标签:图片 image strong 取出 技术 http find 是的 com
利用正则来爬去猫眼电影
===================================
=====================================================
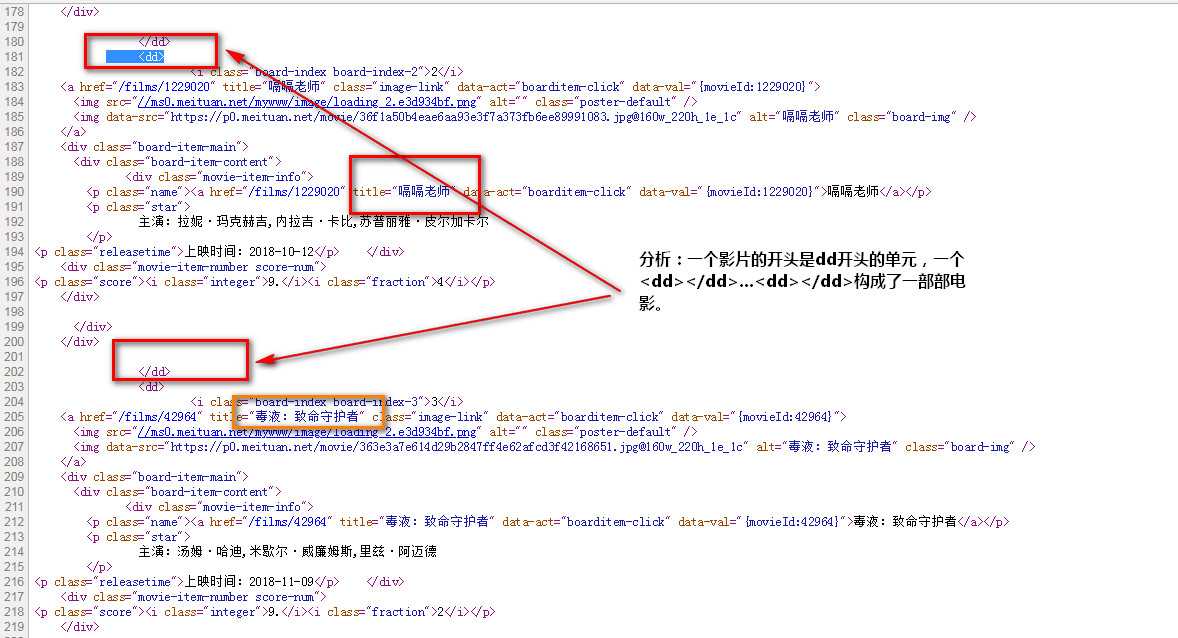
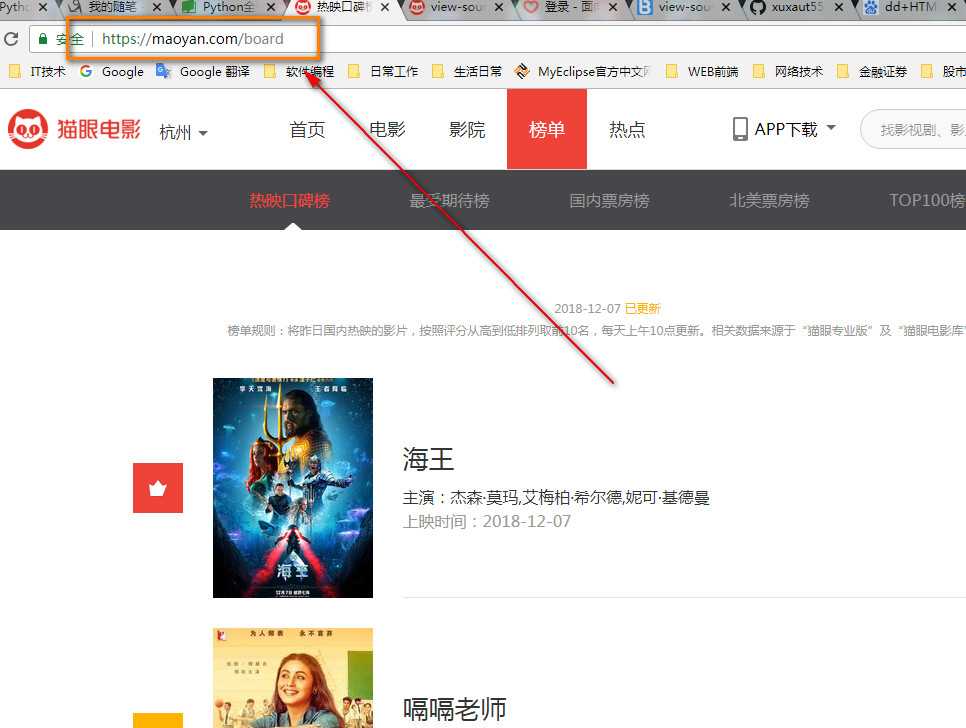
1 ‘‘‘ 2 利用正则来爬去猫眼电影 3 1. url: http://maoyan.com/board 4 2. 把电影信息尽可能多的拿下来 5 6 分析 7 1. 一个影片的内容是以dd开是的单元 8 2. 在单元内存在一部电影的所有信息 9 10 思路: 11 1. 利用re把dd内容都给找到 12 2. 对应找到的每一个dd,用re挨个查找需要的信息 13 14 方法就是三步走: 15 1. 把页面down下来 16 2. 提取出dd单元为单位的内容 17 3. 对每一个dd,进行单独信息提取 18 ‘‘‘ 19 20 21 from urllib import request 22 23 #1 下载页面内容 24 url = "http://maoyan.com/board" 25 26 rsp = request.urlopen(url) 27 html = rsp.read().decode() 28 29 30 31 #2 按dd提取出内容来,缩小处理范围 32 import re 33 34 s = r‘<dd>(.*?)</dd>‘ 35 36 pattern = re.compile(s, re.S) 37 38 films = pattern.findall(html) 39 print(len(films)) 40 41 42 43 #3. 从每一个dd中单独提取出需要的信息 44 for film in films: 45 46 # 提取电影名称 47 s = r‘<a.*?title="(.*?)"‘ 48 pattern = re.compile(s) 49 title = pattern.findall(film)[0] 50 print(title)
标签:图片 image strong 取出 技术 http find 是的 com
原文地址:https://www.cnblogs.com/xuxaut-558/p/10086455.html