标签:硬盘 数据库 info 没有 tps 方式 出现 登陆 不同的应用
在说分库分表之前,先简单介绍下网站架构,这样有助于理解为何需要分库分表这种技术。因为所有的技术,大多都是因为业务的需要而产生的.
1、网站发展的第一阶段
大致架构如下,因为没有多少用户访问,所以单台服务器都搞定所有的事情,上面跑着数据库、资源站点、以及所有的业务站点.
2、网站发展的第二阶段
这个时候访问量开始增加,发现服务器的资源不够用了,用户体验越来越差,所以,第一想法,升级服务器配置.ok,暂时解决了问题,站点又能提供稳定且高效的服务.
3、网站发展的第三阶段
访问量持续增加,这个时候升级服务器的配置所产生的代价太大,而且,就算继续升级也无法解决本质的问题,所以开始考虑其它的方案!
很简单,将业务和数据分离,将业务站点和数据库和资源站点分开,如下架构:
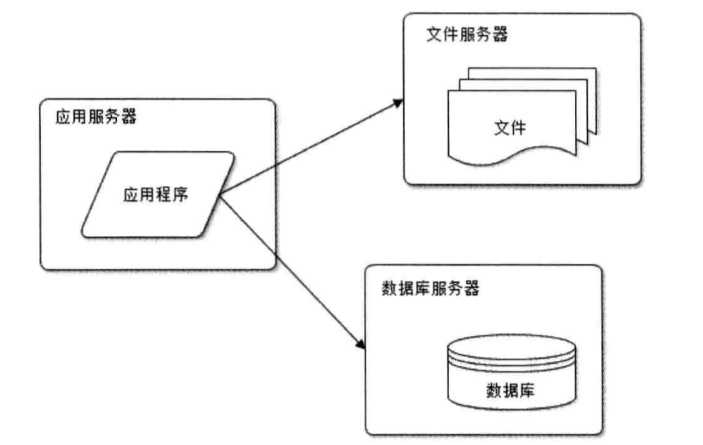
这里需要注意:业务站点需要处理大量的业务逻辑,所以CPU的性能一定要高,文件服务器则需要大一点的硬盘,数据库服务器则需要更快的硬盘和更大的内存.
ok,问题又解决了,站点又能提供稳定且高效的服务.
4、网站发展的第四阶段
访问量持续增加,单台应用服务器的IIS线程并发连接有限,而且随着用户的上升开始出现超时,异常,直至站点崩溃.所以必须解决这个问题.
ok,增加应用服务器,实现小集群(每次加一台),上nginx(关于nginx不了解请参考Nginx),做反向代理,分发用户的请求到不同的应用服务器,如果涉及登陆做下Ip_Hash.
ok,问题又解决了,站点又能提供稳定且高效的服务.
5、网站发展的第五阶段
访问量持续增加,应用服务器也越来越多,数据库的压力越来越大,而且数据随着用户的上升爆发时的增加,数据库面临了性能瓶颈,因为单表数据的上升,所以必须分表,提升查询的速度.所以必须开始动数据库了.
第一步:实现数据库的读写分离,主要是配置,网商有很多文章,自行参考
第二步:分库分表,终于引出来了,哈哈
6、关于分库分表常用的设计思路
按时间、按地区(IP)、按业务进行划分,无外乎这三种方式.下面简单的介绍个例子,假设站点是个登陆站点,主要分为QQ登陆和微信登陆,站点需要记录每次用户的登陆的一些信息.
假设每天有10万用户登陆.做过单表10万数据查询的知道,不加索引的情况下,还是有点慢的.所以我们需要对这个登陆记录表进行拆分.第一步按QQ登陆和微信登陆进行分库,将通过QQ登陆的用户登陆信息存储到QQ登陆库,微信同理,这样每个库每天承担5万的写操作.
但是单表5万记录查询还是有点慢,这个时候还可以进行细分,比如按用户Id,进行拆封按用户Id拆分一般有两种(用户Id算法):
(1)、如果Id是int整数(如SqlServer的自增Id),可以采用Id%10取余算法,找到目标表。采用这种算法,那么原先的单表被拆封成0~9十个表,每个表承担5000的写操作,这样压力瞬间就下来了
(2)、如果Id是Guid(长度固定,全大写),获取最后1个字母,找到目标表,采用这种算法,那么原先的单表被拆封成A-Z36个表,每个表承担写压力就更小了.
上面两个都可取,但是可以根据具体的业务酌情选择.
目前为止,解决了单天的性能瓶颈,但是每天都有10万数据进来,肯定是不行的,所以按照上面的思路每天的数据必须在当前被清空,因为不清空,随着数据每天加10000万的操作,查询到最后还是受不了.
所以必须写个定时服务,每天在业务低峰期清除QQ登陆信息库和微信登陆信息库的数据,清楚的同时将它们迁移到对应QQ登陆信息历史库和微信登陆历史库中,关于历史库的构建就需要仔细考虑了.
考虑了几种方案:
(1)、就两个历史库(微信登陆历史库和QQ登陆历史库),直接Pass,每天10万数据的递增,不用一年就直接崩了.
(2)、按年分库 月+日+用户Id 进行分表 直接Pass,这个方案会产生大概3600个表
(3)、权衡考虑采用按年分库 月+用户Id 进行分表 如果用户Id采用用户Id算法的第一种,那么会产生大概120个表.
确定好历史库设计方案之后,将每天的登陆信息记录同步到对应的历史库中.
标签:硬盘 数据库 info 没有 tps 方式 出现 登陆 不同的应用
原文地址:https://www.cnblogs.com/GreenLeaves/p/10053935.html