标签:python hosts 远程服务 sla 互斥锁 标准输出 生产者消费者模式 相互 上传
1.paramiko模块
用处:连接远程服务器并执行相关操作
使用方法:
SSHClient:连接远程服务器并执行基本命令
import paramiko #创建SSH对象 ssh = paramiko.SSHClient() #允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #连接服务器 ssh.connect(hostname="cl.salt.com",port=22,username="Mr Wu",password=123456) #执行命令 stdin,stdout,stderr = ssh.exec_command("df") #标准输入、标准输出、标准错误 #获取命令结果 res,err = stdout.read(),stderr.read() result = res if res else err print(result) #关闭连接 ssh.close()
SSHFtp:连接远程服务器并执行上传下载功能
import paramiko #建立连接 transport = paramiko.Transport(("hostname",22)) transport.connect(username="Mr Wu",password="123") #TCP/IP等协议实在SFTPClient中定义的 sftp = paramiko.SFTPClient.from_transport(transport) #将本地文件location.py上传至服务器 /tmp/test.py sftp.put("/tmp/location.py","/tmp/test.py") #将远程文件remove_path 下载到本地 local_path sftp.get("remove_path","local_path") transport.close()
SSH_RSA:基于公钥密钥进行连接
RSA:非对称密钥验证
公钥:保存在要连接的服务器
私钥:保存在本地机器
import paramiko private_key = paramiko.RSAKey.from_private_key_file(‘/home/auto/.ssh/id_rsa‘) #创建SSH对象 ssh = paramiko.SSHClient() #允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #连接服务器 ssh.connect(hostname="cl.salt.com",port=22,username="Mr Wu",key_filename=private_key) #执行命令 stdin,stdout,stderr = ssh.exec_command("df") #获取命令结果 res,err = stdout.read(),stderr.read() result = res if res else err print(result.decode())
2.进程:
什么是进程:程序的执行实例称为进程。
每个进程都提供执行程序所需的资源。 进程具有虚拟地址空间,可执行代码,系统对象的打开句柄,安全上下文,唯一进程标识符,环境变量,优先级类,最小和最大工作集大小以及至少一个执行线程。 每个进程都使用单个线程启动,通常称为主线程,但可以从其任何线程创建其他线程。
进程的特点:进程之间的内存是相互独立的
要操作CPU,必须通过线程
进程之间不能直接通信,必须通过中间代理
创建子进程就是对父进程进行一次克隆
进程只能操作它的子进程,不能操作它的父进程
对父进程的修改不会对子进程产生影响
3.线程:
什么是线程:操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程的实际运作单位,一条线程指的是进程中的一个单一顺序的控制流,一个进程可以并发多个线程,每个线程可以执行不同的任务。
线程就是一段可执行的上下文,CPU运行时就不断切换上下文来执行不同的线程,当一个线程没有执行完毕时,寄存器会保存可执行的上下文的中断的位置,当CPU又切换到这段上下文时,就从中断位置继续执行
线程的特点:是操作系统的最小的调度单位,是一串指令的集合
所有在同一进程里的线程共享同一块内存空间
一个线程可以控制和操作同一进程里的其他线程
对主线程的修改可能会影响其他的线程
4.python GIL(Global Interpreter Lock)
全局解释器锁:在python中,全局解释器锁是一个互斥锁,它可以防止多个本机线程同时执行python字节码,这种锁是必要的,因为python线程调用的是操作系统的原生系统,cpython的内存管理不是线程安全的。
全局解释器锁是历史遗留问题:
这是python的内存python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁。
所以由于GIL的存在,python并不能利用cpu多核的特性,在微观层面上,python并不是真正的多线程,在同一时刻只能有一个线程在运行。
python threading模块:
线程的两种调用方式:
直接调用:
实例化一个线程:t = threading.Thread()
import threading,time #循环启动50个线程 def run(n): time.sleep(2) print("task:",n,threading.current_thread()) for i in range(50): t = threading.Thread(target=run,args=("t%s"%i,)) t.start()
继承式调用:
import threading class MyThread(threading.Thread): def __init__(self,n): super(MyThread,self).__init__() self.n = n def run(self): print("running task",self.n) t1 = MyThread("t1") t2 = MyThread("t2") t1.start() t2.start()
t.Join()
阻塞:主线程必须等待线程t执行完毕后才能继续执行
import threading,time def run(n): time.sleep(2) print("task:",n,threading.current_thread()) start_time = time.time() t_list = [] #存放线程实例 for i in range(10): t = threading.Thread(target=run,args=("t%s"%i,)) t.start() t_list.append(t) #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里 for t in t_list: t.join() end_time = time.time() print("=========all threads has finished....") print("cost:",end_time - start_time,threading.current_thread()) #整个程序是一个主线程,for循环内是子线程,主线程与子线程并发运行 #output: ‘‘‘ task: t0 <Thread(Thread-1, started 6448)> task: t1 <Thread(Thread-2, started 10080)> task: t2 <Thread(Thread-3, started 2736)> task: t3 <Thread(Thread-4, started 7072)> task: t4 <Thread(Thread-5, started 7704)> task: t6 <Thread(Thread-7, started 1280)> task: t5 <Thread(Thread-6, started 1520)> task: t8 <Thread(Thread-9, started 3764)> task: t7 <Thread(Thread-8, started 4136)> task: t9 <Thread(Thread-10, started 2444)> =========all threads has finished.... cost: 2.0088112354278564 <_MainThread(MainThread, started 6208)> ‘‘‘
t.setBaemon(True)
将线程t设置为守护线程,整个程序在非守护线程执行结束时就结束,不会等待守护进程
注:由守护进程创建的其他进程,在非守护进程结束时也会结束,不管其是否完成任务
import threading,time def run(n): time.sleep(2) print("task:",n,threading.current_thread()) start_time = time.time() for i in range(50): t = threading.Thread(target=run,args=("t%s"%i,)) t.setDaemon(True) t.start() end_time = time.time() print("=========all threads has finished....") print("cost:",end_time - start_time,threading.current_thread()) #整个程序是一个主线程,for循环内是子线程,主线程与子线程并发运行 #整个程序在非守护线程执行结束时就结束,不会等待守护进程
注:由守护进程创建的其他进程,在非守护进程结束时也会结束,不管其是否完成任务
#output: ‘‘‘ =========all threads has finished.... cost: 0.03975486755371094 <_MainThread(MainThread, started 10208)> ‘‘‘
线程锁:
设count = 0,当我们启用50个线程去执行count += 1时。按理来说,由于GIL的存在,这些线程其实是串行的,计算出的最终count的值应该等于50,但是在实际程序运行时,count的值常常会小于50。这与python GIL的运行原理有关,当CPU大概执行一百多条命令时python解释器就会释放全局解释器锁,这样就可能导致某两个线程返回的是同一个值(其中一个线程还没有执行完毕时,python解释器释放了全局解释器锁,导致另一个线程拿到的值是数据池里面没有改变的值)
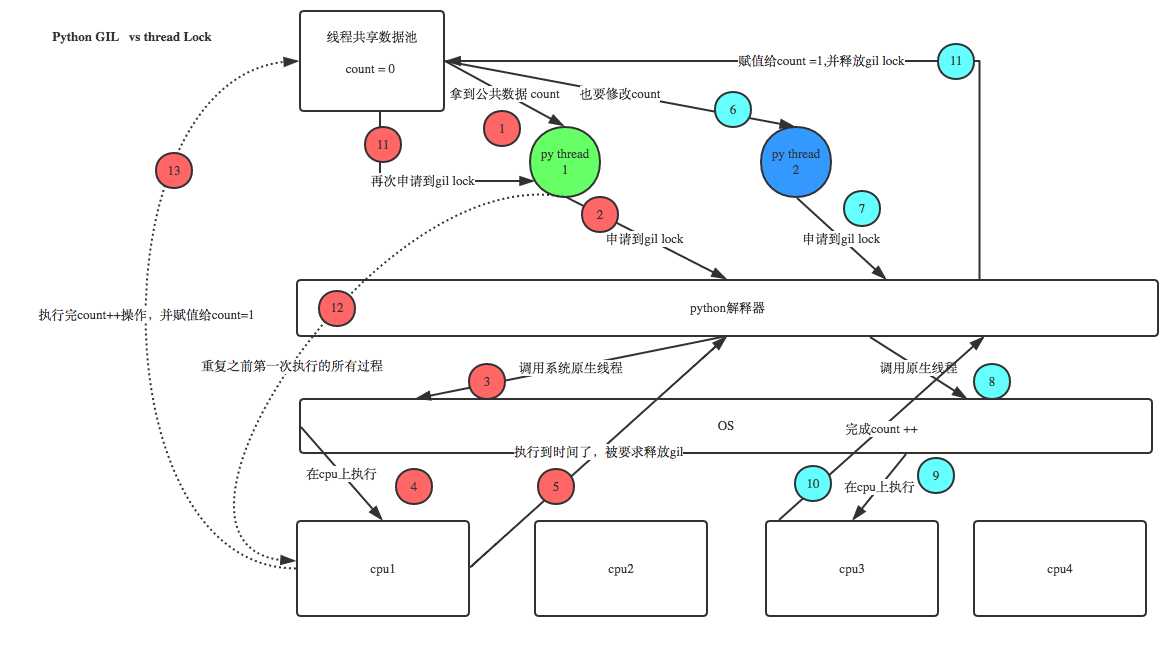
这个时候我们可以自己设置线程锁,即在一个线程执行完任务count += 1后,才会释放线程锁,其他线程才能申请全局解释器锁。
import threading,time #实例化一个线程锁 lock = threading.Lock() num = 0 #当数据量不是特别大时可使用线程锁 def run(n): lock.acquire() #加锁 global num num += 1 lock.release() #释放锁 for t in range(50): t = threading.Thread(target=run,args=(num,)) t.start() print("num:",num) #output: num: 50
递归锁(Rlock)
import threading,time num,num2 = 0,0 lock = threading.RLock() #递归锁 def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print("-----between run1 and run2------") res2 = run2() lock.release() print(res,res2) for i in range(2): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: pass else: print("=======all threads done======") print(num,num2) #output: ‘‘‘ grab the first part data -----between run1 and run2------ grab the second part data 1 1 grab the first part data -----between run1 and run2------ grab the second part data 2 2 =======all threads done====== 2 2 ‘‘‘
信号量(semaphore)
线程锁同时允许一个线程更改数据,而信号量是同时允许一定数量的线程更改数据。
注:在设置的信号量线程里,只要有一个线程完成,就会让新的线程进来,直到所有线程运行结束
semaphore = threading.BoundedSemaphore(5) #设置信号量,最大只能设置为5
semaphore.acquire() #申请线程锁
semaphore.release() #释放线程锁
#在设置的信号量线程里,只要有一个线程完成,就会让新的线程进来,保持设置的线程数直到所有线程运行结束 import threading,time def run(n): semaphore.acquire() print("run the thread: %s\n"%n) global num num += 1 time.sleep(1) semaphore.release() if __name__ == ‘__main__‘: num = 0 semaphore = threading.BoundedSemaphore()#最多允许5个线程同时运行 for i in range(20): t = threading.Thread(target=run,args=(i,)) t.start() while threading.active_count() != 1: pass else: print("-----all threads done-----") print(num)
计时器(Timer)
此类表示仅在经过一定时间后才应运行的操作。
与线程一样,通过调用start()方法启动计时器。 通过调用thecancel()方法可以停止计时器(在其动作开始之前)。 计时器在执行其操作之前将等待的时间间隔可能与用户指定的时间间隔不完全相同。
import threading def run(): print("My Name Is Mr Wu!") t = threading.Timer(10,run) t.start() #在10秒后输出 My Name Is Mr Wu!
事件(event)
事件是一个简单的同步对象;
事件代表一个内部标志和线程。
事件可以等待设置标志,或者自己设置或清除标志。
简单点来说,事件就是通过设置、清除标志位来实现两个线程之间的交互。
event = threading.Event() #生成一个事件实例
event.clear() #清空标志位
event.set() #设置标志位
event.wait() #等待标志位被设置
程序示例:红灯停、绿灯行。红灯、绿灯的持续时间都是5,当汽车看到红灯的时候停止行驶,当看到绿灯的时候行驶。
import time,threading event = threading.Event()#生成一个事件实例 def lighter(): count = 0 while True: if count > 5 and count <= 10:#改成红灯 event.clear()#清空标志位 print("\033[41;1m红灯停\033[0m") elif count > 10: #改成绿灯 #event.set() count = 0 else: event.set() print("\033[42;1m绿灯行\033[0m") time.sleep(1) count += 1 def car(name): while True: if event.is_set(): #绿灯行 print("[%s] running...."%name) time.sleep(1) else: print("[%s] sees red light , waiting..."%name) event.wait() print("[%s] sees green light , start going..."%name) car1 = threading.Thread(target=car,args=("Tesla",)) light = threading.Thread(target=lighter) light.start() car1.start()
队列(Queue)
当必须在多个线程之间安全地交换信息时,队列在线程编程中特别有用。
简单点说,队列就是一个存放数据的容器,线程既可以把数据放进去也可以把数据取出来,以此达到线程交互的目的。
class queue.Queue(maxsize = 0) #先进先出
class queue.LifoQueue(maxsize = 0) #后进先出
class queue.PriorityQueue(maxsize = 0) #存储数据时可设置优先级
优先级队列的构造函数。 maxsize是一个整数,用于设置可以放入队列的项目数的上限。 达到此大小后,插入将阻止,直到消耗队列项。 如果maxsize小于或等于零,则队列大小为无限大。
exception queue.Bmpty
在对空的Queue对象调用非阻塞get()(或get_nowait())时引发异常。
exception queue.Full
在已满的Queue对象上调用非阻塞put()(或put_nowait())时引发异常。
Queue.qsize() #返回队列的长度
Queue.empty() #return True if enmpty
Queue.full() #return True if full
Queue.put(item,block = True,timeout = None) #取出队列里的数据
当把将数据放入队列中时。 如果block=True且timeout=None(默认值),则在队列为满的时候阻塞,直到队列有空闲区域的时候才能继续放入数据。 如果timeout是一个正数,则队列阻塞最多timeout秒,如果在该时间内队列为满,则会引发Full异常。如果block=False,当队列有空闲区域时,则将数据放在队列中,否则引发Full异常(在这种情况下忽略超时)。
Queue.put_nowait(item)
Equivalent to put(item,False).
Queue.get(block = True,timeout = None)
当从队列中取出数据时。 如果block=true且timeout=None(默认值),则在队列为空的时候阻塞,直到队列中有数据时才能继续取出数据。 如果timeout是一个正数,则队列阻塞最多timeout秒,如果在该时间内队列为空,则会引发Empty异常。当block=False,当队列不为空时,则可取出数据,否则引发Empty异常(在这种情况下忽略超时)、
Queue.get_nowait(time)
Equivalent to get(item,False).
生产者消费者模型
为什么要使用生产者消费者模式?
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产这消费者模式?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
程序示例:
import threading,queue,time q = queue.Queue(maxsize=10) def producer(name): count = 1 while True: q.put("骨头%s"%count) print("生产了骨头",count) count += 1 time.sleep(2) def consumer(name): #while q.qsize() > 0: while True: print("[%s] 取到[%s],并且吃了它...."%(name,q.get())) time.sleep(1) p = threading.Thread(target=producer,args=("Alex",)) c = threading.Thread(target=consumer,args=("ChengRongHua",)) c1 = threading.Thread(target=consumer,args=("王森",)) p.start() c.start() c1.start()
标签:python hosts 远程服务 sla 互斥锁 标准输出 生产者消费者模式 相互 上传
原文地址:https://www.cnblogs.com/BUPT-MrWu/p/10014269.html