标签:直线 一半 image fill 提醒 resolved holo input style
1. 简介
Generator函数时ES6提供的一种异步编程解决方案。Generator语法行为和普通函数完全不同,我们可以把Generator理解为一个包含了多个内部状态的状态机。
执行Generator函数回返回一个遍历器对象,也就是说Generator函数除了提供状态机,还是一个遍历器对象生成函数。Generator可以以此返回多个遍历器对象,通过这个对象可以以此访问到Generator函数内部的多个状态。
形式上Generator函数和普通的函数有两点不同,一是function关键字后面,函数名前面有一个星花符号“*”,二是,函数体内部使用yield定义(生产)不同的内部状态。
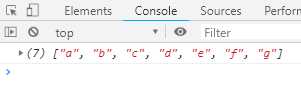
执行Generator函数返回的是一个遍历器对象,这个对象上有一个next方法,执行next方法会返回一个对象,这个对象上有两个属性,一个是value,是yield关键字后面的表达式的值,一个是done,布尔类型,true表示没有遇到return语句,可以继续往下执行,false表示遇到return语句。来看下面的语句:
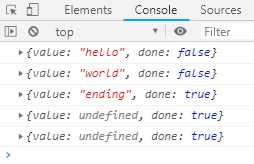
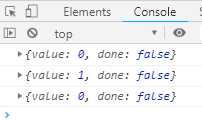
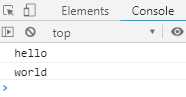
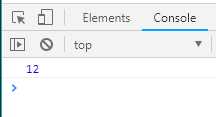
function* helloWorldGenerator () { yield ‘hello‘; yield ‘world‘; return ‘ending‘; } var hw = helloWorldGenerator(); console.log(hw.next()); //第一次调用,Generator函数开始执行,直到遇到yield表达式为止。next方法返回一个对象,它的value属性 // //就是当前yield语句后面表达式的值hello,done属性为false,表示遍历还没有结束 console.log(hw.next()); //第二次调用,Generator函数从上次yield表达式停下的地方,一直执行到下一个yield表达式。next方法 //返回的对象的value属性就是当前yield语句后面表达式的值world,done属性值为false,表示遍历还没有结束。 console.log(hw.next()); //第三次调用,Generator函数从上次yield表达式停下的地方,一直执行到return语句(如果没有return语句 //,则value属性为undefined),done属性为true,表示遍历已经执行结束。 console.log(hw.next()); //第四次调用,此时Generator函数已经执行完毕,next方法返回对戏那个的value属性为undefined,done属性 //为true,表示遍历结束。 console.log(hw.next()); //第五次执行和第四次执行的结果是一样的。
执行结果如下图:
1. 定义Generator函数helloWorldGenerator函数
2. 函数内部有2个yield表达式和一个return语句,return语句结束执行
3. Generator函数的调用方法和普通函数一样,也是在函数名后面加上一对圆括号。不同的是调用之后,函数不是立即执行,返回的也不是return语句的结果undefined,而是一个指向内部状态的指针对象,也就是上面说的遍历器对象(Iterator Object)
4. 调用遍历器对象的next方法,状态指针移动到下一个状态,返回{value: "hello", done: false}
5. 调用遍历器对象的next方法,状态指针移动到下一个状态,返回{value: "world", done: false}
6. 调用遍历器对象的next方法,状态指针移动到下一个状态,返回{value: "ending", done: true},done为false,说明已经遇到了return语句,后面已经没有状态可以返回了
7. 调用遍历器对象的next方法,指针不再移动,返回{value: undefined, done: true}
8. 调用遍历器对象的next方法,指针不再移动,返回{value: undefined, done: true}
注意yield表达式后面的表达式,只有当调用next方法,内部指针指向该语句时才会执行,相当于JavaScript提供了手动的“惰性求职”语法功能。
function* gen() { yield 123 + 456; }
上面代码中,yield后面表达式123 + 456,不会立即求值,只会在next方法将指针移动到这一句时,才会求值。
yield表达式语句和return语句有相似之处,也有却别。相似的地方是都能返回紧跟在语句后面的那个表达式的值。却别在于每次遇到yield,函数暂停执行,下一次再从该位置继续向后执行,return语句没有位置记忆功能。一个函数里面,只能执行一次return语句,但是可以多次执行yield表达式。也就是说Generator可以逐次生成多个返回值,这也是它的名字的来历。
Generator函数中可以不用yield表达式,这时就变成了一个单纯的暂缓执行函数。看下面代码:
function* f () { console.log(‘执行了!‘) } var generator = f(); setTimeout(function () { console.log(generator.next()); // 执行Generator函数,知道遇到yield表达式,这里没有就直接输出:"执行了!",函数返回{"done":true}没有value }, 2000);
输出结果如下:
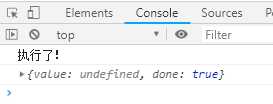
Generator函数f()中没有yield表达式,但是还是一个Generator函数。如果函数f是一个普通函数,在执行var generator = f();的时候就会输出“执行了!”。但是f()是一个Generator函数,就变成了只有调用next方法的时候,函数f才会执行。
另外需要注意,yield表达式只能用在Generator函数里面,用在其他地方都会报错。看下面的代码:
var arr = [1, [[2, 3], 4], [5, 6]]; var flat = function* (a) { a.forEach(function (item) { if (typeof item !== ‘number‘) { yield * flat(item) } else { yield item } }) } for (let f of flat) { console.log(f); }
上面代码会报错,因为forEach方法的参数是一个普通函数,但是在里面使用了yield表达式。可以把forEach改成for循环
var arr = [1, [[2, 3], 4], [5, 6]]; var flat = function* (a) { var length = a.length; for (var i = 0; i < length; i++) { var item = a[i]; if (typeof item !== ‘number‘) { yield *flat(item) } else { yield item; } } } for (var f of flat(arr)) { console.log(f); }
输出结果如下:
另外,如果yield表达式用在另外一个表达式之中,必须放在远圆括号内部。如下:
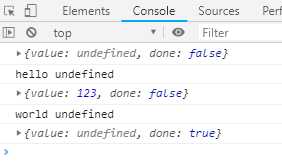
function *demo() { console.log(‘hello ‘ + (yield)); console.log(‘world ‘ + (yield 123)); } var gen = demo(); console.log(gen.next()); console.log(gen.next()); console.log(gen.next());
输出结果如下:
1. 定义Generator函数demo
2. 函数内部有输出"hello"+(yield)和“world”+(yield 123)
3. 调用demo方法得到遍历器对象gen
4. 调用遍历器对象的next方法并输出,注意先执行表达式语句“hello” + (yield),得到{value: undefined, done: false},再输出:“hello undefined”。注意直接输出yield表达式得到的结果是undefined,必须使用遍历器对象的next方法才能获取yield表达式后面的值
5. 调用遍历器对象的next方法并输出,注意先执行表达式语句“worold” + (yield),得到{value: 123, done: false},再输出:“world undefined”。注意直接输出yield表达式得到的结果是undefined,必须使用遍历器对象的next方法才能获取yield表达式后面的值
6. 调用遍历器对象的next方法,因为后面已经没有yield表达式,虽然没有return语句,还是输出{value: undefined, done: true}。done的值是true。后面无论调用next方法多少次,都是这个结果。
yield表达式用作函数或者放在赋值表达式的右边,可以不加括号。如下:
function* demo() { foo(yield ‘a‘, yield ‘b‘); // OK let input = yield; // OK }
上面降到yield表达式本书输出的是undefined,也就是说yield表达式本身没有返回值,或者说总是返回undefined。next方法可以带一个参数,该参数会被当做上一个yield表达式的返回值。
function *f() { for(var i=0; true; i++){ var reset = yield i; if(reset) { i = -1 } } } var g = f(); console.log(g.next()); console.log(g.next()); console.log(g.next(true));
返回结果如下:
上面代码返回一个可以无限运行的Generator函数f,如果next方法没有参数,每次运行到yield表达式,变量reset的值总是yield表达式的值undefined。当next方法带一个参数true时,变量reset就被充值为这个参数的值,即true,因此i的值会等于-1,下一轮循环就会从-1开始递增。这个功能有很重要的语法意义。Generator函数从暂停状态到恢复运行,它的上下文状态(context)是不变的。通过next方法的参数,就有办法在Generator函数开始运行之后,继续向函数体内部注入值。也就是说,在Generator函数运行的不同阶段,从外部向内部注入不同的值,可以调整函数行为。
看下面的例子:
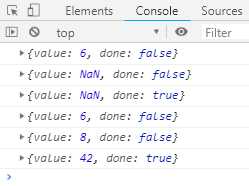
function* foo (x) { var y = 2 * (yield (x + 1)); var z = yield (y / 3); return (x + y + z); } var a = foo(5); console.log(a.next()); console.log(a.next()); console.log(a.next()); var b = foo(5); console.log(b.next()); console.log(b.next(12)); console.log(b.next(13));
运行结果如下图:
1. 申明一个Generator函数foo
2. 调用函数foo,传入参数5,得到遍历器对象a
3. 调用遍历器对象a的next方法,返回yield关键字后面表达式(x + 1)的值,得到6,返回结果{ value: 6, done: false }。
4. 调用遍历器对象a的next方法,往下执行,因为执行next的时候没带参数,上一次yield表达式的值从6变成undefined,而不是6,y的值是2 * undefined,即为NaN。本次yield表达式的值是undefined / 3 为NaN。最后返回结果{ value: undefined, done: false }
5. 调用遍历器对象a的next方法,往下执行,因为执行next的时候没有带参数,上一次yield表达式的值为从NaN变成undefined,因此z的值是undefined,返回的值为5 + NaN + undefined,即为NaN
6. 调用函数foo,传入参数5,得到遍历器对象b
7. 调用遍历器对象的next方法,返回yield关键字后面表达式(x + 1)的值,得到6,返回结果{ value: 6, done: false }
8. 调用遍历器对象的next方法,传参12,因此上一次yield关键字后面的表达式的(x + 1)的值从6变为12,y的值是2 * 12,即为24。yield关键字后面表达式的值为 (24 / 3),即为8。最后返回结果{ value: 8, done: false }
9. 调用遍历器对象的next方法,传入参数13,因此上一次yield关键字后面的表达式(y / 3)的值从8变成13,z的值是13。表达式(x + y + z)的值是(5 + 24 + 13),即42。最后返回结果{ value: 24, done: true }
注意,由于next方法的参数表示上一个yield表达式的返回值,所以在第一调用next方法时,传递参数是无效的。JavaScript引擎直接忽略第一次使用next方法时的参数,只有从第二次使用next方法开始,参数才是有效的。从语义上说,第一个next方法用来启动遍历器对象,所以不用带参数。
再看一个例子:
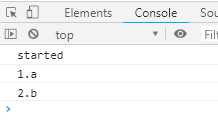
function * dataConsumer () { console.log(‘started‘) console.log(`1.${yield }`) console.log(`2.${yield }`) return ‘result‘ } let genObj = dataConsumer() genObj.next() genObj.next(‘a‘) genObj.next(‘b‘)
输出结果:
1. 定义Generator函数dataConsumer
2. 调用dataConsumer函数,得到遍历器对象genObj
3. 调用遍历器对象genObj的next方法,执行执行dataConsumer函数,只到遇到yield表达式为止。注意第一句输出“started”,第二句里就有yield表达式,因此在这里停止。最终结果是“started”
4. 调用遍历器对象genObj的next方法,传入参数‘a’,继续往下执行,上一次yield表达式的值从undefined变成‘a’,最后输出1.a
5. 调用遍历器对象genObj的next方法,传入参数‘b’,继续往下执行,上一次yield表达式的值从undefined变成‘b’,最后输出2.b
上面代码是一个很直观的例子,每次通过next方法向Generator函数注入值,然后打印出来。
如果想要第一次调用next方法时就能够输入值,可以在Generator函数外面再包一层。
function wrapper (generatorFunction) { return function (...args) { let generatorObject = generatorFunction(...args) generatorObject.next() return generatorObject } } const wrapped = wrapper(function *() { console.log(`first input: ${yield }`) return ‘DONE‘ }) wrapped().next(‘hello‘)
输出结果:
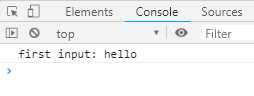
上面代码中,Generator函数如果不用wrapper先包一层,是无法在第一次调用next方法的时候就输入参数的。
2. Generator和Iterator接口的关系
任意一对象的Symbol.iterator方法,等于该对象的遍历器生成函数,调用该函数会返回该对象的一个遍历器对象。
由于Generator函数就是遍历器生成函数,因此可以把Generator赋值给对象的Symbol.iterator属性,从而使这个对象具有Iterator接口。
var myIterable = {}; myIterable[Symbol.iterator] = function *() { yield 1; yield 2; yield 3; }; console.log([...myIterable]);
输出结果如下:
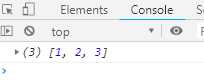
上面代码中Generator函数赋值给Symbol.iterator属性,从而使myIterator对象具有了iterator接口,这样就可以被...运算符遍历了。
Generator函数执行后,返回一个遍历器对象。该对象本身也具有Symbol.iterator属性,执行后返回自身。
function *gen() { } var g = gen(); console.log(g[Symbol.iterator]() === g); // 输出true
上面代码中,gen是一个Generator函数,调用它会生成一个遍历器兑现g,它的Symbol.iterator属性也是一个遍历器对象生成函数,执行后返回它自己。
for...of循环可以自动遍历Generator函数生成的Generator对象,并且不需要调用next方法,看下面的代码:
function* foo () { yield 1; yield 2; yield 3; yield 4; yield 5; return 6; } for (let v of foo()) { console.log(v); }
输出结果如下:
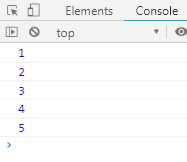
上面代码中使用for...of循环,以此显示5个yield表达式的值。这里需要注意,一旦next方法的返回对象的done属性为true,for...of循环就会终止,且不包含该返回对象,所以上面代码中return语句返回值6,不包括在for...of循环中。
下面是一个利用Generator函数和for...of循环,实现斐波那契数列的例子
function* fibonacci () { let [prev, curr] = [0, 1]; for (; ;) { [prev, curr] = [curr, prev + curr]; yield curr; } } for (let n of fibonacci()) { if (n > 1000) break; console.log(n); }
输出结果如下:
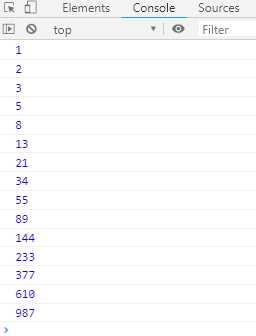
从上面代码可以看出,使用for...of语句时,不再需要使用next方法。
利用for...of循环,可以写出遍历任意对象(Object)的方法。原生的JavaScript兑现更没有遍历接口,无法使用for...of循环,通过Generator函数为它加上这个接口,就可以说用了。
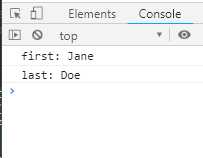
function* objectEntries (obj) { let propKeys = Reflect.ownKeys(obj); for (let propKey of propKeys) { yield [propKey, obj[propKey]]; } } let jane = {first: ‘Jane‘, last: ‘Doe‘}; for (let [key, value] of objectEntries(jane)) { console.log(`${key}: ${value}`); }
输出结果如下:
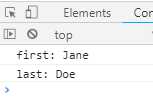
上面代码中,对象jane原生不具备Iterator接口,无法用for...of遍历。这是我们通过Generator函数objectEntries函数为它加上遍历器接口,就可以用for...of遍历了。加上遍历器接口的另一种写法是,将Generator函数加到对象的Symbol.iterator属性上,代码如下:
function* objectEntries () { let propKeys = Object.keys(this); for (let propKey of propKeys) { yield [propKey, this[propKey]]; } } let jane = {first: ‘Jane‘, last: ‘Doe‘}; jane[Symbol.iterator] = objectEntries; for (let [key, value] of jane) { console.log(`${key}: ${value}`); }
输出结果如下:
除了for...of循环,扩展运算符(...),解构赋值和Array.from方法内部调用的都是遍历器接口,这就是说,它们都可以将Generator函数返回的Iterator对象作为参数。看下面的代码:
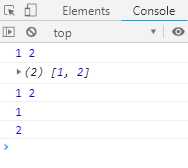
function* numbers () { yield 1 yield 2 return 3 yield 4 } // 扩展运算符 console.log(...numbers()) // Array.from方法 console.log(Array.from(numbers())) // 解构赋值 let [x, y] = numbers() console.log(x, y) // for ... of循环 for (let n of numbers()) { console.log(n) }
输出结果如下:
3. Generator.property上的方法
3.1. Generator.property.throw()
Generator原型对象上有一个throw方法,可以在函数体外抛出错误,然后在Generator函数体内捕获。
var g = function* () { try { yield; } catch (e) { console.log(‘内部捕获‘, e) } } var i = g(); i.next(); try { i.throw(‘a‘); i.throw(‘b‘); } catch (e) { console.log(‘外部捕获‘, e); }
输出结果如下:
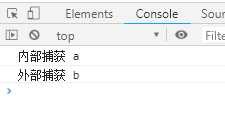
上面代码中,遍历器对象i连续抛出两个错误。第一个错误被Generator函数体内部的catch语句捕获。i第二次抛出错误,由于Generator函数内部的catch语句已经执行过了,不会再捕捉到这个错误,所以这个错误就被抛出了Generator函数体,被函数体外的catch语句捕获。
throw方法可以接受一个参数,参数会被catch语句接收,建议抛出Error对象实例。
var g = function* () { try { yield; } catch (e) { console.log(e) } } var i = g(); i.next(); i.throw(new Error(‘出错了!‘))
输出结果如下:
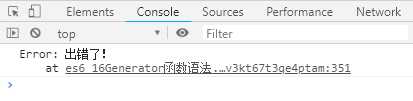
不要混淆遍历器对象的throw方法和全局的throw命令。上面代码的错误,是用遍历器对象的throw方法抛出的,而不是用throw命令抛出的。后者只能被函数体外的catch语句捕获。
var g = function* () { while (true) { try { yield; } catch (e) { if (e !== ‘a‘) { throw e; } console.log(‘内部捕获‘, e) } } } var i = g(); i.next(); try { throw new Error(‘a‘); throw new Error(‘b‘); } catch (e) { console.log(‘外部捕获‘, e); }
输出结果如下:
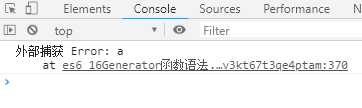
上面代码只捕获了a,是因为函数体外的catch语句块,捕获了抛出的a错误以后,就不会再继续try代码块里剩余的语句了。因为没有执行i.catch()语句,内部的异常不会被捕获。
如果Generator函数内部没有try...catch代码块,那么throw方法抛出的错误将被外部try...catch代码块捕获。
var gen = function* gen () { yield console.log(‘hello‘); yield console.log(‘world‘); } var g = gen(); g.next(); g.throw();
输出如下:
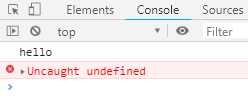
上面代码中给,g.throw抛出错误后,没有任何try...catch代码可以捕获这个错误,导致程序报错,终端执行。
throw方法抛出的错误要被内部捕获,前提是必须至少执行一次next方法。
function * gen () { try { yield 1 } catch (e) { console.log(‘内部捕获‘) } } var g = gen() t.throw(1)
输出结果如下:
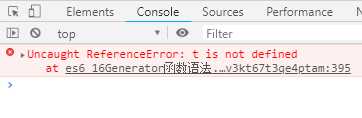
上面代码中,g.throw(1)执行时,next方法一次都没有执行过。这时,抛出的错误不会被内部捕获,而是直接在外部抛出,导致程序出错。这种行为其实很好理解,因为第一次执行next方法,等同于启动执行Generator函数的内部代码,否则Generator函数还没有开始执行,这时throw方法抛出错误只能抛出在函数外部。
throw方法被捕获以后,会附带执行下一条yield表达式。也就是说,会附带执行一次next方法。
var gen = function* gen () { try { yield console.log(‘a‘); } catch (e) { } yield console.log(‘b‘); yield console.log(‘c‘); } var g = gen(); g.next(); g.throw(); g.next();
输出结果如下:
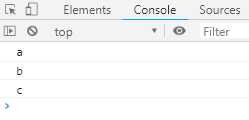
上面代码中,g.throw方法被捕获以后,自动执行了一次next方法。所以会打印b。另外,也可以看到,只要Generator函数内部部署了try...catch代码块,那么遍历器的throw方法抛出的错误,不影响下一次遍历。
另外,throw命令和g.throw方法是无关的,两者互不影响。
var gen = function* gen() { yield console.log(‘hello‘); yield console.log(‘world‘); } var g = gen(); g.next(); try { throw new Error(); } catch (e) { g.next(); }
输出结果如下:
上面代码中,throw命令抛出的错误不会影响到遍历器的状态,所以两次执行next方法,都进行了正确的操作。
这种函数体内捕获错误的机制,方便了对错误的处理。多个yield表达式可以只用一个try...catch代码块来捕获错误。如果使用回调函数的写法,想要捕获多个错误,就不得不为每个函数内部写一个错误处理语句,现在只在Generator函数内部洗写一次catch语句就可以了。
Generator函数体外抛出的错误,可以在函数体内捕获;反过来,Generator函数体内抛出的错误,也可被函数体外的catch捕获。
function* foo () { var x = yield 3; var y = x.toUpperCase(); yield y; } var it = foo(); it.next(); try { it.next(42); } catch (err) { console.log(err); }
上面代码中,第二个next方法向函数体内传入一个参数42,,数值是没有toUpperCase方法的,所以会抛出一个TypeError错误,被函数体外的catch捕获。
一旦Generator执行过程中抛出错误,且没有被内部捕获,就不会再往下执行下去了。如果伺候还调用next方法,将返回一个value属性为undefined,done属性为tru的对象,即JavaScript引擎认为这个Generator已经运行结束了。
function *g() { yield 1; console.log(‘throwing an exception‘); throw new Error(‘generator broke!‘); yield 2; yield 3; } function log(generator) { var v; console.log(‘starting generator‘); try{ v = generator.next(); console.log(‘第一次运行next方法‘, v); } catch(err) { console.log(‘捕捉错误‘, v); } try{ v = generator.next(); console.log(‘第二次运行next方法‘,v); }catch(err){ console.log(‘捕捉错误‘, v); } try{ v = generator.next(); console.log(‘第三次运行next方法‘, v); } catch(err) { console.log(‘捕捉错误‘, v); } console.log(‘caller done‘); } log(g());
执行结果如下:
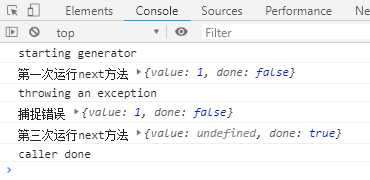
上面代码一共三次运行next方法,第二次运行的时候会抛出错误,然后第三次运行的时候,Generator函数就已经结束了,不再执行下去。
3.2.Generator.property.return()
Generator函数返回的遍历器对象,还有一个return方法,可以返回给定值,并且终结遍历Generator函数。
function *gen() { yield 1; yield 2; yield 3; } var g = gen(); console.log(g.next()); console.log(g.return(‘foo‘)); console.log(g.next());
执行结果如下:
function *gen() { yield 1; yield 2; yield 3; } var g = gen(); console.log(g.next()); console.log(g.return(‘foo‘)); console.log(g.next());
上面代码中,遍历器对象g调用return方法之后,返回值的value属性就是return方法的参数“foo”。并且,Generator函数的遍历就终止了,返回值的done属性为true,以后再调用next方法,done属性的返回值总是true。
如果return方法调用时,不提供参数,则返回值的value属性为undefined。
function *gen() { yield 1; yield 2; yield 3; } var g = gen(); console.log(g.next()); console.log(g.return());
执行结果如下:
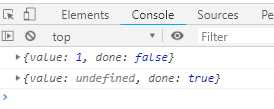
如果Generator函数内部有try...finally代码块,那么return方法会推迟到finally代码块执行完后再执行。
function * numbers() { yield 1; try{ yield 2; yield 3; } finally { yield 4; yield 5; } yield 6; } var g = numbers(); console.log(g.next()); console.log(g.next()); console.log(g.return(7)); console.log(g.next()); console.log(g.next());
执行结果如下:
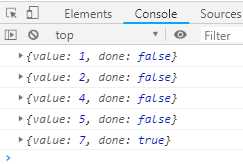
上面代码中,调用return方法后,就开始执行finally代码块,然后等到finally代码块执行完,再执行return方法。
next(),throw(),return()方法的共同点
next(),throw(),return()这三个方法本质上是同一件事情,可以放在一起理解。他们的作用个都是让Generator函数恢复执行,并且使用不同的语句替换yield表达式。
next()是将yield表达式替换成一个值。
const g = function* (x, y) { let result = yield x + y return result } const gen = g(1, 2) console.log(gen.next()) console.log(gen.next(1))
输出结果如下:
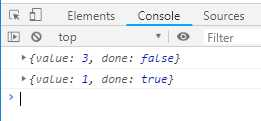
上面代码中,第二个next(1)方法相当于将yield表达式x + y替换成一个值1。如果next方法没有参数,就相当于替换成undefined。所以第二次调用next方法的时候如果不传参数,返回的结果是{ value: undefined, done: false }。
throw是将yield表达式替换成一个throw语句。
const g = function* (x, y) { let result = yield x + y return result } const gen = g(1, 2) console.log(gen.next()) gen.throw(new Error(‘出错了‘))
输出结果如下:
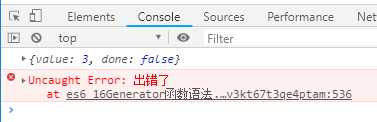
上面代码相当于将let result = yield x + y替换成let result = throw(new Error(‘出错了‘))
return语句时将yield表达式替换成一个return语句
const g = function* (x, y) { let result = yield x + y return result } const gen = g(1, 2) console.log(gen.next()) console.log(gen.return(2))
输出结果如下:
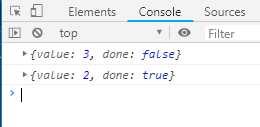
return语句相当于将let result = yield x + y替换成let result = return 2
4. yield*表达式
如果在Generator函数内部,调用跟另外一个Generator函数,默认情况下是没有效果的。看下面代码:
function* foo () { yield ‘a‘; yield ‘b‘; } function* bar () { yield ‘x‘; foo(); yield ‘y‘; } for (let v of bar()) { console.log(v); }
输出结果如下
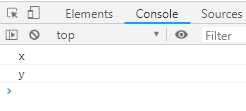
上面代码中,foo和bar都是Generator函数,在bar函数中调用foo,是不会有任何效果的。可以使用yield*表达式来调用另外一个Generator函数。如下代码:
function* foo () { yield ‘a‘; yield ‘b‘; } function* bar () { yield ‘x‘; yield *foo(); yield ‘y‘; } for (let v of bar()) { console.log(v); }
执行效果如下:
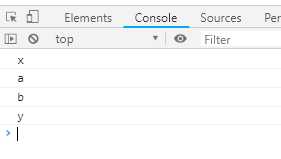
function* bar() { yield ‘x‘; yield* foo(); yield ‘y‘; } // 等同于 function* bar() { yield ‘x‘; yield ‘a‘; yield ‘b‘; yield ‘y‘; } // 等同于 function* bar() { yield ‘x‘; for (let v of foo()) { yield v; } yield ‘y‘; } for (let v of bar()){ console.log(v); }
输出结果是相同的,在一个Generator函数中使用yield*调用另外一个Generator函数,相当于把另一个Generator函数中的yield表达式放在这个函数中执行。
function* inner () { yield ‘hello!‘; } function* outter1 () { yield ‘open‘; yield inner(); yield ‘close‘; } var gen = outter1(); console.log(gen.next().value); console.log(gen.next().value); console.log(gen.next().value); function* outter2 () { yield ‘open‘; yield* inner(); yield ‘close‘; } var gen2 = outter2(); console.log(gen2.next().value); console.log(gen2.next().value); console.log(gen2.next().value);
输出结果如下:
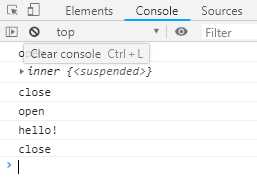
上面代码中,outer2使用了yield*表达式,outer1没有使用。结果就是,outer1返回一个遍历器对象,outer2返回该遍历器对象的内布置。从语法角度看,如果yield表达式跟的是一个遍历器对象,需要在yield关键字后面加上星号,表明它返回的是一个遍历器对象,这被称为yield*表达式。
let delegatedIterator = (function* () { yield ‘Hello!‘; yield ‘Bye!‘; }()); let delegatingIterator = (function* () { yield ‘Greetings!‘; yield* delegatedIterator; yield ‘Ok, bye.‘; }()); for (let value of delegatingIterator) { console.log(value); }
执行结果如下:
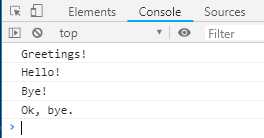
上面代码中,delegatingIterator是代理者,delegatedIterator是被代理者,由于yield* delegatedIterator语句得到的值,是一个遍历器,所以要用型号表示。运行结果是用一个遍历器,遍历了多个Generator,有递归的效果。
yield*后面的Generator函数没有return语句的时候,等同于在Generator函数内部,部署了一个for...of循环。如下代码:
function *concat(iter1, iter2) { yield * iter1; yield * iter2; } // 等同于 function * concat(iter1, iter2) { for(var value of iter1){ yield value; } for(var value of iter2){ yield value; } }
上面代码说明,yield*后面的Generator函数(没有return语句时),不过是for...of的一种简写形式,完全可以用后者代替前者。反之,在有return语句的时候需要使用var value = yield* iterator的形式获取return语句的值。
如果yield*后面跟着一个数组,由于数组原生支持遍历器,因此就会遍历数组成员。如下代码:
function* gen () { yield* [‘a‘, ‘b‘, ‘c‘] } let g = gen() console.log(g.next()) console.log(g.next()) console.log(g.next()) console.log(g.next())
执行结果如下:
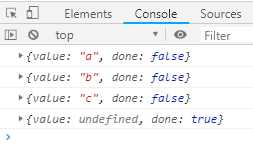
上面代码中,yield命令后面如果不加星号,返回的是整个数组,加了星号就表示返回的是数组的遍历器对象。
实际上,任何数据结构,只要有Iterator接口,就可以被yield*表达式遍历。
let read = (function* () { yield ‘hello‘; yield* ‘world‘; })(); console.log(read.next().value); console.log(read.next().value);
返回结果如下:
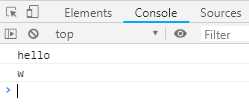
上面代码中,yield表达式返回的是整个字符串,但是yield*表达式返回的是单个字符。因为字符串有Iterator接口,所以被yield*表达式遍历。
如果被代理的Generator函数有return语句,那么久可以向代理它的Generator函数返回数据。
function* foo () { yield 2; yield 3; return "foo"; yield 4; } function* bar () { yield 1; var v = yield* foo(); console.log("v: " + v); yield 5; } var it = bar(); console.log(it.next()); // {value: 1, done: false} console.log(it.next()); // {value: 2, done: false} console.log(it.next()); // {value: 3, done: false} console.log(it.next()); // "v: foo" {value: 5, done: true} console.log(it.next()); // {value: undefined, done: true}
执行结果如下:
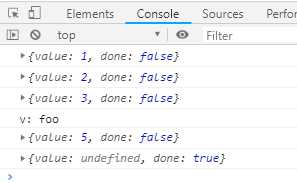
1. 定义Generator函数foo
2. 定义Generator函数bar,在函数内部使用yield*表达式调用函数foo
3. 调用bar方法,得到遍历器对象it
4. 调用遍历器对象it的next方法,返回{ value: 1, done: false }
5. 调用遍历器对象it的next方法,返回Generator函数foo的第一个yield表达式返回的对象{ value: 2, done: false }
6. 调用遍历器对象it的next方法,返回Generator函数foo的第二个yield表达式返回的对象{ value: 3, done: false }
7. 调用遍历器对象it的next方法,foo结束,foo方法里面有return语句,返回值是“foo”,继续往下执行只到遇到yield语句,输出“v:foo” 并输出{ value: 5, done: false }
8. 调用遍历器对象it的next方法,Generator函数里已经没有yield语句,输出{ value: undefiined, done: true }
再看下面的例子
function* genFuncWithReturn () { yield ‘a‘; yield ‘b‘; return ‘The result‘; } function* logReturned (genObj) { let result = yield* genObj; console.log(result); } console.log([...logReturned(genFuncWithReturn())])
输出结果:
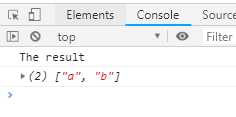
上面代码中,存在两次遍历,第一是扩展运算符便利函数logReturned返回的遍历器对象,第二次是yield*语句遍历函数genFunWithReturn返回的遍历器对象。这两次遍历效果是叠加的,最终表现为扩展运算符遍历函数getFuncWithReturn返回的遍历器对象。这两次遍历的效果是叠加的,最终表现为扩展运算符遍历函数getFunWithReturn返回的遍历器对象。所以,最后的数据表达式得到的值是[ ‘a‘, ‘b‘ ]。但是函数getFuncWithReturn的return语句的返回值“The result”,会返回给函数logReturned内部的result变量,因此会有终端输出。
yield*命令可以很方便地取出多维嵌套数组的所有成员。看下面的代码:
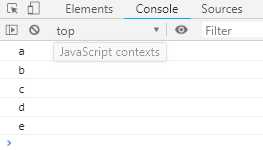
function* iterTree (tree) { if (Array.isArray(tree)) { for (let i = 0; i < tree.length; i++) { yield* iterTree(tree[i]); } } else { yield tree; } } const tree = [‘a‘, [‘b‘, ‘c‘], [‘d‘, ‘e‘]]; for (let x of iterTree(tree)) { console.log(x); }
运行结果如下:
下面的例子稍微复杂,使用yield*语句遍历完全二叉树
function Tree (left, label, right) { this.left = left; this.label = label; this.right = right; } // 下面是中序(inorder)遍历函数,由于返回的是一个遍历器,所以要用genrator函数,函数体内采用递归算法,所以左树和右树都要用yield*遍历 function* inorder (t) { if (t) { yield* inorder(t.left); yield t.label; yield* inorder(t.right) } } // 下面生成二叉树 function make (array) { // 判断是否为叶子节点 if (array.length === 1) { return new Tree(null, array[0], null); } return new Tree(make(array[0]), array[1], make(array[2])); } let tree = make([[[‘a‘], ‘b‘, [‘c‘]], ‘d‘, [[‘e‘], ‘f‘, [‘g‘]]]); var result = []; for (let node of inorder(tree)) { result.push(node); } console.log(result);
输出结果如下
作为对象属性的Generator函数
如果一个对象的属性是Generator函数,可以简写成下面的形式
let obj = { * myGeneratorMethod () { } }
上面代码中myGeneratorMethod属性前面有一个星号,表示这个属性是一个Generator函数。它的完整形式如下:
let obj = { myGeneratorMethod: function* () { } }
Generator函数的this
Generator函数总是返回一个遍历器,ES6规定这个遍历器是Generator函数的实例,也继承了Generator函数的prototype对象上的方法。
function* g () { } g.prototype.hello = function () { return ‘hi!‘; }; let obj = g(); console.log(obj instanceof g); // true console.log(obj.hello()); // ‘hi‘
上面代码中,Generator函数g返回的遍历器obj,是g的实例,而且继承了g.prototype。但是,如果把g当做普通的构造函数,并不会生效,因为g返回总是遍历器对象,而不是this对象。
function* g () { this.a = 11; } let obj = g(); console.log(obj.a); // undefined
上面代码中,Generator函数g在this对象上面添加了一个属性a,但是obj对象拿不到这个属性。
Generator函数也不能喝new命令一起使用,否则会报错。
function* F () { yield this.x = 2; yield this.y = 3; } let obj = new F(); // Uncaught TypeError: F is not a constructor
上面代码中,new命令和Generator函数F一起使用,结果报错,因为F不是一个构造函数 。
有没有办法让Generator函数返回一个正常的对象实例,既可以用next方法,又可以获得正常的this呢?下面是一个变通方法,首先生成一个空对象,使用call方法绑定Generator函数内部的this。这样,构造函数调用以后,这个空对象就是Generator函数实例的对象了。
function* F () { this.a = 1; yield this.b = 2; yield this.c = 3; } var obj = {}; var f = F.call(obj); console.log(f.next()); // object{value: 2, done: false} console.log(f.next()); // object{value: 3, done: false} console.log(f.next()); // object{value: undefined, done: true} console.log(obj.a); //1 console.log(obj.b); //2 console.log(obj.c); //3
执行结果如下:
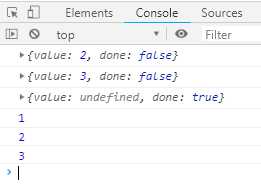
上面代码中,首先是F内部的this对象绑定obj对象,然后调用它,返回一个Iterator对象。这个对象执行三次next()方法,(因为F内部有两个yield表达式),完成F内部所有代码运行。这是所有内部属性都绑定在obj对象上路,因此obj对象也就成了F对象的实例。
上面代码中给,执行的是遍历器对象f,但是生成的对象实例是obj,有没有办法将这两个对象统一起来呢?一个办法就是将obj换成F.prototype。
function* F () { this.a = 1; yield this.b = 2; yield this.c = 3; } var f = F.call(F.prototype); console.log(f.next()); console.log(f.next()); console.log(f.next()); console.log(f.a); console.log(f.b); console.log(f.c);
执行结果如下:
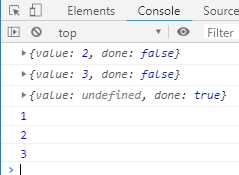
再将F改造成一个构造函数,就可以对它执行new命令了,代码如下:
function* gen () { this.a = 1; yield this.b = 2; yield this.c = 3; } function F () { return gen.call(gen.prototype); } var f = new F(); console.log(f.next()); console.log(f.next()); console.log(f.next()); console.log(f.a); console.log(f.b); console.log(f.c);
5 含义
5.1 Generator和状态机
Generator是实现状态机的最佳结果。比如,下面代码中clock函数就是一个状态机。
var ticking = true; var clock = function () { if (ticking) { console.log(‘Tick!‘) } else { console.log(‘Tock!‘) } ticking = !ticking; } clock(); clock();
clock函数有两种状态(Tick和Tock) ,每运行一次,就改变一次状态。这个函数如果用Generator函数实现,就是像下面这样:
var clock = function* () { while (true) { console.log(‘Tick!‘); yield; console.log(‘Tock!‘); yield; } }; var c = clock(); c.next(); c.next();
和上面不用Generator函数的方法比较,少了用来保存状态的外部变量ticking,这样更加简洁,安全(状态不会被外面代码篡改) ,更符合函数式变成的思想,在写法上也更加优雅。Generator之所以可以不用外部变量保存,因为它本身就包含了一个状态信息,即目前是否处于暂停状态。
5.2 Generator与协程
协程(coroutine)是一种程序运行的方式,可以理解为“协作的线程”或者“协作的函数”。协程可以用单线程实现,也可以用多线程实现。
(1)协程与子例程的差异
传统的“子例程”(subroutine)采用堆栈式的“后进先出”的执行方式,只有当调用的子函数完全执行完毕,才会结束执行父函数。协程与其不同,多个线程(单线程情况下,即多个函数)可以并行执行,但是只有一个线程(或函数)处于正在运行的状态,其他线程(或函数)都处于暂停状态(suspended),线程(或函数)之间可以交换执行权。也就是说,一个线程(或函数)执行到一半,可以暂停执行,将执行权交给另一个线程(或函数),等到收回执行权的时候,再恢复执行。这种可以并行执行,交换执行权的线程(或函数),就称为协程。
从实现上来看,在内存中给,子例程只使用一个栈(stack),而协程是同时存在多个栈,但只有一个栈是在运行状态,也就是说,协程是以多占用内存为代码,实现多任务的并行。
(2)协程与普通线程的差异
协程适用于多任务运行的环境。在这个意义上,它与普通的线程很相似,都有自己的执行上下文,可以分享全局变量。他们的不同之处在于,同一时间可以有多个线程处于运行状态,但是运行的协程只有一个,其他协程都处于暂停状态。此外,普通的线程是抢先式的,到底哪个线程优先得到资源,必须由运行环境决定,但是协程是合作式的,执行权由协程自己分配。
由于JavaScript是单线程语言,只能保持一个调用栈。引入协程后,每个任务可以保持自己的调用栈。这样做的最大好处是抛出错误的时候,可以找到原始的调用栈。不至于像异步操作的回调函数那样,一旦出错,原始的调用栈早就结束。
Generator函数是ES6对协程的实现,但是属于不完全实现。Generator函数是“半协程”,意思是只有Generator函数的调用者,才能将程序的执行权交给Generator函数。如果是完全执行的协程,任何函数都可以让暂停的协程继续执行。
如果将Generator函数当做协程,完全可以将多个需要相互协作的任务协程Generator函数,他们之间使用yield表达式交换控制权。
5.3 Generator与上下文
JavaScript代码运行时,会产生一个全局的上下文环境(context,又称运行环境),它包含了当前所有变量和对象。然后,执行函数(或者块级代码)的时候,又会在当前上下文环境的上层,产生一个函数运行的上下文,变成当前(active)的上下文,由此产生一个上下文环境的堆栈(context statck)。
这个堆栈式“先进后出”的数据结构,最后产生的上下文环境首先执行完成,退出堆栈,然后执行完成它下层的上下文,直至所有代码执行完成,堆栈清空。
Generator函数不是这样,它执行产生的上下文环境,一旦遇到yied命令,就会暂时退出堆栈,但是并不消失,里面所有变量和对象会冻结在当前状态。等到对它执行next命令时,这个上下文环境又会重新加入调用栈,冻结的变量和对象恢复执行。
function * gen () { yield 1; return 2; } let g = gen(); console.log(g.next().value, g.next().value);
输出结果:
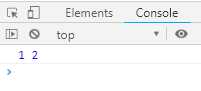
上面的代码中,第一次执行g.next()时,Generator函数的gen的上下文会加入堆栈,机开始运行gen内部的代码。等到遇到yield 1的时候,gen上下文退出堆栈,内部状态冻结。第二次执行g.next()时,gen上下文又重新加入堆栈,变成当前的上下文,重新恢复执行。
5.4 应用
Generator可以暂停该函数执行,返回yield表达式的值。这种特点使得Generator函数有多种应用场景。
5.4.1 异步操作的同步化表达
Generator函数的暂停执行的效果,意味着可以把异步操作写在yield表达式里面,等到调用next方法时再往后执行。这实际上等同于不需要写回调函数了。因为异步操作的后续操作可以放在yield表达式下面,反正要等到调用next方法时再执行,所以Generator函数的一个重要时机意义就是用来处理异步操作,改写回调函数。看下面的代码段:
function* loadUI () { showLoadingScreen(); yield loadUIDataAsynchronously(); hideLoadingScreen(); } var loader = loadUI(); // 加载UI loader.next(); // 卸载UI loader.next();
上面代码中,第一次调用loadUI函数时,该函数不会执行,仅返回一个遍历器。下一次对改遍历器调用next方法,则会显示Loaidng界面(showLoadingScreen),并且异步加载数据(loadingUIDataAsynchronously)。等到数据加载完成,再一次调用next方法,则会隐藏Loading界面。可以看到,这种写法的好处是所有Loading界面的逻辑,都会被封装在一个函数里,按部就班非常清晰。
下面是一个例子,可以手动逐行读取一个文本文件。
function* numbers () { let file = new FileReader(‘numbers.txt‘); try { while (!file.eof) { yield parseInt(file.readLine(), 10); } } finally { file.close(); } }
5.4.2 流程控制
如果有一个多步操作非常耗时,采用回调函数,可能写成下面这样:
setp1(function (value1) { setp2(value1, function (value2) { setp3(value2, function (value3) { // Dom something with value3 }) }) })
采用Promise改写上面的代码。代码中把回调函数,改成直线执行的形式,但是加入了大量的Promise语法。
Promise.resolve(setp1) .then(setp2) .then(setp3) .then(setp4) .then(function (value4) { // Do something with value4 }, function (error) { // Handle any error from stemp1 through step4 }).done()
采用Generator语法,可以写成下面这样:
function* longRunningTask (value1) { try { var value2 = yield step1(value1); var value3 = yield setp2(value2); var value4 = yield setp3(value3); var value5 = yield setp4(value4); // Do something with value4 } catch (e) { // handle error } } // 然后使用一个函数,依次自动执行所有步骤 scheduler(longRunningTask(initValue)); function scheduler (task) { var taskObj = task.next(task.value); if (!taskObj.done) { task.value = taskObj.value; scheduler(task); } }
注意,上面这种做法,只适合同步操作,即所有的task都必须是同步的,不能有异步操作。因为这里的代码得到返回值,立即继续往下执行,没有判断异步操作何时完成。
下面使用for...of循环会一次执行yield命令的德行,提供一种更一般的控制流程管理的方式。
let step = [step1Func, setp2Func, setp3Fund]; function* iterateSteps () { for (var i = 0; i < step.length; i++) { var step = step[i]; yield step(); } }
上面代码中,数组steps封装了一个任务的多个步骤,Generator函数iterateSteps则是一次为这些步骤添加上yield命令。
将任务分解成步骤之后,还可以将项目分解成多个执行的任务。
let jobs = [job1, job2, job3]; function* iterateJobs (jobs) { for (var i = 0; i < jobs.length; i++) { var job = jobs[i]; yield* iterateSteps(job.setps); // 在Generator函数内部调用另外一个Generator函数 } }
上面代码中,数组jobs封装了一个项目的多个任务,Generator函数iterateJobs则以此为这些任务加上yield*命令。
最后,就可以使用for...of循环以此执行所有任务的所有步骤。
for (var setp of iterateJobs(jobs)) { console.log(step.id); }
再次提醒,上面的做法只能用于所有步骤都是同步操作的情况,不能有异步操作的步骤。
for...of本质是wihie循环,所以上面的代码实质上执行的是下面的逻辑。
var it = iterateJobs(jobs); var res = it.next(); while (!res.done) { var result = res.value; res = it.next(); }
5.4.3 部署Iterator接口
利用Generator函数,可以在任意对象上部署Iterator接口。
function* iterEntries (obj) { let keys = Object.keys(obj); for (let i = 0; i < keys.length; i++) { let key = keys[i]; yield [key, obj[key]]; } } let myObj = {foo: 3, bar: 7}; for (let [key, value] of iterEntries(myObj)) { console.log(key, value); } for (let [key, value] of Object.entries(myObj)) { console.log(key, value); } for (let key in myObj) { console.log(key); }
输出结果如下:
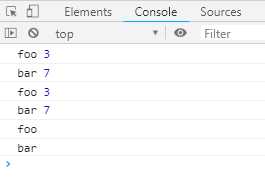
上面代码中,myObj是一个普通对象,通过iterEntries函数,就有了Iterator接口。就是说可以在任意对象上部署next方法。此外还可以使用Object.keys,Object.values,Object.entries,for...in来遍历对象
上述代码中,myObj是一个普通对象,通过iterEntries函数,就有了Iterator接口。也就是说,可以在任意对象上部署next方法。
下面例子是对数组部署Iterator接口的例子,尽管数组原生具有这个接口。
function * makeSimpleGenerator (array) { var nextIndex = 0 while (nextIndex < array.length) { yield array[nextIndex++] } } var gen = makeSimpleGenerator([‘yo‘, ‘ya‘]) console.log(gen.next()) console.log(gen.next()) console.log(gen.next()) console.log(gen.next())
执行结果如下:
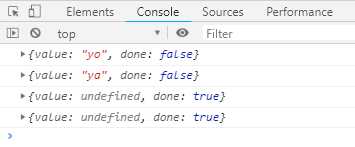
5.4.4 作为数据解构
Generator可以看做是一个数据结果,更确切的说,可以看做一个数组解构,因为Generator函数可以返回一系列的值,这意味着它可以对任意表达式,提供类似数组的接口。
function* doStuff () { yield fs.readFile.bind(null, ‘hello.txt‘); yield fs.readFile.bind(null, ‘world.txt‘); yield fs.readFile.bind(null, ‘and-such.txt‘); } for (task of doStuff()) { // task是一个函数,可以像回调函数那样使用它。 }
上面代码就是一次返回三个函数,但是由于使用了Generator函数,导致可以像处理数组那样,处理这三个返回的函数。
实际上,如果用ES5表达,完全可以使用数组模拟Generator的这种用法。
function doStuff () { return [ fs.readFile.bind(null, ‘hello.txt‘), fs.readFile.bind(null, ‘world.txt‘), fs.readFile.bind(null, ‘and-such.txt‘) ] }
上面的函数,可以用一模一样的for...of循环处理。比较一下可以看出Generator是的数组或者操作,具备了类似数组的接口。
6. 异步编程
6.1 概念
异步
异步编程在JavaScript语言中很重要。JavaScript语言的执行环境是“单线程的”的,如果没有异步编程,难以想象。
ES6之前,异步编程的方法,大概是4种:回调函数,事件监听,订阅/发布,Promise对象。Generator函数将JavaScript异步编程带入一个全新的阶段。
所谓“异步”,简单的说就是一个任务不是连续完成的,可以理解为任务被认为地分成两段,先执行第一段,然后转而执行其他的任务,等做好准备,再回头执行第二段。
比如,有一个任务是读取文件进行处理,任务的第一段向是操作系统发出请求,要求读取文件。然后执行其他任务,等到操作系统返回文件,再接着执行第二段(处理文件)。这种不连续的执行,就叫异步执行。
相应的,连续的执行就叫同步。由于是连续执行,不能插入其他任务,所以操作系统从硬盘读取文件的这段时间,程序只能干等着。
回调函数
JavaScript语言对异步编程的实现,就是回调函数。所谓回调函数,就是把任务的第二段单独写在一个函数里,等到重新执行这个任务的时候,就直接调用这个函数。回调函数的英文名字是callback,是“重新调用”的意思。
读取文件进行处理,是这样的:
s.readFile(‘/etc/passwd‘, ‘utf-8‘, function (err, data) { if (err) throw err; console.log(data); });
上面代码中,readFile函数的第三个参数,就是回调函数,也就是任务的第二阶段。等到操作系统返回了/etc/passwd这个文件之后,回调函数才会执行。
一个有趣的问题是,为什么Node约定,回调函数的参数里,必须要有一个错误对象err(如果没有错误,这个参数是null)?
原因是执行分成两段,第一段执行完成后,任务所在的上下文环境就已经结束了。在这以后抛出的错误,原来的上下文环境已经无法捕捉,只能当做参数,传入第二段。
Promise
回调函数本身并没有问题,它的问题出在多个回调函数嵌套。假设读取A文件之后,再读取B文件,代码如下:
fs.readFile(fileA, ‘utf-8‘, function (err, data) { fs.readFile(fileB, ‘utf-8‘, function (err, data) { // ... }); });
如果依次读取两个以上的文件,就会出现多重嵌套。代码不是纵向发展,而是横向发展,很快就会挤成一团,无法阅读。因为多个异步操作构成了强耦合,只要有一个操作需要修改,它的上层回调函数和下层回调函数,可能就要跟着修改,这种情况被称为“回调函数地狱”。
Promise对象就是为了解决这个问题而被提出的。它不是新的语法功能,而是一种新的写法,允许将回调函数的嵌套,改成链式调用。采用Promise,连续读取多个文件的写法如下:
var readFile = require(‘fs-readfile-promise‘); readFile(fileA) .then(function (data) { console.log(data.toString()); }) .then(function () { return readFile(fileB); }) .then(function (data) { console.log(data.toString()); }) .catch(function (err) { console.log(err); });
上面代码中,使用了fs-readfile-promise模块,它的作用就是返回一个Promise版本的readFile函数。Promise提供then方法加载回调函数,catch方法捕捉执行过程中抛出的错误。
可以看到,Promise的写法只是回调函数的改进,使用then方法以后,异步任务的两段执行看着更清楚了,除此之外,并无新意。
Promise有一个问题是代码冗余,原来的任务被Promise包装了一下,不管怎么操作,看上去的一堆then方法,原来的语义变得很不清楚了。
7. Generator函数处理异步
协程
传统的编程语言,早有异步编程的解决方案(多任务解决方案)。其中有一种叫“协程(coroutine)”,意思是:多个线程协作完成任务。协程有点像函数,又有点像线程。它的运行流程如下:
第一步:协程A开始执行
第二步:协程A执行到一半,进入暂停状态,执行权交转移到协程B
第三步:(一段时间后)协程B交换执行权
第四步:协程B恢复执行
举例来说,读取文件的协程写法如下:
function* asyncJob() { // ...其他代码 var f = yield readFile(fileA); // ...其他代码 }
上面代码中asyncJob是一个协程,它的关键就在yield表达式。yield命令表示执行到此处,将执行权交给其他的协程。也就是说,yield命令是异步任务的两个阶段的分界线。协程遇到yield命令就暂停,等到执行权返回,再从暂停的地方继续往后执行。它的最大的优点,就是代码的写法非常像同步操作,如果去除yield命令,就是一模一样的。
协程的Generator函数实现
Generator函数是协程在ES6的实现,最大特点就是可以交出函数的执行权(暂停执行)。整个Generator函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用yield表达式注明。Generator函数的执行方法如下:
function* gen (x) { var y = yield x + 2; return y; } var g = gen(1); // 调用Generator函数,传入参数1,返回指针 console.log(g.next()); // 移动指针,直至遇到yield表达式,返回{value: 3, done: false} console.log(g.next(2)); // 移动指针,传入参数2,作为上一次yield表达式的返回值,赋给y,返回{value: 2, done: true} console.log(g.next(2)); // 返回{value: undefined, done: true}
执行结果如下:
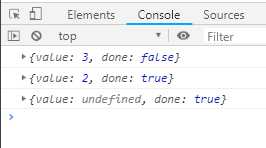
1. 定义Generator函数gen,function后面有星花“*”,内部有yield表达式
2. 调用Generator,传入参数1,返回一个内部状态的指针对象g
3. 第一次调用Generator对象g的next方法,Generator函数开始执行,知道遇到第一个yield表达式,返回yield表达式的值value是3,当前状态done的值false
4. 第二次调用Generator对象g的next方法,Generator函数从上次yield表达式停下的地方往下执行,遇到return语句,返回return表达式的值value是2(传入参数的值是2,上次yield表达式的值就是2,而不是x + 2 = 3)
5. 第三次调用Generator对象g的next方法,Generator函数上内上次执行的是return语句,不会再往下执行,返回yield表达式的值value是undefined,当前状态是done不变
上面代码中,调用Generator函数,会返回一个内部指针(即遍历器)g。这是Generator函数不同于普通函数的,即执行它不会返回内部语句的return语句的结果,而是一个内部状态的指针对象。调用指针g的next方法,会移动内部指针(即执行异步任务的第一阶段),执行内部语句,只到遇到第一个yield语句,上面是x + 2。
next方法的作用是分阶段执行Generator函数。每次调用next方法,会返回一个对象,表示当前阶段的信息(value属性和done属性)。value属性是yield语句后面表达式的值,表示当前阶段的值;done属性是一个布尔值,表示Generator函数是否执行完毕,即是否还有下一个阶段。
Generator函数的数据交换和错误处理
Generator函数可以暂停执行和恢复执行,这是它能封装异步任务的根本原因。此外,它还有两个特性是它可以作为异步编程的完整解决方案:函数内外的数据交换和错误处理机制。
next返回值的value属性,是Generator函数向外部输出的数据,next方法还可以接受参数,向Generator函数体内输入数据。
function* gen(x){ var y = yield x + 2; return y; } var g = gen(1); g.next() // { value: 3, done: false } g.next(2) // { value: 2, done: true }
上面代码中,第一个next方法的value属性,返回表达式x + 2的值3。第二个next方法带有参数2,这个参数可以传入Generator函数内部,作为上颚阶段任务的返回结果,被函数体内部的变量y接收。因此,这一步的value属性,返回的就是2(变量y的值) 。
Generator函数内部还可以部署错误处理代码,不做函数体外抛出的错误。
function* gen (x) { try { var y = yield x + 2; } catch (e) { console.log(e); } return y; } var g = gen(1); // 调用Generator函数,传入参数1,返回指针 console.log(g.next()); // 指针移动,直至遇到yield表达式,返回value:3, done:false, 这是因为后面还有一个return console.log(g.throw(‘出错了!!!!‘)); // {value: undefined, done: true} 使用指针对象的throw方法抛出错误,在函数体内被catch捕获并传递错误信息,输出错误信息,返回done:true,没有value属性 console.log(g.next()) // {value: undefined, done: true}
执行结果如下:
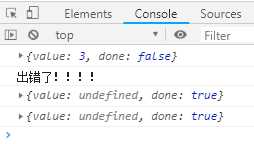
1. 定义Generator函数,function后面有星花,函数内部有yield表达式
2. 调用Generator函数gen,返回指向内部状态的指针对象g
3. 第一次调用对象g的next方法,指针移动,只到执行到第一个yield表达式,返回{value: 3, done: false}
4. 调用对象g的throw方法,抛出错误,函数内部的try...catch捕获错误,输出错误,返回结果{value: undefined, done: true}。
5. 第二次调用对象g的next方法,输出{value: undefined, done: true}
上面代码在Generator函数体外,使用指针对象的throw方法抛出的错误,可以被函数体内的try...catch代码块捕获。这意味着,出错的代码与处理错误的代码分离开了,这对异步编程很重要。
异步任务的封装
看下面的代码如何使用Generator函数执行一个异步任务
var fetch = require(‘node-fetch‘); function* gen () { var url = ‘https://api.github.com/users/github‘; var result = yield fetch(url); console.log(result); } var g = gen(); // 执行Generator函数,获取指针 var result = g.next(); // 移动指针,执行函数,直至遇到yield表达式fetch(url),它执行的是异步操作 result.value.then(function (data) { // fetch返回的是一个Promise对象,因此要用then方法调用下一个next方法 console.log(data) }).then(function (data) { g.next(); })
上面代码中,Generator函数封装了一个异步操作,该操作先读取一个远程接口,然后从JSON格式的数据分析信息。执行Generator函数之前,先获取遍历对象,然后用next方法执行,执行异步任务的第一阶段。由于Fetch模块返回的是一个Promise兑现给,因此要用then方法调用下一个next方法。
Thunk
Thunk函数是自动执行Generator函数的一种方法。Thunk函数在变成语言刚刚起步的时候被提出,即求之策略,函数的参数到底应该在什么时候求值。
Thunk函数的含义
编译器的“传名调用”实现,往往是将参数放到一个临时函数中,再将这个临时函数传入函数体。这个临时函数就叫做 Thunk函数。
let x = 1;
function f(m) {
return m * 2;
}
console.log(f(x + 5));
// 等同于
let x = 1;
var thunk = function () {
return x + 5;
}
function f(thunk) {
return thunk() * 2;
}
console.log(f(thunk))
输出结果如下:
上面的代码中,先定义函数f,调用函数的时候传入表达式x + 5,那这个参数什么时候替换成6呢?一种方式是“传值调用” ,即在进入函数体之前,就计算x + 5的值(等于6),再将值传入函数f。C语言就是采用这种方式。
另一种是“传名调用”,即将表达式x + 5传入函数体,只在用到它的时候求值。Haskell语言采用这种策略。
两种方式哪一种更好呢?回答是各有利弊。传值调用比较简单,但是对参数求值的时候还没有用到这个参数,可能造成性能损失。
编译器的“传名调用”实现,往往是将参数放到一个临时函数之中,再将这个临时函数传入函数体。这个临时函数就叫做“Thunk函数”。
JavaScript语言中的Thunk函数
JavaScript语言是传值调用,它的Thunk函数含义所有不同。在JavaScript语言中Thunk函数替换的不是表达式,而是多参数函数,将其替换成一个只接受回调函数作为参数的单参数函数。
// 正常版本的readFile(多参数版本) fs.readFile(fileName, callback); // Thunk版本的readFile(单参数版本) var Thunk = function (fileName) { return function (callback) { return fs.readFile(fileName, callback) } } var readFileThunk = Thunk(fileName); readFileThunk();
上面代码中,fs模块的readFile方法是一个多参数函数,两个参数分别为文件名和回调函数。经过转换器处理,它变成一个单参数函数,只接受回调函数作为参数。这个单参数版本,就叫做Thunk函数。
任何函数,只要参数有回调函数,就能够改写成Thunk函数的形式。下面是个Thunk函数转换器。
//ES5版本 var Thunk = function (fn) { return function () { var args = Array.prototype.slice.call(arguments); // 使用call方法改变slice函数运行上下文,arguments虽然不是数组 return function (callback) { args.push(callback); return fn.apply(this, args); } } } //ES6版本 const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); } } }
ES5版本
1. 定义Thunk函数,传入参数fn
2. Thunk函数体内返回一个函数对象
3. 在函数内,使用Array.property.slice.call方法获取外层函数的参数,返回数组,放在args中
4. 在函数内,再返回一个函数,把callback放在参数数组args的末尾
5. 最后在参数上使用apply方法调用,上下文环境为当前Thunk对象,传入参数为数组args
ES6版本
1. 定义Thunk函数,传入参数fn
2. Thunk函数体内返回一个函数对象,参数使用扩展运算符...将参数args转为都好分割的参数序列
3. 在函数体内,再返回一个函数,传入参数为callback
4. 最后使用call方法,在当前对象上调用fn方法,传入参数为args分隔号的参数序列和callback
下面是一个完整的例子
function f (a, cb) { cb(a); } const ft = Thunk(f); ft(1)(console.log) // 输出1
1. 定义一个有两个参数的函数f,第二个参数是回调函数,在函数体内调用回调函数并传入第一个参数
2. 调用Thunk转换器,传入参数f,f被转换成Thunk函数ft
3. 调用ft,传入参数1,返回的是内部函数,再传入参数console.log,最后在1上执行console.log(1),输出1
这里用语言很难组织起来,只能揣摩。
Thunkify模块
在生产环境,可以使用Thunkify模块,使用命令npm install thunkify安装Thunkify模块。使用方式如下:
var thunkify = require(‘thunkify‘); var fs = require(‘fs‘); var read = thunkify(fs.readFile); read(‘package.json‘)(function (err, str) { // 回调函数的函数体 })
Thunkif的源码和上面的转换很像
function thunkify (fn) { return function () { var args = new Array(arguments.length); var ctx = this; for (var i = 0; i < args.length; ++i) { args[i] = arguments[i]; } return function (done) { var called; args.push(function () { if (called) return; called = true; done.apply(null, arguments); }); try { fn.apply(ctx, args); } catch (err) { done(err); } } } };
在代码里多了一个检查机制,变量called确保回调函数只运行一次。这样设计与下文的Generator函数相关。
function f (a, b, callback) { var sum = a + b; callback(sum); callback(sum); } var ft = thunkify(f); var print = console.log.bind(console); ft(1, 2)(print); // 输出3
上面代码中,由于thunkify值允许回到函数执行一次,所以只输出一行结果。
Generator函数的流程管理
Thunk函数哟有什么用呢? 只是为了减少参数吗?在ES6中有了Generator函数,Thunk函数可以用于Generator函数的自动流程管理。Generator函数可以自动执行。
function* gen() { // ... } var g = gen(); var res = g.next(); while(!res.done){ console.log(res.value); res = g.next(); }
上面代码中,Generator函数gen会自动执行完所有步骤。
但是这不适合异步操作。如果必须保证前一步执行完,才能执行后一步,上面的自动执行就不可取。这时Thunk函数就能排上用场。以读取文件为例,下面的Generator函数封装了两个异步操作。
var fs = require(‘fs‘); var thunkify = require(‘thunkify‘); var readFileThunk = thunkify(fs.readFile); var gen = function* () { var r1 = yield readFileThunk(‘/etc/fstab‘); console.log(r1.toString()); var r2 = yield readFileThunk(‘/etc/shells‘); console.log(r2.toString()); } var g = gen(); var r1 = g.next(); r1.value(function (err, data) { if (err) throw err; var r2 = g.next(data); r2.value(function (err, data) { if (err) throw err; g.next(data); }) })
上面代码中,使用yield命令将程序的执行权移除Generator函数,那么就需要一种方法再将执行权交还给Generator函数。手动执行指针对象g是Generator函数的内部指针,表示目前执行到哪一步。next方法负责将指针移动到下一步,并返回当前这一步的信息(即yield表达式的值,包含value属性和done属性)。这里的自动执行步骤其实是返回调用g.next()方法。下面我们将探讨如何用Thunk函数调用Generator函数自动执行。
function run(fn) { var gen = fn(); function next(err, data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } function *g () { yield 1; yield 2; return 3; } run(g)
上面代码的run函数,就是一个 Generator 函数的自动执行器。内部的next函数就是 Thunk 的回调函数。next函数先将指针移到 Generator 函数的下一步(gen.next方法),然后判断 Generator 函数是否结束(result.done属性),如果没结束,就将next函数再传入 Thunk 函数(result.value属性),否则就直接退出。
有了这个执行器,执行 Generator 函数方便多了。不管内部有多少个异步操作,直接把 Generator 函数传入run函数即可。当然,前提是每一个异步操作,都要是 Thunk 函数,也就是说,跟在yield命令后面的必须是 Thunk 函数。
var g = function* () { var f1 = yield readFileThunk(‘fileA‘); var f2 = yield readFileThunk(‘fileB‘); var fn = yield readFileThunk(‘fileN‘); }; run(g);
上面代码中,函数g封装了n个异步读取文件操作,只要执行run函数,这些操作就会自动完成。这样异步操作不仅可以写的像同步函数,二期一行代码就可以执行。
Thunk函数不是Generator函数自动执行的唯一方法。自动执行的关键是,必须有一种机制,自动控制Generator函数的流程,接收和交还陈旭的执行权。回调函数可以做这一点,Promise也可以做到。
co模块
co模块是著名程序员TJ Holowaychuk于2013年6月发布的一个小工具,用于Generator函数的自动执行。
下面是一个Generator函数,用于以此读取两个文件。
var readFile = require(‘fs-readfile-promise‘); var gen = function *() { var f1 = yield readFile(‘./a.txt‘); var f2 = yield readFile(‘./b.txt‘); console.log(f1); console.log(f2); } var co = require(‘co‘); co(gen).then(function () { console.log(‘Generator函数执行完成‘) });
结果如下
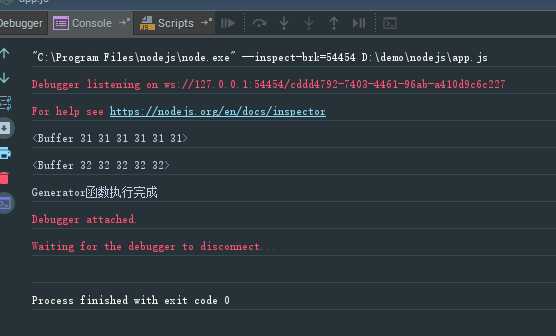
注:这里是在node.js环境下才能执行,在html页面中不能执行上面的代码。
上面代码中,Generator函数只要传入co函数中,就会自动执行。co函数返回一个Promise对象,因此可以用then方法添加回调函数。
co模块的原理
co为什么可以自动执行Generator函数呢?前面说过,Generator函数就是一个异步操作的容器。它的自动呢执行需要一种机制,当异步操作有了结果,就能自动交会执行权。
有两种该方法可以做到这一点
(1) 回调函数,将异步操作包装成Thunk函数,在回调函数里交回执行权。
(2) Promise对象,将异步操作包装秤Promise对象,用then方法交回执行权。
co模块其实就是将两种自动执行器(Thunk函数和Promise对象),包装成一个模块。使用co的前提条件是,Generator函数的yield命令后面,一定是Thunk函数或者Promise对象。如果数组或对象的成员,全部都是Promise对象,也可以使用co。
基于Promise对象的自动执行
上面介绍了Thunk函数的自动执行器,下面来看基于Promise对象的自动执行器,这是理解co模块必须的。继续使用上面的例子。首先把fs模块的readFile方法包装成一个Promise对象。
var fs = require(‘fs‘); var readFile = function (fileName) { return new Promise(function (resolve, reject) { fs.readFile(fileName, function (error, data) { if (error) return reject(error); resolve(data); }) }) } var gen = function *() { var f1 = yield readFile(‘./a.txt‘); var f2 = yield readFile(‘./b.txt‘); console.log(f1.toString()) console.log(f2.toString()) }; var g = gen(); g.next().value.then(function (data) { g.next(data).value.then(function (data) { g.next(data) }) })
上面代码中手动执行Generator函数,执行结果如下:
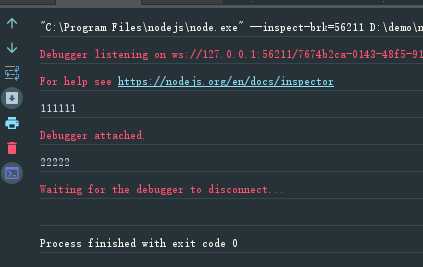
手动执行其实就是用then方法,层层添加回调函数。知道这一点就可以写一个自动执行器。
function run(gen) { var g = gen(); function next(data) { var result = g.next(data); if (result.done) return result.value; result.value.then(function (data) { next(data); }); } next(); } run(gen);
执行结果和上面是一样的。上面代码中,只要Generator函数还没有执行到最后一步,next函数就调用自身,以此实现自动执行。
co模块的源码
co就是上面的自动执行器的扩展,它的源代码不多,只有几十行,很简单。首先,co函数接受Generator函数作为参数,返回一个Promise对象。
function co(gen) { var ctx = this; return new Promise(function (resolve, reject) { }); }
在返回的Promise对象里面,co先检查参数gen是否为Generator函数。如果是就执行该函数,得到一个内部指针对象,如果不是就返回,并将Promise对象的状态改为resolved。如下:
function co(gen) { var ctx = this; return new Promise(function(resolve, reject) { if (typeof gen === ‘function‘) gen = gen.call(ctx); if (!gen || typeof gen.next !== ‘function‘) return resolve(gen); }); }
接着,co将Generator函数的内部指针对象的next方法,包装成onFulfilled函数。这主要是为了能够捕捉抛出的错误。
function co(gen) { var ctx = this; return new Promise(function(resolve, reject) { if (typeof gen === ‘function‘) gen = gen.call(ctx); if (!gen || typeof gen.next !== ‘function‘) return resolve(gen); onFulfilled(); function onFulfilled(res) { var ret; try { ret = gen.next(res); } catch (e) { return reject(e); } next(ret); } }); }
最后,就是关键的next函数,它会反复调动自己。
function next(ret) { if (ret.done) return resolve(ret.value); var value = toPromise.call(ctx, ret.value); if (value && isPromise(value)) return value.then(onFulfilled, onRejected); return onRejected( new TypeError( ‘You may only yield a function, promise, generator, array, or object, ‘ + ‘but the following object was passed: "‘ + String(ret.value) + ‘"‘ ) ); }
上面的next函数,内部一共只有四行命令:
1. 根据ret的done属性检查当前是否为Generator函数的最后一步,如果是就返回。
2. 确保每一步的返回值,都是Promise对象。
3. 使用then方法,为返回值加上回调函数,然后通过onFulfilled函数再次调用next函数。
4. 在参数不符合要求的情况下(参数非Thunk函数和Promise对象),将Promise对象的状态改为rejected,从而终止执行。
处理并发的异步操作
co支持并发的异步操作,即允许某些操作同时进行,等到他们全部完成,才进行下一步。要把并发的操作都放在数组对象里面,跟在yield语句后面。
// 数组的写法 co(function* () { var res = yield [ Promise.resolve(1), Promise.resolve(2) ]; console.log(res); }).catch(onerror); // 对象的写法 co(function* () { var res = yield { 1: Promise.resolve(1), 2: Promise.resolve(2), }; console.log(res); }).catch(onerror);
下面是另一个例子
co(function* () { var values = [n1, n2, n3]; yield values.map(somethingAsync); }); function* somethingAsync(x) { // do something async return y }
上面的代码,允许并发三个somethingAsync异步操作,等到他们全部完成,才会进行下一步。
处理Stream
Node提供Stream(流媒体)模式读写数据,特点是一次只处理数据的一部分,数据分成一块块以此处理,就像“数据流”一样。这样对于处理大规模数据非常有利。Steam模式使用EventEmitter API,会释放三个事件:
data事件:下一块数据已经准备好了。
end事件:整个“数据流”处理完了。
error事件:发生错误。
使用Promise.race()函数,可以判断这三个事件之一谁先发生,只有当data事件最先发生时,才进入下一个数据块的处理。从而我们可以通过一个while循环,完成所有数据的读取。
const co = require(‘co‘); const fs = require(‘fs‘); const stream = fs.createReadStream(‘./Les_Miserables.txt‘); let valjeanCount = 0; co(function *() { while (true) { const res = yield Promise.race([ new Promise(resolve => stream.once(‘data‘, resolve)), new Promise(resolve => stream.once(‘end‘, resolve)), new Promise((resolve, reject) => stream.once(‘error‘, reject)) ]); if (!res) { break; } stream.removeAllListeners(‘data‘); stream.removeAllListeners(‘end‘); stream.removeAllListeners(‘error‘); valjeanCount += (res.toString().match(/valjean/ig) || []).length; } console.log(‘count:‘, valjeanCount) });
执行结果如下:
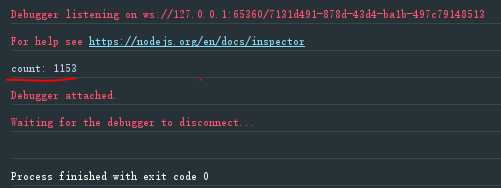
上面代码采用Stream模式读取Les_Miserables.txt这个文件,对于每个数据块都用stream.once方法,在data,end,error三个事件上添加一次性回调函数。变量res只有在data事件发生时才有值,然后累加每个数据块之中“valjean”这个单词,可以看到Les_Miserables.text这个文件中“valjean”这个单词一共出现了1153次。
8. async函数
8.1 含义
ES2017标准中引入了async函数,使得异步操作变得更加方便。async是Generator函数的语法糖。下面有一个Generator函数,一次读取两个文件。
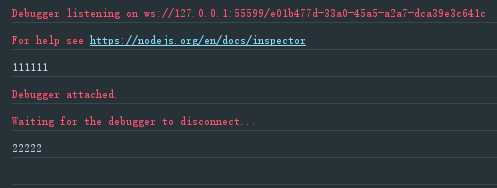
/** * Generator函数,依次读取两个文件 */ const fs = require(‘fs‘); const readFile = function (fileName) { return new Promise(function (resolve, reject) { fs.readFile(fileName, function (error, data) { if (error) return reject(error) resolve(data) }) }) } const gen = function *() { const f1 = yield readFile(‘./a.txt‘) const f2 = yield readFile(‘./b.txt‘) console.log(f1.toString()) console.log(f2.toString()) } function run(gen) { var g = gen(); function next(data) { var result = g.next(data); if (result.done) return result.value; result.value.then(function (data) { next(data); }); } next(); } run(gen)
读取结果如下:
改写成async函数,如下:
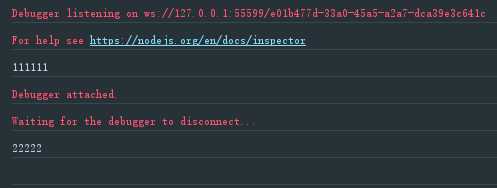
const fs = require(‘fs‘); const readFile = function (fileName) { return new Promise(function (resolve, reject) { fs.readFile(fileName, function (error, data) { if (error) return reject(error) resolve(data) }) }) } /** * async函数实现读取两个文件 * @returns {Promise<void>} */ const asyncReadFile = async function () { const f1 = await readFile(‘./a.txt‘) const f2 = await readFile(‘./b.txt‘) console.log(f1.toString()) console.log(f2.toString()) } asyncReadFile()
执行结果如下:
他们执行的结果是一样的,比较一下可以看出,async函数就是将Generator函数的星号(*)替换成async并放在function关键字的前面,函数体内用await代替了yield关键字,仅此而已。async函数对Generator函数的改进有四点:
(1)内置执行器
Generator函数的执行必须依靠执行器,所以才有了co模块,而async函数自带执行器。也就是说async函数的执行,和普通函数一样,只要调用就好,只要一行。上面代码中asyncReadFile()这一句就可以自动执行async函数。这完全不像Generator函数,需要调用next方法,或者co模块,才能真正执行,得到最后结果。
(2)更好的语义
async和await,比起星号和yield,语义更加清楚了。async表示函数里有异步操作,await表示紧跟在后边的表达式需要等待结果。
(3)更广的适用性
co模块约定,yield命令后面只能是Thunk函数或者Promise对象,而async函数的await命令后面,可以使Promise对象和原始的类型的值(数值,字符串,布尔值,但是这是等同于同步操作)
(4)返回的是Promise
async函数返回的是Promise对象,这比Generator函数的返回值是Iterator对象方便多了。可以用then方法指定下一步操作。
进一步说,async函数完全可以看做是多个异步操作,包装秤一个Promise对象,而await命令就是内部then命令的语法糖。
8.2 基本用法
async函数返回一个Promsie对象(嗯嗯,都是返回Promise对象),可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
下面是一个例子:
async function getStockPriceByName(name) { var symbol = await getStockSymbol(name); var stockPrice = await getStockPrice(symbol); return stockPrice; } getStockPriceByName(‘goog‘).then(function (result) { console.log(result); });
上面代码是一个获取股票的函数,函数前面的async关键字表示这个函数内部有异步操作。调用该函数时,会立即返回一个Promise对象。
下面是另外一个例子,指定多少毫秒之后输出一个值。
function timeout(ms) { return new Promise((resolve) => { setTimeout(resolve, ms); }) } async function asyncPrint(value, ms) { await timeout(ms); console.log(value) } asyncPrint(‘hello world‘, 50);
1. 定义timeout函数,返回一个Promise对象,在ms毫秒之后返回Promise对象的fullfiled状态
2. 定义一个async(Generator)函数,async相当于星花,await相当于yield表达式,await表达式后面调用timeout函数,传入参数ms
3. 调用async函数,传入两个参数“hello world”, 50
4. 调用async函数,遇到await表达式,执行后面的timeout方法,传入参数ms;timeout方法返回一个Promise对象,指定ms毫秒之后执行resolve,将Promise对象的状态修改为resolved
5. async方法中侦测到timeout方法执行完毕,执行后面的console.log方法,输出“hello world”
由于async函数返回的是Promise对象,可以作为await命令的参数。所以上面的代码也可以写成下面的形式
async function timeout(ms) { await new Promise((resolve) => { setTimeout(resolve, ms); }); } async function asyncPrint(value, ms) { await timeout(ms); console.log(value); } asyncPrint(‘hello world‘, 50);
1. 定义async(Generator)方法,async相当于Generator中的星花
async函数有多种使用形式
// 函数声明 async function foo() { } // 函数表达式 const foo = async function () { } // 对象的方法 let obj = {async foo()}; obj.foo().then(); // class的方法 class Storage { constructor() { this.cachePromise = caches.open(‘avatars‘); } async getAvatar(name) { const cache = await this.cachePromise; return cache.match(`/avatars/${name}.jpg`) } } const storage = new Storage(); storage.getAvatar(‘jake‘).then(...) // 箭头函数 const foo = async () => {}
8.3 语法
返回Promise对象
async函数返回一个Promise对象。async函数内部return语句返回的值(done属性为false时,value的值),会成为then方法回调函数的参数。
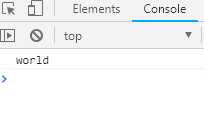
async function f() { await ‘hello‘ return ‘world‘ } f().then(v => console.log(v))
1. 定义async(Generator)函数,async相当于星花,await相当于yield表达式
输出结果如下:
上面代码中,函数f内部return命令的返回值,会被then方法回调函数接收到。
async函数内部冒出的错误,会导致返回的Promise对象为reject状态。抛出的错误对象会被catch方法回调函数接收到。
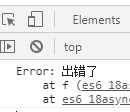
async function f() { throw new Error(‘出错了‘) } f().then( value => console.log(value), error => console.log(error) )
输出结果如下:
Promise对象的状态变化
async函数返回的Promise对象,必须等到内部所有的await命令后面的Promise对象执行完,才会发生状态改变,除非遇到return语句或者抛出错误。也就是说,只有async函数内部的异步操作执行完,才会执行then方法指定的回到函数。这一点和Generator函数是不一样的,Generator函数是调用指针对象的next方法才会往下执行。
下面看一个例子:
async function getTitle (url) { let response = await fetch(url); let html = await response.text(); return html.match(/<title>([\s\S]+)<\/title>/i)[1]; } getTitle(‘https://tc39.github.io/ecma262/‘).then(console.log);
在网页中的执行结果如下:
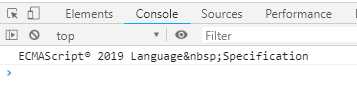
函数getTitle内部有三个操作,抓取网页,取出文本,匹配页面标题。只有这三根操作全部完成才会执行then方法中的console.log。这里then方法中名没有传入参数,但是console.log方法却直接拿到返回值作为getTitle方法的返回值作为参数输出。
await命令
通常,await敏力后面是一个Promise对象,返回该对象的结果。如果不是Promise对象,就直接返回对应的值。
async function f () { return await 123; } f().then(v => console.log(v))
上面代码中,await命令的参数值是123,这等同于return 123
另一种情况,await命令后面是一个thenable对象(即定义then方法的对象),那么await会将其等同于Promise对象。
class Sleep { constructor (timeout) { this.timeout = timeout } then (resolve, reject) { const startTime = Date.now() setTimeout( () => resolve(Date.now() - startTime), this.timeout ) } } (async () => { const actualTime = await new Sleep(1000) console.log(actualTime) })();
输出结果如下:
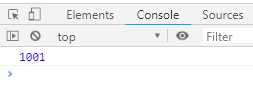
上面代码中,await命令后面是一个Sleep对象的实例。这个实例不是Promise对象,但是因为定义了then方法,await会将其视为Promise处理。
await命令后面的Promise对象如果变成reject状态,则reject的参数会被catch方法的回调函数接收到。
async function f () { await Promise.reject(‘出错了‘) } f().then(v => console.log(v)).catch(e => console.log(e))
注意,上面代码中await语句前面没有return,但是reject方法的参数依然传入了catch方法的回调函数。这里如果在await前面加上return,则效果是一样的。
任何一个await语句后面的Promise对下那个变成reject状态,那么整个async函数都会中断执行。
async function f() { await Promise.reject(‘出错了‘); await Promise.resolve(‘hello world‘); // 不会执行 }
上面代码,第二个await语句时不会执行的,因为第一个await语句变成了reject。下面会介绍处理这个reject状态并继续往下执行的方法。
有时候我们希望及时前一个操作失败,也不要终端后面的异步操作。这时可以将第一个await放在try...catch里面,这样不管这个异步操作是否成功,第二个await都会执行。
async function f () { try { await Promise.reject(‘出错了‘); } catch (e) { } return await Promise.resolve(‘hello world‘); } f().then(v => console.log(v))
执行结果如下:
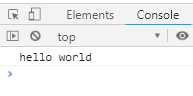
上面代码try代码块中await Promise.reject(‘出错了‘)语句虽然会抛出错误,但是在catch语句块中没有处理,然后继续执行return await Promise.resolve(‘hello world‘),最后输出‘hello world’。
另一种方法是await后面的Promise对象再跟一个catch方法,处理前面可能出现的错误。
async function f () { await Promise.reject(‘出错了‘) .catch(e => console.log(e)); return await Promise.resolve(‘hello world‘); } f().then(v => console.log(v))
输出结果如下:
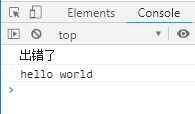
在reject方法后面直接catch方法,处理内部错误。外部的then方法处理正常情况,这样既可以处理内部的错误,也可以处理外部的错误。
错误处理
如果await后面的异步操作出错,那么等同于async函数返回的Promise对象被reject。
async function f () { await new Promise(function (resolve, reject) { throw new Error(‘出错了‘) }) } f().then(v => console.log(v)).catch(e => console.log(e))
执行结果如下:
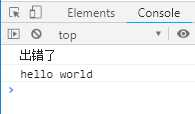
上面代码中,async函数f执行后,await后面的Promise对象会抛出一个错误对象,导致catch方法的回调函数被调用,它的参数就是抛出的错误对象。
防止错误抛出的方法,也是将其放在try...catch代码块中,吃掉错误。
async function f () { try { await new Promise(function (resolve, reject) { throw new Error(‘出错了‘) }) } catch (e) { } return await (‘hello world‘) } f().then(value => console.log(value)).catch(e => console.log(e))
输出结果如下:
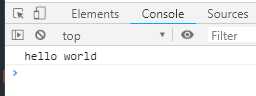
如果有多个await命令,可以统一放在try...catch结构中。
async function main () { try { const val1 = await firstStep(); const val2 = await secondStep(val1); const val3 = await thirdStep(val1, val2); console.log(‘final: ‘ val3); } catch (e) { console.log(e) } }
下面的例子,使用try...catch解构,实现多3次重复尝试。
const superagent = require(‘superagent‘); const NUM_RETRIES = 3; async function test () { let i; for (i = 0; i < NUM_RETRIES; i++) { try { await superagent.get(‘http://google.com/this-throws-an-error‘); break } catch (e) { } } console.log(i) } test();
输出结果如下:
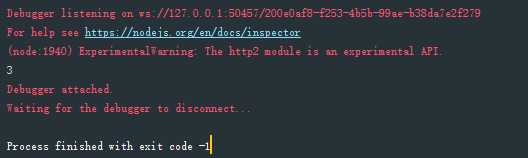
上面代码中,如果await操作成功,就会使用break语句退出循环;否则会被catch语句捕捉,进入下一轮循环。
使用注意点
第一点,前面已经说过,await命令后面的Promise对象,运行结果可能是rejected,所以最好把await命令放在try...catche代码块中。
async function myFunction() { try { await somethingThatReturnsAPromise(); } catch (err) { console.log(err); } } // 另一种写法 async function myFunction() { await somethingThatReturnsAPromise() .catch(function (err) { console.log(err); }); }
第二点,多个await命令后面的异步操作,如果不存在继发关系,最好让他们同时触发。
let foo = await getFoo();
let bar = await getBar();
上面代码中,getFoo,getBar是连个独立的异步操作(相互不依赖),被写成继发关系。这样比较耗时,因为只有getFoo完成以后,才会执行getBar,完全可以让他们同时触发。
let foo = await getFoo(); let bar = await getBar(); // 写法一 let [foo, bar] = await Promise.all([getFoo(), getBar()]); // 写法二,异步方法同步执行 let fooPromise = getFoo(); let barPromise = getBar(); let foo = await fooPromise; let bar = await barPromise;
第三点, await命令只能用在async函数中,如果用在普通函数中,就会报错。
async function dbFuc(db) { let docs = [{}, {}, {}]; // 报错 docs.forEach(function (doc) { await db.post(doc); }); }
上面代码会报错,因为await用在普通函数中。但是如果将forEach方法的参数改成async也是有问题的。
function dbFuc(db) { //这里不需要 async let docs = [{}, {}, {}]; // 可能得到错误结果 docs.forEach(async function (doc) { await db.post(doc); }); }
上面代码不会正常工作,原因是这时三个db.post操作是并发执行的,也是同步执行,而不是继发执行。正确的写法是使用for...of循环。
async function dbFuc(db) { let docs = [{}, {}, {}]; for (let doc of docs) { await db.post(doc); } }
如果确实希望多个请求并发执行,可以使用Promise.all方法。当三个请求都会resolved的时候,下面的两种写法效果相同。
async function dbFuc(db) { let docs = [{}, {}, {}]; let promises = docs.map((doc) => db.post(doc)); let results = await Promise.all(promises); console.log(results); } // 或者使用下面的写法 async function dbFuc(db) { let docs = [{}, {}, {}]; let promises = docs.map((doc) => db.post(doc)); let results = []; for (let promise of promises) { results.push(await promise); } console.log(results); }
目前,esm模块加载器支持顶层await,即await命令可以不放在async函数里面,直接使用。
// async 函数的写法 const start = async () => { const res = await fetch(‘google.com‘); return res.text(); }; start().then(console.log); // 顶层 await 的写法 const res = await fetch(‘google.com‘); console.log(await res.text());
上面代码中,第二种写法的脚本必须使用esm加载器,才会生效。
第四点,async函数可以保留运行堆栈。
const a = () => { b().then(() => c()); };
上面代码中给,函数a内部运行了一个异步任务b()。当b()运行的时候,函数a()不会中断,而是继续执行。等到b()运行结束,可能a()早已经云心刚结束了。b()所在的上下文环境已经消失。如果b()或者c()报错,错误堆栈将不包括a().
将这个例子改造一下如下:
const a = async () => {
await b();
c();
};
上面代码中,b()运行的时候,a()是暂停执行,上下文环境保存着,一旦b()或c()报错,错误堆栈将包括a()。
8.4 async函数的实现原理
async函数的实现原理,就是将Generator函数和自动执行器,包装在一个函数里。
async function fn(args) { // ... } // 等同于 function fn(args) { return spawn(function* () { // ... }); }
所有的async函数都可以写成上面的第二种形式,其中的spawn函数就是自动执行器。下面给出spaw函数的实现,基本就是前文自动执行器的翻版。
function spawn (genF) { return new Promise(function (resolve, reject) { const gen = genF() function step (nextF) { let next; try { newxt = nextF() } catch (e) { return reject(e) } if (next.done) { return resolve(next.value) } Promise.resolve(next.value).then(function (v) { step(function () { return gen.next(v) }) }, function (e) { step(function () { return gen.throw(e) }) }) } step(function () { return gen.next(undefined) }) }) }
8.5 与其他异步处理方法的比较
我们通过一个例子来看看async与Promise,Generator函数的比较。
首先是Promise的写法:
function chainAnimationsPromise (elem, animations) { // 变量ret用来保存上一个动画的返回值 let ret = null // 新建一个空的Promise let p = Promise.resolve() // 使用then方法,添加所有动画 for (let anim of animations) { p = p.then(function (val) { ret = val return anim(elem) }) } // 返回一个部署了错误捕捉机制的Promise return p.catch(function (e) { // 忽略错误,继续执行 }).then(function () { return ret }) }
虽然Promise的写法比回调函数的写法大大改进,但是一眼看上去,代码完全都是Promise的API(then,catch),操作本身的语义反而不容易看出来。
接着是Generator函数的写法。
function chainAnimationsGenerator (elem, animations) { return spawn(function *() { let ret = null try { for (let anim of animations) { ret = yield anim(elem) } } catch (e) { // } return ret }) }
上面代码使用Generator函数遍历了每个动画,语义比Promise写法更加清晰,用户定义的操作全部都出现在spawn函数的内部。这个写法问题在于,必须有一个任务运行器,自动执行Generator函数,上面代码中spawn函数就是自动执行器,它返回一个Promise对象,而且必须保证yield语句后面的表达式,必须返回一个Promise。
最后是yield函数的写法。
async function chianAnimationsAsync(elem, animations) { let ret = null try { for (let anim of animations) { ret = await anim(elem) } } catch (e) { // 忽略错误,继续执行 } return ret }
可以看到async函数的实现最简洁,最符合语义,几乎没有语义不想管的代码。它将Generator写法中的的自动执行器,改在语言层面提供,不暴露给用户,因此代码量最少。如果使用Generator写法,自动执行器需要用户自己提供。
8.6 按顺序完成异步操作
实际开发中,经常遇到一组异步操作,需要按顺序执行。比如读取一组URL地址,然后按照读取顺序输出结果。
Promise的写法如下:
function logInOrder (urls) { // 远程读取所有的URL const textPromises = urls.map(url => { return fetch(url).then(response => response.text()) }) // 按次序输出 textPromises.reduce((chain, textPromise) => { return chain.then(() => textPromise).then(text => console.log(text)) }, Promise.resolve()) }
上面代码使用fetch方法,同时远程读取一组URL。每个fetch操作都返回一个Promise对象,放入textPromises数组。然后,reduce方法一次处理每个Promise对象,放入textPromise数组。然后,reduce方法一次处理每个Promise对象,然后使用then,将所有Promise对象连接起来,因此就可以以此输出结果。
这种写法不直观,还要使用数组对象的reduce方法,可读性比较差,下面是async函数的实现。
async function logInOrder (urls) { for (let url of urls) { const response = await fetch(url) console.log(await response.text()) } }
上面代码大大简化,问题是所有的远程操作都是继发。只有前一个RUL返回结果,才会去读下一个URL,这样的效率很差,浪费时间,我们需要并发发出远程请求,结果按照先后顺序输出就好了。
async function loadInOrder (urls) { // 并发读取远程URL const textPromises = urls.map(async url => { const response = await fetch(url) return response.text() }) // 按次序输出 for (const textPromise of textPromises) { console.log(await textPromise) } }
上面代码中,虽然map方法的参数是async函数,但是他们是并发执行的,因为只有async函数内部是继发执行,外部不受影响。后面的for...of循环内部使用了await,因此实现了按顺序输出。
8.7 异步遍历
Iterator接口是一种数据便利的协议,只要调用遍历器对象的next方法,就会得到一个指针对象,表示当前遍历指针所在的那个位置的信息。next方法返回的对象的解构和Generator的next方法返回的对象是一样的{value: ‘‘, done: ‘‘},其中value表示当前的数据的值,done是一个布尔值,表示遍历是否结束。
这里隐藏着一个规定,next方法必须是同步的,只要调用就必须立刻返回该值。这就是说,一旦执行next方法,就必须同步地得到value和done这两个属性。如果遍历指针正好指向同步操作,这是没有问题的,但是对于异步操作,就不太合适了。目前解决的方法是Generator函数里的异步操作,返回一个Thunk函数或者Promise对象,即value是一个Thunk函数或者Promise对象,等待以后返回真正的值,done属性则还是同步产生的。
ES2018引入“异步遍历器”(Async Iterator),为异步操作提供原生的遍历器接口,即value和done属性都是异步产生的。
异步遍历的接口
异步遍历器的最大的语法特点,就是调用遍历器的next方法,返回的是一个Promise对象。
asyncIterator .next() .then( ({ value, done }) => /* ... */ );
上面示例代码中asyncIterator是一个异步遍历器,调用next方法以后,返回一个Promise对象。因此可以使用then方法指定,这个Promise对象的状态变成resolved的回调函数。回调函数的参数以一个有value和done属性的对象,这个跟同步遍历器是一样的。
一个对象的同步遍历器的接口部署在Symbo.iterator属性上。同样的异步遍历器接口部署在Symbol.asyncIterator属性上面。不管是什么样的对象,只要它的Symbol.asyncIterator属性有值,就表示可以对它进行异步遍历。
下面是一个异步遍历器的示例代码:
const asyncIterable = createAsyncIterable([‘a‘, ‘b‘]); const asyncIterator = asyncIterable[Symbol.asyncIterator](); asyncIterator .next() .then(iterResult1 => { console.log(iterResult1); // { value: ‘a‘, done: false } return asyncIterator.next(); }) .then(iterResult2 => { console.log(iterResult2); // { value: ‘b‘, done: false } return asyncIterator.next(); }) .then(iterResult3 => { console.log(iterResult3); // { value: undefined, done: true } });
代码中,异步遍历器其实返回了两次值。第一次调用的时候,返回一个Promise对象,等到Promise对象resolve了,再返回一个表示当前数据成员信息的对象,这就是说,异步遍历器与同步遍历器的行为是一致的,只是会先返回Promise对象作为中介。
由于异步遍历器的next方法,返回的是一个Promise对象。因此,可以把它放在await命令后面。
async function f() { const asyncIterable = createAsyncIterable([‘a‘, ‘b‘]); const asyncIterator = asyncIterable[Symbol.asyncIterator](); console.log(await asyncIterator.next()); // { value: ‘a‘, done: false } console.log(await asyncIterator.next()); // { value: ‘b‘, done: false } console.log(await asyncIterator.next()); // { value: undefined, done: true } }
上面代码中,next方法用await处理后,就不必使用then方法了。真个流程已经很接近同步处理了。
注意,异步遍历器的next方法是可以连续调用的,不必等到上一步产生的Promise对象resolve以后再调用。这种情况下,next方法会累积起来,自动按照每一步的顺序运行下去。下面是一个例子,把所有的next方法放在Promise.all方法里面。
const asyncIterable = createAsyncIterable([‘a‘, ‘b‘]); const asyncIterator = asyncIterable[Symbol.asyncIterator](); const [{value: v1}, {value: v2}] = await Promise.all([ asyncIterator.next(), asyncIterator.next() ]); console.log(v1, v2); // a b
另外一种方法是一次性调用所有的next方法,然后await最后一步操作。
async function runner() { const writer = openFile(‘someFile.txt‘); writer.next(‘hello‘); writer.next(‘world‘); await writer.return(); } runner();
for await of
上面说过,for...of循环用于遍历同步的Iterator接口。新引入的for await ... of循环,则是调用遍历异步的Iteator接口。
async function f() { for await (const x of createAsyncIterable([‘a‘, ‘b‘])) { console.log(x); } } // a // b
上面代码中,creatAsyncIterator()返回一个拥有异步遍历器接口的对象,for...of循环自动调用这个对象的异步遍历器的next方法,会得到一个Promise对象。await用来处理这个Promise对象,一旦resolve,就会把得到的值x传入for....of循环体。
for await...of循环的一个用途,是部署了asyncIterable操作的异步操作,可以直接放在这个循环体里。
let body = ‘‘; async function f() { for await(const data of req) body += data; const parsed = JSON.parse(body); console.log(‘got‘, parsed); }
上面代码中,req是一个asyncIterable对象,用来异步读取数据。可以看到,使用for await...of循环后,代码非常简洁。
如果next方法返回的Promise对象被reject,for await...of就会报错,要用try...catch捕获。
async function () { try { for await (const x of createRejectingIterable()) { console.log(x); } } catch (e) { console.error(e); } }
注意,for await...of循环也可以用于同步遍历器。
(async function () { for await (const x of [‘a‘, ‘b‘]) { console.log(x); } })();
Node v10支持异步遍历器,node中的Stream模块就部署了这个接口,下面是读取文件的传统写法和异步遍历器的写法的差异。
// 传统写法 function main(inputFilePath) { const readStream = fs.createReadStream( inputFilePath, { encoding: ‘utf8‘, highWaterMark: 1024 } ); readStream.on(‘data‘, (chunk) => { console.log(‘>>> ‘+chunk); }); readStream.on(‘end‘, () => { console.log(‘### DONE ###‘); }); } // 异步遍历器写法 async function main(inputFilePath) { const readStream = fs.createReadStream( inputFilePath, { encoding: ‘utf8‘, highWaterMark: 1024 } ); for await (const chunk of readStream) { console.log(‘>>> ‘+chunk); } console.log(‘### DONE ###‘); }
异步Generator函数
就像Generator函数返回一个同步遍历器对象一样,异步Generator函数的作用给,是返回一个异步遍历器对象。
在语法上,异步Generator函数就是async函数与Generator函数的结合。
async function* gen() { yield ‘hello‘; } const genObj = gen(); genObj.next().then(x => console.log(x));
代码输出结果如下
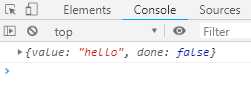
上面代码中,gen是一个异步Generator函数,执行后返回一个异步Iterator对象。改对象调用next方法,返回一个Promise对象。
异步遍历器的设计目的之一,就是Generaotr函数处理同步和异步操作的时候,能够使用同一套接口。
// 同步 Generator 函数 function* map(iterable, func) { const iter = iterable[Symbol.iterator](); while (true) { const {value, done} = iter.next(); if (done) break; yield func(value); } } // 异步 Generator 函数 async function* map(iterable, func) { const iter = iterable[Symbol.asyncIterator](); while (true) { const {value, done} = await iter.next(); if (done) break; yield func(value); } }
上面代码中,map是一个Generator函数,第一个参数是可遍历对象iterator,第二个参数是一个回调函数func。map的作用是将iterator每一步返回的值,用func进行处理。上面有两个版本的map,前一个处理同步遍历器,后一个处理异步遍历器。可以看到连个版本的写法基本一致。
下面是一个异步Generator函数的例子。
async function* readLines(path) { let file = await fileOpen(path); try { while (!file.EOF) { yield await file.readLine(); } } finally { await file.close(); } }
上面代码中,异步操作前面使用await关键字标明,await后面的操作应该返回Promise对象。凡是shiyongyield关键字的地方,就是next方法停下来的地方,它后面的表达式的值(即await file.readLine()的值),会作为next()返回对象的value属性,这一点是与同步Generator函数一致的。
异步Generator函数内部,能够同时使用await和yield命令。可以这样理解,await命令用于将外部操作产生的值输入函数内部,yield命令用于将函数内部的值输出。
上面代码定义的异步Generator函数的用法如下:
(async function () { for await (const line of readLines(filePath)) { console.log(line); } })()
异步Generator函数可以与for await...of循环结合起来使用。
async function* prefixLines(asyncIterable) { for await (const line of asyncIterable) { yield ‘> ‘ + line; } }
异步Generator函数的返回值是一个异步Iterator,即每次调用它的next方法,会返回一个Promise对象,也就是说,跟在yield命令后面的,应该是一个Promise对象。如果想上面的那个例子那样,yield命令后面是一个字符串,会被自动包装成一个Promise对象。
function fetchRandom() { const url = ‘https://www.random.org/decimal-fractions/‘ + ‘?num=1&dec=10&col=1&format=plain&rnd=new‘; return fetch(url); } async function* asyncGenerator() { console.log(‘Start‘); const result = await fetchRandom(); // (A) yield ‘Result: ‘ + await result.text(); // (B) console.log(‘Done‘); } const ag = asyncGenerator(); ag.next().then(({value, done}) => { console.log(value); })
执行顺序如下:
1. ag.next()立刻返回一个Promise对象
2. asyncGenerator函数开始执行,打印Start
3. await命令返回一个Promise对象,asyncGenerator函数暂停在这里
4. A处变成fulfilled状态,产生的值放入result变量,asyncGenerator函数继续往下执行
5. 函数在B处的yield暂停执行,一旦yield命令取到值,ag.next()返回的那个Promise对象编程fulfilled状态
6. ag.next()后面的then方法指定的回调函数开始执行。改回调函数的参数是一个对象{value, done},其中value的值是yield命令后面的那个表达式的值,done的值是false
执行结果如下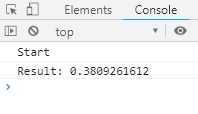
A和B两行的作用类似下面的代码
return new Promise((resolve, reject) => { fetchRandom() .then(result => result.text()) .then(result => { resolve({ value: ‘Result: ‘ + result, done: false, }); }); });
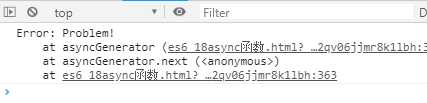
如果 一部Generator函数抛出错误会导致Promise对象的状态变为reject,然后抛出的错误被catch方法捕获。
async function* asyncGenerator() { throw new Error(‘Problem!‘); } asyncGenerator().next().catch(err => console.log(err));
执行结果如下:
注意,普通的async函数返回的是一个Promise对象,而异步Generator函数返回的是一个异步Iterator对象。可以这样理解,async函数和异步Generator函数,是封装异步操作的两种方法,都用来达到同一种目的。区别在于,前者自带执行器,后者通过for await...of执行,或者可以自己编写执行器。下面是一个异步Generator函数的执行器。
// 异步执行器 async function takeAsync(asyncIterable, count = Infinity) { const result = []; const iterator = asyncIterable[Symbol.asyncIterator](); while (result.length < count) { const {value, done} = await iterator.next(); if (done) break; result.push(value); } return result; } // 使用异步执行器 async function f() { async function* gen() { yield ‘a‘; yield ‘b‘; yield ‘c‘; } return await takeAsync(gen()); } f().then(function (result) { console.log(result); // [‘a‘, ‘b‘, ‘c‘] })
执行结果如下:
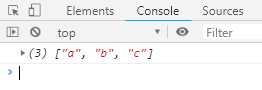
上面代码中,异步Generator函数产生的异步遍历器,会通过while循环自动执行,每当await iterator.next()完成,就会进入下一轮循环。一旦done属性变成true,就会调出循环,异步遍历器执行结束。
异步Generator函数出现以后,JavaScript就有了四种形式的函数:普通函数,async函数,Generator函数,异步Generator函数。通常,如果是一系列按照顺序执行的异步操作(比如读取文件,然后写入新内容,再存入硬盘)可以使用async函数;如果是一系列产生相同数据结构的异步操作(比如一行一行的读取文件),可以使用异步Generator函数。
异步Generator函数也可以通过next方法的参数,接收外部传入的数据。
const writer = openFile(‘someFile.txt‘); writer.next(‘hello‘); // 立即执行 writer.next(‘world‘); // 立即执行 await writer.return(); // 等待写入结束
上面代码中,openFile是一个异步Generator函数。next方法的参数,向该函数内部的操作传入数据。每次next方法都是同步执行的,最后的await命令用于等待整个操作结束。
最后,同步的数据结构,也可以使用异步Generator函数。
async function* createAsyncIterable(syncIterable) { for (const elem of syncIterable) { yield elem; } }
上面代码中,由于没有异步操作,所以也就没有使用await关键字。
yield * 语句
yield*语句也可以跟一个异步遍历器。
async function* gen1() { yield ‘a‘; yield ‘b‘; return 2; } async function* gen2() { // result 最终会等于 2 const result = yield* gen1(); } (async function () { for await (const x of gen2()) { console.log(x); } })();
上面代码中,gen2函数里的result变量,最后的值是2.
与同步Generator函数一样,for await...of循环会展开yield*,输出结果如下:
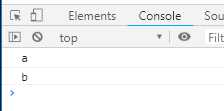
标签:直线 一半 image fill 提醒 resolved holo input style
原文地址:https://www.cnblogs.com/tylerdonet/p/9948115.html