标签:结果 def oid 初始化 就是 qps from innodb executors
对于Guava Cache本身就不多做介绍了,一个非常好用的本地cache lib,可以完全取代自己手动维护ConcurrentHashMap。
目前需要开发一个接口I,对性能要求有非常高的要求,TP99.9在20ms以内。初步开发后发现耗时完全无法满足,mysql稍微波动就超时了。

主要耗时在DB读取,请求一次接口会读取几次配置表Entry表。而Entry表的信息更新又不频繁,对实时性要求不高,所以想到了对DB做一个cache,理论上就可以大幅度提升接口性能了。
DB表结构(这里的代码都是为了演示,不过原理、流程和实际生产环境基本是一致的)
CREATE TABLE `entry` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` int(11) NOT NULL, `value` varchar(50) NOT NULL DEFAULT ‘‘, PRIMARY KEY (`id`), UNIQUE KEY `unique_name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
接口中的查询是根据name进行select操作,这次的目的就是设计一个cache类,将DB查询cache化。
首先,自然而然的想到了最基本的guava cache的使用,如下:
@Slf4j @Component public class EntryCache { @Autowired EntryMapper entryMapper; /** * guava cache 缓存实体 */ LoadingCache<String, Entry> cache = CacheBuilder.newBuilder() // 缓存刷新时间 .refreshAfterWrite(10, TimeUnit.MINUTES) // 设置缓存个数 .maximumSize(500) .build(new CacheLoader<String, Entry>() { @Override // 当本地缓存命没有中时,调用load方法获取结果并将结果缓存 public Entry load(String appKey) { return getEntryFromDB(appKey); } // 数据库进行查询 private Entry getEntryFromDB(String name) { log.info("load entry info from db!entry:{}", name); return entryMapper.selectByName(name); } }); /** * 对外暴露的方法 * 从缓存中取entry,没取到就走数据库 */ public Entry getEntry(String name) throws ExecutionException { return cache.get(name); } }
这里用了refreshAfterWrite,和expireAfterWrite区别是expireAfterWrite到期会直接删除缓存,如果同时多个并发请求过来,这些请求都会重新去读取DB来刷新缓存。DB速度较慢,会造成线程短暂的阻塞(相对于读cache)。
而refreshAfterWrite,则不会删除cache,而是只有一个请求线程会去真实的读取DB,其他请求直接返回老值。这样可以避免同时过期时大量请求被阻塞,提升性能。
但是还有一个问题,那就是更新线程还是会被阻塞,这样在缓存key集体过期时,可能还会使响应时间变得不满足要求。
就像上面所说,只要刷新缓存,就必然有线程被阻塞,这个是无法避免的。
虽然无法避免线程阻塞,但是我们可以避免阻塞用户线程,让用户无感知即可。
所以,我们可以把刷新线程放到后台执行。当key过期时,有新用户线程读取cache时,开启一个新线程去load DB的数据,用户线程直接返回老的值,这样就解决了这个问题。
代码修改如下:
@Slf4j @Component public class EntryCache { @Autowired EntryMapper entryMapper; ListeningExecutorService backgroundRefreshPools = MoreExecutors.listeningDecorator(new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>())); /** * guava cache 缓存实体 */ LoadingCache<String, Entry> cache = CacheBuilder.newBuilder() // 缓存刷新时间 .refreshAfterWrite(10, TimeUnit.MINUTES) // 设置缓存个数 .maximumSize(500) .build(new CacheLoader<String, Entry>() { @Override // 当本地缓存命没有中时,调用load方法获取结果并将结果缓存 public Entry load(String appKey) { return getEntryFromDB(appKey); } @Override // 刷新时,开启一个新线程异步刷新,老请求直接返回旧值,防止耗时过长 public ListenableFuture<Entry> reload(String key, Entry oldValue) throws Exception { return backgroundRefreshPools.submit(() -> getEntryFromDB(key)); } // 数据库进行查询 private Entry getEntryFromDB(String name) { log.info("load entry info from db!entry:{}", name); return entryMapper.selectByName(name); } }); /** * 对外暴露的方法 * 从缓存中取entry,没取到就走数据库 */ public Entry getEntry(String name) throws ExecutionException { return cache.get(name); } /** * 销毁时关闭线程池 */ @PreDestroy public void destroy(){ try { backgroundRefreshPools.shutdown(); } catch (Exception e){ log.error("thread pool showdown error!e:{}",e.getMessage()); } } }
改动就是新添加了一个backgroundRefreshPools线程池,重写了一个reload方法。
ListeningExecutorService是guava的concurrent包里的类,负责一些线程池相关的工作,感兴趣的可以自己去了解一下。
在reload方法里提交一个新的线程,就可以用这个线程来刷新cache了。
如果刷新cache没有完成的时候有其他线程来请求该key,则会直接返回老值。
同时,千万不要忘记销毁线程池。
上面两步达到了不阻塞刷新cache的功能,但是这个前提是这些cache已经存在。
项目刚刚启动的时候,所有的cache都是不存在的,这个时候如果大批量请求过来,同样会被阻塞,因为没有老的值供返回,都得等待cache的第一次load完毕。
解决这个问题的方法就是在项目启动的过程中,将所有的cache预先load过来,这样用户请求刚到服务器时就会直接读cache,不用等待。
@Slf4j @Component public class EntryCache { @Autowired EntryMapper entryMapper; ListeningExecutorService backgroundRefreshPools = MoreExecutors.listeningDecorator(new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>())); /** * guava cache 缓存实体 */ LoadingCache<String, Entry> cache = CacheBuilder.newBuilder() // 缓存刷新时间 .refreshAfterWrite(10, TimeUnit.MINUTES) // 设置缓存个数 .maximumSize(500) .build(new CacheLoader<String, Entry>() { @Override // 当本地缓存命没有中时,调用load方法获取结果并将结果缓存 public Entry load(String appKey) { return getEntryFromDB(appKey); } @Override // 刷新时,开启一个新线程异步刷新,老请求直接返回旧值,防止耗时过长 public ListenableFuture<Entry> reload(String key, Entry oldValue) throws Exception { return backgroundRefreshPools.submit(() -> getEntryFromDB(key)); } // 数据库进行查询 private Entry getEntryFromDB(String name) { log.info("load entry info from db!entry:{}", name); return entryMapper.selectByName(name); } }); /** * 对外暴露的方法 * 从缓存中取entry,没取到就走数据库 */ public Entry getEntry(String name) throws ExecutionException { return cache.get(name); } /** * 销毁时关闭线程池 */ @PreDestroy public void destroy(){ try { backgroundRefreshPools.shutdown(); } catch (Exception e){ log.error("thread pool showdown error!e:{}",e.getMessage()); } } @PostConstruct public void initCache() { log.info("init entry cache start!"); //读取所有记录 List<Entry> list = entryMapper.selectAll(); if (CollectionUtils.isEmpty(list)) { return; } for (Entry entry : list) { try { this.getEntry(entry.getName()); } catch (Exception e) { log.error("init cache error!,e:{}", e.getMessage()); } } log.info("init entry cache end!"); } }
让我们用数据看看这个cache类的表现:
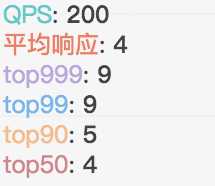
200QPS,TP99.9是9ms,完美达标。
可以看出来,合理的使用缓存对接口性能还是有很大提升的。
标签:结果 def oid 初始化 就是 qps from innodb executors
原文地址:https://www.cnblogs.com/csonezp/p/10011031.html