标签:html 分享 现在 9.png .sh 知识 形式 color 查看
1、爬取网站美图爬取图片是最常见的爬虫入门项目,不复杂却能很好地熟悉Python语法、掌握爬虫思路。
加python学习交流qun 784758214 各种Python新手项目资料包免费领取,不定时还有web、爬虫等技术的免费知识分享直播教学
当然有两个点要注意:
不要侵犯版权,
要注意营养。
思路流程
第一步:获取网址的response,分页内容,解析后提取图集的地址。
第二步:获取网址的response,图集分页,解析后提取图片的下载地址。
第三步:下载图片(也就是获取二进制内容,然后在本地复刻一份)。
部分代码
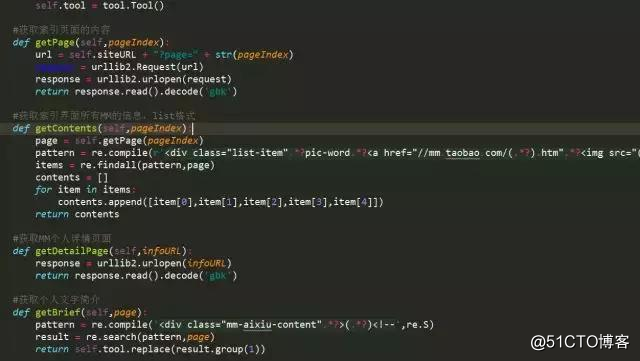
运行结果
爬取王者荣耀全套皮肤
怎么获取全套皮肤?用钱买,或者用爬虫爬取下来~虽然后者不能穿。这个案例稍微复杂一点,但是一个非常值得学习的项目。
思路流程
首先进入所有英雄列表,你会看到下图
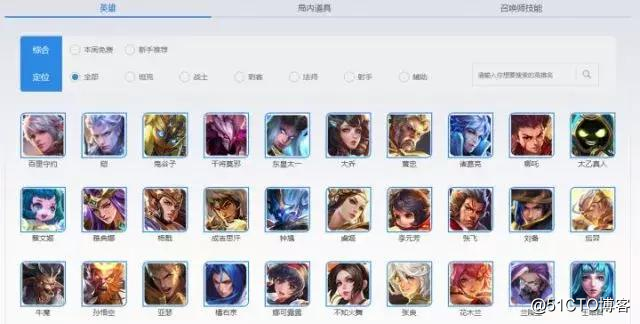
在这个网页中包含了所有的英雄名称。点击其中一个英雄例如“百里守约”,进去后如下图:

网址中196.shtml以前的字符都是不变的,变化的只是196.shtml。而196是“百里守约”所对应的数字,要想爬取图片就应该进入每个英雄图片所在的网址,而网址的关键就是对应的数字。那么这些数字怎么找呢?
在所有英雄列表中,打开浏览器的开发者工具,刷新,找到一个json格式的文件,如图所示:
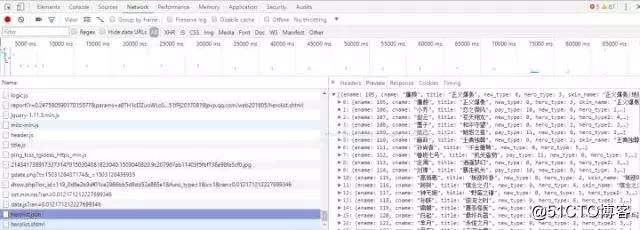
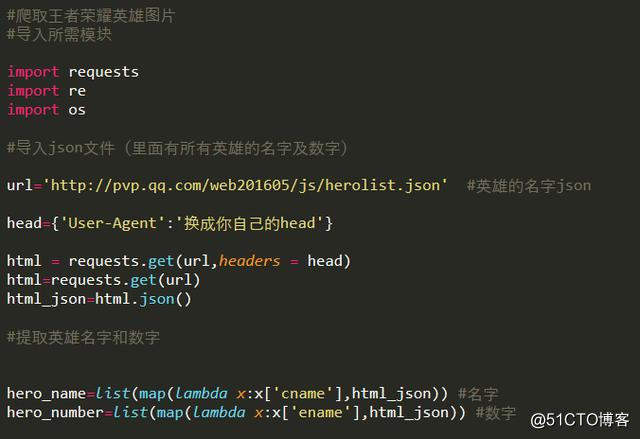
这时就会看到所有英雄对应的数字了。在上图所示的Headers中可以找到该json文件对应的网址形式。将其导入Python,把这些数字提取出来,然后模拟出所有英雄的网址即可
小节代码:
下载图片
现在可以进入所有英雄的网址并爬取网址下的图片了。进入一个英雄的网址,打开开发者工具,在NetWork下刷新并找到英雄的皮肤图片。如图所示:
然后在Headers中查看该图片的网址。会发现皮肤图片是有规律的。我们可以用这样的方式来模拟图片网址

在该网址中只有str(v)与str(u)是改变的(str( )是Python中的一个函数),str(v)是英雄对应的数字,str(u)只是图片编号,例如第一个图片就是1,第二个就是2,第三个……而一个英雄的皮肤应该不会超过12个(可以将这个值调到20等)。接着就是下载了。
爬取下来的图片是这样,每个文件夹里面是该英雄对应的图片,如下图:
人生苦短,Python当歌!学习,其实是一个坚持、分享、交流、提高的过程。学会交流,不懂就问,与更多优秀的人一起成长,学习效果也会更加显著。
加python学习交流qun 784758214 各种Python新手项目资料包免费领取,不定时还有web、爬虫等技术的免费知识分享直播教学
标签:html 分享 现在 9.png .sh 知识 形式 color 查看
原文地址:http://blog.51cto.com/14082686/2324724
{kind=link}