标签:理念 国际 c++实现 field func 字母 one sig 分支
第1章 预备知识
1.1 C++简介
C++融合了3中不同的编程方式:C语言代表的过程性语言,C++在C语言基础上添加的类代表的面向对象语言,C++模板支持的泛型编程
1.2 C++简史
1.2.1 C语言
20世纪70年代早期,贝尔实验室的Dennis Ritchie致力于开发Unix操作系统.为完成这项工作,Ritchie需要一种语言,它必须简洁,能够生成简洁,快速的程序,并能有效地控制硬件
Ritchie希望有一种语言能将低级语言的效率,硬件访问能力和高级语言的通用性,可移植性融合在一起,于是他在旧语言的基础上开发了C语言
1.2.2 C语言编程原理
C语言与当前最主流的语言一样,在最初面世时也是过程性(procedural)语言,这意味着它强调的是编程的算法方面
自顶向下(top-down)的设计原则
在C语言中,其理念是将大型程序分解成小型,便于管理的任务.如果其中的一项任务仍然过大,则将它分解为更小的任务.这一过程将一直持续下去,直到将程序划分为小型的,易于编写的模块
1.2.3 面向对象编程
OOP提供了一种新方法.与强调算法的过程性编程不同的是,OOP强调的是数据.OOP不像过程性编程那样,试图使问题满足语言的过程性方法,而是试图让语言来满足问题的要求.其理念是设计与问题的本质特性相对应的数据格式
在C++中,类是一种规范,它描述了这种新型数据格式,对象是根据这种规范构造的特定数据结构
OOP程序设计方法首先设计类,它们准确地表示了程序要处理的东西.类定义描述了对每个类可执行的操作,然后您便可以设计一个使用这些类的对象的程序.从低级组织(如类)到高级组织(如程序)的处理过程叫做自下向上(bottom-up)的编程
OOP编程并不仅仅是将数据和方法合并为类定义.例如,OOP还有助于创建可重用的代码,这将减少大量的工作.信息隐藏可以保护数据,使其免遭不适当的访问.多态让您能够为运算符和函数创建多个定义,通过编程上下文来确定使用哪个定义.
继承让您能够使用旧类派生出新类.正如接下来将看到的那样,OOP引入了很多新的理念,使用的编程方法不同于过程性编程.它不是将重点放在任务上,而是放在表示概念上
1.2.4 C++和泛型编程
泛型编程(generic programming)是C++支持的另一种编程模式.它与OOP的目标相同,即使重用代码和抽象通用概念的技术更简单.不过OOP强调的是编程的数据方面,而泛型编程强调的是独立于特定数据类型.它们的侧重点不同.OOP是一个管理大型项目的工具,
而泛型编程提供了指向常见任务(如对数据排序或合并链表)的工具.术语泛型(generic)指的是创建独立于类型的代码.C++数据表示同类型的数据进行排序,通常必须为每种类型创建一个排序函数.泛型编程需要对语言进行扩展,以便可以只编写一个泛型(即不是特定类型的)
函数,并将其用于各种实际类型.C++模板提供了完成这种任务的机制
1.2.5 C++的起源
与C语言一样,C++也是在贝尔实验室诞生的,Bjarne Stroustrup于20世纪80年代在这里开发出了这种语言
C++是C语言的超集,这意味着任何有效的C程序都是有效的C++程序.它们之间有些细微的差异,但无足轻重
名称C++来自C语言中的递增运算符++,该运算符将变量加1.名称C++表明,它是C的扩充版本
计算机程序将实际问题转换为计算机能够执行的一系列操作.OOP部分赋予了C++语言将问题所涉及的概念联系起来的能力,C部分则赋予了C++语言紧密联系硬件的能力
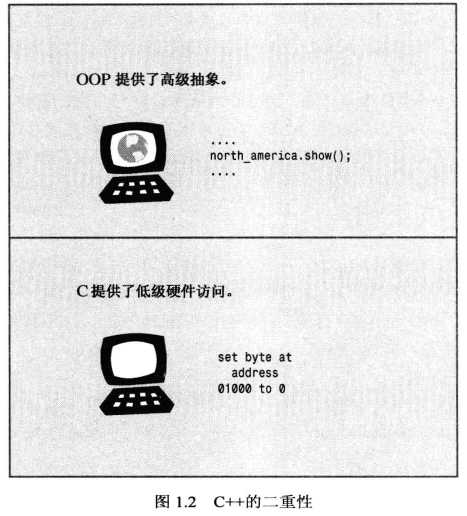
1.3 可移植性和标准
1.3.1 C++的发展
Stroustrup编写的《The Programming Language》包含65页的参考手册,它成了最初的C++事实标准
下一个事实标准是Ellis和Stroustrup编写的《The Annotated C++ Reference Manual》
C++98标准新增了大量特性,其篇幅将近800页,且包含的说明很少
C++11标准的篇幅长达1350页,对旧标准做了大量的补充
1.3.2 本书遵循的C++标准
1.4 程序创建的技巧
1.4.1 创建源代码文件
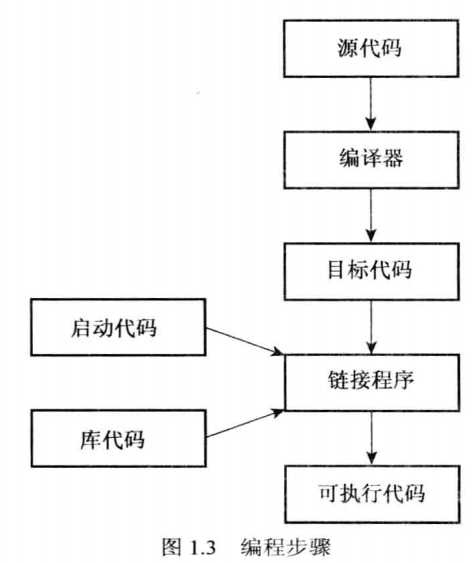
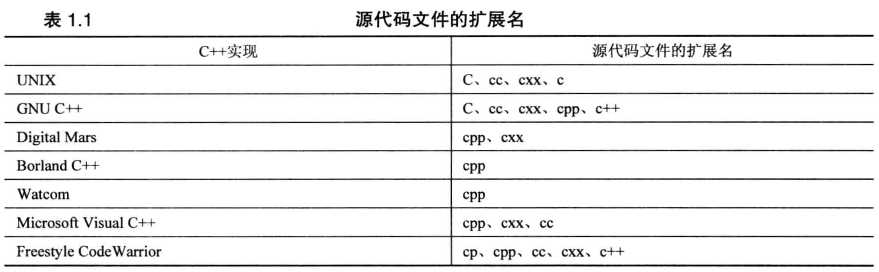
1.4.2 编译和链接
1.5 总结
第2章 开始学习C++
2.1 进入C++

#include <iostream> // 预处理器编译指令#include int main() { using namespace std; cout << "Come up and C++ me some time"; cout << endl; cout << "You won‘t regret it!" << endl; cin.get(); return 0; }
2.1.1 main()函数
通常,main()被启动代码调用,而启动代码是由编译器添加到程序中的,是程序和操作系统之间的桥梁.事实上,该函数头描述的是main()和操作系统之间的接口
在C语言中,省略返回类型相当于说函数的类型为int.然而,C++逐步淘汰了这种用法
int main(void) // very explicit style
ANSI/ISO C++标准对那些抱怨必须在main()函数最后包含一条返回语句过于繁琐做出了让步.如果编译器到达main()函数末尾时没有遇到返回语句,则认为main()函数以return 0;结尾.这条隐含的返回语句只适用于main()函数,而不适用于其他函数
2.1.2 C++注释
2.1.3 C++预处理器和iostream文件
C++和C一样,也使用一个预处理器,该程序在进行主编译之前对源文件进行处理.不必执行任何特殊的操作来调用该预处理器,它会在编译程序时自动运行
#include <iostream>
该编译指令导致预处理器将iostream文件的内容添加到程序中.这是一种典型的预处理器操作:在源代码被编译之前,替换或添加文本
这提出了一个问题:为什么要将iostream文件的内容添加到程序中呢?答案涉及程序与外部世界之间的通信.iostream中的io指的是输入(进入程序的信息)和输出(从程序中发送出去的信息).C++的输入/输出方案涉及iostream文件中的多个定义
为了使用cout来显示消息,程序需要这些定义.#include 编译指令导致iostream文件的内容随源代码文件的内容一起被发送给编译器.实际上,iostream文件的内容将取代程序中的代码行#include<iostream>.原始文件没有被修改,而是将源代码文件和iostream
组合成一个复合文件,编译的下一阶段将使用该文件
2.1.4 头文件名
像iostream这样的文件叫做包含文件(include file)--由于它们被包含在其他文件中;也叫头文件(header file)--由于它们被包含在文件起始处.C++编译器自带了很多头文件,每个头文件都支持一组特定的工具
C语言的传统是,头文件使用扩展名 h,将其作为一种通过名称标识文件类型的简单方式.例如,头文件math.h支持各种C语言数学函数,但C++的用法变了.现在,对老式C的头文件保留了扩展名 h(C++程序仍可以使用这种文件),而C++头文件则没有扩展名.
有些C头文件被转换为C++头文件,这些文件被重新命名,去掉了扩展名 h(使之成为C++风格的名称),并在文件名称前面加上前缀c(表明来自C语言).例如,C++版本的math.h为cmath.有时C头文件的C版本和C++版本相同,而有时候新版本做了一些修改.
对于纯粹的C++头文件(如 iostream)来说,去掉h不只是形式上的变化,没有h的头文件也可以包含名称空间
由于C使用不同的文件扩展名来表示不同文件类型,因此用一些特殊的扩展名(如.hpp或.hxx)表示C++头文件是有道理的,ANSI/ISO委员会也这样认为.问题在于究竟使用哪种扩展名,因此最终它们一致同意不使用任何扩展名
2.1.5 名称空间
Microflop::wanda("go dancing?"); // use Microflop namespace version
Piscine::wanda("a fish named Desire"); // use Piscine namespace version
按照这种方式,类,函数和变量便是C++编译器的标准组件,它们现在都被放置在名称空间std中.仅当头文件没有扩展名h时,情况才是如此.这意味着在iostream中定义的用于输出的cout变量实际上是std::cout,而endl实际上是std::endl
using namespace std;
这个using编译指令使得std名称空间中的所有名称都可用.这是一种偷懒的方法,在大型项目中是一个潜在的问题.更好的方法是,只使所需的名称可用.
using std::cout;
using std::endl;
using std::cin;
2.1.6 使用cout进行C++输出
endl是一个特殊的C++符号,表示一个重要的概念:重起一行.在输出流中插入endl将导致屏幕光标移到下一行.诸如endl等对于cout来说有特殊含义的特殊符号被称为控制符(manipulator).和cout一样,endl也是在头文件iostream中定义的,且位于名称空间std中.
C++还提供了另一种在输出中指示换行的旧式方法:C语言符号\n.\n被视为一个字符,名为换行符
一个差别是,endl确保程序继续运行前刷新输出(将其立即显示在屏幕上);而使用"\n"不能提供这样的保证,这意味着在有些系统中,有时可能在您输入信息后才会出现提示
换行符是一种被称为"转义序列"的按键组合
2.1.7 C++源代码的格式化
2.2 C++语句
#include <iostream> int main() { using namespace std; int carrots; carrots = 25; cout << "I have "; cout << carrots; cout << " carrots."; cout << endl; carrots = carrots - 1; cout << "Crunch, crunch. Now I have " << carrots << " carrots." << endl; cin.get(); return 0; }
2.2.1 声明语句和变量
2.2.2 赋值语句
int steinway;
int baldwin;
int yamaha;
yamaha = baldwin = steinway = 88;
赋值将从右到向左进行.首先,88被赋给steinway;然后,stenway的值(现在是88)被赋给baldwin;然后baldwin的值88被赋给yamah(C++遵循C的爱好,允许外观奇怪的代码)
2.2.3 cout的新花样
2.3 其他C++语句
#include <iostream> int main() { using namespace std; int carrots; cout << "How many carrots do you have?" << endl; cin >> carrots; cout << "Here are two more."; carrots = carrots + 2; cout << "Now you have " << carrots << " carrots." << endl; cin.get(); cin.get(); return 0; }
2.3.1 使用cin
cin >> carrots;
从这条语句可知,信息从cin流向carrots.显然,对这一过程有更为正式的描述.就像C++将输出看作是流出程序的字符流一样,它也将输入看作是流入程序的字符流.iostream文件将cin定义为一个表示这种流的对象.
输出时,<<运算符将字符串插入到输出流中;输入时,cin使用>>运算符从输入流中抽取字符
2.3.2 使用cout进行拼接
2.3.3 类简介
2.4 函数
2.4.1 使用有返回值函数
表达式sqrt(6.25)将调用sqrt()函数.表达式sqrt(6.25)被称为函数调用,被调用的函数叫做被调用函数(called function),包含函数调用的函数叫做调用函数(calling function)
double sqrt(double); // function prototype
原型结尾的分号表明它是一条语句,这使得它是一个原型,而不是函数头.如果省略分号,编译器将把这行代码解释为一个函数头,并要求接着提供定义该函数的函数体
应在首次使用函数之前提供其原型.通常的做法是把原型放到main()函数定义的前面
#include <iostream> #include <cmath> int main() { using namespace std; double area; cout << "Enter the floor area,in square feet,of your home: "; cin >> area; double side; side = sqrt(area); cout << "That‘s the equivalent of a square " << side << " feet to the side." << endl; cout << "How fascinating!" << endl; cin.get(); cin.get(); return 0; }
C++还允许在创建变量时对它进行赋值,double side = sqrt(are);这个过程叫做初始化(initialization)
2.4.2 函数变体
2.4.3 用户定义的函数
#include <iostream> void simon(int); int main() { using namespace std; simon(3); cout << "Pick an integer: "; int count; cin >> count; simon(count); cout << "Done!" << endl; cin.get(); cin.get(); return 0; } void simon(int n) { using namespace std; cout << "Simon says touch your toes " << n << " times." << endl; }
main()的返回值并不是返回给程序的其他部分,而是返回给操作系统
2.4.4 用户定义的有返回值的函数
#include <iostream> int stonetolb(int); int main() { using namespace std; int stone; cout << "Enter the weight in stone: "; cin >> stone; int pounds = stonetolb(stone); cout << stone << " stone = "; cout << pounds << " pounds." << endl; cin.get(); cin.get(); return 0; } int stonetolb(int sts) { return 14 * sts; }
2.4.5 在多函数程序中使用using编译指令
2.5 总结
2.6 复习题
2.7 编程练习
第3章 处理数据
3.1 简单变量
3.1.1 变量名
3.1.2 整型
术语宽度(width)用于描述存储整数时使用的内存量.使用的内存越多,则越宽
char类型最常用来表示字符,而不是数字
3.1.3 整型short,int,long和long long
short是short int 的简称,而long是long int的简称
#include <iostream> #include <climits> int main() { using namespace std; int n_int = INT_MAX; short n_short = SHRT_MAX; long n_long = LONG_MAX; long long n_llong = LLONG_MAX; cout << "int is " << sizeof(int) << " bytes." << endl; cout << "short is " << sizeof n_short << " bytes." << endl; cout << "long is " << sizeof n_long << " bytes." << endl; cout << "long long is " << sizeof n_llong << " bytes." << endl; cout << endl; cout << "Maximum values:" << endl; cout << "int: " << n_int << endl; cout << "short: " << n_short << endl; cout << "long: " << n_long << endl; cout << "long long: " << n_llong << endl << endl; cout << "Minimum value = " << INT_MIN << endl; cout << "Bits per byte = " << CHAR_BIT << endl; cin.get(); return 0; }
#define编译指令的工作方式与文本编辑器或字处理器中的全局搜索并替换命令相似.预处理器查找独立的标记(单独的单词),跳过嵌入的单词
#define编译指令是C语言遗留下来的.C++有一种更好的创建符号常量的方法(使用关键字const),所以不会经常使用#define.然而,有些头文件,尤其是那些被设计成可用于C和C++中的头文件,必须使用#define
3.1.4 无符号类型
#include <iostream> #define ZERO 0 #include <climits> int main() { using namespace std; short sam = SHRT_MAX; unsigned short sue = sam; cout << "Sam has " << sam << " dollars and Sue has " << sue; cout << " dollars deposited." << endl << "Add $1 to each account." << endl << "Now "; sam = sam + 1; sue = sue + 1; cout << "Sam has " << sam << " dollars and Sue has " << sue; cout << " dollars deposited.\nPoor Sam!" << endl; sam = ZERO; sue = ZERO; cout << "Sam has " << sam << " dollars and Sue has " << sue; cout << " dollars deposited." << endl; cout << "Take $1 from each account." << endl << "Now "; sam = sam - 1; sue = sue - 1; cout << "Sam has " << sam << " dollars and Sue has " << sue; cout << " dollars deposited." << endl << "Lucky Sue!" << endl; cin.get(); return 0; }
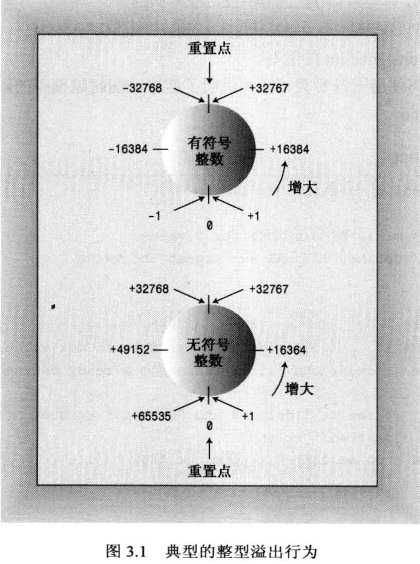
通常,int被设置为对目标计算机而言最为"自然"的长度.自然长度(natrual size)指的是计算机处理起来效率最高的长度.如果没有非常有说服力的理由来选择其他类型,则应使用int
C++使用前一(两)位来标识数字常量的基数.如果第一位为1~9,则基数为10(十进制);因此93是以10为基数的.如果第一位是0,第二位为1~7,则基数为8(八进制);因此042的基数是8;它相当于十进制数34
如果前两位为0x或0X,则基数为16(十六进制);因此0x42为十六进制数,相当于十进制数66.对于十六进制数,字符a~f和A~F表示了十六进制位,对应于10~15.
#include <iostream> int main() { using namespace std; int chest = 42; int waist = 0x42; int inseam = 042; cout << "Monsieur cuts a striking figure!\n"; cout << "chest = " << chest << " (42 in decimal)\n"; cout << "waist = " << waist << " (0x42 in hex)\n"; cout << "inseam = " << inseam << " (042 in octal)\n"; cin.get(); return 0; }
#include <iostream> int main() { using namespace std; int chest = 42; int waist = 42; int inseam = 42; cout << "Monsieur cuts a striking figure!" << endl; cout << "chest = " << chest << " (decimal for 42)" << endl; cout << hex; cout << "waist = " << waist << " (hexadecimal for 42)" << endl; cout << oct; cout << "inseam = " << inseam << " (octal for 42)" << endl; cin.get(); return 0; }
3.1.5 选择整型类型
3.1.6 整型字面值
3.1.7 C++如何确定常量的类型
3.1.8 char类型:字符和小整数
#include <iostream> int main() { using namespace std; char ch; cout << "Enter a character: " << endl; cin >> ch; cout << "Hola! "; cout << "Thank you for the " << ch << " character." << endl; cin.get(); cin.get(); return 0; }
#include <iostream> int main() { using namespace std; char ch = ‘M‘; int i = ch; cout << "The ASCII code for " << ch << " is " << i << endl; cout << "Add one to the character code:" << endl; ch = ch + 1; i = ch; cout << "The ASCII code for " << ch << " is " << i << endl; cout << "Displaying char ch using cout.put(ch): "; cout.put(ch); cout.put(‘!‘); cout << endl << "Done" << endl; cin.get(); cin.get(); return 0; }
有些字符不能直接通过键盘输入到程序中.例如,按回车键并不能使字符串包含一个换行符;相反,程序编辑器将把这种键击解释为在源代码中开始新的一行.其他一些字符也无法从键盘输入,因此C++语言赋予了它们特殊的含义
对于这些字符,C++提供了一种特殊的表示方法-----转义序列.转义序列的概念可追溯到使用电传打字机与计算机通信的时代,现代系统并非都支持所有的转义序列
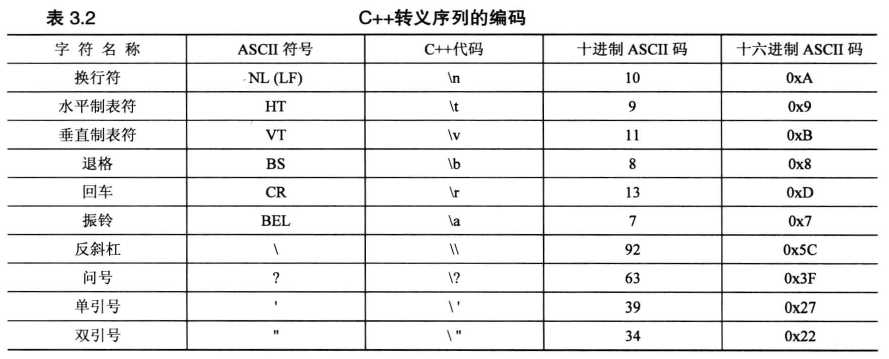
C++实现支持一个基本的源字符集,即可用来编写源代码的字符集.它由标准美国键盘上的字符(大写和小写)和数字,C语言中使用的符号(如{和=}以及其他一些字符(如换行符和空格)组成.还有一个基本的执行字符集,它包括在程序执行期间可处理的字符(如可从文件中读取或显示到屏幕上的字符).它增加了一些字符,如退格和振铃.C++标准还允许实现提供扩展源字符集和扩展执行字符集.另外,那些被作为字母的额外字符也可用于标识符名称中.也就是说,德国实现可能允许使用日耳曼语的元音变音,而法国实现则允许使用重元音.C++有一种表示这种特殊字符的机制,它独立于任何特定的键盘,使用的是通用字符名(universal character name)
通用字符名的用法类似于转义序列.通用字符名可以以\u或\U打头.\u后面是8个十六进制位,\U后面则是16个十六进制位.这些位表示的是字符的ISO 10646码点(ISO 10646是一种正在制定的国际标准,为大量的字符提供了数值编码)
int k\u00F6rper;
cout << "Let them eat g\u00E2teau.\n";
与int不同的是,char在默认情况下既不是没有符号,也不是有符号.是否有符号由C++实现决定
char fodo; // may be sigend,may be unsigned
unsigend char bar; // definitely unsigend
sigend char snark; // definitely sigend
如果将char用作数值类型,则unsigend char 和 signed char 之间的差异将非常重要.另一方面,如果使用char变量来存储标准ASCII字符,则char有没有符号都没关系,在这种情况下,可以使用char
cin和cout将输入和输出看作是char流,因此不适于用来处理wchar_t类型.iostream头文件的最新版本提供了作用相似的工具--wcin和wcout,可用于处理wchar_t流.另外,可以通过加上前缀L来表示宽字符常量和宽字符串
wchar_t bob = L‘P‘; // a wide-character constant
wcout << L"tall" << endl; // outputting a wide-character string
char16_t ch1 = u‘q‘; // basic character in 16-bit form
char32_t ch2 = U‘\U0000222B‘; // universal character name in 32-bit form
3.19 bool类型
ANSI/ISO C++标准添加了一种名叫bool的新类型(对C++来说是新的)
字面值true和false都可以通过提升转换为int类型,true被转换为1,而false被转换为0
int ans = true; // ans assigend 1
int promise = false; // promise assigned 0
另外,任何数字值或指针值都可以隐式转换(即不用显式强制转换)为bool值.任何非零值都被转换为true,而零被转换为false;
bool start = -100; // start assigned true
bool stop = 0; // stop assigned false
3.2 const 限定符
关键字const叫做限定符,因为它限定了声明的含义
如果以前使用过C语言,您可能觉得前面讨论的#define语句已经足够完成这样的工作了.但const比#define好,首先,它能够明确指定类型.其次,可以使用C++的作用域规则将定义限制在特定的函数或文件中.第三,可以将const用于更复杂的类型
ANSI C也使用const限定符,这是从C++借鉴来的.如果熟悉ANSI C版本,则应注意,C++版本稍微有些不同.区别之一是作用域规则.另一个主要的区别是,在C++中可以const值来声明数组长度
3.3 浮点数
3.3.1 书写浮点数
d.dddE+n指的是将小数点向右移n位,而d.dddE-n指的是将小数点向左移n位.之所以称为"浮点",就是因为小数点可移动
3.3.2 浮点类型
和ANSI C一样,C++也有3种浮点类型:float,double和long double.这些类型是按它们可以表示的有效数位和允许的指数最小范围来描述的.有效位(significant figure)是数字中有意义的位.例如,加利福利亚的Shasta山脉的高度位14179英尺,该数字使用了5个有效位
指出了最接近的英尺数.然而,将Shasta山脉的高度写成约14000英尺时,有效位数为2位,因为结果经过四舍五入精确到了千位.在这种情况下,其余的3位只不过是占位符而已.有效位数不依赖于小数点的位置.例如,可以将高度写成14.162千英尺.这样仍有5个有效位,
因为这个值精确到了第5位
事实上,C和C++对于有效位数的要求是,float至少32位,double至少48位,且不少于float,long double至少和double一样多.这三种类型的有效位数可以一样多.然而,通常,float为32位,double为64位,long double为80,96或128位.另外,这3种类型的指数范围至少是-37到37
#include <iostream> int main() { using namespace std; cout.setf(ios_base::fixed, ios_base::floatfield); // fixed-point float tub = 10.0 / 3.0; // good to about 6 places double mint = 10.0 / 3.0; // good to about 15 places const float million = 1.0e6; cout << "tub = " << tub; cout << ", a million tubs = " << million * tub; cout << ",\nand ten million tubs = "; cout << 10 * million * tub << endl; cout << "mint = " << mint << " and a million mints = "; cout << million * mint << endl; cin.get(); return 0; }
3.3.3 浮点常量
在默认情况下,像8.24和2.4E8这样的浮点常量都属于double类型.如果希望常量为float类型,请使用f或F后缀.对于long double类型,可使用l或L后缀(由于l看起来像数字1,因此L是更好的选择).
#include <iostream> int main() { using namespace std; float a = 2.34E+22f; float b = a + 1.0f; cout << "a = " << a << endl; cout << "b - a = " << b - a << endl; cin.get(); return 0; }
3.3.4 浮点数的优缺点
C++对基本类型进行分类,形成了若干个族.类型signed char,short,int和long统称为符号类型;它们的无符号版本统称为无符号类型;C++11新增了long long,bool,wchar_t,符号整型和无符号整型;C++11新增了char16_t和char32_t.float,double和long double统称为浮点型.
整数和浮点型统称算术(arithmetic)类型
3.4 C++算术符
#include <iostream> int main() { using namespace std; float hats, heads; cout.setf(ios_base::fixed, ios_base::floatfield); cout << "Enter a number: "; cin >> hats; cout << "Enter another number: "; cin >> heads; cout << "hats = " << hats << "; heads = " << heads << endl; cout << "hats + heads = " << hats + heads << endl; cout << "hats - heads = " << hats - heads << endl; cout << "hats * heads = " << hats * heads << endl; cout << "hats / heads = " << hats / heads << endl; cin.get(); cin.get(); return 0; }
也许读者对得到的结果心存怀疑.11.17加上50.25应等于61.42,但是输出种却是61.419998.这不是运算问题;而是由于float类型表示有效位数的能力有限.记住,对于float,C++只保证6位有效位.如果将61.419998四舍五入成6位,将得到61.4200,这是保证精度下的正确值.
如果需要更高的精度,请使用double或long double.
3.4.1 运算符优先级和结合性
C++使用优先级规则来决定首先使用哪个运算符
当两个运算符的优先级相同时,C++将看操作数的结合性(associativity)是从左到右,还是从右到左.从左到右的结合性意味着如果两个优先级相同的运算符被同时用于同一个操作数,则首先应用左侧的运算符.从右到左的结合性则首先应用右侧的运算符
注意,仅当两个运算符被用于同一个操作数时,优先级和结合性规则才有效.
int dues = 20 * 5 + 24 * 6;
运算符优先级表明了两点:程序必须在做加法之前计算20 * 5,必须在做加法之前计算24 * 6.但优先级和结合性都没有指出应先计算哪个乘法.读者可能认为,结合性表明应先做左侧的乘法,但是在这种情况下,两个*运算符并没有用于同一个操作数,所以该规则不适用
事实上,C++把这个问题留给了实现,让它来决定在系统种的最佳顺序
3.4.2 除法分支
#include <iostream> int main() { using namespace std; cout.setf(ios_base::fixed, ios_base::floatfield); cout << "Integer division: 9 / 5 = " << 9 / 5 << endl; cout << "Floating-point division: 9.0 / 5.0 = "; cout << 9.0 / 5.0 << endl; cout << "Mixed divison: 9.0 / 5 = " << 9.0 / 5 << endl; cout << "double constants: 1e7/9.0 = "; cout << 1.e7 / 9.0 << endl; cout << "float constants: 1e7f/ 9.0f = "; cout << 1.e7f / 9.0f << endl; cin.get(); cin.get(); return 0; }
3.4.3 求模运算符
#include <iostream> int main() { using namespace std; const int Lbs_per_stn = 14; int lbs; cout << "Enter your weight in pounds: "; cin >> lbs; int stone = lbs / Lbs_per_stn; int pounds = lbs % Lbs_per_stn; cout << lbs << " pound are " << stone << " stone, " << pounds << " pound(s).\n"; cin.get(); cin.get(); return 0; }
3.4.4 类型转换
#include <iostream> int main() { using namespace std; cout.setf(ios_base::fixed, ios_base::floatfield); float tree = 3; // int converted to float int guess(3.9832); // double converted to int int debt = 7.2E12; // result not defined in C++ cout << "tree = " << tree << endl; cout << "guess = " << guess << endl; cout << "debt = " << debt << endl; cin.get(); cin.get(); return 0; }
在计算表达式时,C++将bool,char,unsigned char,signed char和short值转换为int.这些转换被称为整型提升(integral promotion)
强制类型转换不会修改变量本身,而是创建一个新的,指定类型的值,可以在表达式种使用这个值.
(typeName) value // converts value to typeName type
typeName (value) // converts value to typeName type
第一种格式来自C语言,第二种格式是纯粹的C++.新格式的想法是,要让强制类型转换就像是函数调用.这样对内置类型的强制类型转换就像是为用户定义的类设计的类型转换
#include <iostream> int main() { using namespace std; int auks, bats, coots; // the following statement adds the values as double, // then converts the result to int auks = 19.99 + 11.99; // these statements add values as int bats = (int)19.99 + (int)11.99; // old C syntax coots = int(19.99) + int(11.99); // new C++ syntax; cout << "auks = " << auks << ", bats = " << bats; cout << ", coots = " << coots << endl; char ch = ‘Z‘; cout << "The code for " << ch << " is "; // print as char cout << int(ch) << endl; // print as int cout << "Yes, the code is "; cout << static_cast<int>(ch) << endl; // using static_cast cin.get(); return 0; }
3.4.5 C++11中的auto声明
3.5 总结
3.6 复习题
3.7 编程练习
第4章 复合类型
4.1 数组
数组之所以被称为复合类型,是因为它是使用其他类型来创建的.不能仅仅将某种东西声明为数组,它必须是特定类型的数组.没有通用的数组类型,但存在很多特定的数组类型,如char数组或long数组.
#include <iostream> int main() { using namespace std; int yams[3]; yams[0] = 7; yams[1] = 8; yams[2] = 6; int yamcosts[3] = { 20,30,5 }; cout << "Total yams = "; cout << yams[0] + yams[1] + yams[2] << endl; cout << "The package with " << yams[1] << " yams costs "; cout << yamcosts[1] << " cents per yam.\n"; int total = yams[0] * yamcosts[0] + yams[1] * yamcosts[1]; total = total + yams[2] * yamcosts[2]; cout << "The total yam expense is " << total << " cents.\n"; cout << "\nSize of yams array = " << sizeof yams; cout << " bytes.\n"; cout << "Size of one element = " << sizeof yams[0]; cout << " bytes.\n"; cin.get(); cin.get(); return 0; }
4.1.1 程序说明
4.1.2 数组的初始化规则
4.1.3 C++11数组初始化方法
4.2 字符串
字符串是存储在内存的连续字节中的一系列字符.C++处理字符串的方式有两种.第一种来自C语言,常被称为C-风格字符串(C-style string).另一种基于string类库的方法
4.2.1 拼接字符串常量
4.2.2 在数组中使用字符串
#include <iostream> #include <cstring> int main() { using namespace std; const int Size = 15; char name1[Size]; char name2[Size] = "C++owboy"; cout << "Howdy! I‘m " << name2; cout << "! What‘s your name?\n"; cin >> name1; cout << "Well, " << name1 << ", your name has "; cout << strlen(name1) << " letters and is stored\n"; cout << "in an array of " << sizeof(name1) << " bytes.\n"; cout << "Your initial is " << name1[0] << ".\n"; name2[3] = ‘\0‘; cout << "Here are the first 3 characters of my name: "; cout << name2 << endl; cin.get(); cin.get(); return 0; }
4.2.3 字符串输入
#include <iostream> int main() { using namespace std; const int ArSize = 20; char name[ArSize]; char dessert[ArSize]; cout << "Enter your name:\n"; cin >> name; cout << "Enter your favorite dessert:\n"; cin >> dessert; cout << "I have some delicious " << dessert; cout << " for you, " << name << ".\n"; cin.get(); cin.get(); return 0; }
4.2.4 每次读取一行字符串输入
#include <iostream> int main() { using namespace std; const int ArSize = 20; char name[ArSize]; char dessert[ArSize]; cout << "Enter your name:\n"; cin.getline(name, ArSize); cout << "Enter your favorite dessert:\n"; cin.getline(dessert, ArSize); cout << "I have some delicious " << dessert; cout << " for you, " << name << ".\n"; cin.get(); return 0; }
#include <iostream> int main() { using namespace std; const int ArSize = 20; char name[ArSize]; char dessert[ArSize]; cout << "Enter your name:\n"; cin.get(name, ArSize).get(); cout << "Enter your favorite dessert:\n"; cin.get(dessert, ArSize).get(); cout << "I have some delicious " << dessert; cout << " for you, " << name << ".\n"; cin.get(); return 0; }
4.2.5 混合输入字符串和数字
4.3 string简介
#include <iostream> #include <string> int main() { using namespace std; char charr1[20]; char charr2[20] = "jaguar"; string str1; string str2 = "panther"; cout << "Enter a kind of feline: "; cin >> charr1; cout << "Enter another kind of feline: "; cin >> str1; cout << "Here are some felines:\n"; cout << charr1 << " " << charr2 << " " << str1 << " " << str2 << endl; cout << "The thrid letter in " << charr2 << " is " << charr2[2] << endl; cout << "The third letter in " << str2 << " is " << str2[2] << endl; cin.get(); cin.get(); return 0; }
4.3.1 C++11字符串初始化
4.3.2 赋值,拼接和附加
#include <iostream> #include <string> int main() { using namespace std; string s1 = "penguin"; string s2, s3; cout << "You can assign one string object to another: s2 = s1\n"; s2 = s1; cout << "s1: " << s1 << ", s2: " << s2 << endl; cout << "You can assign a C-style string to a string object.\n"; cout << "s2 = \"buzzard\"\n"; s2 = "buzzard"; cout << "s2: " << s2 << endl; cout << "You can concatenate strings: s3 = s1 + s2\n"; s3 = s1 + s2; cout << "s3: " << s3 << endl; cout << "You can append strings.\n"; s1 += s2; cout << "s1 += s2 yields s1 = " << s1 << endl; s2 += " for a day"; cout << "s2 += \" for a day\" yields s2 = " << s2 << endl; cin.get(); cin.get(); return 0; }
4.3.3 string类的其他操作
4.3.4 stringl类I/O
4.3.5 其他形式的字符串字面值
4.4 结构简介
4.4.1 在程序中使用结构
4.4.2 C++11结构初始化
4.4.3 结构可以将string类作为成员吗
4.4.4 其他结构属性
4.4.5 结构数组
4.4.6 结构中的位字段
4.5 共用体
4.6 枚举
4.6.1 设置枚举量的值
4.6.2 枚举的取值范围
4.7 指针和自由存储空间
4.7.1 声明和初始化指针
4.7.2 指针的危险
4.7.3 指针和数字
4.7.4 使用new来分配内存
4.7.5 使用delete释放内存
4.7.6 使用new来创建动态数组
4.8 指针,数组和指针算术
4.8.1 程序说明
4.8.2 指针小结
4.8.3 指针和字符串
4.8.4 使用new创建动态结构
4.8.5 自动存储,静态存储和动态存储
4.9 类型组合
4.10 数组的代替品
4.10.1 模板类vector
4.10.2 模板类array(C++11)
4.10.3 比较数组,vector对象和array对象
4.11 总结
4.12 复习题
4.13 编程练习
第5章 循环和关系表达式
5.1 for循环
5.1.1 for循环的组成部分
5.1.2 回到for循环
5.1.3 修改步长
5.1.4 使用for循环访问字符串
5.1.5 递增运算符(++)和递减运算符(--)
5.1.6 副作用和顺序点
5.1.7 前缀格式和后缀格式
5.1.8 递增/递减运算符和指针
5.1.9 组合赋值运算符
5.1.10 复合语句(语句块)
5.1.11 其他语法技巧-逗号运算符
5.1.12 关系表达式
5.1.13 赋值,比较和可能犯的错误
5.1.14 C-风格字符串的比较
5.1.15 比较string类字符串
5.2 while循环
5.2.1 for与while
5.2.2 等待一段时间:编写延时循环
5.3 do while循环
5.4 基于范围的for循环(C++11)
5.5 循环和文本输入
5.5.1 使用原始的cin进行输入
5.5.2 使用cin.get(char)进行补救
5.5.3 使用哪一个cin.get()
5.5.4 文件尾条件
5.5.5 另一个cin.get()版本
5.6 嵌套循环和二维数组
5.6.1 初始化二维数组
5.6.2 使用二维数组
5.7 总结
5.8 复习题
5.9 编程练习
第6章 分支语句和逻辑运算符
第7章 函数-C++的编程模块
第8章 函数探幽
第9章 内存模型和名称空间
第10章 对象和类
第11章 使用类
第12章 类和动态内存分配
第13章 类继承
第14章 C++中的代码重用
第15章 友元,异常和其他
第16章 string类和标准模板库
第17章 输入,输出和文件
第18章 探讨C++新标准
附录A 计数系统
附录B C++保留字
附录C ASCII字符集
附录D 运算符优先级
附录E 其他运算符
附录F 模板类string
附录G 标准模板库方法和函数
附录H 精选读物和网上资源
附录I 转换为ISO标准C++
标签:理念 国际 c++实现 field func 字母 one sig 分支
原文地址:https://www.cnblogs.com/revoid/p/9763188.html
