标签:运算 并且 cte finally 重载方法 ping 应用 index github
作为.net程序员,使用过指针,写过不安全代码吗?
为什么要使用指针,什么时候需要使用它?
如果能很好地回答这两个问题,那么就能很好地理解今天了主题了。C#构建了一个托管世界,在这个世界里,只要不写不安全代码,不操作指针,那么就能获得.Net至关重要的安全保障,即什么都不用担心;那如果我们需要操作的数据不在托管内存中,而是来自于非托管内存,比如位于本机内存或者堆栈上,该如何编写代码支持来自任意区域的内存呢?这个时候就需要写不安全代码,使用指针了;而如何安全、高效地操作任何类型的内存,一直都是C#的痛点,今天我们就来谈谈这个话题,讲清楚 What、How 和 Why ,让你知其然,更知其所以然,以后有人问你这个问题,就让他看这篇文章吧,呵呵。
回答这个问题前,先总结一下如何用C#操作任何类型的内存:
托管内存(managed memory )
var mangedMemory = new Student();很熟悉吧,只需使用new操作符就分配了一块托管堆内存,而且还不用手工释放它,因为它是由垃圾收集器(GC)管理的,GC会智能地决定何时释放它,这就是所谓的托管内存。默认情况下,GC通过复制内存的方式分代管理小对象(size < 85000 bytes),而专门为大对象(size >= 85000 bytes)开辟大对象堆(LOH),管理大对象时,并不会复制它,而是将其放入一个列表,提供较慢的分配和释放,而且很容易产生内存碎片。
栈内存(stack memory )
unsafe{
var stackMemory = stackalloc byte[100];
}很简单,使用stackalloc关键字非常快速地就分配好了一块栈内存,也不用手工释放,它会随着当前作用域而释放,比如方法执行结束时,就自动释放了。栈内存的容量非常小( ARM、x86 和 x64 计算机,默认堆栈大小为 1 MB),当你使用栈内存的容量大于1M时,就会报StackOverflowException 异常 ,这通常是致命的,不能被处理,而且会立即干掉整个应用程序,所以栈内存一般用于需要小内存,但是又不得不快速执行的大量短操作,比如微软使用栈内存来快速地记录ETW事件日志。
本机内存(native memory )
IntPtr nativeMemory0 = default(IntPtr), nativeMemory1 = default(IntPtr);
try
{
unsafe
{
nativeMemory0 = Marshal.AllocHGlobal(256);
nativeMemory1 = Marshal.AllocCoTaskMem(256);
}
}
finally
{
Marshal.FreeHGlobal(nativeMemory0);
Marshal.FreeCoTaskMem(nativeMemory1);
}通过调用方法Marshal.AllocHGlobal或Marshal.AllocCoTaskMem来分配非托管堆内存,非托管就是垃圾回收器(GC)不可见的意思,并且还需要手工调用方法Marshal.FreeHGlobal or Marshal.FreeCoTaskMem 释放它,千万不能忘记,不然就产生内存碎片了。
首先我们设计一个解析完整或部分字符串为整数的API,如下:
public interface IntParser
{
// allows us to parse the whole string.
int Parse(string managedMemory);
// allows us to parse part of the string.
int Parse(string managedMemory, int startIndex, int length);
// allows us to parse characters stored on the unmanaged heap / stack.
unsafe int Parse(char* pointerToUnmanagedMemory, int length);
// allows us to parse part of the characters stored on the unmanaged heap / stack.
unsafe int Parse(char* pointerToUnmanagedMemory, int startIndex, int length);
}从上面可以看到,为了支持解析来自任何内存区域的字符串,一共写了4个重载方法。
接下来在来设计一个支持复制任何内存块的API,如下:
public interface MemoryblockCopier
{
void Copy<T>(T[] source, T[] destination);
void Copy<T>(T[] source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, void* destination, int elementsCount);
unsafe void Copy<T>(void* source, int sourceStartIndex, void* destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, int sourceLength, T[] destination);
unsafe void Copy<T>(void* source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
}脑袋蒙圈没,以前C#操纵各种内存就是这么复杂、麻烦。通过上面的总结如何用C#操作任何类型的内存,相信大多数同学都能够很好地理解这两个类的设计,但我心里是没底的,因为使用了不安全代码和指针,这些操作是危险的、不可控的,根本无法获得.net至关重要的安全保障,并且可能还会有难以预估的问题,比如堆栈溢出、内存碎片、栈撕裂等等,微软的工程师们早就意识到了这个痛点,所以span诞生了,它就是这个痛点的解决方案。
先来看看,如何使用span操作各种类型的内存(伪代码):
托管内存(managed memory )
var managedMemory = new byte[100];
Span<byte> span = managedMemory;栈内存(stack memory )
var stackedMemory = stackalloc byte[100];
var span = new Span<byte>(stackedMemory, 100);本机内存(native memory )
var nativeMemory = Marshal.AllocHGlobal(100);
var nativeSpan = new Span<byte>(nativeMemory.ToPointer(), 100);span就像黑洞一样,能够吸收来自于内存任意区域的数据,实际上,现在,在.Net的世界里,Span
现在重构上面的两个设计,如下:
public interface IntParser
{
int Parse(Span<char> managedMemory);
int Parse(Span<char>, int startIndex, int length);
}
public interface MemoryblockCopier
{
void Copy<T>(Span<T> source, Span<T> destination);
void Copy<T>(Span<T> source, int sourceStartIndex, Span<T> destination, int destinationStartIndex, int elementsCount);
}上面的方法根本不关心它操作的是哪种类型的内存,我们可以自由地从托管内存切换到本机代码,再切换到堆栈上,真正的享受玩转内存的乐趣。
浅析span的工作机制
先来窥视一下源码:
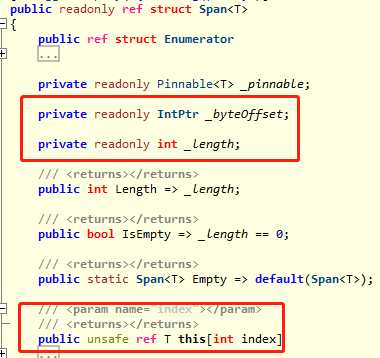
我已经圈出的三个字段:偏移量、索引、长度(使用过ArraySegment<byte> 的同学可能已经大致理解到设计的精髓了),这就是它的主要设计,当我们访问span表示的整体或部分内存时,内部的索引器会按照下面的算法运算指针(伪代码):
ref T this[int index]
{
get => ref ((ref reference + byteOffset) + index * sizeOf(T));
}整个变化的过程,如图所示:
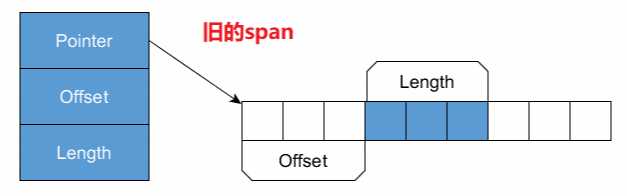
上面的动画非常清楚了吧,旧span整合它的引用和偏移成新的span的引用,整个过程并没有复制内存,而是直接返回引用,因此性能非常高,因为新span获得并更新了引用,所以垃圾回收器(GC)知道如何处理新的span,从而获得了.Net至关重要的安全保障,而这些都是span内部默默完成的,开发人员根本不用担心,非托管世界依然美好。
正是由于span的高性能,目前很多基础设施都开始支持span,甚至使用span进行重构,比如:System.String.Substring方法,我们都知道此方法是非常消耗性能的,首先会创建一个新的字符串,然后在复制原始字符串的字符集给它,而使用span可以实现Non-Allocating、Zero-coping,下面是我做的一个基准测试:
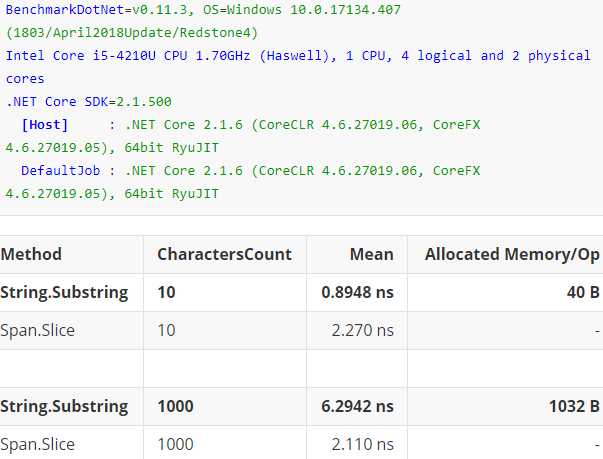
使用String.SubString和Span.Slice分别截取长度为10和1000的字符串前一半,从中指标Mean可以看出方法SubString的耗时随着字符串长度呈线性增长,而Slice几乎保持不变;从指标Allocated Memory/Op可以看出,方法Slice并没有被分配新的内存,实践出真知,可以预见Span未来将会成为.Net下编写高性能应用程序的重要积木,应用前景也会非常地广,微服务、物联网都是它发光发热的好地方。
看完本篇博客,应该对Span的What、Why、How了如指掌了,那么我的目的就达到了,不懂的同学可以多读几遍,下一篇,我将会畅谈Span的应用场景、优缺点,让大家能够安全高效地使用好它,大家也可以在评论留言自己的应用场景,我会在写下一篇博客时多多参考。
如果有什么疑问和见解,欢迎评论区交流。
如果你觉得本篇文章对您有帮助的话,感谢您的【推荐】。
如果你对高性能编程感兴趣的话可以关注我,我会定期的在博客分享我的学习心得。
欢迎转载,请在明显位置给出出处及链接。
https://github.com/dotnet/corefxlab/blob/master/docs/specs/span.md
https://msdn.microsoft.com/en-us/magazine/mt814808
https://github.com/dotnet/BenchmarkDotNet/pull/492
https://github.com/dotnet/coreclr/issues/5851
通俗易懂,C#如何安全、高效地玩转任何种类的内存之Span。
标签:运算 并且 cte finally 重载方法 ping 应用 index github
原文地址:https://www.cnblogs.com/justmine/p/10006621.html