标签:com http 注释 test creat name .sql 意思 object
JDBC在我们学习J2EE的时候已经接触到了,但是仅是照搬步骤书写,其中的PreparedStatement防sql注入原理也是一知半解,然后就想回头查资料及敲测试代码探索一下。再有就是我们在项目中有一些配置项是有时候要变动的,比如数据库的数据源,为了在修改配置时不改动编译的代码,我们把要变动的属性提取到一个配置文件中,比如properties,因为properties里面都是键值对的形式,所以非常便于阅读和维护。
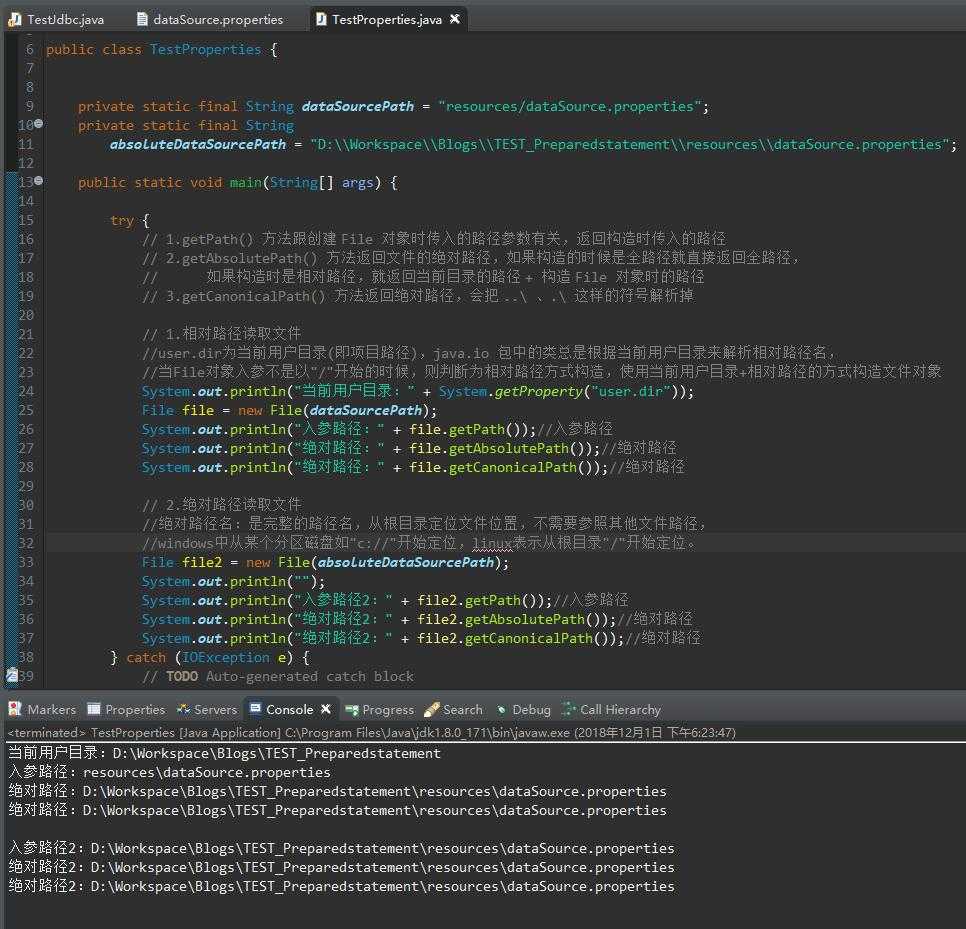
package com.test.properties; import java.io.File; import java.io.IOException; public class TestProperties { private static final String dataSourcePath = "resources/dataSource.properties"; private static final String absoluteDataSourcePath = "D:\\Workspace\\Blogs\\TEST_Preparedstatement\\resources\\dataSource.properties"; public static void main(String[] args) { try { // 1.getPath() 方法跟创建 File 对象时传入的路径参数有关,返回构造时传入的路径 // 2.getAbsolutePath() 方法返回文件的绝对路径,如果构造的时候是全路径就直接返回全路径, // 如果构造时是相对路径,就返回当前目录的路径 + 构造 File 对象时的路径 // 3.getCanonicalPath() 方法返回绝对路径,会把 ..\ 、.\ 这样的符号解析掉 // 1.相对路径读取文件 //user.dir为当前用户目录(即项目路径),java.io 包中的类总是根据当前用户目录来解析相对路径名, //当File对象入参不是以"/"开始的时候,则判断为相对路径方式构造,使用当前用户目录+相对路径的方式构造文件对象 System.out.println("当前用户目录:" + System.getProperty("user.dir")); File file = new File(dataSourcePath); System.out.println("入参路径:" + file.getPath());//入参路径 System.out.println("绝对路径:" + file.getAbsolutePath());//绝对路径 System.out.println("绝对路径:" + file.getCanonicalPath());//绝对路径 // 2.绝对路径读取文件 //绝对路径名:是完整的路径名,从根目录定位文件位置,不需要参照其他文件路径, //windows中从某个分区磁盘如"c://"开始定位,linux表示从根目录"/"开始定位。 File file2 = new File(absoluteDataSourcePath); System.out.println(""); System.out.println("入参路径2:" + file2.getPath());//入参路径 System.out.println("绝对路径2:" + file2.getAbsolutePath());//绝对路径 System.out.println("绝对路径2:" + file2.getCanonicalPath());//绝对路径 } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
下面截图是控制台输出的结果:对应的解释我都写在代码的注释里了。
搞清楚了绝对路径和相对路径,我们就可以借助java.util包中的Properties来读取项目中的配置文件了,下面是常用的三种方法:
1.其中第一种方法在上面的相对路径读取文件中也讲了,这里使用相对路径,java.io解析时会自动加上项目路径,也就是说等于是绝对路径,这里也可以使用绝对路径,但项目不推荐这样做是因为指定死了盘符,项目移动别的系统平台时就要改动。
2.第2、3种方法大同小异,就是要注意下class时使用加”/”是classes根目录下,所以要加”/”,而getClassLoader时直接是获得的classPath,所以不需要加根目录”/”
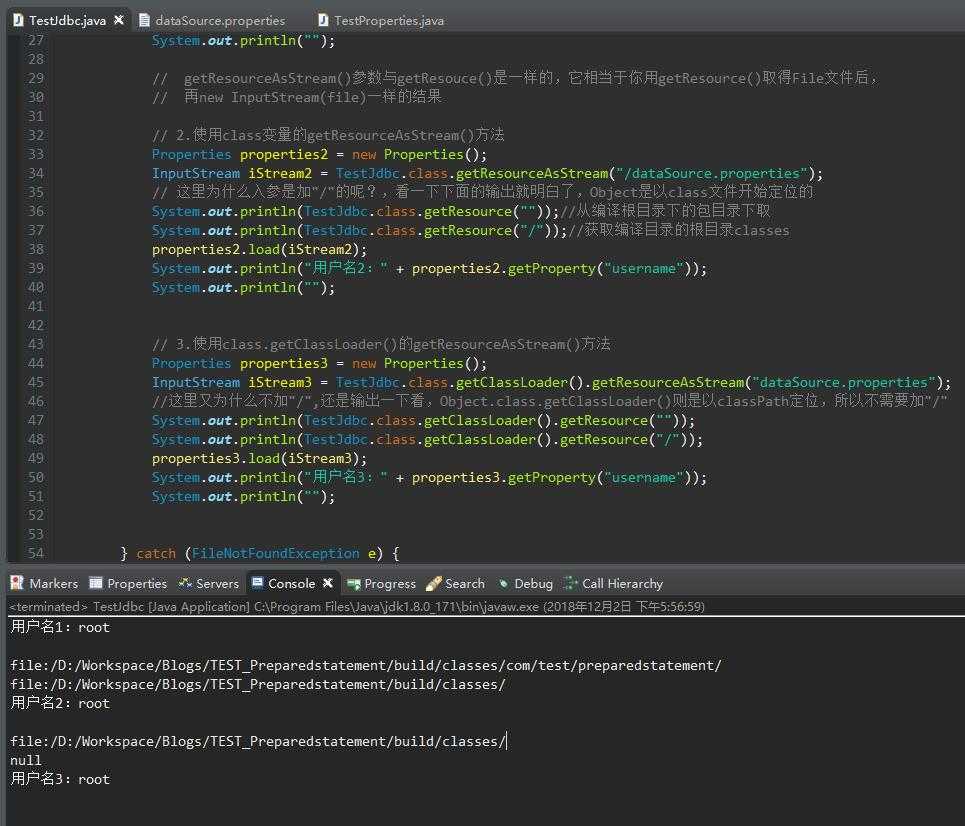
package com.test.preparedstatement; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.util.Properties; public class TestJdbc { private static final String dataSourcePath = "resources/dataSource.properties"; public static void getPathByJavaUtilProperties() { try { // 1.使用java.util.Properties类的load(InputStream in)方法加载properties文件 InputStream iStream = new BufferedInputStream(new FileInputStream(new File(dataSourcePath))); Properties properties = new Properties(); properties.load(iStream); System.out.println("用户名1:" + properties.getProperty("username")); System.out.println(""); // getResourceAsStream()参数与getResouce()是一样的,它相当于你用getResource()取得File文件后, // 再new InputStream(file)一样的结果 // 2.使用class变量的getResourceAsStream()方法 Properties properties2 = new Properties(); InputStream iStream2 = TestJdbc.class.getResourceAsStream("/dataSource.properties"); // 这里为什么入参是加"/"的呢?,看一下下面的输出就明白了,Object是以class文件开始定位的 System.out.println(TestJdbc.class.getResource(""));//从编译根目录下的包目录下取 System.out.println(TestJdbc.class.getResource("/"));//获取编译目录的根目录classes properties2.load(iStream2); System.out.println("用户名2:" + properties2.getProperty("username")); System.out.println(""); // 3.使用class.getClassLoader()的getResourceAsStream()方法 Properties properties3 = new Properties(); InputStream iStream3 = TestJdbc.class.getClassLoader().getResourceAsStream("dataSource.properties"); //这里又为什么不加"/",还是输出一下看,Object.class.getClassLoader()则是以classPath定位,所以不需要加"/" System.out.println(TestJdbc.class.getClassLoader().getResource("")); System.out.println(TestJdbc.class.getClassLoader().getResource("/")); properties3.load(iStream3); System.out.println("用户名3:" + properties3.getProperty("username")); System.out.println(""); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) { TestJdbc.getPathByJavaUtilProperties(); // TestJdbc.getDataBaseData(); } }
下面是输出结果,这里要注意TestJdbc.class.getClassLoader().getResource("/")是null
加载好配置文件后,我来测试一下jdbc连接mysql数据库时,批量插入数据使用statement和preparedStatement效率,不多比比,代码来说话:
package com.test.preparedstatement; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; import java.sql.Statement; import java.util.Properties; public class TestJdbc { private static final String dataSourcePath = "resources/dataSource.properties"; public static void getDataBaseData() { try { InputStream iStream = new BufferedInputStream(new FileInputStream(new File(dataSourcePath))); Properties properties = new Properties(); properties.load(iStream); String username = properties.getProperty("username"); String password = properties.getProperty("password"); String driver = properties.getProperty("driver"); String url = properties.getProperty("url"); // 1.statement方式 long start = System.currentTimeMillis(); //加载驱动 Class.forName(driver); //建立连接 Connection connection = DriverManager.getConnection(url, username, password); //创建statement Statement statement = connection.createStatement(); for (int i = 0; i < 50; i++) { statement.execute("insert into test values("+i+",‘a"+i+"‘)"); } statement.close(); connection.close(); System.out.println("statment花费时间:"+String.valueOf(System.currentTimeMillis()-start)); // 2.preparedStatement方式 long start2 = System.currentTimeMillis(); //加载驱动 Class.forName(driver); //建立连接 Connection connection2 = DriverManager.getConnection(url, username, password); //创建preparedStatement PreparedStatement preparedStatement = connection2.prepareStatement("insert into test values(?,?)"); for (int j = 50; j < 100; j++) { preparedStatement.setInt(1, j); preparedStatement.setString(2, "b"+j); preparedStatement.execute(); } preparedStatement.close(); connection2.close(); System.out.println("preparedStatement花费时间:"+String.valueOf(System.currentTimeMillis()-start2)); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } public static void main(String[] args) { TestJdbc.getDataBaseData(); } }
数据库数据插入了100条数据,执行成功:
然后看看控制台执行时间比较:
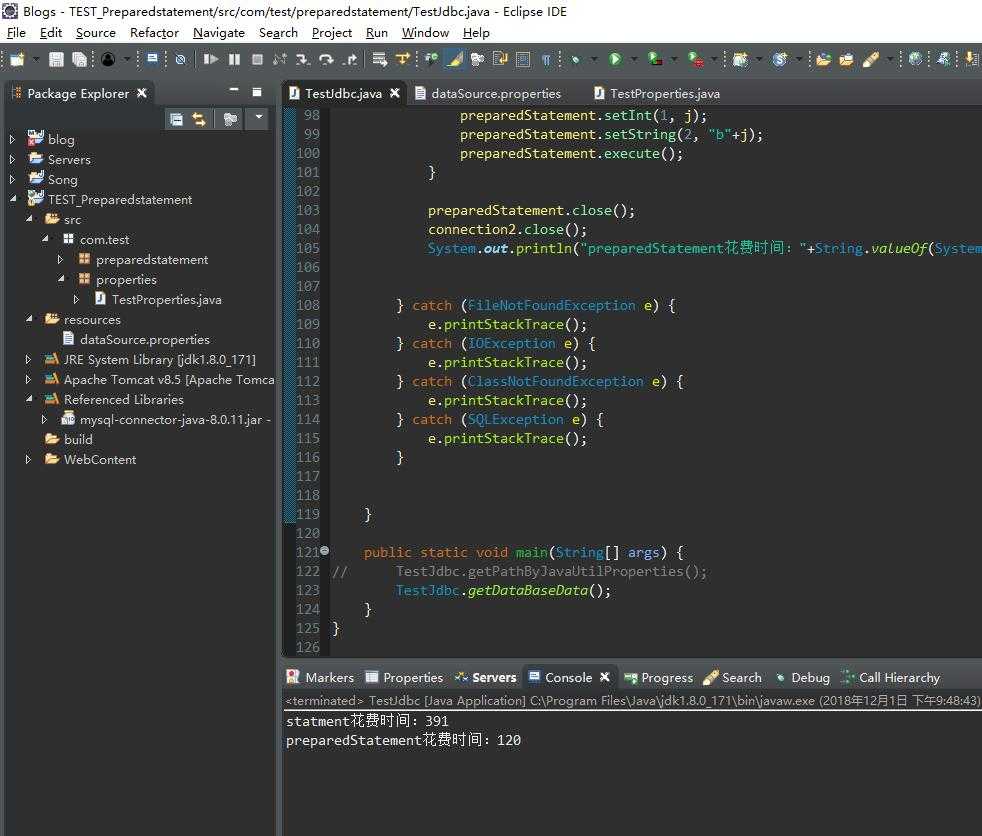
可以看到statement执行时间是preparedstatement执行时间的3倍,在批量处理上,preparedstatement效率更高。
prepared是准备的意思,也就是mysql的预编译在起作用。
1.使用statement时,每次执行sql,statement都会直接把sql扔给数据库执行,而且每次执行都要经过编译sql,执行sql,获得结果的过程,50次操作,50次编译。
2.preparedstatement不同的是在创建preparedstatement对象时就把sql语句结构输入进去了,并把这个sql预编译成函数并保存起来,然后加载参数,执行sql,返回结果。当批量处理时,后面49个处理都是使用这个函数,因为sql结构没变,所以不用二次编译,直接赋值,执行。
3.PreparedStatement继承自Statement,可以说对statement做了优化
4.下面这句是网上说的,具体我没测过:JDBC驱动程序5.0.5以后版本 默认预编译都是关闭的。jdbc:mysql://localhost:3306/mybatis?&useServerPrepStmts=true&cachePrepStmts=tru在MySQL中,既要开启预编译也要开启缓存。因为如果只是开启预编译的话效率还没有不开启预编译效率高。
5.因为preparedstatement使用?作占位符,所以就算恶意的sql进入到后台,在preparedStatement.execute();之前已经对sql做了预编译,就是说sql的执行函数已经确定,所以不会再破坏sql的结构。所以可以防止sql注入。
回头探索JDBC及PreparedStatement防SQL注入原理
标签:com http 注释 test creat name .sql 意思 object
原文地址:https://www.cnblogs.com/songzhen/p/J2EE-JDBC-001.html