标签:ima 动态 rate png src 别人 图的定义 rest sel
一、视图
视图就是通过查询得到一张虚拟表,然后保存下来,下次用的直接使用即可。使用视图我们可以把查询过程中的临时表摘出来,用视图去实现,这样以后再想操作该临时表的数据时就无需重写复杂的 SQL 语句了,直接去视图中查找即可,但视图有明显地效率问题,并且视图是存放在数据库中的,如果我们程序中使用的 SQL 过分依赖数据库中的视图,即强耦合,那就意味着扩展 SQL 极为不便,因此并不推荐使用。
-- 1.
-- 视图是一个虚拟表(非正式存在),其本质是其本质是
-- 【根据SQL语句获取动态的数据集,并为其命名】,
-- 用户使用时只需使用【名称】即可获取结果集,
-- 可以将该结果集当做表来使用。
-- 2.
-- 有了视图以后你是不是觉得写SQL语句就很简单了,但是你尽量不要这样做
-- 因为MySQL是DBA管着呢,那么你告诉DBA建一堆视图,你写程序的时候是方便了,
-- 但是你要是修改呢,那么你就得修改视图了,你就得找到DBA修改你的视图了,
-- 那么这样联系别人会很麻烦的。说不定人家还很忙呢。还是推荐自己去写SQL语句。
-- 注意:
-- 如果是一个单表的就可以修改或者删除或者插入
-- 如果是几个表关联的时候是不可以修改或者删除或者插入的(这点也是不确定的,有的可以改,有的不可以改)
强调:
1、在硬盘中,视图只有表结构文件,没有表数据文件
2、视图通常是用于查询,尽量不要修改视图中的数据
1、创建视图
创建视图需要具有 create view 的权限,同时应该具有查询涉及列的 select 权限。
语法格式:
create [algorithm = {undefined | merge | temptable}]
view 视图名 [(视图列表)]
as 查询语句
[with [cascaded | local] check option]
【例1】下面在 student 表上创建一个简单的视图,视图名为 student_view1

【例2】下面在 student 表上创建一个名为 student_view2 的视图,包含学生的姓名、课程名以及对应的成绩。

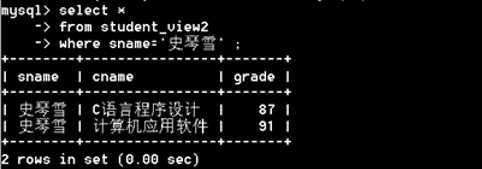
【例3】当我们在查询史琴雪的所有已修课程的成绩时,就可以借助视图很方便地完成查询。

创建视图时要注意以下几点:
1、运行创建视图的语句需要用户具有创建视图(crate view)的权限。
2、select 语句不能包含 from 子句中的子查询。
3、select 语句不能引用系统或用户变量。
4、select 语句不能引用预处理语句参数。
5、在存储子程序内,定义不能引用子程序参数或局部变量。
6、在定义中引用的表或视图必须存在。
7、在定义中不能引用 temporary 表,不能创建 temporary 视图。
8、在视图定义中命名的表必须已存在。
9、不能将触发程序与视图关联在一起。
10、在视图定义中允许使用 order by。
2、删除视图
删除视图时,只能删除视图的定义,不会删除数据。其次用户必须拥有 drop 权限。
语法格式:
drop view [if exists]
view_name[, view_name2]…
restrict | cascade]
【例4】下面将删除视图 student_view1

3、查看视图定义
查看视图是指查看数据库中已存在的视图的定义。查看视图必须要有 show view 的权限。
查看视图的方法包括以下几条语句,它们从不同的角度显示视图的相关信息
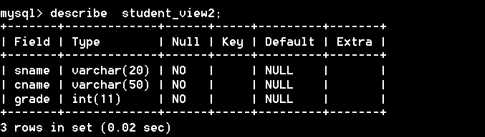
1)describe 语句,语法格式:describe 视图名称; 或者 desc 视图名称;
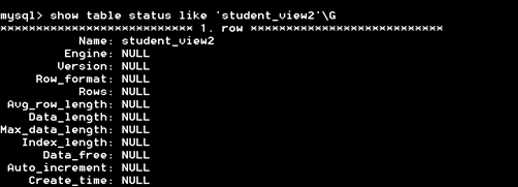
2)show table status 语句,语法格式: show table status like ‘视图名‘
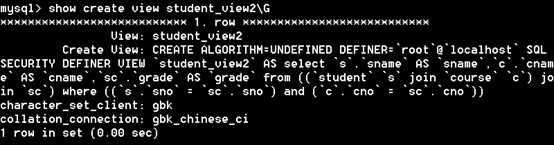
3)show create view 语句,语法格式:show create view ‘视图名‘
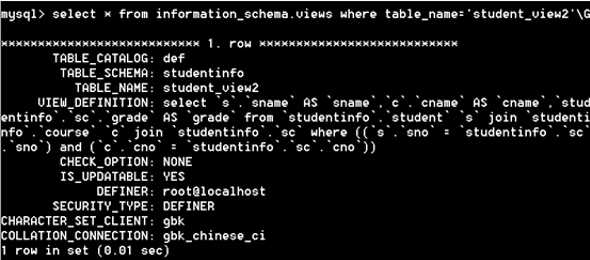
4)查询 information_schem 数据库下的 views 表
语法格式:select * from information_schema.views where table_name = ‘视图名‘
【例5】查看 student_view2 视图信息
方式一:describe
方式二:show table status
方式三:show create view
方式四:information_schema.views
4、修改视图定义
修改视图是指修改数据库中已经存在表的定义
(1)create or replace view 语句格式
create or replace [algorithm = {undefined | merge | temptable}]
view 视图名[ { 属性清单 } ]
as select 语句
[ with [ cascaded | local ] check option];
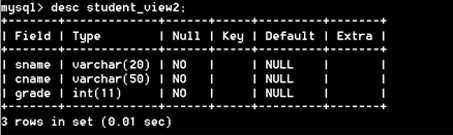
【例6】修改视图 student_view2 的列名为姓名、选修课、成绩

(2)alter 语句格式
create or replace [algorithm = {undefined | merge | temptable}]
view 视图名[ { 属性清单 } ]
as select 语句
[ with [ cascaded | local ] check option];
【例7】把 student_view2 列的名称再改为 sname,cname,grade
5、更新视图数据
原则:尽量不要更新视图
对视图的更新其实就是对表的更新,更新视图是指通过视图来插入(insert)、更新(update)和删除(delete)表中的数据。
通过视图更新时,都是转换到基本表来更新。更新视图时,只能更新权限范围内的数据。
【例8】通过视图对 student 表进行更新

二、触发器
1、概念
触发器是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,它比数据库本身标准的功能有更精细和更复杂的数据控制能力。
2、创建使用触发器
触发程序是与表有关的命名数据库对象,当表上出现特定事件时,将激活该对象。
语法格式:
# 针对插入, 在插入一条记录之后会自动触发一个触发器的执行
create trigger tri_after_insert_t1 after insert on 表名 for each row
begin
sql代码。。。
end
create trigger tri_after_insert_t2 before insert on 表名 for each row
begin
sql代码。。。
end
==================================================
# 针对删除
create trigger tri_after_delete_t1 after delete on 表名 for each row
begin
sql代码。。。
end
create trigger tri_after_delete_t2 before delete on 表名 for each row
begin
sql代码。。。
end
==================================================
# 针对修改
create trigger tri_after_update_t1 after update on 表名 for each row
begin
sql代码。。。
end
create trigger tri_after_update_t2 before update on 表名 for each row
begin
sql代码。。。
end
案例:
# 准备表
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, # 提交时间
success enum (‘yes‘, ‘no‘) # 0代表执行失败
);
CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
);
==============================================
delimiter $$
create trigger tri_after_insert cmd after insert on cmd for each now
begin
if NEW.success = ‘no‘ then
insert into errlog(err_cmd, err_time) values (NEW.cmd, NEW.sub_time);
end if;
end $$
delimiter ;
-- delimiter 是用来改变SQL语句的结束,因为一条SQL语句的结束标志是分号,在创建触发器写SQL代码时,一条判断语句的结束是用分号,但MySQL会把它当作是整个SQL语句的结束,所以会报错
三、存储过程与函数
1、概念
一个存储过程是一个可编程的函数,它在数据库中创建并保存。它可以有 SQL 语句和一些特殊的控制结构组成。
存储过程优点:
存储过程增强了 SQL 语言的功能和灵活性
存储过程允许标准组件是编程
存储过程能实现较快的执行速度
存储过程能过减少网络流量
存储过程可被作为一种安全机制来充分利用
2、存储过程和函数的区别
1)一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
2)对于存储过程来说可以返回参数,如记录集,而函数只能返回值或者表对象。
3)存储过程,可以使用非确定函数,不允许在用户定义函数主体中内置非确定函数。
4)存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用。
3、创建和使用存储过程与函数
(1)存储过程
创建存储过程语法格式:
create procedure sp_name ([proc_parameter[,..]])
[characteristic ..] routine_body
调用存储过程语法格式:
call sp_name([parameter[, ...]])
说明:sp_name 为存储过程的名称,如果要调用某个特定数据库的存储过程,则需要在前面加上该数据库的名称。
(2)创建函数
语法格式:
create function sp_name ([func_parameter[,..]])
returns type
[characteristic ..] routine_body
说明:在 MySQL 中,存储函数的使用方法与 MySQL 内部函数的使用方法是一样的。换言之,用户自己定义的存储函数与 MySQL 内部函数是一个性质的。
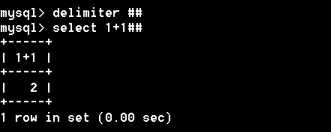
(3)delimiter 命令
可以用 delimiter 来改变默认的结束标志
【例1】把结束符改为 ##,执行 select 1+1##
4、变量










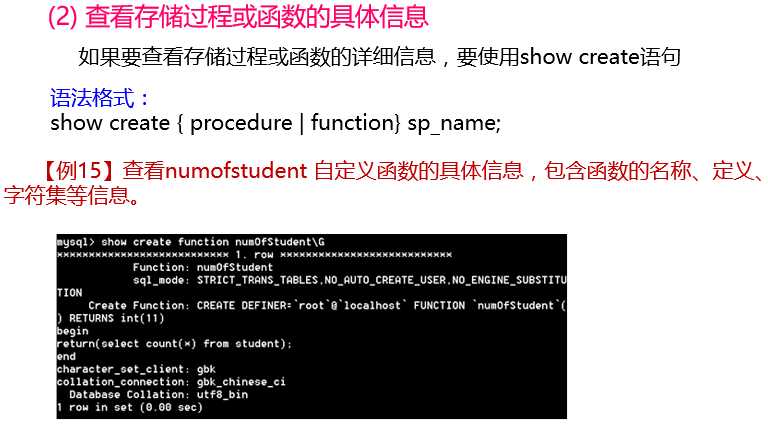



Learning-MySQL【6】:视图、触发器、存储过程、函数、流程控制
标签:ima 动态 rate png src 别人 图的定义 rest sel
原文地址:https://www.cnblogs.com/qiuxirufeng/p/10021447.html
