_rank,topic_name,topic_times)) 24 tplt = "排名:{0:^4}\t标题:{1:{3}^15}\t热度:{2:^8}" 25 print(tplt.format(topic_rank,topic_name,topic_times,chr(12288))) 26 27 def main(): 28 url = ‘http://top.baidu.com/buzz?b=1&fr=20811‘ 29 headers= {‘User-Agent‘:‘Mozilla/5.0‘} 30 html = get_html(url,headers) 31 get_pages(html) 32 33 if __name__==‘__main__‘: 34 main()
好了。完成任务,生活愉快!
标签:分析 应该 排名 搜索 file tee pat port get
原文地址:https://www.cnblogs.com/xunhuajun/p/10008867.html