标签:code sql 语法错误 upd 创建索引 date agg alt bubuko
1、避免一些不走索引的查询
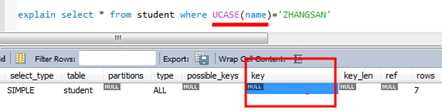
1)避免在索引列上使用函数或者计算,如果这样,优化器将不再使用索引而使用全表扫描:
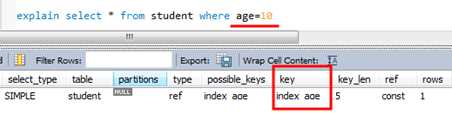
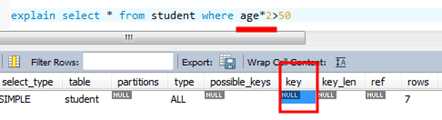
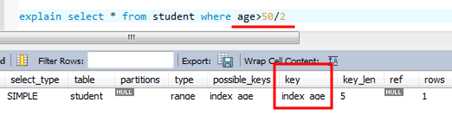
Select * from T where hh*10>1000;(低效,优化器不再使用索引)
Select * from T where hh>1000/10;(更高效,优化器将使用索引)
|
/*在student表的age上创建索引*/ create index index_age on student(age) 下面是走索引的
但是在索引列上计算就不走索引了
替换成下面的情况又走索引了
在索引列上使用函数查询将不走索引(无意义,仅做示例)
|
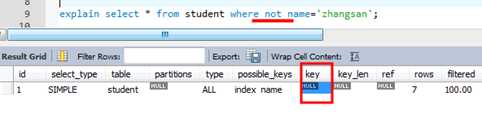
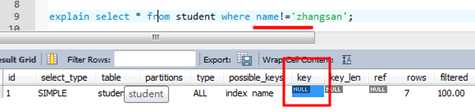
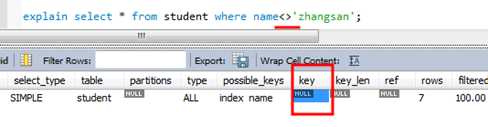
2)避免在索引列上使用not,<>和!=,索引只知道什么在表中,而不能告诉什么不在表中,数据库发现上面三种符号将不再使用索引,而是走全表扫描。
|
/*在student表的name上创建索引*/ create index index_name on student(name)
上面是走索引的,但是下面的情况就不走索引了 1.使用not关键字不走索引 2.使用!=是不走索引,走全表扫描 3.使用<>符号是不走索引的,走全表扫描
|
3)在使用like关键字时,如果将通配符“%”置于要查询字段的前面那么数据库将走全表扫描而不走索引。
4)另一个方面,索引不是越多越好,索引虽然会提高select的效率,但是同时也降低了insert以及update的效率,因为insert或者update时有可能重建索引,这会导致时间的开销。
2:sql语句改写方面:
1)用exists代替in,可以提高查询效率,例如:
Select * from emp where depid in (select depid from dep=’hh’);(更加低效)
Select * from emp where exists(select 1 from dep where emp.depid=id and dep=’hh’);(更加高效)
SELECT * FROM ACCOUNT
WHERE AC_CODE
NOT IN (
SELECT CODE
FROM GOODS
WHERE NUM=‘001‘) //低效
SELECT * FROM ACCOUNT
WHERE NOT EXISTS
(SELECT CODE
FROM GOODS
WHERE CODE=ACCOUNT.AC_CODE
AND NUM=‘001‘)
2)如果一个select中要查询出所有的列,使用*是很方便但是很低效,这是因为数据库会查询数据字典,将*依次转换成所有的列名,非常耗时,如果要显示全部列名则要手写出全部列名。

|
3)Order by语句决定了返回的结果是如何排序的。如果Order by语句后面字段是非索引项那么该查询性能较低,解决的方式是重写语句在order by后面使用索引。
4)使用表的别名,当sql语句连接多个表时,使用表的别名并且把别名置于每个列上,这样可以减少解析时间减少有列名歧义带来的语法错误。
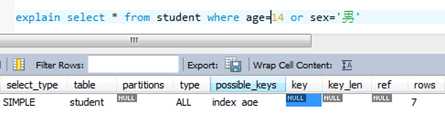
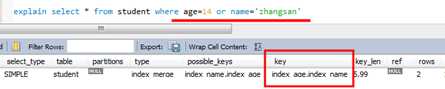
5)使用OR关键字,查询语句的查询条件只有or关键字,而且or前后的两个条件中的列都是索引时,索引才会生效,否则索引不会生效。
|
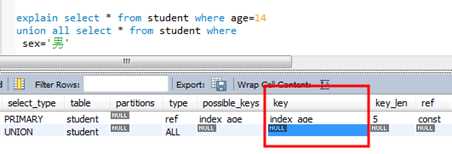
使用or关键字前面是索引列后面是非索引列不走索引 Or前后都是索引,查询才走索引 使用union all ,一个走索引一个不走索引,效率也比全部不走索引要高
|
6)尽量避免全表扫描,在常用在where和order by后面的列建立索引。
7)表适当冗余。因为单表查询比多表联查的性能要高。比如:一个外卖系统,用户下单后手机通知用户,这时候需要查询订单表和用户表,性能较低,那么我们就可以在订单表上加用户ID和用户手机这两个字段,性能回比多表连接查询要高。
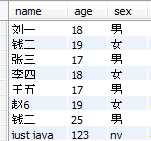
实验表结构:
索引:
create index index_name on student(name)
create index index_age on student(age)
标签:code sql 语法错误 upd 创建索引 date agg alt bubuko
原文地址:https://www.cnblogs.com/llynosy/p/10069322.html