标签:simple chrome hide 结果 property afn object 能力 link
爬虫要爬取的信息主要来自于网页加载的内容,有必要了解一些网页的知识。
当我们在浏览器网址栏输入一个网址——URL,经过TCP/IP协议簇的处理,这个网址请求的信息就被发送到URL对应的服务器,接着服务器处理这个请求,并将请求的内容返回给浏览器,浏览器便显示或者下载URL请求相应的资源。这是前一篇博客所述。
在这一篇博客,笔者尝试说明浏览器是如何显示出这个页面的。如下
与超文本相对的是线性文本。线性,即直线关系,成比例。一本书,从第一页到最后一页,呈现直线关系;一本书的书签,从第一章转跳至第十章,呈现的是非线性关系。对于线性的计算机文件,不能直接从从一个位置的文件非线性地转至另一个位置的文件,这中间是要经过一定的顺序;相反,超文本之间的关系是非线性的,从一个HTML文件可以直接连接至另一个HTML文件。促成这种连接的正是是超文本链接,超文本链接就是超链接,上一篇的URL就是超链接的一种,电子书中的书签也是超链接的一种。
HTML是一门语言,常用于编写网页,HTML文件是超文本的一种形式。以下是一些名称的解释,以辅助理解,不必太在意于严格的定义。
树的结构是很简单的,平时留心观察即可知道树为何是“直”的。从第一个分叉开始这树就是由无数的“开叉”结构组成,直至最微小的枝芽。怎么简单怎么来,数学上的描述不管。下面的性质和定义来自《用Python解决数据结构和算法》
相关术语在“定义1”里面有解释,以分类树为例 此处有图片
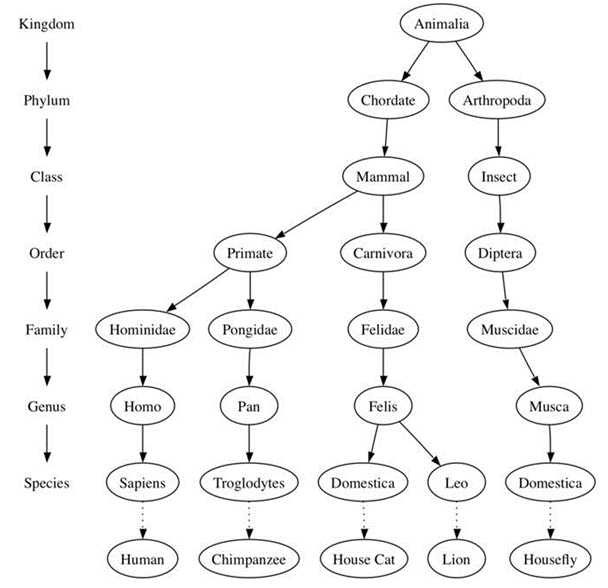
图1 一些动物的分类树

图2 一小部分Unix文件系统的分层情况
树是节点和连接节点的边的集合
这个定义简单粗暴,但蕴含的东西不少。以下是一些相关的东西,都是些抽象的概念,将其类比成枝节叶可以吧
每棵树为空,或者包含一个根节点和0个或多个子树,其中每个子树也符合这样的定义
这个定义巧妙,用到递归只能“巧妙”了。
HTML是由一系列的元素组成,元素由首尾标签和其中的内容组成,学习HTML就要学习那一堆元素。标签表示元素的起始和结束。下面是一个简单的HTML网页。例如代下面代码中
<li>List item one</li>是元素,<li>是首标签,</li>是尾标签,‘List item one‘是内容。
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>simple</title> </head> <body> <h1>A simple web page</h1> <ul> <li>List item one</li> <li>List item two</li> </ul> <h2><a href="http://www.cs.luther.edu">Luther CS </a><h2> </body> </html>
代码1
这个网页也相当于一棵树,树的每一层都对应超文本标记符的一层嵌套。如图3
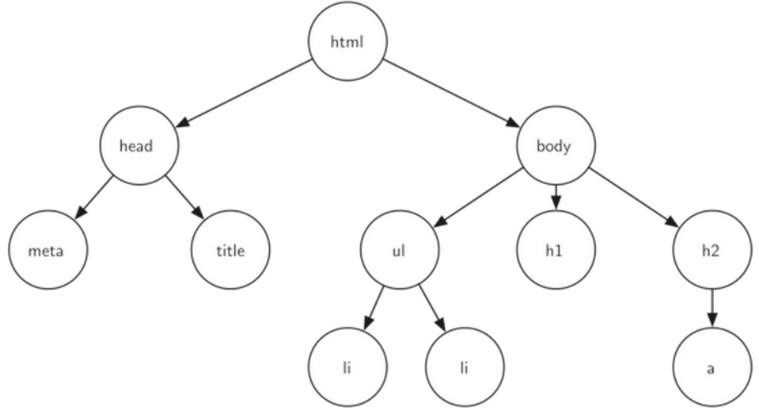
图3 与网页的构成元素相对应的树
DOM(Document Object Model),文档对象模型。当浏览器要显示HTML文档网页的时候,浏览器会创建这个网页全部元素的内部表示体系——DOM,类似于地图表示实际的地点一样,DOM也可以看做是这个HTML网页的“地图”,我们可以通过JavaScript(例如父子对象的形式)去读取DOM这张“地图”。在DOM里面,网页的所有元素以父子对象等形式形成树形结构,这棵树最顶层的是浏览器window对象(如图4),window对象的一个子对象是document对象,一个HTML文档被加载到浏览器的时候,都会创建一个document对象,这个对象包含了HTML文档的全部元素,同样HTML的内容也会表示成树形结构(如图3)
当DOM把网页表示成“树”的形式(如图3)时,每个元素都相当于树的节点(元素节点),每个属性也相当一个节点(属性节点),文本也是(文本节点),属性节点和文本节点包含在元素节点中。边表示了元素间的关系。
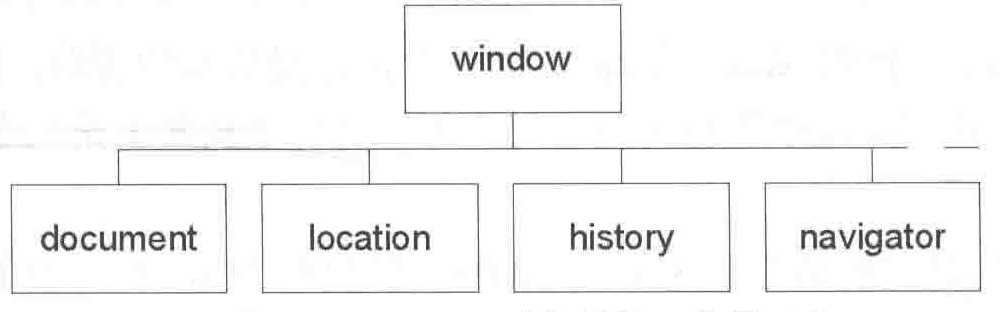
图4 window对象及其一些子对象
通过DOM模型,浏览器就知道如何去显示一个HTML网页的title,h1,body,ul······,但这并不是唯一的方式,我们同样可以通过CSS(Cascading Style Sheets)层级样式表去告诉浏览器该如何去显示一个网页文档,实际上浏览器也会根据外部样式表去构建一棵“树”——CSSOM(CSS Object Model,CSS 对象模型)。
CSS是一种样式表语言,用于为HTML文档定义布局。例如,设置字体、颜色、边距、高度、宽度、背景图像等等。爬虫中经常用到CSS选择器。
为HTML应用CSS的一种方法是使用HTML属性style。例如下面代码,通过行内样式表将页面背景设为红色,代码如下:
<html> <head> <title>例子</title> </head> <body style="background-color: #FF0000;"> <p>这个页面是红色的</p> </body> </html>
为HTML应用CSS的另一种方法是采用HTML元素style。代码如下
<html> <head> <title>例子</title> <style type="text/css"> body {background-color: #FF0000;} </style> </head> <body> <p>这个页面是红色的</p> </body> </html>
外部样式表就是一个扩展名为css的文本文件。如何在一个HTML文档里引用一个外部样式表文件(style.css)呢?可以在HTML文档里创建一个指向外部样式表文件的链接(link)即可,就像下面代码那样,其中href="style/style.css是CSS文件的路径,要注意的就是外部样式表的路径问题,详略。 代码如下:
<link rel="stylesheet" type="text/css" href="style/style.css" />
样式表中包含了定义网页外观的规则,样式表中的每条规则都有两个主要部分:选择器(selector)和声明块(declaration block)。选择器的作用在于定位以及决定哪些元素受到影响;声明块由一个或多个属性- 值对(每个属性-值对构成一条声明,declaration)组成,它们指定应该做什么(参见图5 ~图6)。

构造样式规则的步骤如下:
由于选择器具有定位作用,例如所以利用选择器就可以定位到我们想提取的数据,因此,CSS选择器经常在爬虫中出现。常见的CSS选择器语法规则如图7,见W3C链接:
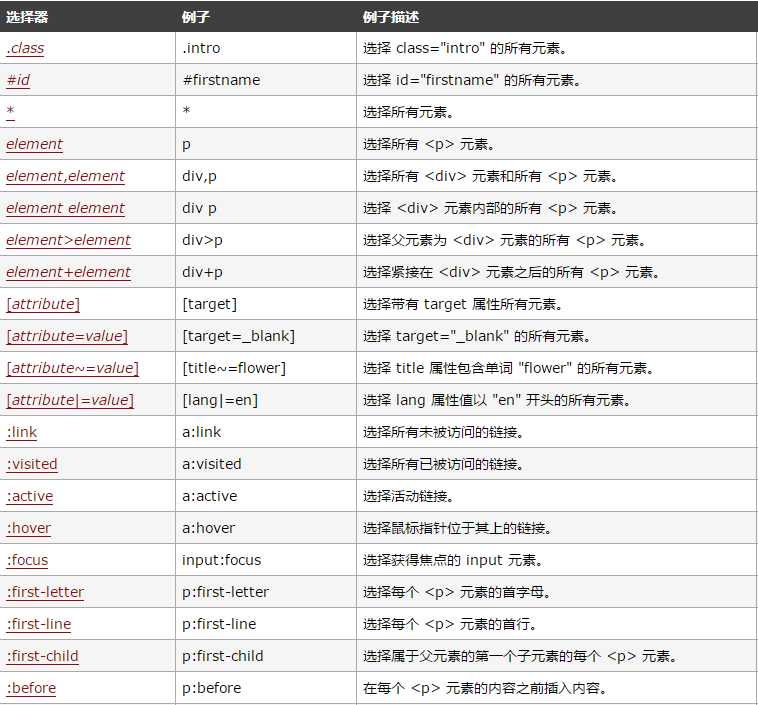
图7 一些CSS选择器的语法规则
例如如果爬取到下面这段HTML代码,就可以通过CSS选择器去提取,如下:
html_doc = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, ‘lxml‘) # 选择所有title标签,结果是一个列表,可迭代 print(soup.select("title")) # 选择body标签下的所有a标签,并获取文本 results = soup.select("body a") for result in results: print(result.get_text()) # 通过id查找 选择a标签,其id属性为link1的标签 print(soup.select("a#link1")) # 选择所有p标签中的第三个标签 print(soup.select("p:nth-of-type(3)")) # 相当于soup.select(p)[2] # 选择a标签,其href属性以lacie结尾 print(soup.select(‘a[href$="lacie"]‘)) # 选择a标签,其href属性包含.com print(soup.select(‘a[href*=".com"]‘)) # 通过【属性】查找,选择a标签,其属性中存在myname的所有标签 a = soup.select("a[myname]") # 选择a标签,其属性href=http://example.com/lacie的所有标签 b = soup.select("a[href=‘http://example.com/lacie‘]") # 选择a标签,其href属性以http开头 c = soup.select(‘a[href^="http"]‘) print(a) print(b) print(c)

1 # 选择body标签下的直接a子标签 2 print(soup.select("body > a")) 3 # 选择id=link1后的所有兄弟节点标签 4 print(soup.select("#link1~.mysis")) 5 # 选择id=link1后的下一个兄弟节点标签 6 print(soup.select("#link1 + .mysis")) 7 # 选择a标签,其类属性为mysis的标签 8 print(soup.select("a.mysis")) 9 # 从html中排除某标签,此时soup中不再有script标签 10 print([s.extract()for s in soup(‘script‘)]) 11 # 如果想排除多个呢 12 print([s.extract()for s in soup([‘script‘, ‘fram‘])])
例如如果爬取到下面这段HTML代码,就可以通过CSS选择器去提取,如下:
html = ‘‘‘ <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ‘‘‘ from pyquery import PyQuery as pq doc = pq(html) a = doc(‘.item-0.active a‘) # 先获取class为item-0 且class为active的li标签内的a标签节点,再提取属性 print(a, type(a)) print(a.attr(‘href‘)) # 获取到的结果为链接路径: link3.html print(a.attr.href) print(a.text()) # 获取文本,获得a节点的wb li = doc(‘.item-0.active‘) print(li.html()) # html()返回该节点的所有文本,包括标签a的开始和结束 lt = doc(‘li‘) print(lt.html()) # 只返回第一个li的文本,欲获取全部需要遍历 print(lt.text()) # 返回所有li的文本,用空格隔开,结果是字符串类型 print(type(lt.text())) b = doc(‘a‘) print(b, type(b)) print(b.attr.href) # attr()方法只会得到第一个节点的属性,这时,需要遍历 for item in b.items(): print(item.attr.href)
html = ‘‘‘ <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ‘‘‘ from pyquery import PyQuery as pq doc = pq(html) print(doc(‘#container .list li‘)) print(type(doc(‘#container .list li‘))) items = doc(‘.list‘) print(items.text()) print(type(items.text())) print(items) lis = items.find(‘li‘) print(lis) print(type(items)) print(type(lis)) ls = items.children() # 返回子节点 print(ls) print(type(ls))
这里只说两点,ajax和渲染,因为爬虫经常碰到
到目前为止,已经了解到浏览器在加载HTML的时候,先解析HTML文档,然后生成HTML树——DOM,同时浏览器生成了另外一棵树——CSSOM,这两个模型共同创建“渲染树”,之后浏览器就有了足够的信息去进行布局,并在屏幕上绘制页面。如果这里没有外部样式表也没有行内或者内部样式表(前面所述),也无需操心,因为浏览器本身也自带了一个默认的CSS样式表,只不过我们自定义的CSS样式表会将它覆盖而已。这里的“绘制的页面”就是要显示的页面,暂且理解成编程中的“print”吧,这里的一些奇怪的问题(比如:“浏览器显示HTML文档首尾标签去哪里啦?)”都可以类比print函数中的一些问题(“引号去哪里了?”)来看待,因为浏览器的显示和print函数是的目的都是将内容显示到电脑屏幕!只不过这里的绘制不是普通打印而是“彩打”。
渲染的过程如下(图片来自这里):
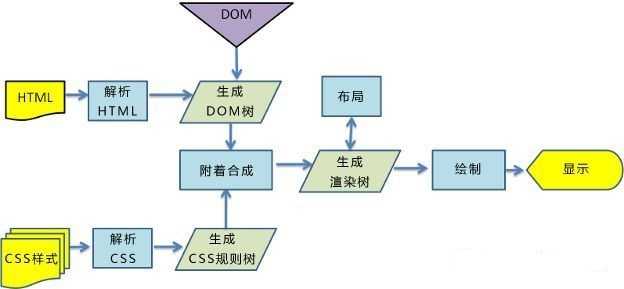
为什么渲染还和JavaScript有关呢?是的,单单是HTML和CSS就可以显示出网页,但JavaScript却有更强大的功能,其实JavaScript就是网页源代码中的一个脚本,他在浏览器显示页面的时候可以改变这个页面的布局和内容,也就是改变DOM和CSSOM的能力,从而改变了网页的显示。
Ajax是一种无需刷新页面即可从服务器(或客户端)上加载数据的手段,这里的刷新是指重新请求,重新下载页面。而Ajax却可以在不刷新的情况下加载数据,从而给人一种“流畅”的感觉。但ajax只是其中的一种手段,例如上面提到的JavaScript渲染也是这样的一种手段。那么ajax是如何实现这种效果的呢?既然加载了数据那么肯定是向服务器发送了请求,那么如何做到不显示新的页面呢?答案是XMLHttpRequest(XHR)对象,它可以实现这种方式。既然是对象当然就有类似于“send()”等方法向服务器发送请求,然后接受到服务器响应的内容,接下来avaScript就会解释并处理这些内容,然后渲染网页,继而浏览器将数据显示出来。因此在爬虫的时候要想爬取这种动态加载的数据,就需要在开发者工具中去找寻这些新的URL请求,然后再在程序中模拟这种请求,再提取数据。就这样先吧。代码来自W3C如下:
<html> <head> <script type="text/javascript"> function loadXMLDoc() { var xmlhttp; if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp=new XMLHttpRequest(); } else {// code for IE6, IE5 xmlhttp=new ActiveXObject("Microsoft.XMLHTTP"); } xmlhttp.onreadystatechange=function() { if (xmlhttp.readyState==4 && xmlhttp.status==200) { document.getElementById("myDiv").innerHTML=xmlhttp.responseText; } } xmlhttp.open("POST","/ajax/demo_post.asp",true); xmlhttp.send(); } </script> </head> <body> <h2>AJAX</h2> <button type="button" onclick="loadXMLDoc()">请求数据</button> <div id="myDiv"></div> </body> </html>
周末结束了!以上。
标签:simple chrome hide 结果 property afn object 能力 link
原文地址:https://www.cnblogs.com/ydkh/p/10012790.html
