标签:jvm 特点 解释器 特定 变量 插入 tor 自己的 现在
经历了两周的面试,终于收到了几个满意的offer。换工作的过程是痛苦的,除了一天马不停蹄地跑好几家公司面试,剩下的时间基本就是背面试题了。想找到一份适合自己的面试题并不简单,比如我找的是高级Java开发的职位。出于之前公司系统架构的设计,需要准备Java、spring、springboot、mysql、mybatis、mycat、zookeeper、dubbo、kafka、redis、网络等面试题。我结合之前面试的20多家公司,以及从CSDN/简书/掘金/公众号等相关渠道搜集到的面试题,从中整理出一些高频的面试题库,帮助大家更加省力从容的应付面试。更全的整理题库,可以通过搜索微信小程序【Java职场范儿】或扫描最下方小程序二维码。轻轻松松地刷题。
一、Java获取Class文件的几种方式?
//1.通过Object类中的getClass()方法的。
public static void getClassObject_1() {
Person p = new Person();
Class clazz = p.getClass();
} //2.任何数据类型都具备一个静态的属性.class来获取其对应的Class对象
public static void getClassObject_1() {
Class clazz = Person.class;
} //3.只要通过给定的类的字符串名称就可以获取该类
public static void getClassObject_1() {
String className = "Person";
Class clazz = Class.forName(className);
} 二、如何获取Class中的私有方法?
Method method = e.getClass().getDeclaredMethod("私有方法名",String.class);一、 HashMap和ConcurrentHashMap的原理(并发必问)
HashMap:
1.7版本,使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同,或者hashcode取模后的结果相同(hash collision),那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表。在hashcode特别差的情况下,比方说所有key的hashcode都相同,这个链表可能会很长,那么put/get操作都可能需要遍历这个链表。也就是说时间复杂度在最差情况下会退化到O(n)
1.8版本,使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构,如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里。如果同一个格子里的key不超过8个,使用链表结构存储。如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树。那么即使hashcode完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销。也就是说put/get的操作的时间复杂度最差只有O(log n)。
ConcurrentHashMap:
在多线程环境下,使用HashMap进行put操作时存在丢失数据的情况,为了避免这种bug的隐患,强烈建议使用ConcurrentHashMap代替HashMap。
1.7版本,使用Segment + HashEntry方式进行实现。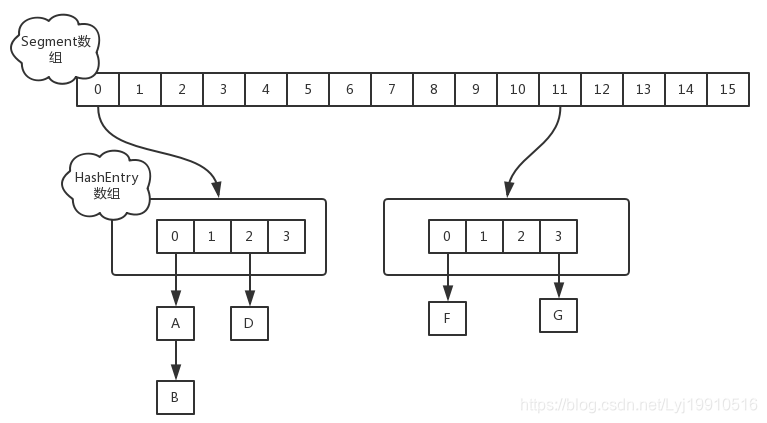
1.8版本,1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,结构如下: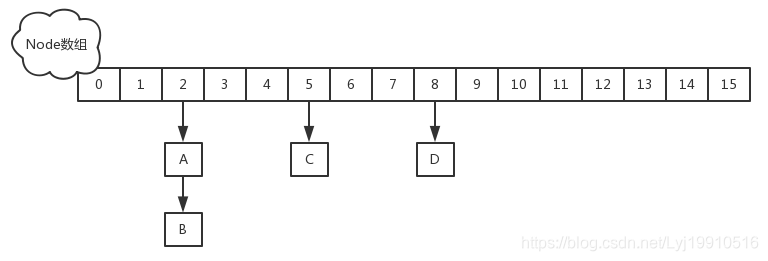
更详细的内容请参考《Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析》
二、 常见的线程池及应用场景
三、 阻塞队列
linkedblockingdeque:双向阻塞
四、 线程池的处理流程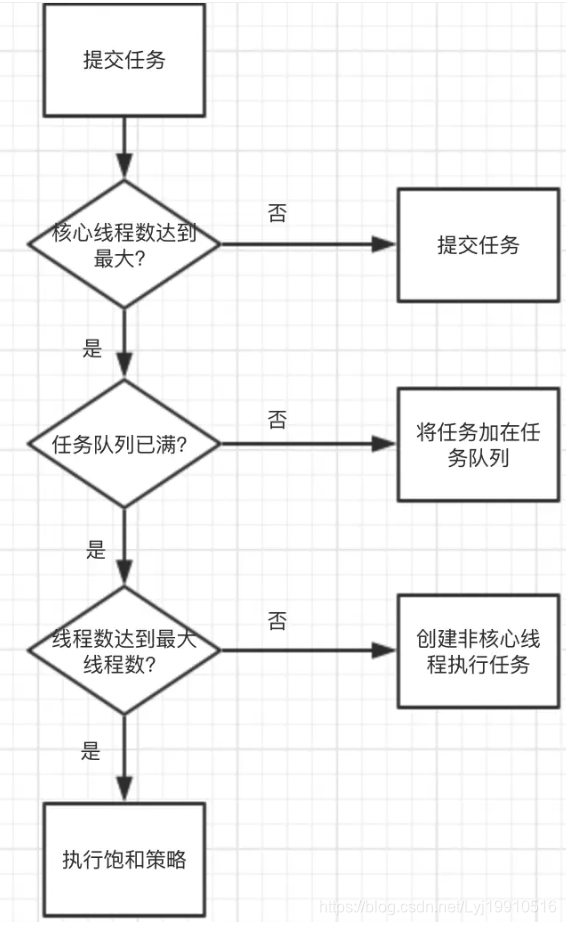
五、Lock与synchronized 的区别
synchronized:
在资源竞争不是很激烈的情况下,偶尔会有同步的情形下,synchronized是很合适的。原因在于,编译程序通常会尽可能的进行优化synchronize,另外可读性非常好,不管用没用过5.0多线程包的程序员都能理解。
ReentrantLock:
ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
一、 JVM内存分哪几个区,每个区的作用是什么
Java虚拟机主要分为以下一个区:
方法区:
虚拟机栈:
本地方法栈
堆
二、java中垃圾收集的方法有哪些?
三、java内存分配与回收策率以及Minor GC和Major GC
标签:jvm 特点 解释器 特定 变量 插入 tor 自己的 现在
原文地址:http://blog.51cto.com/12133258/2325519