标签:图片 eth blog sources esc def 阿里 its cep
Kubernetes 上部署 efk 日志收集系统环境版本:
OS:CentOS 7.4(1804)
Kubernetes:1.11.3
Elasticsearch:5.4.0
Fuentd-elasticsearch:2.0.2
Kibana:6.4.0
本地镜像仓库:192.168.22.8
NFS-Server:192.168.22.8
部署顺序:
Kibana -> NFS动态存储 -> Elasticsearch -> Fuentd-es ->设置节点label
Kibana初始化要10-15分钟,时间较长,所以先部署
开始部署:
一、部署Kibana
1、使用Deployment方式部署kibana
[root@server efk]# cat kibana-deployment.yaml
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana-logging
template:
metadata:
labels:
k8s-app: kibana-logging
spec:
containers:
- name: kibana-logging
image: 192.168.22.8/kibana:6.4.0 ##此处192.168.22.8改为你自己的仓库,或阿里仓库,删除ip就是走默认配置下载
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch-logging:9200
- name: SERVER_BASEPATH
#value: /api/v1/proxy/namespaces/kube-system/services/kibana-logging
value: /api/v1/namespaces/kube-system/services/kibana-logging/proxy
- name: XPACK_MONITORING_ENABLED
value: "false"
- name: XPACK_SECURITY_ENABLED
value: "false"
ports:
- containerPort: 5601
name: ui
protocol: TCP
[root@server efk]# kubectl create -f kibana-deployment.yaml ##部署kibana
查看是否部署成功
[root@server efk]# kubectl get pod -n kube-system |grep kibana
kibana-logging-69c8b74dc7-m7n84 1/1 Running 0 21m
如果部署失败,则使用以下命令查看错误信息
# kubectl describe pod -n kube-system kibana-logging-69c8b74dc7-m7n84 ##注意最后那一段为kibana的pod,要写你自己的
# kubectl logs -n kube-system kibana-logging-69c8b74dc7-m7n842、部署kibana的service
[root@server efk]# cat kibana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Kibana"
spec:
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana-logging
查看是否部署成功
[root@server efk]# kubectl get service -n kube-system |grep "kibana"
kibana-logging ClusterIP 10.68.251.197 <none> 5601/TCP 26m二、部署NFS动态存储provisioner
1、在192.168.22.8上安装NFS-Server
[root@harbor ~]# yum -y install nfs-server配置nfs
[root@harbor ~]# cat /etc/exports
/share *(rw,sync,insecure,no_subtree_check,no_root_squash)
[root@harbor ~]# mkdir /share启动NFS-Server
[root@harbor ~]# systemctl restart nfs-server查看是否共享成功
[root@harbor ~]# showmount -e 192.168.22.8
Export list for 192.168.22.8:
/share *--------OK nfs-server配置成功
2、在Kubernetes使用nfs部署动态pv provisioner
[root@server efk]# cat nfs-provisioner.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Kibana"
spec:
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana-logging
[root@server efk]#
[root@server efk]#
[root@server efk]# cat nfs-provisioner-01.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: nfs-provisioner-01
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-provisioner-01
template:
metadata:
labels:
app: nfs-provisioner-01
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
#image: quay.io/external_storage/nfs-client-provisioner:latest
image: jmgao1983/nfs-client-provisioner:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
# 此处供应者名字供storageclass调用
value: nfs-provisioner-01
- name: NFS_SERVER
value: 192.168.22.8
- name: NFS_PATH
value: /share
volumes:
- name: nfs-client-root
nfs:
server: 192.168.22.8
path: /share
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-dynamic-class
provisioner: nfs-provisioner-01创建pv
[root@server efk]# kubectl create -f ./nfs-provisioner.yaml 查看是否创建成功
[root@server efk]# kubectl get pod -n kube-system |grep "nfs"
nfs-provisioner-01-65d4f6df88-qq6k9 1/1 Running 0 37m三、部署Elasticsearch
因为search是有数据的所以要按有状态的服务来部署,这里使用上一步仓库的动态存储pv来存储数据
[root@server efk]# cat es-statefulset.yaml
# RBAC authn and authz
apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "services"
- "namespaces"
- "endpoints"
verbs:
- "get"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: kube-system
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: elasticsearch-logging
namespace: kube-system
apiGroup: ""
roleRef:
kind: ClusterRole
name: elasticsearch-logging
apiGroup: ""
---
# Elasticsearch deployment itself
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
version: v6.4.0
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
serviceName: elasticsearch-logging
replicas: 2
selector:
matchLabels:
k8s-app: elasticsearch-logging
version: v6.4.0
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v6.4.0
kubernetes.io/cluster-service: "true"
spec:
serviceAccountName: elasticsearch-logging
containers:
#- image: gcr.io/google-containers/elasticsearch:v5.6.4
#- image: mirrorgooglecontainers/elasticsearch:v5.6.4
- image: 192.168.22.8/efk/elasticsearch:6.4.0
name: elasticsearch-logging
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: elasticsearch-logging
mountPath: /data
env:
- name: "NAMESPACE"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
# Elasticsearch requires vm.max_map_count to be at least 262144.
# If your OS already sets up this number to a higher value, feel free
# to remove this init container.
initContainers:
- image: alpine:3.6
command: ["/sbin/sysctl", "-w", "vm.max_map_count=262144"]
name: elasticsearch-logging-init
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: elasticsearch-logging
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: "nfs-dynamic-class"
resources:
requests:
storage: 5Gi创建elasticsearch应用pod
[root@server efk]# kubectl create -f es-statefulset.yaml 查看是否创建成功
[root@server efk]# kubectl get pod -n kube-system |grep elasticsearch
elasticsearch-logging-0 1/1 Running 0 40m
elasticsearch-logging-1 1/1 Running 0 40m创建service
[root@server efk]# cat es-service.yaml
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Elasticsearch"
spec:
ports:
- port: 9200
protocol: TCP
targetPort: db
# clusterIP: None
selector:
k8s-app: elasticsearch-logging[root@server efk]# kubectl create -f es-service.yaml查看是否创建成功
[root@server efk]# kubectl get service -n kube-system |grep elasticsearch
elasticsearch-logging ClusterIP 10.68.150.151 <none> 9200/TCP 41m三、部署fluentd-es
fluentd 采集规则文件
[root@server efk]# cat fluentd-es-configmap.yaml
kind: ConfigMap
apiVersion: v1
data:
containers.input.conf: |-
<source>
type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag kubernetes.*
read_from_head true
format multi_format
<pattern>
format json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</source>
system.input.conf: |-
<source>
type tail
format /^(?<time>[^ ]* [^ ,]*)[^\[]*\[[^\]]*\]\[(?<severity>[^ \]]*) *\] (?<message>.*)$/
time_format %Y-%m-%d %H:%M:%S
path /var/log/salt/minion
pos_file /var/log/es-salt.pos
tag salt
</source>
# Example:
# Dec 21 23:17:22 gke-foo-1-1-4b5cbd14-node-4eoj startupscript: Finished running startup script /var/run/google.startup.script
<source>
type tail
format syslog
path /var/log/startupscript.log
pos_file /var/log/es-startupscript.log.pos
tag startupscript
</source>
<source>
type tail
format /^time="(?<time>[^)]*)" level=(?<severity>[^ ]*) msg="(?<message>[^"]*)"( err="(?<error>[^"]*)")?( statusCode=($<status_code>\d+))?/
path /var/log/docker.log
pos_file /var/log/es-docker.log.pos
tag docker
</source>
<source>
type tail
# Not parsing this, because it doesn‘t have anything particularly useful to
# parse out of it (like severities).
format none
path /var/log/etcd.log
pos_file /var/log/es-etcd.log.pos
tag etcd
</source>
# Multi-line parsing is required for all the kube logs because very large log
# statements, such as those that include entire object bodies, get split into
# multiple lines by glog.
# Example:
# I0204 07:32:30.020537 3368 server.go:1048] POST /stats/container/: (13.972191ms) 200 [[Go-http-client/1.1] 10.244.1.3:40537]
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/kubelet.log
pos_file /var/log/es-kubelet.log.pos
tag kubelet
</source>
# Example:
# I1118 21:26:53.975789 6 proxier.go:1096] Port "nodePort for kube-system/default-http-backend:http" (:31429/tcp) was open before and is still needed
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/kube-proxy.log
pos_file /var/log/es-kube-proxy.log.pos
tag kube-proxy
</source>
# Example:
# I0204 07:00:19.604280 5 handlers.go:131] GET /api/v1/nodes: (1.624207ms) 200 [[kube-controller-manager/v1.1.3 (linux/amd64) kubernetes/6a81b50] 127.0.0.1:38266]
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/kube-apiserver.log
pos_file /var/log/es-kube-apiserver.log.pos
tag kube-apiserver
</source>
# Example:
# I0204 06:55:31.872680 5 servicecontroller.go:277] LB already exists and doesn‘t need update for service kube-system/kube-ui
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/kube-controller-manager.log
pos_file /var/log/es-kube-controller-manager.log.pos
tag kube-controller-manager
</source>
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/kube-scheduler.log
pos_file /var/log/es-kube-scheduler.log.pos
tag kube-scheduler
</source>
# Example:
# I1104 10:36:20.242766 5 rescheduler.go:73] Running Rescheduler
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/rescheduler.log
pos_file /var/log/es-rescheduler.log.pos
tag rescheduler
</source>
# Example:
# I0603 15:31:05.793605 6 cluster_manager.go:230] Reading config from path /etc/gce.conf
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/glbc.log
pos_file /var/log/es-glbc.log.pos
tag glbc
</source>
# Example:
# I0603 15:31:05.793605 6 cluster_manager.go:230] Reading config from path /etc/gce.conf
<source>
type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
time_format %m%d %H:%M:%S.%N
path /var/log/cluster-autoscaler.log
pos_file /var/log/es-cluster-autoscaler.log.pos
tag cluster-autoscaler
</source>
# Logs from systemd-journal for interesting services.
<source>
type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
pos_file /var/log/gcp-journald-docker.pos
read_from_head true
tag docker
</source>
<source>
type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
pos_file /var/log/gcp-journald-kubelet.pos
read_from_head true
tag kubelet
</source>
<source>
type systemd
filters [{ "_SYSTEMD_UNIT": "node-problem-detector.service" }]
pos_file /var/log/gcp-journald-node-problem-detector.pos
read_from_head true
tag node-problem-detector
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
type forward
</source>
monitoring.conf: |-
# Prometheus Exporter Plugin
# input plugin that exports metrics
<source>
@type prometheus
</source>
<source>
@type monitor_agent
</source>
# input plugin that collects metrics from MonitorAgent
<source>
@type prometheus_monitor
<labels>
host ${hostname}
</labels>
</source>
# input plugin that collects metrics for output plugin
<source>
@type prometheus_output_monitor
<labels>
host ${hostname}
</labels>
</source>
# input plugin that collects metrics for in_tail plugin
<source>
@type prometheus_tail_monitor
<labels>
host ${hostname}
</labels>
</source>
output.conf: |-
<filter kubernetes.**>
type kubernetes_metadata
</filter>
<match **>
type elasticsearch
log_level info
include_tag_key true
host elasticsearch-logging
port 9200
logstash_format true
buffer_chunk_limit 2M
buffer_queue_limit 8
flush_interval 5s
max_retry_wait 30
disable_retry_limit
num_threads 2
</match>
metadata:
name: fluentd-es-config-v0.1.1
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcilefluentd-es.yaml
[root@server efk]# cat fluentd-es-ds.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: kube-system
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: kube-system
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: fluentd-es-v2.0.2
namespace: kube-system
labels:
k8s-app: fluentd-es
version: v2.0.2
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.2
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.2
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ‘‘
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
#image: gcr.io/google-containers/fluentd-elasticsearch:v2.0.2
#image: mirrorgooglecontainers/fluentd-elasticsearch:v2.0.2
image: 192.168.22.8/efk/fluentd-elasticsearch:v2.0.2
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: libsystemddir
mountPath: /host/lib
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
# It is needed to copy systemd library to decompress journals
- name: libsystemddir
hostPath:
path: /usr/lib64
- name: config-volume
configMap:
name: fluentd-es-config-v0.1.1创建fluentd POD
[root@server efk]# kubectl create -f ./fluentd-es-configmap.yaml fluentd-es-ds.yaml 注意:Fluentd 是以 DaemonSet 形式运行且只会调度到有beta.kubernetes.io/fluentd-ds-ready=true标签的节点,所以对需要收集日志的节点逐个打上标签:
[root@server efk]# kubectl label nodes 192.168.22.12 beta.kubernetes.io/fluentd-ds-ready=true
node "192.168.22.12" labeled查看是否创建成功
[root@server efk]# kubectl get pod -n kube-system |grep fluentd
fluentd-es-v2.0.2-9ttr5 1/1 Running 0 23h
fluentd-es-v2.0.2-fsdwp 1/1 Running 0 23h
fluentd-es-v2.0.2-k9ghs 1/1 Running 0 23h四、访问 kibana
因kibana启动需要很长时间 ,必须要看到kibana的日志里显示 启动成功 ,方可访问
kubectl logs -n kube-system kibana-logging-69c8b74dc7-m7n84 -f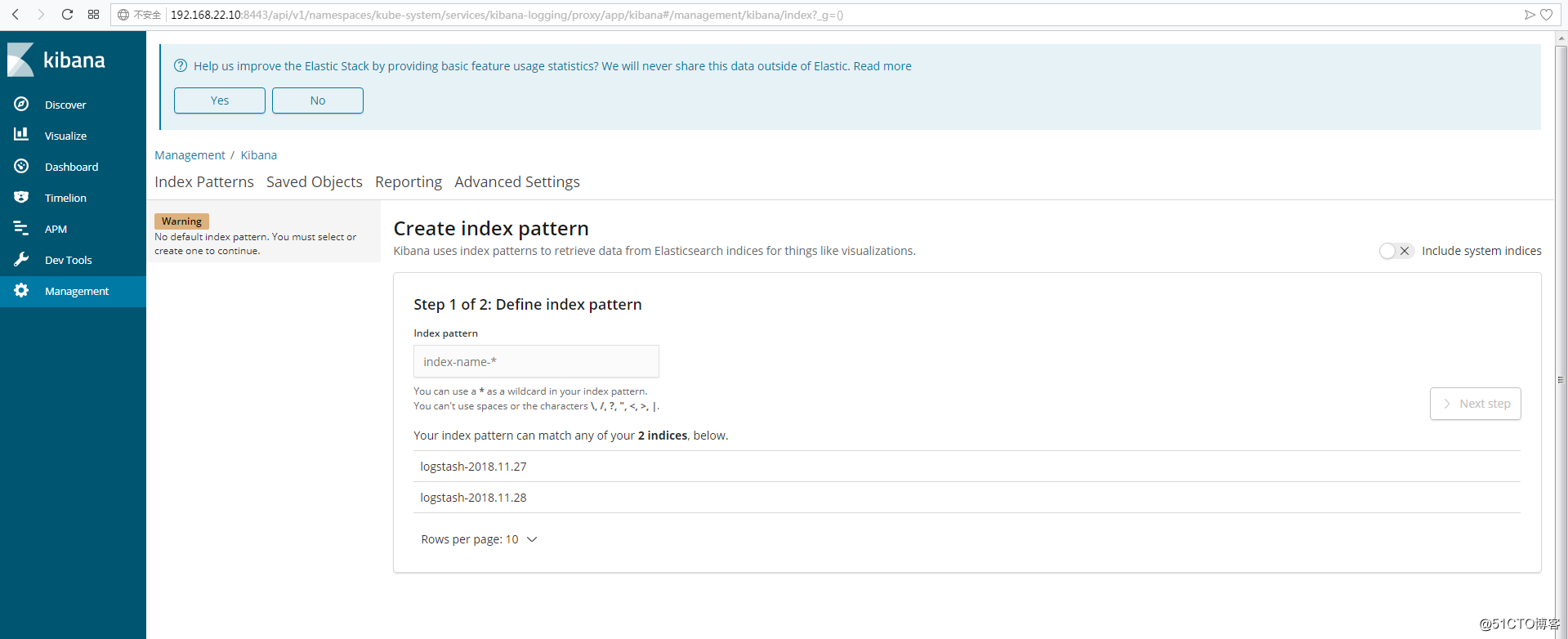
Kubernetes 1.11.3上使用动态PV部署EFK 6.4.0
标签:图片 eth blog sources esc def 阿里 its cep
原文地址:http://blog.51cto.com/passed/2323139