标签:log 包括 exce 用户名 新浪微博 步骤 手机 http ref
新浪微博作为新时代火爆的新媒体社交平台,拥有许多用户行为及商户数据,因此需要研究人员都想要得到新浪微博数据,But新浪微博数据量极大,获取的最好方法无疑就是使用Python爬虫来得到。网上有一些关于使用Python爬虫来爬取新浪微博数据的教程,但是完整的介绍以及爬取用户所有数据信息比较少,因此这里分享一篇主要通过selenium包来爬取新浪微博用户数据的文章。目标
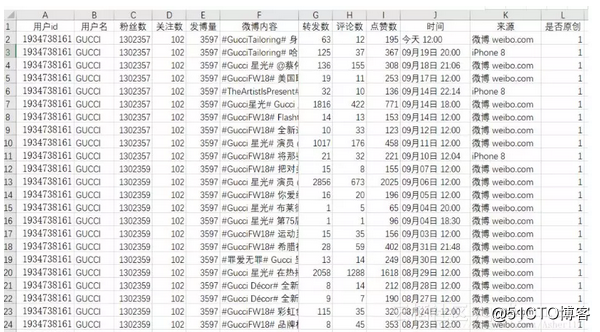
爬取新浪微博用户数据,包括以下字段:id,昵称,粉丝数,关注数,微博数,每一篇微博的内容,转发数,评论数,点赞数,发布时间,来源,以及是原创还是转发。(本文以GUCCI(古驰)为例)
方法
+使用selenium模拟爬虫
+使用BeautifulSoup解析HTML
结果展示
步骤分解
1.选取爬取目标网址
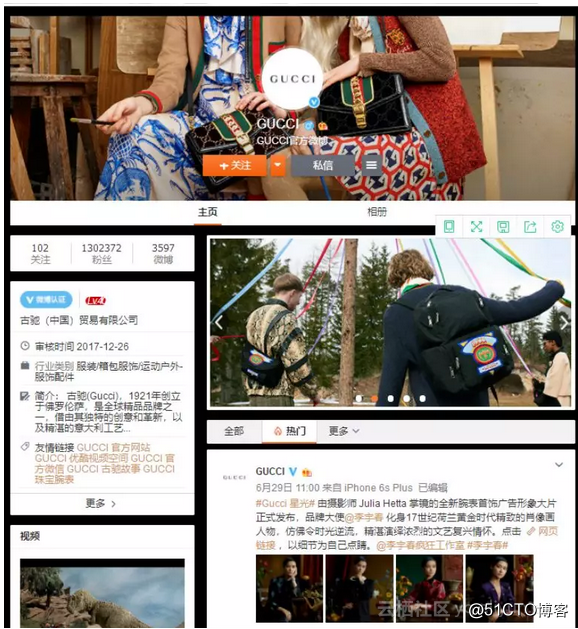
首先,在准备开始爬虫之前,得想好要爬取哪个网址。新浪微博的网址分为网页端和手机端两个,大部分爬取微博数据都会选择爬取手机端,因为对比起来,手机端基本上包括了所有你要的数据,并且手机端相对于PC端是轻量级的。
下面是GUCCI的手机端和PC端的网页展示。
2.模拟登陆
定好爬取微博手机端数据之后,接下来就该模拟登陆了。
模拟登陆的网址
登陆的网页下面的样子
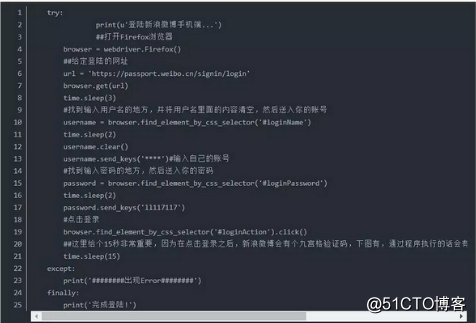
模拟登陆代码
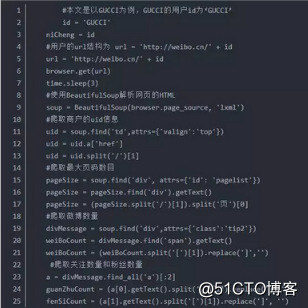
3.获取用户微博页码
在登录之后可以进入想要爬取的商户信息,因为每个商户的微博量不一样,因此对应的微博页码也不一样,这里首先将商户的微博页码爬下来。与此同时,将那些公用信息爬取下来,比如用户uid,用户名称,微博数量,关注人数,粉丝数目。
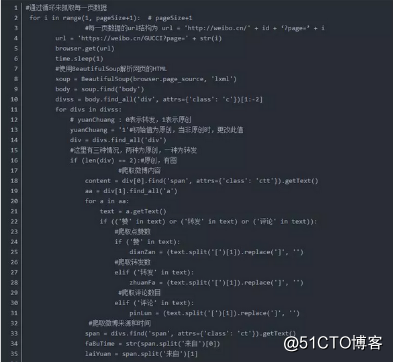
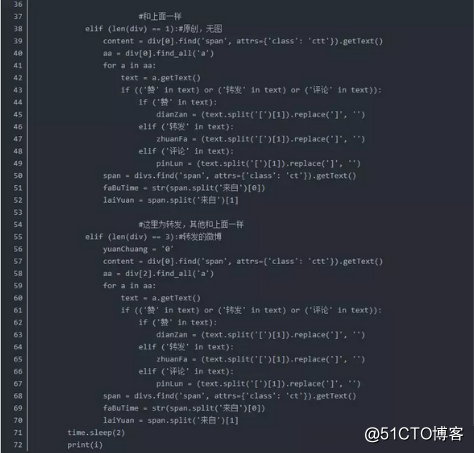
4.根据爬取的最大页码,循环爬取所有数据
在得到最大页码之后,直接通过循环来爬取每一页数据。抓取的数据包括,微博内容,转发数量,评论数量,点赞数量,发微博的时间,微博来源,以及是原创还是转发。
4.在得到所有数据之后,可以写到csv文件,或者excel,最后的结果显示在上面展示
文章到这里完整的微博爬虫就解决啦!
最后,如果有想一起学习python,爬虫,可以来一下我的python学习裙【 784758214 】,内有安装
包和学习视频资料免费分享,好友都会在里面交流,分享一些学习的方法和需要注意的小细节,每天
也会准时的讲一些项目实战案例。
点击:加入
标签:log 包括 exce 用户名 新浪微博 步骤 手机 http ref
原文地址:http://blog.51cto.com/14082686/2325401