标签:get arc 抓取 技术分享 exception arch javascrip google 数据保存
题记:
互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种:
1.解析出汽车之家某个车型的网页,然后正则表达式匹配出混淆后的数据对象与混淆后的js,并对混淆后的js使用pyv8进行解析返回正常字符,然后通过字符与数据对象进行匹配,具体方法见这位园友,传送门:https://www.cnblogs.com/my8100/p/js_qichezhijia.html (感谢这位大神前半部分的思路)
2.解析出汽车之家某个车型的网页,然后正则表达式匹配出混淆后的数据对象与混淆后的js,针对混淆后的js进行进行手动匹配,因为混淆的js大概分为8大类(无参数 返回常量,无参数 返回函数,参数等于返回值函数,无参数 返回常量,无参数 返回常量中间无混淆代码,字符串拼接时使无参常量,字符串拼接时使用返回参数的函数),然后通过正则表达式进行解析出8类内容并进行逐个替换,最终也会返回一个带有顺序的字符串,将这个字符串与前边的数据对象再次替换,最终数据对象中的所有span都会被替换成中文,具体操作见园友的地址,传送门:https://www.cnblogs.com/dyfblog/p/6753251.html (感谢这位大神前半部分的思路)
不过鉴于作者技术有限,上述的两种方案,我都没有完整的执行完成,哪怕花了一周的时间也没有,但是没有办法,谁让我是一个很爱钻牛角尖的人呢,下一步提出我自己琢磨出来的方案,流程上稍微有点复杂,但是稳打稳扎,还是可以爬出来的,好了话不多说了,贴出步骤;
1.获取所有车型的网页,保存到本地:
1 import bs4 2 import requests as req 3 ‘‘‘ 4 第一步,下载出所有车型的网页。 5 ‘‘‘ 6 def mainMethod(): 7 ‘‘‘ 8 解析汽车之家所有车型数据保存到D盘 9 ‘‘‘ 10 li = [chr(i) for i in range(ord("A"),ord("Z")+1)] 11 firstSite="https://www.autohome.com.cn/grade/carhtml/" 12 firstSiteSurfixe=".html" 13 secondSite = "https://car.autohome.com.cn/config/series/" 14 secondSiteSurfixe = ".html" 15 16 for a in li: 17 if a is not None: 18 requestUrl = firstSite+a+firstSiteSurfixe 19 print(requestUrl) 20 #开始获取每个品牌的车型 21 resp = req.get(requestUrl) 22 # print(str(resp.content,"gbk")) 23 bs = bs4.BeautifulSoup(str(resp.content,"gbk"),"html.parser") 24 bss = bs.find_all("li") 25 con = 0 26 for b in bss: 27 d = b.h4 28 if d is not None: 29 her = str(d.a.attrs[‘href‘]) 30 her = her.split("#")[0] 31 her = her[her.index(".cn")+3:].replace("/",‘‘) 32 if her is not None: 33 secSite = secondSite +her + secondSiteSurfixe 34 print("secSite="+secSite) 35 # print(secSite) 36 #奥迪A3 37 if her is not None: 38 resp = req.get(secSite) 39 text = str(resp.content,encoding="utf-8") 40 print(a) 41 fil = open("d:\\autoHome\\html\\"+str(her),"a",encoding="utf-8") 42 fil.write(text) 43 con = (con+1) 44 else: 45 print(con) 46 if __name__ =="__main__": 47 mainMethod()
2.解析出每个车型的关键js并拼装成一个html,保存到本地。
1 import os 2 import re 3 ‘‘‘ 4 第二步,解析出每个车型的关键js拼装成一个html 5 ‘‘‘ 6 if __name__=="__main__": 7 print("Start...") 8 rootPath = "D:\\autoHome\\html\\" 9 files = os.listdir(rootPath) 10 for file in files: 11 print("fileName=="+file.title()) 12 text = "" 13 for fi in open(rootPath+file,‘r‘,encoding="utf-8"): 14 text = text+fi 15 else: 16 print("fileName=="+file.title()) 17 #解析数据的json 18 alljs = ("var rules = ‘2‘;" 19 "var document = {};" 20 "function getRules(){return rules}" 21 "document.createElement = function() {" 22 " return {" 23 " sheet: {" 24 " insertRule: function(rule, i) {" 25 " if (rules.length == 0) {" 26 " rules = rule;" 27 " } else {" 28 " rules = rules + ‘#‘ + rules;" 29 " }" 30 " }" 31 " }" 32 " }" 33 "};" 34 37 "document.head = {};" 38 "document.head.appendChild = function() {};" 39 40 "var window = {};" 41 "window.decodeURIComponent = decodeURIComponent;") 42 try: 43 js = re.findall(‘(\(function\([a-zA-Z]{2}.*?_\).*?\(document\);)‘, text) 44 for item in js: 45 alljs = alljs + item 46 except Exception as e: 47 print(‘makejs function exception‘) 48 49 50 newHtml = "<html><meta http-equiv=‘Content-Type‘ content=‘text/html; charset=utf-8‘ /><head></head><body> <script type=‘text/javascript‘>" 51 alljs = newHtml + alljs+" document.write(rules)</script></body></html>" 52 f = open("D:\\autoHome\\newhtml\\"+file+".html","a",encoding="utf-8") 53 f.write(alljs) 54 f.close()
3.解析出每个车型的数据json,比如var config ,var option , var bag var innerbag..但我就解析了基本信息跟配置信息,其他的无所谓。
1 import os 2 import re 3 ‘‘‘ 4 解析出每个车型的数据json,保存到本地。 5 ‘‘‘ 6 if __name__=="__main__": 7 print("Start...") 8 rootPath = "D:\\autoHome\\html\\" 9 files = os.listdir(rootPath) 10 for file in files: 11 print("fileName=="+file.title()) 12 text = "" 13 for fi in open(rootPath+file,‘r‘,encoding="utf-8"): 14 text = text+fi 15 else: 16 print("fileName=="+file.title()) 17 #解析数据的json 18 jsonData = "" 19 config = re.search(‘var config = (.*?){1,};‘,text) 20 if config!= None: 21 print(config.group(0)) 22 jsonData = jsonData+ config.group(0) 23 option = re.search(‘var option = (.*?)};‘,text) 24 if option != None: 25 print(option.group(0)) 26 jsonData = jsonData+ option.group(0) 27 bag = re.search(‘var bag = (.*?);‘,text) 28 if bag != None: 29 print(bag.group(0)) 30 jsonData = jsonData+ bag.group(0) 31 # print(jsonData) 32 f = open("D:\\autoHome\\json\\"+file,"a",encoding="utf-8") 33 f.write(jsonData) 34 f.close()
4.生成样式文件,保存 到本地。
1 import os 2 from selenium import webdriver 3 4 ‘‘‘ 5 第四步,浏览器执行第二步生成的html文件,抓取执行结果,保存到本地。 6 ‘‘‘ 7 class Crack(): 8 def __init__(self,keyword,username,passod): 9 self.url = ‘https://www.baidu.com‘ 10 self.browser = webdriver.Chrome(‘E:\work\ChromePortable\App\Google Chrome\chromedriver.exe‘) 11 12 if __name__=="__main__": 13 lists = os.listdir("D:/autoHome/newHtml/") 14 for fil in lists: 15 file = os.path.exists("D:\\autoHome\\content\\"+fil) 16 if file : 17 print(‘文件已经解析。。。‘+str(file)) 18 continue 19 crack = Crack(‘测试公司‘,‘17610177519‘,‘17610177519‘) 20 21 print(fil) 22 crack.browser.get("file:///D:/autoHome/newHtml/"+fil+"") 23 text = crack.browser.find_element_by_tag_name(‘body‘) 24 print(text.text) 25 f = open("D:\\autoHome\\content\\"+fil,"a",encoding="utf-8") 26 f.write(text.text) 27 f.close() 28 crack.browser.close()
5.读取样式文件,匹配数据文件,生成正常数据文件
1 import os 2 import re 3 ‘‘‘ 4 匹配样式文件与json数据文件,生成正常的数据文件。 5 ‘‘‘ 6 if __name__ =="__main__": 7 rootPath = "D:\\autoHome\\json\\" 8 listdir = os.listdir(rootPath) 9 for json_s in listdir: 10 print(json_s.title()) 11 jso = "" 12 #读取json数据文件 13 for fi in open(rootPath+json_s,‘r‘,encoding="utf-8"): 14 jso = jso+fi 15 content = "" 16 #读取样式文件 17 spansPath = "D:\\autoHome\\content\\"+json_s.title()+".html" 18 # print(spansPath) 19 for spans in open(spansPath,"r",encoding="utf-8"): 20 content = content+ spans 21 print(content) 22 #获取所有span对象 23 jsos = re.findall("<span(.*?)></span>",jso) 24 num = 0 25 for js in jsos: 26 print("匹配到的span=>>"+js) 27 num = num +1 28 #获取class属性值 29 sea = re.search("‘(.*?)‘",js) 30 print("匹配到的class==>"+sea.group(1)) 31 spanContent = str(sea.group(1))+"::before { content:(.*?)}" 32 #匹配样式值 33 spanContentRe = re.search(spanContent,content) 34 if spanContentRe != None: 35 if sea.group(1) != None: 36 print("匹配到的样式值="+spanContentRe.group(1)) 37 jso = jso.replace(str("<span class=‘"+sea.group(1)+"‘></span>"),re.search("\"(.*?)\"",spanContentRe.group(1)).group(1)) 38 print(jso) 39 fi = open("D:\\autoHome\\newJson\\"+json_s.title(),"a",encoding="utf-8") 40 fi.write(jso) 41 fi.close()
6.到前五步已经可以看到json数据文件都已经是混淆前的了,说明已经爬取成功了。
7.读取数据文件,生成excel
1 import json 2 import os 3 import re 4 import xlwt 5 ‘‘‘ 6 读取数据文件,生成excel 7 ‘‘‘ 8 if __name__ == "__main__": 9 rootPath = "D:\\autoHome\\newJson\\" 10 workbook = xlwt.Workbook(encoding = ‘ascii‘)#创建一个文件 11 worksheet = workbook.add_sheet(‘汽车之家‘)#创建一个表 12 files = os.listdir(rootPath) 13 startRow = 0 14 isFlag = True #默认记录表头 15 for file in files: 16 list = [] 17 carItem = {} 18 print("fileName=="+file.title()) 19 text = "" 20 for fi in open(rootPath+file,‘r‘,encoding="utf-8"): 21 text = text+fi 22 # else: 23 # print("文件内容=="+text) 24 #解析基本参数配置参数,颜色三种参数,其他参数 25 config = "var config = (.*?);" 26 option = "var option = (.*?);var" 27 bag = "var bag = (.*?);" 28 29 configRe = re.findall(config,text) 30 optionRe = re.findall(option,text) 31 bagRe = re.findall(bag,text) 32 for a in configRe: 33 config = a 34 print("++++++++++++++++++++++\n") 35 for b in optionRe: 36 option = b 37 print("---------------------\n") 38 for c in bagRe: 39 bag = c 40 # print(config) 41 # print(option) 42 # print(bag) 43 config = json.loads(config) 44 option = json.loads(option) 45 # print(bag) 46 try: 47 bag = json.loads(bag) 48 # print(config) 49 # print(option) 50 # print(bag) 51 path = "D:\\autoHome\\autoHome.xls" 52 53 configItem = config[‘result‘][‘paramtypeitems‘][0][‘paramitems‘] 54 optionItem = option[‘result‘][‘configtypeitems‘][0][‘configitems‘] 55 optionItem = option[‘result‘][‘configtypeitems‘][0][‘configitems‘] 56 except Exception as e: 57 f = open("D:\\autoHome\\异常数据\\exception.txt","a",encoding="utf-8") 58 f.write(file.title()+"\n") 59 60 #解析基本参数 61 for car in configItem: 62 carItem[car[‘name‘]]=[] 63 for ca in car[‘valueitems‘]: 64 carItem[car[‘name‘]].append(ca[‘value‘]) 65 # print(carItem) 66 #解析配置参数 67 for car in optionItem: 68 carItem[car[‘name‘]]=[] 69 for ca in car[‘valueitems‘]: 70 carItem[car[‘name‘]].append(ca[‘value‘]) 71 72 if isFlag: 73 co1s = 0 74 75 for co in carItem: 76 co1s = co1s +1 77 worksheet.write(startRow,co1s,co) 78 else: 79 startRow = startRow+1 80 isFlag = False 81 82 #计算起止行号 83 endRowNum = startRow + len(carItem[‘最大扭矩(N·m)‘]) #车辆款式记录数 84 for row in range(startRow,endRowNum): 85 print(row) 86 colNum = 0 87 for col in carItem: 88 89 colNum = colNum +1 90 print(str(carItem[col][row-startRow]),end=‘|‘) 91 worksheet.write(row,colNum,str(carItem[col][row-startRow])) 92 93 else: 94 startRow = endRowNum 95 workbook.save(‘d:\\autoHome\\Mybook.xls‘)
8.最后打开excel文件,给你们看看。
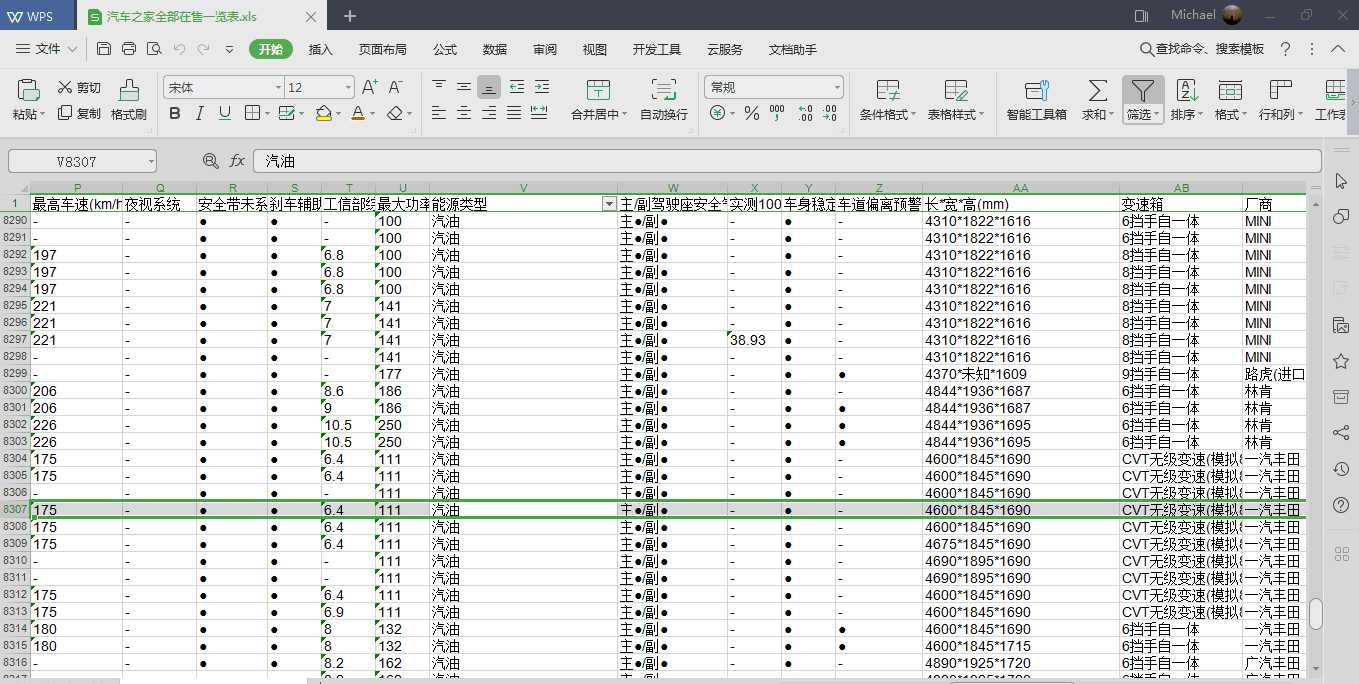
数据量大概有8300的样子。以后买车就用这个参考了。
标签:get arc 抓取 技术分享 exception arch javascrip google 数据保存
原文地址:https://www.cnblogs.com/kangz/p/10011348.html