标签:跨平台 调用 主函数 一个 怎么 onclick send sync for循环
多任务是指操作系统同时可以运行多个任务。
- 单核CPU实现多任务原理:操作系统轮流让各个任务交替执行;
- 多核CPU实现多任务原理:真正的执行多任务只能在多核CPU上实现,多出来的任务轮流调度到每个核心上执行。
- 并发:看上去一起执行,任务数多于CPU核心数;
- 并行:真正的一起执行,任务数小于等于CPU核心数。
实现多任务的方式:
1、多进程模式
2、多线程模式
3、协程模式
4、多进程+多线程模式
对于操作系统而言,一个任务就是一个进程;
进程是系统中程序执行和资源分配的基本单元,每个进程都有自己的数据段、代码段、堆栈段。
下面是一小段程序,一个单任务的例子。在其中,有两个输出语句分别在在两个不同的循环当中,单任务的执行方式,也就是最初学习时,当一个循环没有结束的时候,无法执行到下面的程序当中。如果想要让两个循环可以同时在执行,就是在实现多任务,当然不是说同时输出,而是两个循环都在执行着。
1 from time import sleep
2 # 只能执行到那一个循环,执行不了run,所以叫单任务
3 def run():
4 while True:
5 print("&&&&&&&&&&&&&&&")
6 sleep(1.2)
7
8 if __name__ == "__main__":
9 while True:
10 print("**********")
11 sleep(1)
12 run()
接下来启用多任务,通过进程来实现。
multiprocessing库:跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象(fork仅适用于Linux)。
下面的程序是在一个父进程中创建一个子进程,让父进程和子进程可以都在执行,创建方式程序中已经很简洁了。可以自己把这两段程序复制下来运行一下,看看输出的效果。
1 from multiprocessing import Process
2 from time import sleep
3 import os
4
5 def run(str):
6 # os.getpid()获取当前进程id号
7 # os.getppid()获取当前进程的父进程id号
8 while True:
9 print("&&&&&&&&&&&&&&&%s--%s--%s" % (str, os.getpid(), os.getppid()))
10 sleep(0.5)
11
12 if __name__ == "__main__":
13 print("主(父)进程启动 %s" % (os.getpid()))
14 # 创建子进程
15 # target说明进程执行的任务
16 p = Process(target=run, args=("nice",))
17 # 启动进程
18 p.start()
19
20 while True:
21 print("**********")
22 sleep(1)
我想第一个单任务的程序就不必说了吧,就是一个死循环,一直没有执行到下面的run函数。第二段程序是通过多进程实现的多任务,两个循环都能执行到,我把结果截图放下面,最好自己去试一下。
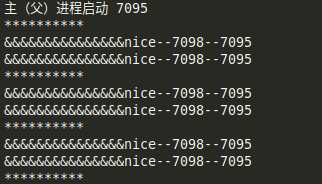
上面的多进程的例子中输出了那么多,我们使用的时候究竟是先执行哪个后执行哪个呢?根据我们的一般思维来说,我们写的主函数其实就是父进程,在主函数中间,要调用的也就是子进程。
1 from multiprocessing import Process
2 from time import sleep
3 import os
4
5 def run():
6 print("启动子进程")
7 print("子进程结束")
8 sleep(3)
9
10 if __name__ == "__main__":
11 print("父进程启动")
12 p = Process(target=run)
13 p.start()
14
15 # 父进程的结束不能影响子进程,让进程等待子进程结束再执行父进程
16 p.join()
17
18 print("父进程结束")
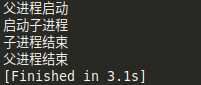
在多进程的程序当中定义的全局变量在多个进程中是不能共享的,篇幅较长在这里就不举例子了,可以自己试一下。这个也是和稍后要说的线程的一个区别,在线程中,变量是可以共享的,也因此衍生出一些问题,稍后再说。
在正常工作使用的时候,当然不止有有个一个两个进程,毕竟这一两个也起不到想要的效果。那么就需要采用更多的进程,这时候需要通过进程池来实现,就是在进程池中放好你要建立的进程,然后执行的时候,把他们都启动起来,就可以同时进行了,在一定的环境下可以大大的提高效率。当然这个也和起初提到的有关,如果你的CPU是单核的,那么多进程也只是起到了让几个任务同时在执行着,并没有提高效率,而且启动进程的时候还要花费一些时间,因此在多核CPU当中更能发挥优势。
在multiprocessing中有个Pool方法,可以实现进程池。在利用进程池时可以设置要启动几个进程,一般情况下,它默认和你电脑的CPU核数一致,也可以自己设置,如果设置的进程数多于CPU核数,那多出来的进程会轮流调度到每个核心上执行。下面是启动多个进程的过程。
1 from multiprocessing import Pool
2 import os
3 import time
4 import random
5
6
7 def run(name):
8 print("子进程%s启动--%s" % (name, os.getpid()))
9 start = time.time()
10 time.sleep(random.choice([1,2,3,4,5]))
11 end = time.time()
12 print("子进程%s结束--%s--耗时%.2f" % (name, os.getpid(), end-start))
13
14 if __name__ == "__main__":
15 print("启动父进程")
16
17 # 创建多个进程
18 # Pool 进程池 :括号里的数表示可以同时执行的进程数量
19 # Pool()默认大小是CPU核心数
20 pp = Pool(4)
21 for i in range(5):
22 # 创建进程,放入进程池,统一管理
23 pp.apply_async(run, args=(i,))
24
25 # 在调用join之前必须先调用close,调用close之后就不能再继续添加新的进程了
26 pp.close()
27 # 进程池对象调用join还等待进程池中所有的子进程结束
28 pp.join()
29
30 print("结束父进程")
(1)单进程实现

1 from multiprocessing import Pool 2 import time 3 import os 4 5 # 实现文件的拷贝 6 def copyFile(rPath, wPath): 7 fr = open(rPath, ‘rb‘) 8 fw = open(wPath, ‘wb‘) 9 context = fr.read() 10 fw.write(context) 11 fr.close() 12 fw.close() 13 14 path = r‘F:\python_note\线程、协程‘ 15 toPath = r‘F:\python_note\test‘ 16 17 # 读取path下的所有文件 18 filesList = os.listdir(path) 19 20 # 启动for循环处理每一个文件 21 start = time.time() 22 for fileName in filesList: 23 copyFile(os.path.join(path,fileName), os.path.join(toPath,fileName)) 24 25 end = time.time() 26 print(‘总耗时:%.2f‘ % (end-start))
(2)多进程实现
1 from multiprocessing import Pool 2 import time 3 import os 4 5 # 实现文件的拷贝 6 def copyFile(rPath, wPath): 7 fr = open(rPath, ‘rb‘) 8 fw = open(wPath, ‘wb‘) 9 context = fr.read() 10 fw.write(context) 11 fr.close() 12 fw.close() 13 14 path = r‘F:\python_note\线程、协程‘ 15 toPath = r‘F:\python_note\test‘ 16 17 18 if __name__ == "__main__": 19 # 读取path下的所有文件 20 filesList = os.listdir(path) 21 22 start = time.time() 23 pp = Pool(4) 24 for fileName in filesList: 25 pp.apply_async(copyFile, args=(os.path.join( 26 path, fileName), os.path.join(toPath, fileName))) 27 pp.close() 28 pp.join() 29 end = time.time() 30 print("总耗时:%.2f" % (end - start))
上面两个程序是两种方法实现同一个目标的程序,可以将其中的文件路径更换为你自己的路径,可以看到最后计算出的耗时是多少。也许有人发现并不是多进程的效率就高,说的的确没错,因为创建进程也要花费时间,没准启动进程的时间远多让这一个核心运行所有核心用的时间要多。这个例子也只是演示一下如何使用,在大数据的任务下会有更深刻的体验。
我们知道Python是一个面向对象的语言。而且Python中万物皆对象,进程也可以封装成对象,来方便以后自己使用,只要把他封装的足够丰富,提供清晰的接口,以后使用时会快捷很多,这个就根据自己的需求自己可以试一下,不写了。
上面提到过进程间的变量是不能共享的,那么如果有需要该怎么办?通过队列的方式进行传递。在父进程中创建队列,然后把队列传到每个子进程当中,他们就可以共同对其进行操作。
1 from multiprocessing import Process, Queue
2 import os
3 import time
4
5
6 def write(q):
7 print("启动写子进程%s" % (os.getpid()))
8 for chr in [‘A‘, ‘B‘, ‘C‘, ‘D‘]:
9 q.put(chr)
10 time.sleep(1)
11 print("结束写子进程%s" % (os.getpid()))
12
13 def read(q):
14 print("启动读子进程%s" % (os.getpid()))
15 while True:
16 value = q.get()
17 print("value = "+value)
18 print("结束读子进程%s" % (os.getpid()))
19
20 if __name__ == "__main__":
21 # 父进程创建队列,并传递给子进程
22 q = Queue()
23 pw = Process(target=write, args=(q,))
24 pr = Process(target=read, args=(q,))
25
26 pw.start()
27 pr.start()
28 # 写进程结束
29 pw.join()
30 # pr进程里是个死循环,无法等待期结束,只能强行结束
31 pr.terminate()
32 print("父进程结束")
- 在一个进程内部,要同时干多件事,就需要运行多个"子任务",我们把进程内的多个"子任务"叫做线程
- 线程通常叫做轻型的进程,线程是共享内存空间,并发执行的多任务,每一个线程都共享一个进程的资源
- 线程是最小的执行单元而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统来决定,程序自己不能决定什么时候执行,执行多长时间
模块:
1、_thread模块 低级模块(更接近底层)
2、threading模块 高级模块,对_thread进行了封装
同样,先给一个多线程的例子,其中,仍然使用run函数作为其中的一个子线程,主函数为父线程。通过threading的Thread方法创建线程并开启,join来等待子线程。
1 import threading
2 import time
3
4
5 def run():
6 print("子线程(%s)启动" % (threading.current_thread().name))
7
8 # 实现线程的功能
9 time.sleep(1)
10 print("打印")
11 time.sleep(2)
12
13 print("子线程(%s)结束" % (threading.current_thread().name))
14
15
16 if __name__ == "__main__":
17 # 任何进程都默认会启动一个线程,称为主线程,主线程可以启动新的子线程
18 # current_thread():返回线程的实例
19 print("主线程(%s)启动" % (threading.current_thread().name))
20
21 # 创建子线程
22 t = threading.Thread(target=run, name="runThread")
23 t.start()
24
25 # 等待线程结束
26 t.join()
27
28 print("主线程(%s)结束" % (threading.current_thread().name))
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在每个进程中,互不影响。
而多线程所有变量都由所有线程共享。所以任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时修改一个变量,容易把内容改乱了。
1 import threading
2
3
4 num = 10
5
6 def run(n):
7 global num
8 for i in range(10000000):
9 num = num + n
10 num = num - n
11
12 if __name__ == "__main__":
13 t1 = threading.Thread(target=run, args=(6,))
14 t2 = threading.Thread(target=run, args=(9,))
15
16 t1.start()
17 t2.start()
18 t1.join()
19 t2.join()
20
21 print("num = ",num)
在第三小点中已经提到了,多线程的一个缺点就是数据是共享的,如果有两个线程正同时在修改这个数据,就会出现混乱,它自己也不知道该听谁的了,尤其是在运算比较复杂,次数较多的时候,这种错误的机会会更大。
当然,解决办法也是有的,那就是利用线程锁。加锁的意思就是在其中一个线程正在对数据进行操作时,让其他线程不得介入。这个加锁和释放锁是由人来确定的。
- 确保了这段代码只能由一个线程从头到尾的完整执行
- 阻止了多线程的并发执行,要比不加锁时候效率低。包含锁的代码段只能以单线程模式执行
- 由于可以存在多个锁,不同线程持有不同的锁,并试图获取其他的锁,可能造成死锁导致多个线程挂起,只能靠操作系统强制终止
1 def run(n):
2 global num
3 for i in range(10000000):
4 lock.acquire()
5 try:
6 num = num + n
7 num = num - n
8 finally:
9 # 修改完释放锁
10 lock.release()
11
12 if __name__ == "__main__":
13 t1 = threading.Thread(target=run, args=(6,))
14 t2 = threading.Thread(target=run, args=(9,))
15
16 t1.start()
17 t2.start()
18 t1.join()
19 t2.join()
20
21 print("num = ",num)
上面这段程序是循环多次num+n-n+n-n的过程,变量n分别设为6和9是在两个不同的线程当中,程序中已经加了锁,你可以先去掉试一下,当循环次数较小的时候也许还能正确,但次数一旦取的较高就会出现混乱。
加锁是在循环体当中,依次执行加减法,定义中说到确保一个线程从头到尾的完整执行,也就是在计算途中,不会有其他的线程打扰。你可以想一下,如果一个线程执行完加法,正在执行减法,另一个线程进来了,它要先进行加法时的初始sum值该是多少呢,线程二不一定在线程一的什么时候进来,万一刚进来时候,线程一恰好给sum赋值了,而线程二仍然用的是正准备进来时候的sum值,那从这里开始岂不已经分道扬镳了。所以,运算的次数越多,结果会越离谱。
这个说完了,还有一个小小的改进。你是否记得读写文件时候书写的一种简便形式,通过with来实现,可以避免我们忘记关闭文件,自动帮我们关闭。当然还有一些其他地方也用到了这个方法。这里也同样适用。
1 # 与上面代码功能相同,with lock可以自动上锁与解锁
2 with lock:
3 num = num + n
4 num = num - n
- 创建一个全局的ThreadLocal对象
- 每个线程有独立的存储空间
- 每个线程对ThreadLocal对象都可以读写,但是互不影响
根据名字也可以看出,也就是在本地建个连接,所有的操作在本地进行,每个线程之间没有数据的影响。
1 import threading
2
3
4 num = 0
5 local = threading.local()
6
7 def run(x, n):
8 x = x + n
9 x = x - n
10
11 def func(n):
12 # 每个线程都有local.x
13 local.x = num
14 for i in range(10000000):
15 run(local.x, n)
16 print("%s-%d" % (threading.current_thread().name, local.x))
17
18
19 if __name__ == "__main__":
20 t1 = threading.Thread(target=func, args=(6,))
21 t2 = threading.Thread(target=func, args=(9,))
22
23 t1.start()
24 t2.start()
25 t1.join()
26 t2.join()
27
28 print("num = ",num)
1 ‘‘‘
2 控制线程数量是指控制线程同时触发的数量,可以拿下来这段代码运行一下,下面启动了5个线程,但是他们会两个两个的进行
3 ‘‘‘
4 import threading
5 import time
6
7 # 控制并发执行线程的数量
8 sem = threading.Semaphore(2)
9
10 def run():
11 with sem:
12 for i in range(10):
13 print("%s---%d" % (threading.current_thread().name, i))
14 time.sleep(1)
15
16
17 if __name__ == "__main__":
18 for i in range(5):
19 threading.Thread(target=run).start()
上面的程序是有多个线程,但是每次限制同时执行的线程,通俗点说就是限制并发线程的上限;除此之外,也可以限制线程数量的下限,也就是至少达到多少个线程才能触发。
1 import threading
2 import time
3
4
5 # 凑够一定数量的线程才会执行,否则一直等着
6 bar = threading.Barrier(4)
7
8 def run():
9 print("%s--start" % (threading.current_thread().name))
10 time.sleep(1)
11 bar.wait()
12 print("%s--end" % (threading.current_thread().name))
13
14
15 if __name__ == "__main__":
16 for i in range(5):
17 threading.Thread(target=run).start()
1 import threading
2
3
4 def run():
5 print("***********************")
6
7 # 延时执行线程
8 t = threading.Timer(5, run)
9 t.start()
10
11 t.join()
12 print("父线程结束")
1 import threading
2 import time
3
4
5 def func():
6 # 事件对象
7 event = threading.Event()
8 def run():
9 for i in range(5):
10 # 阻塞,等待事件的触发
11 event.wait()
12 # 重置阻塞,使后面继续阻塞
13 event.clear()
14 print("**************")
15 t = threading.Thread(target=run).start()
16 return event
17
18 e = func()
19
20 # 触发事件
21 for i in range(5):
22 time.sleep(2)
23 e.set()
这个例子是用了生产者和消费者来模拟,要进行数据通信,还引入了队列。先来理解一下。
1 import threading
2 import queue
3 import time
4 import random
5
6
7 # 生产者
8 def product(id, q):
9 while True:
10 num = random.randint(0, 10000)
11 q.put(num)
12 print("生产者%d生产了%d数据放入了队列" % (id, num))
13 time.sleep(3)
14 # 任务完成
15 q.task_done()
16
17 # 消费者
18 def customer(id, q):
19 while True:
20 item = q.get()
21 if item is None:
22 break
23 print("消费者%d消费了%d数据" % (id, item))
24 time.sleep(2)
25 # 任务完成
26 q.task_done()
27
28
29 if __name__ == "__main__":
30 # 消息队列
31 q = queue.Queue()
32
33 # 启动生产者
34 for i in range(4):
35 threading.Thread(target=product, args=(i, q)).start()
36
37 # 启动消费者
38 for i in range(3):
39 threading.Thread(target=customer, args=(i, q)).start()
1 import threading
2 import time
3
4
5 # 线程条件变量
6 cond = threading.Condition()
7
8
9 def run():
10 with cond:
11 for i in range(0, 10, 2):
12 print(threading.current_thread().name, i)
13 time.sleep(1)
14 cond.wait() # 阻塞
15 cond.notify() # 告诉另一个线程可以执行
16
17
18 def run2():
19 with cond:
20 for i in range(1, 10, 2):
21 print(threading.current_thread().name, i)
22 time.sleep(1)
23 cond.notify()
24 cond.wait()
25
26
27 threading.Thread(target=run).start()
28 threading.Thread(target=run2).start()
- 子程序/子函数:在所有语言中都是层级调用,比如A调用B,在B执行的工程中又可以调用C,C执行完毕返回,B执行完毕返回最后是A执行完毕。是通过栈实现的,一个线程就是一个子程序,子程序调用总是一个入口,一次返回,调用的顺序是明确的
- 协程:看上去也是子程序,但执行过程中,在子程序的内部可中断,然后转而执行别的子程序,不是函数调用,有点类似CPU中断
1 # 这是一个子程序的调用
2 def C():
3 print("C--start")
4 print("C--end")
5
6 def B():
7 print("B--start")
8 C()
9 print("B--end")
10
11 def A():
12 print("A--start")
13 B()
14 print("A--end")
15
16 A()
- 协程与子程序调用的结果类似,但不是通过在函数中调用另一个函数
- 协程执行起来有点像线程,但协程的特点在于是一个线程
- 与线程相比的优点:协程的执行效率极高,因为只有一个线程,也不存在同时写变量的冲突,在协程中共享资源不加锁,只需要判断状态
1 # python对协程的支持是通过generator实现的
2 def run():
3 print(1)
4 yield 10
5 print(2)
6 yield 20
7 print(3)
8 yield 30
9
10 # 协程的最简单风格,控制函数的阶段执行,节约线程或者进程的切换
11 # 返回值是一个生成器
12 m = run()
13 print(next(m))
14 print(next(m))
15 print(next(m))
1 # python对协程的支持是通过generator实现的
2 def run():
3 print(1)
4 yield 10
5 print(2)
6 yield 20
7 print(3)
8 yield 30
9
10 # 协程的最简单风格,控制函数的阶段执行,节约线程或者进程的切换
11 # 返回值是一个生成器
12 m = run()
13 print(next(m))
14 print(next(m))
15 print(next(m))
1 def product(c):
2 c.send(None)
3 for i in range(5):
4 print("生产者产生数据%d" % (i))
5 r = c.send(str(i))
6 print("消费者消费了数据%s" % (r))
7 c.close()
8
9
10 def customer():
11 data = ""
12 while True:
13 n = yield data
14 if not n:
15 return
16 print("消费者消费了%s" % (n))
17 data = "200"
18
19
20 c = customer()
21 product(c)
标签:跨平台 调用 主函数 一个 怎么 onclick send sync for循环
原文地址:https://www.cnblogs.com/yudanqu/p/10013049.html
