标签:out enforce cli https 索尼 err 文件目录 sid binlog
1) mha管理节点安装包:
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-manager-0.56.tar.gz
2) mha node节点安装包:
mha4mysql-node-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56.tar.gz
3) mysql中间件:
Atlas-2.2.1.el6.x86_64.rpm
4) mysql源码安装包
mysql-5.6.17-linux-glibc2.5-x86_64.tar


姓名:松信嘉范
MySQL/Linux专家
2001年索尼公司入职
2001年开始使用oracle
2004年开始使用MySQL
2006年9月-2010年8月MySQL从事顾问
2010年-2012年DeNA
2012年至今Facebook
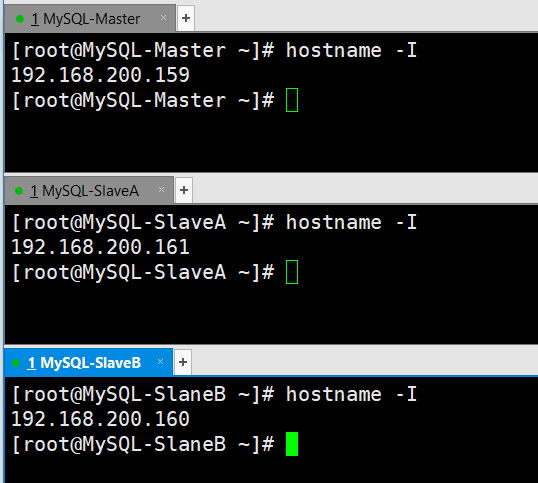
1、MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换过程中,MHA能最大程度上保证数据库的一致性,以达到真正意义上的高可用。
2、MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应程序是完全透明的。
1、复制主库binlog日志出来
2、找出relaylog日志最全的从库
3、将最全的relaylog日志在所有从库中同步(第一次数据同步)
4、将之前最全的那个从库提升为主库
5、将复制出来的binlog日志放到新提升为主库的从库里面
6、其他所有从库重新指向新提升主库,继续主从复制

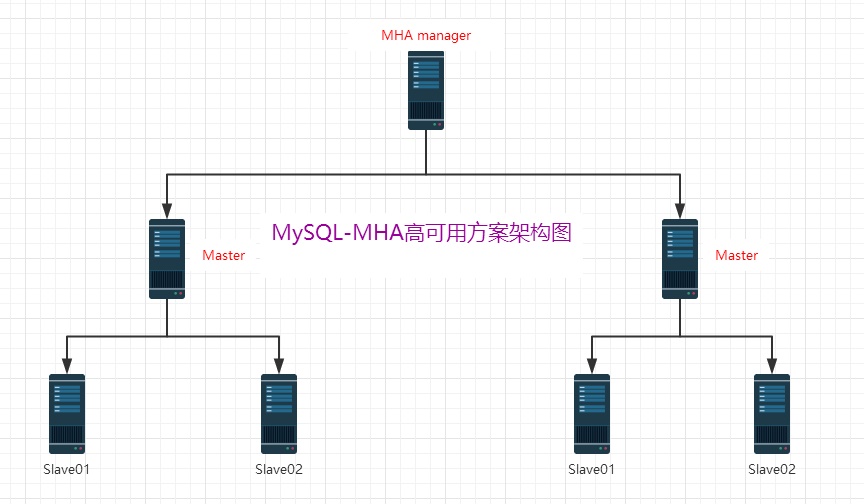
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下: 
链接:https://pan.baidu.com/s/1aSh6hKFDcA6VAsXicbTSSQ
提取码:2ynt
yum -y install ncurses-develyum -y install libaiotar xf mysql-5.6.17-linux-glibc2.5-x86_64.tar.gz -C /usr/local/ln -s /usr/local/mysql-5.6.17-linux-glibc2.5-x86_64 /usr/local/mysqluseradd mysql -s /sbin/nologin -M/usr/local/mysql/scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data//bin/cp /usr/local/mysql/support-files/my-default.cnf /etc/my.cnf/bin/cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqldln -s /usr/local/mysql/bin/* /usr/local/bin/
mysqladmin -uroot password ‘123123‘主库和从库都要开启binlog
主库和从库server-id不同
要有主从复制用户
[root@MySQL-Master ~]# vim /etc/my.cnf [root@MySQL-Master ~]# cat /etc/my.cnf[client]socket = /usr/local/mysqld/data/mysql.sock[mysqld]lower_case_tabel_names = 1default-storage-engine = InnoDBport = 3306datadir = /usr/local/mysql/datacharacter-set-server = utf8socket = /usr/local/mysql/data/mysql.socklog_bin = mysql-bin #开启binlog日志server_id = 1 #设置server_idinnodb_buffer_pool_size = 200Mslave-parallel-workers = 8thread_cache_size = 600back_log = 600slave_net_timeout = 60max_binlog_size = 512Mkey_buffer_size = 8Mquery_cache_size = 64Mjoin_buffer_size = 2Msort_buffer_size = 2Mquery_cache_type = 1thread_stack = 192K
(1)删除不必要的用户
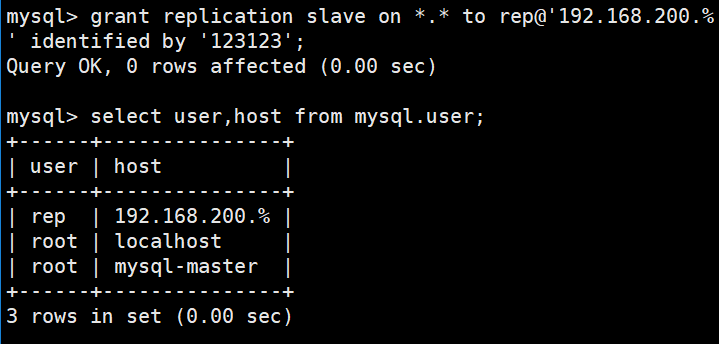
mysql>mysql> select user,host from mysql.user;+------+--------------+| user | host |+------+--------------+| root | 127.0.0.1 || root | ::1 || | localhost || root | localhost || | mysql-master || root | mysql-master |+------+--------------+6 rows in set (0.10 sec)mysql> drop user root@‘127.0.0.1‘;Query OK, 0 rows affected (0.00 sec)mysql> drop user root@‘::1‘;Query OK, 0 rows affected (0.00 sec)mysql> drop user ‘ ‘@‘localhost‘;Query OK, 0 rows affected (0.00 sec)mysql> drop user ‘ ‘@‘mysql-master‘;Query OK, 0 rows affected (0.00 sec)mysql> select user,host from mysql.user;+------+--------------+| user | host |+------+--------------+| root | localhost || root | mysql-master |+------+--------------+2 rows in set (0.00 sec)(2)创建主从复制用户
MySQL-SlaveA 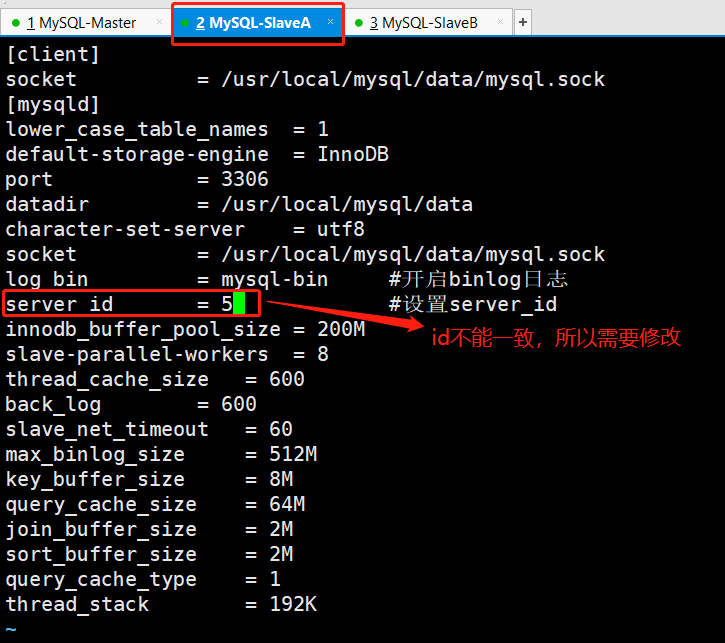
MySQL-SlaveB 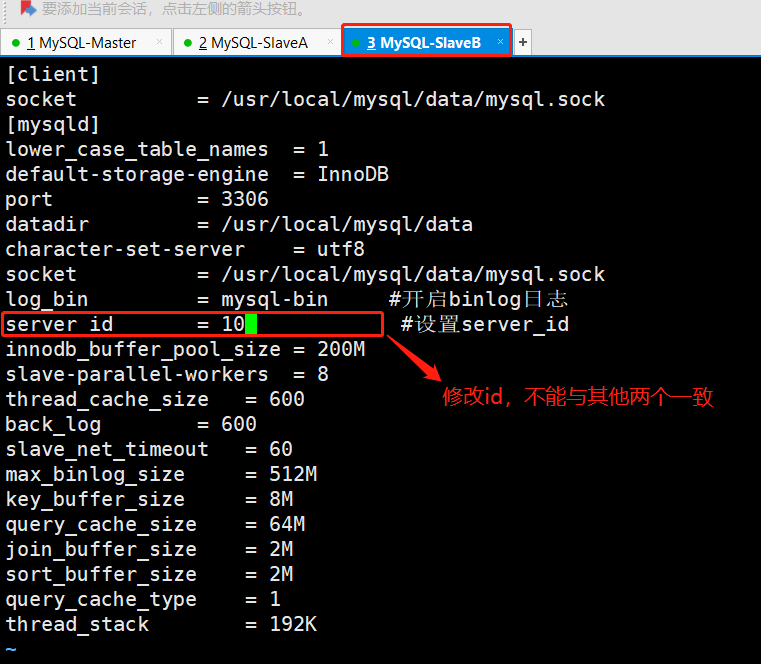
特别提示: 在以往如果是基于binlog日志的主从复制,则必须要记住主库的master状态信息。
但是在MySQL5.6版本里多了一个Gtid的功能,可以自动记录主从复制位置点的信息,并在日志中输出出来。
编辑mysql配置文件(主库从库都需要修改)
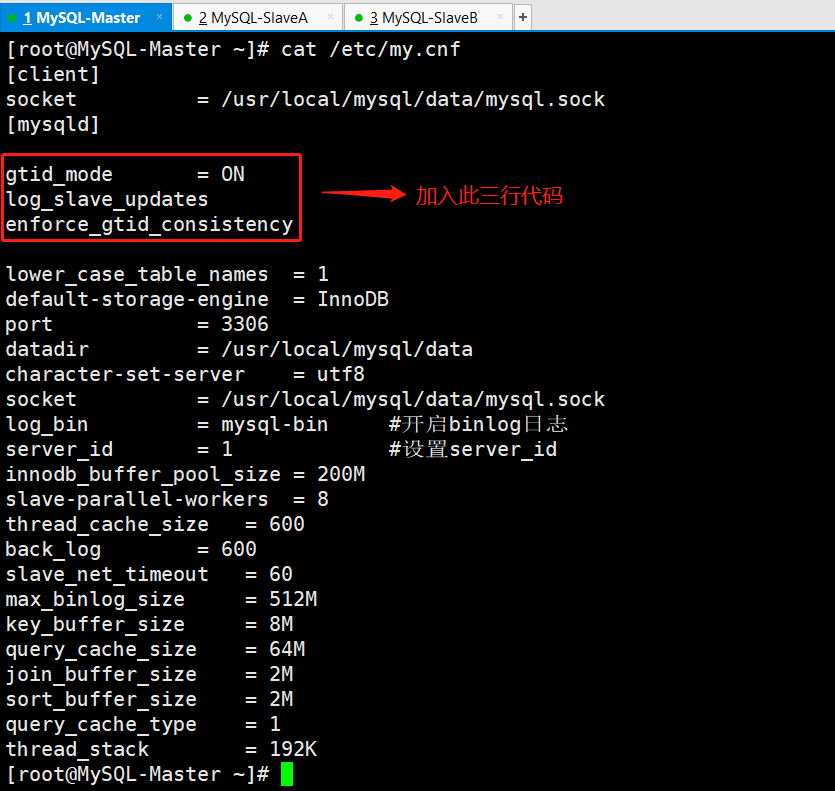
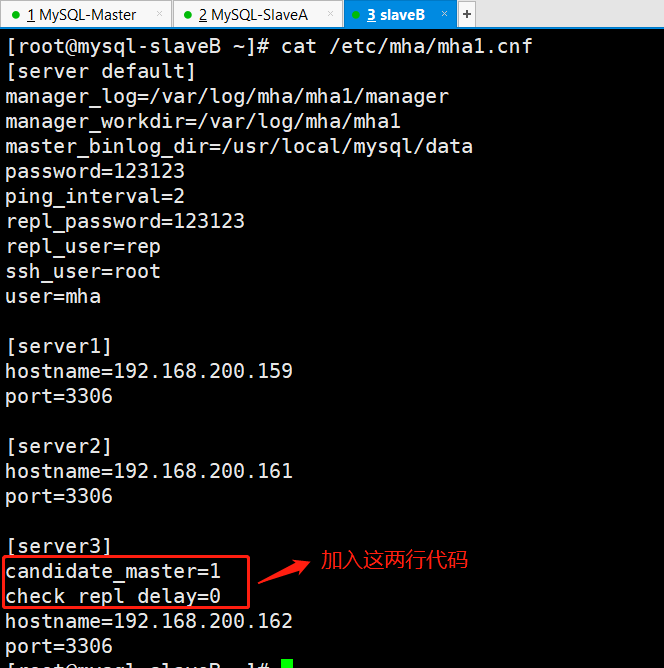
三台机器都需要加上上图标注的三行代码
修改完配置文件以后重启动数据库
/etc/init.d/mysqld restart再次查看GTID状态 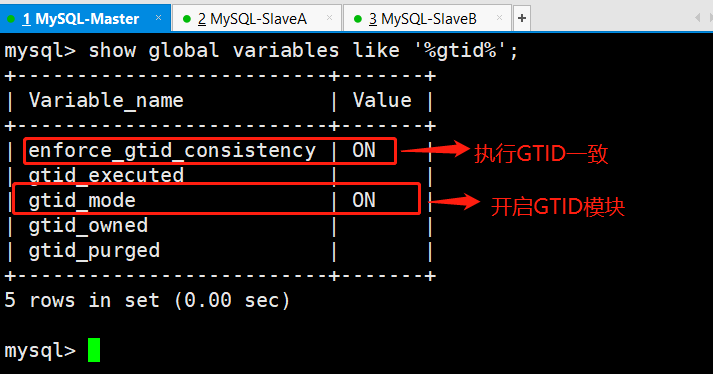
再次提示:
主库从库都必须要开启GTID,否则在做主从复制的时候就会报错.
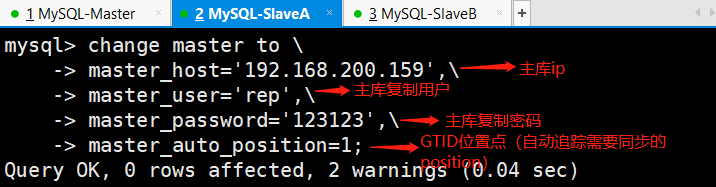
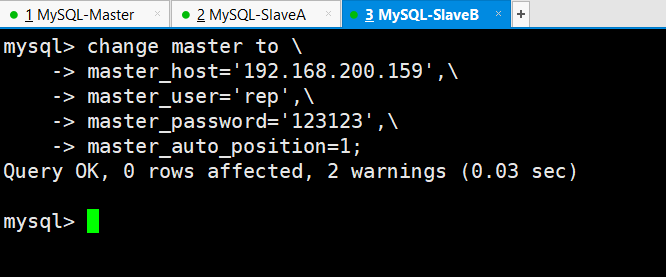
mysql>start slave; 开启主从复制
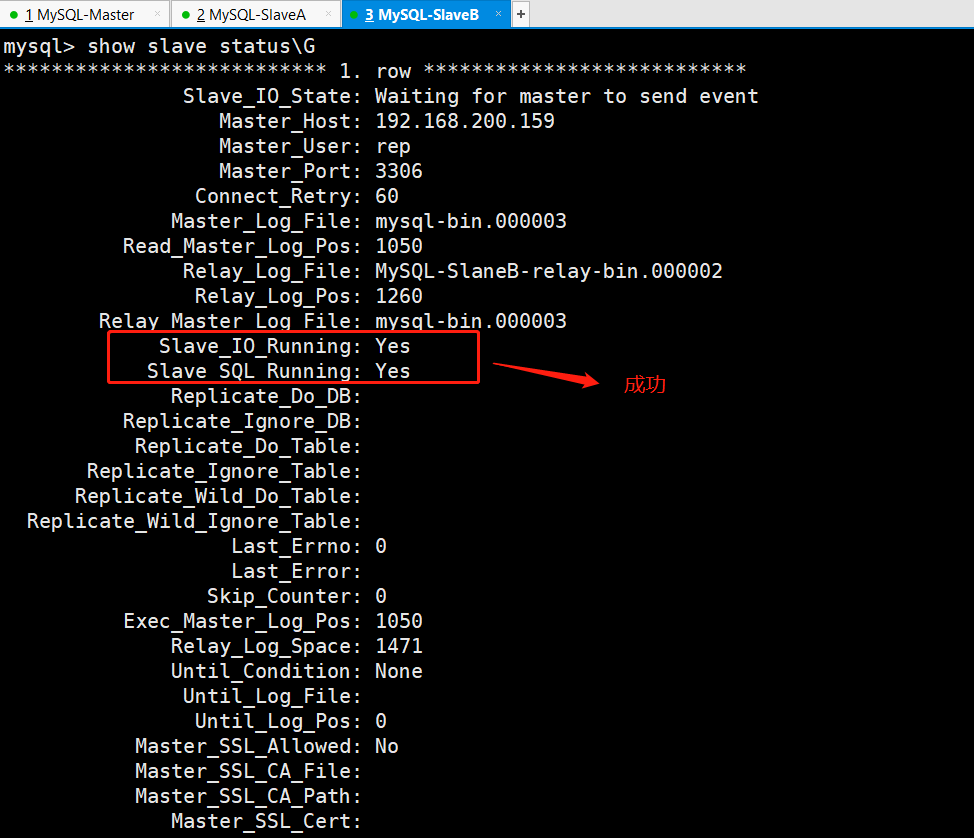
两个从库MySQL-SlaveA和MySQL-SlaveB都执行以上步骤。
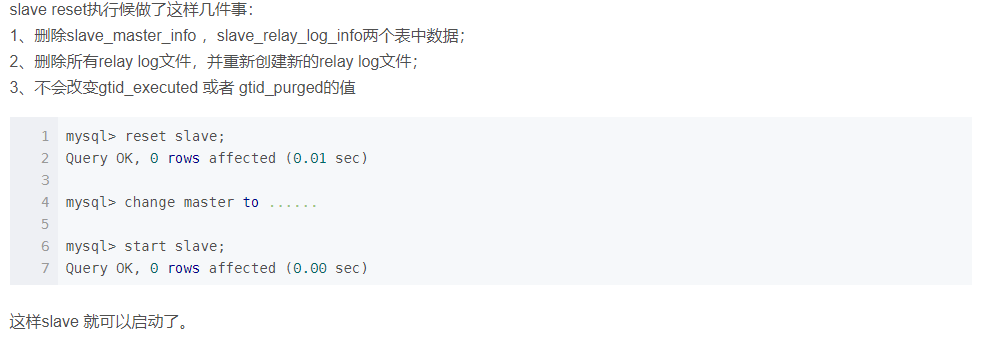
MySQL主从复制,启动slave时,出现下面报错:
mysql> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
解决办法:
1、GTID(Global Transaction)全局事务标识符:是一个唯一的标识符,它创建并与源服务器(主)上提交的每个事务相关联。此标识符不仅对其发起的服务器是唯一的,而且在给定复制设置中的所有服务器上都是唯一的。所有交易和所有GTID之间都有1对1的映射。
2、GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。
下面是一个GTID的具体形式:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
(1)支持多线程复制:事实上是针对每个database开启相应的独立线程,即每个库有一个单独的(sql thread)
(2)支持启用GTID,在配置主从复制,传统的方式里,你需要找到binlog和POS点,然后change master to 指向。在mysql5.6里,无须再知道binlog和POS点,只需要知道master的IP/端口/账号密码即可,因为同步复制是自动的,MySQL通过内部机制GTID自动找点同步。
(3)基于Row复制只保存改变的列,大大节省磁盘空间,网络,内存等
(4)支持把Master和Slave的相关信息记录在Table中;原来是记录在文件里,现在则记录在表里,增强可用性
(5)支持延迟复制
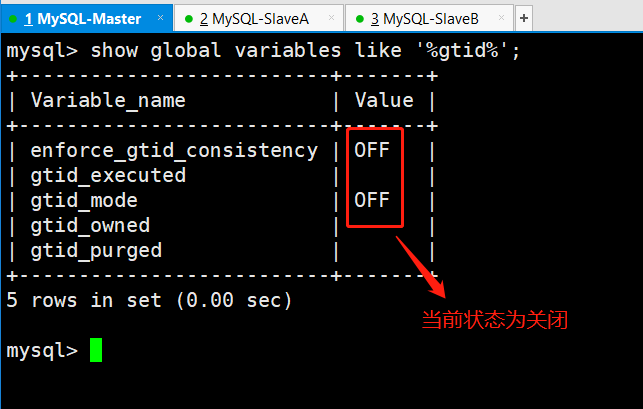
#mysql配置文件:[mysqld]gtid_mode=ONenforce_gtid_consistency#查看show global variables like ‘%gtid%’;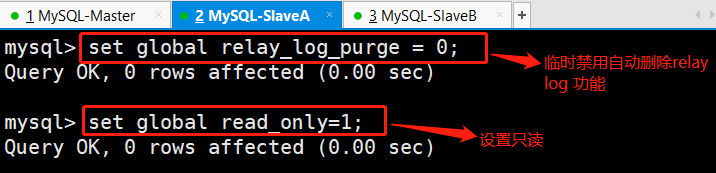
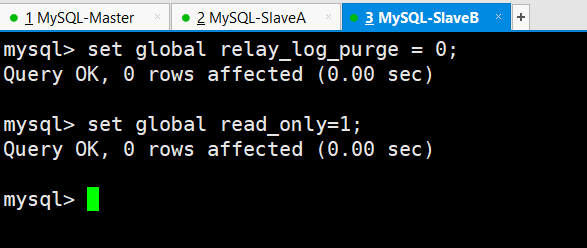
编辑配置文件/etc/my.cnf
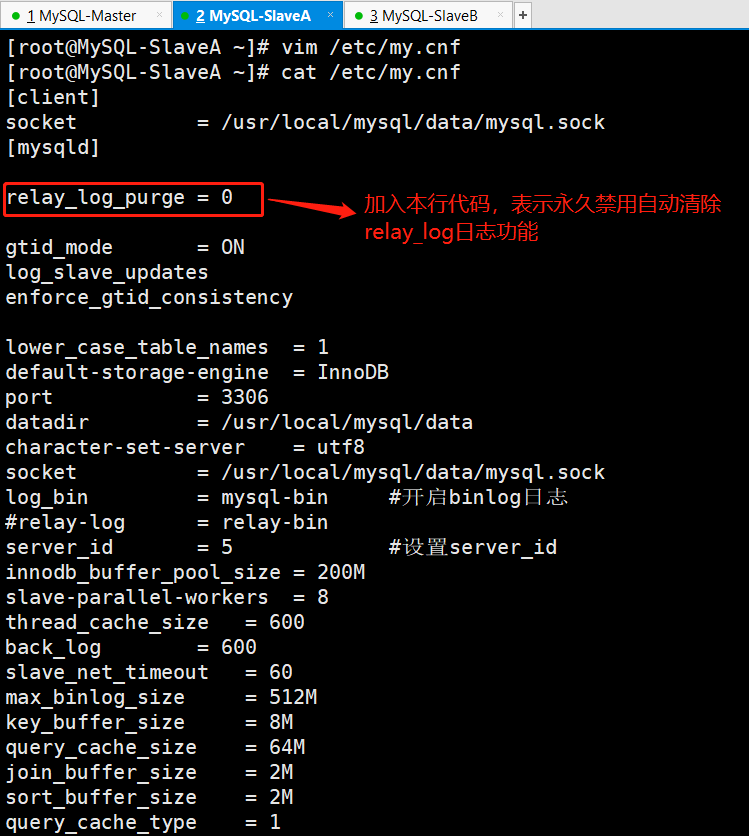
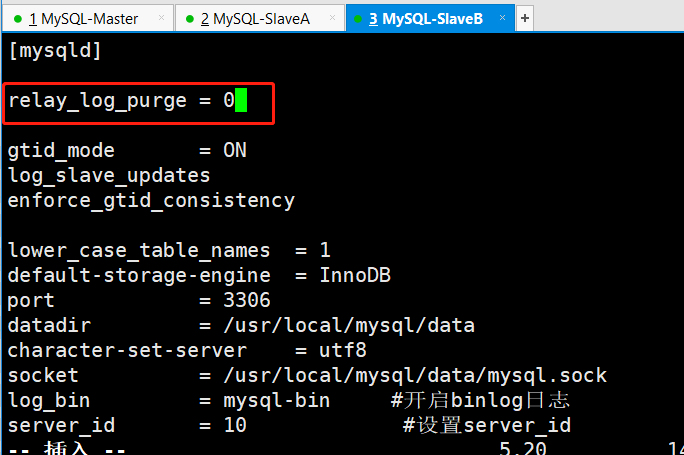
修改完毕后重启mysql服务:/etc/init.d/mysqld restart
mha4mysql-node-0.56-0.el6.noarch.rpm以下链接提取
链接:https://pan.baidu.com/s/1S9FDyBjxEBXBF00aAFK4pw
提取码:opja
光盘安装依赖包 yum -y install perl-DBD-MySQL安装mha4mysql-node-0.56-0.el6.noarch.rpmrpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm 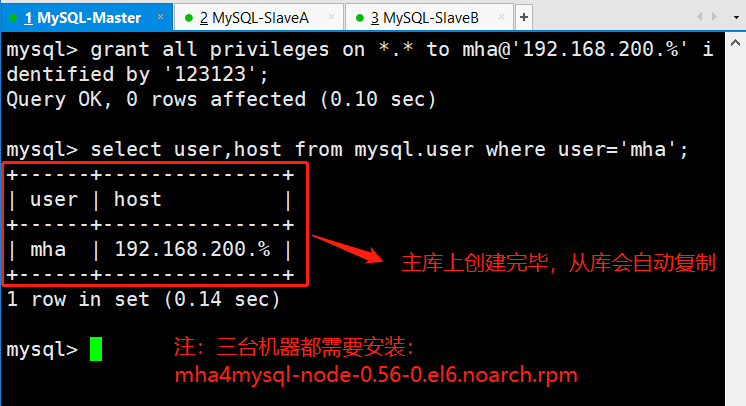
#使用阿里云源+epel源wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repowget -O /etc/yum.repos.d/epel-6.repo http://mirrors.aliyun.com/repo/epel-6.repo#安装manager依赖包(需要公网源)yum -y install perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes#安装manager包[root@MySQL-SlaveB rpm]# rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm Preparing... ########################################### [100%] 1:mha4mysql-manager ########################################### [100%]#创建配置文件目录mkdir -p /etc/mha#创建日志目录mkdir -p /var/log/mha/mha1#创建配置文件(默认没有)[root@MySQL-SlaveB ~]# cd /etc/mha/[root@MySQL-SlaveB mha]# ls[root@MySQL-SlaveB mha]# vim /etc/mha/mha1.cnf[root@MySQL-SlaveB mha]# cat /etc/mha/mha1.cnf[server default]manager_log=/var/log/mha/mha1/manager #manager管理日志存放路径manager_workdir=/var/log/mha/mha1 #manager管理日志的目录路径master_binlog_dir=/usr/local/mysql/data #binlog日志的存放路径user=mha #管理账户password=123123 #管理账户密码ping_interval=2 #存活检查的间隔时间repl_user=rep #主从复制的授权账户repl_password=123123 #主从复制的授权账户密码ssh_user=root #用于ssh连接的账户[server1]hostname=192.168.200.159port=3306[server2]#candidate_master=1 #此条暂时注释掉(后面解释)#check_repl_delay=0 #此条暂时注释掉(后面解释)hostname=192.168.200.161port=3306[server3]hostname=192.168.200.160port=3306#**特别提示:**#以上配置文件内容里每行的最后不要留有空格,因此,不能复制的呦特别说明:
参数:candidate_master=1
解释:设置为候选master,如果设置该参数以后,发生主从切换以后会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
参数:check_repl_delay=0
解释:默认情况下如果一个slave落后master 100M的relay logs 的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
#创建密钥对[root@MySQL-SlaveB ~]# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa >/dev/null 2>&1#发送MySQL-SlaveB公钥,包括自己[root@MySQL-SlaveB ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.159[root@MySQL-SlaveB ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.161[root@MySQL-SlaveB ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.160#发送MySQL-SlaveA公钥,包括自己[root@MySQL-SlaveA ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.159[root@MySQL-SlaveA ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.161[root@MySQL-SlaveA ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.160#发送MySQL-Master公钥,包括自己[root@MySQL-Master ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.159[root@MySQL-Master ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.160[root@MySQL-Master ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.200.161[root@MySQL-SlaveB ~]# masterha_check_ssh --conf=/etc/mha/mha1.cnf #ssh检查命令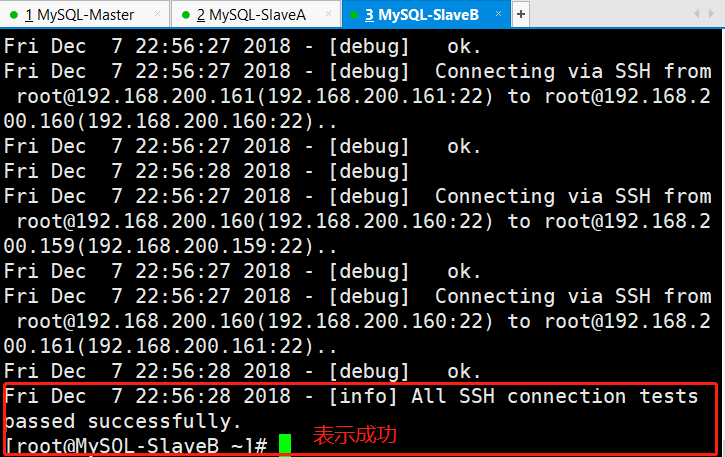
[root@MySQL-SlaveB ~]# masterha_check_repl --conf=/etc/mha/mha1.cnf
(1)错误的主从复制检测
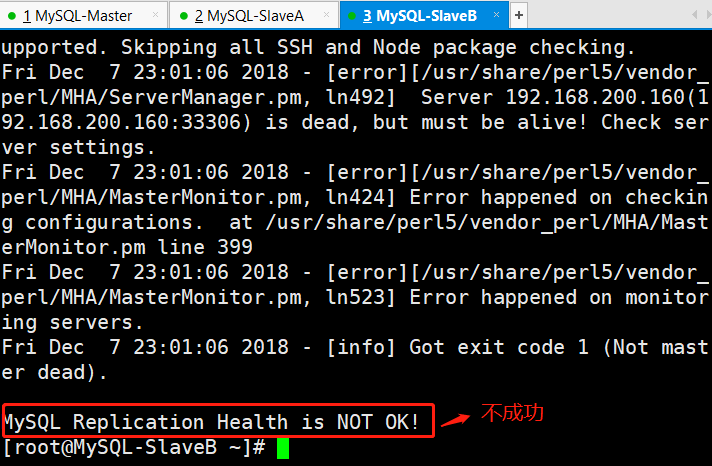
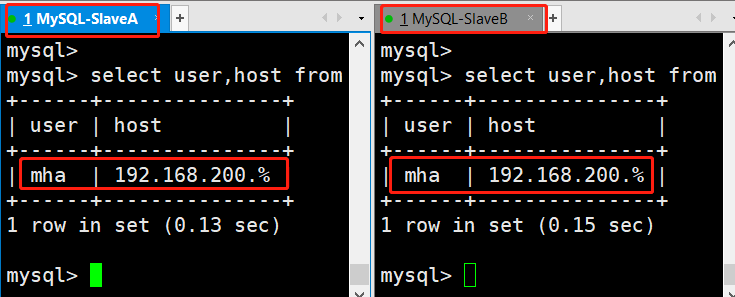
因此在MySQL-SlaveA和MySQL-SlaveB上添加主从复制的用户即可。
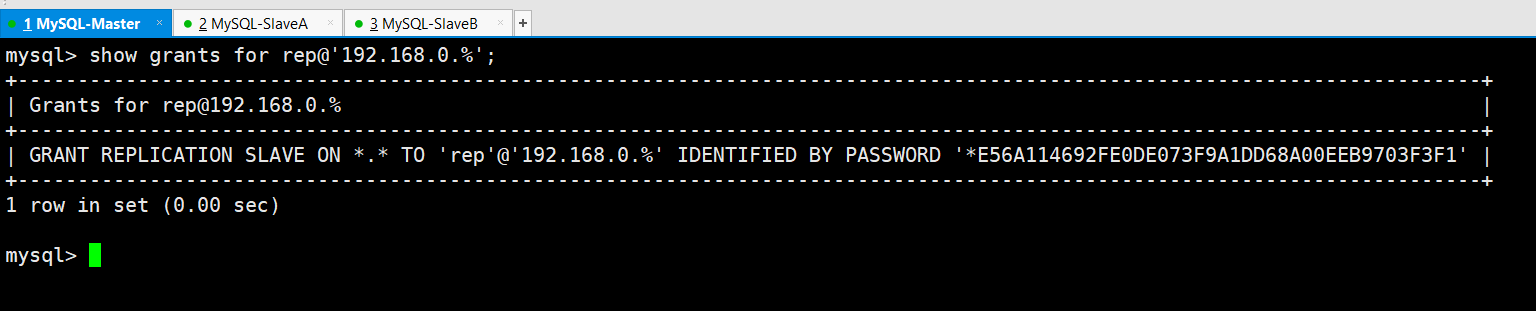
grant replication slave on . to rep@‘192.168.200.%‘ identified by ‘123123‘;

[root@mysql-slaveB ~]# nohup masterha_manager --conf=/etc/mha/mha1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/mha1/manager.log 2>&1 &[1] 3408[root@mysql-slaveB ~]# ps -ef | grep perl | grep -v greproot 3408 1272 1 03:03 pts/0 00:00:00 perl /usr/bin/masterha_manager --conf=/etc/mha/mha1.cnf --remove_dead_master_conf --ignore_last_failover
初始状态: 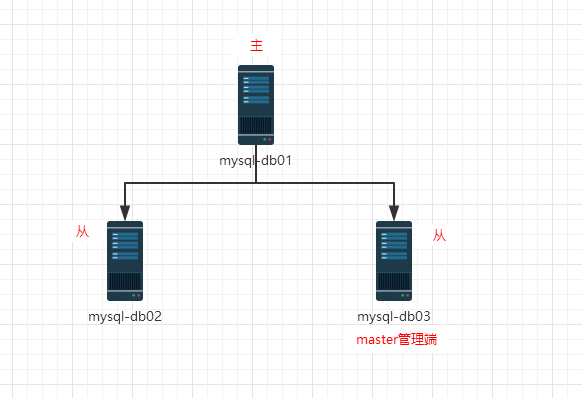
(1)登陆mysql-db02(192.168.0.53)查看信息状态 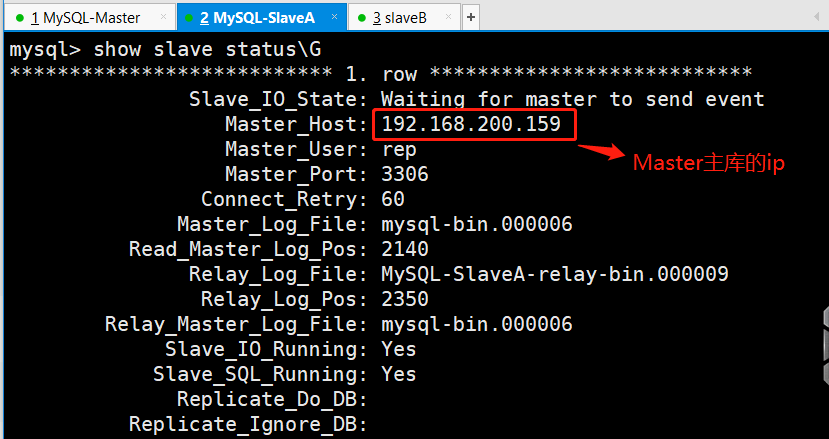
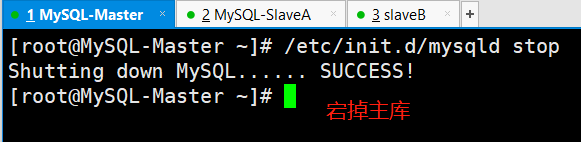
(2)停掉mysql-db01(192.168.0.51)上的MySQL服务
[root@MySQL-Master ~]# /etc/init.d/mysqld stopShutting down MySQL..... SUCCESS!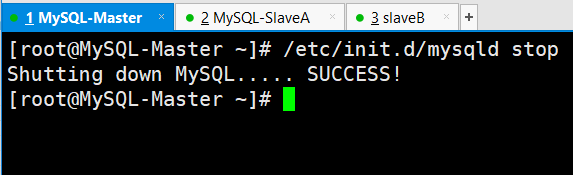
(3)查看slaveB上的MySQL从库同步状态
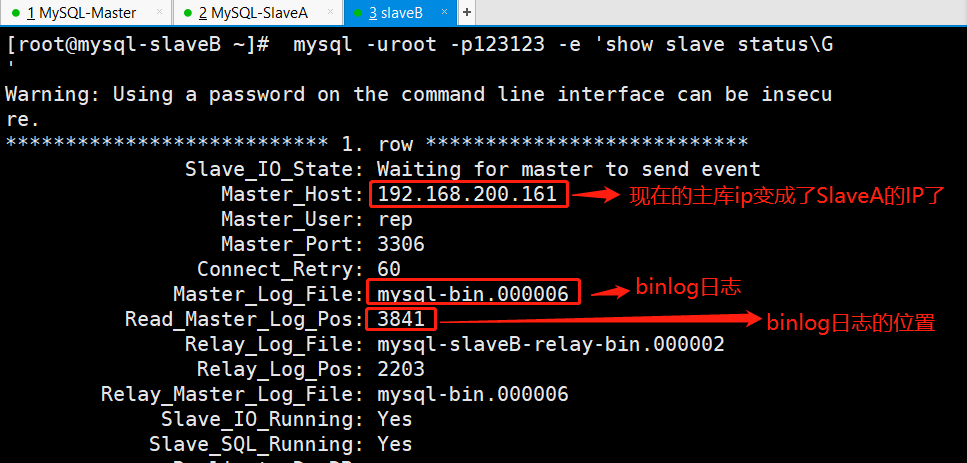
(4)查看mysql-db02上的MySQL,主库同步状态。

(5)查看mysql-db03上的mha进程状态
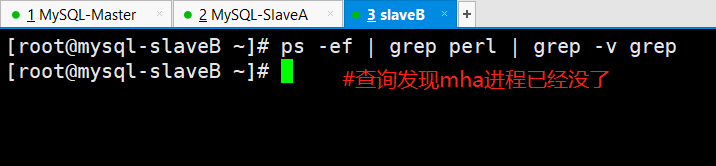
(6)查看mha配置文件信息
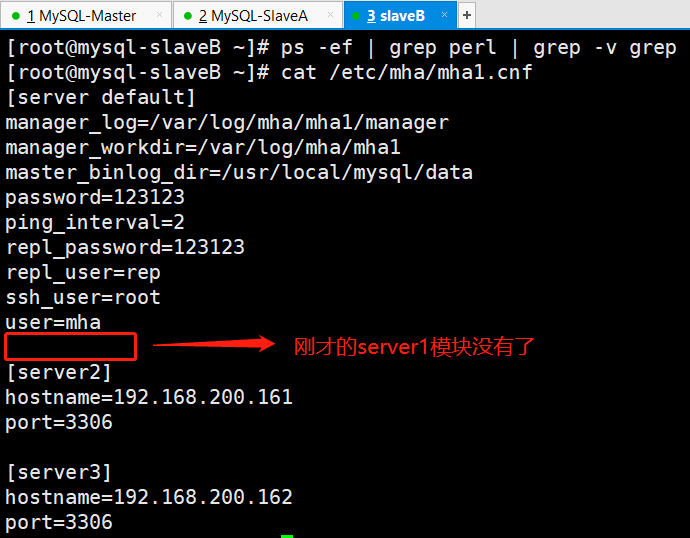
说明:
当作为主库的mysql-db01上的MySQL宕机以后,mha通过检测发现mysql-db01宕机,那么会将binlog日志最全的从库立刻提升为主库,而其他的从库会指向新的主库进行再次同步。
查询mha日志路径 /var/log/mha/mha1/manager
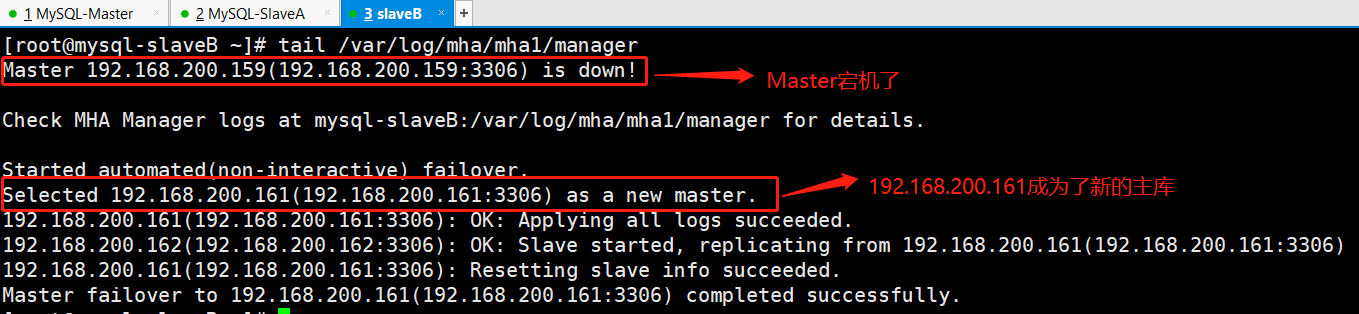
由于mysql-Master的MySQL服务宕机,因此mha将mysql-SlaveA提升为了主库。因此,我们需要将宕机的mysql-Master的MySQL服务启动,然后作为主库mysql-SlaveA的从库。
初始状态: 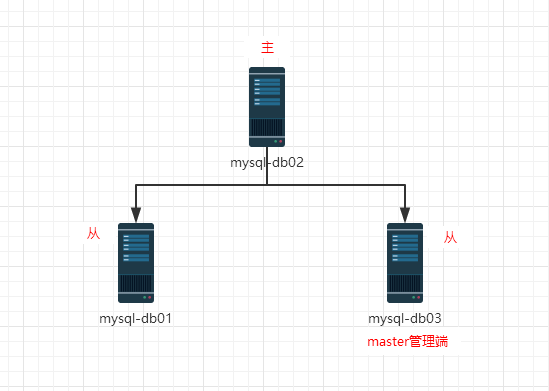
(1)将故障宕机的mysql-Master的MySQL服务启动并授权进行从同步
/etc/init.d/mysqld start #启动Master的MySQL服务#进入mysql授权进行从同步mysql> CHANGE MASTER TO MASTER_HOST=‘192.168.200.161‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘rep‘, MASTER_PASSWORD=‘123123‘;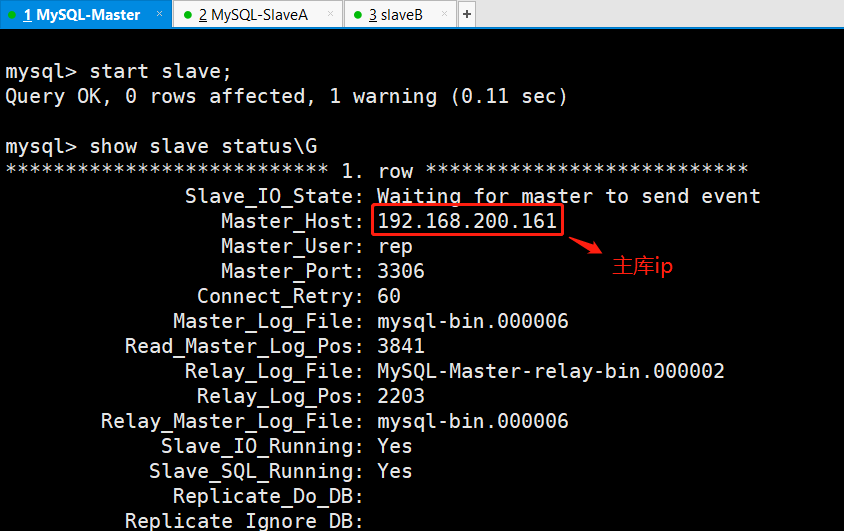
(2)将mha配置文件里缺失的部分补全
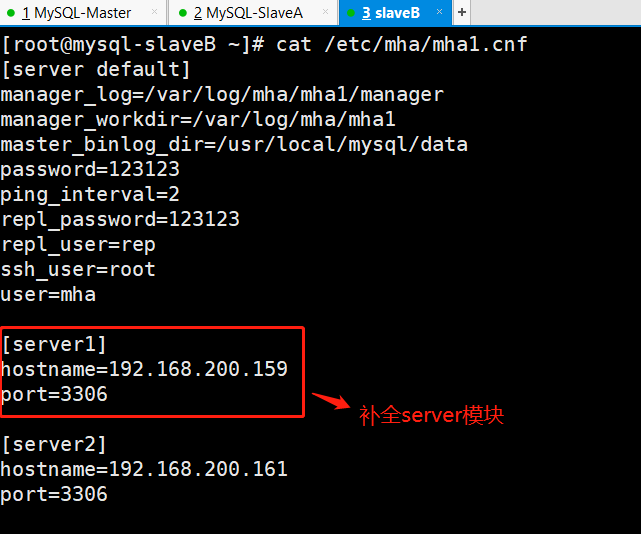
(3)启动mha进程
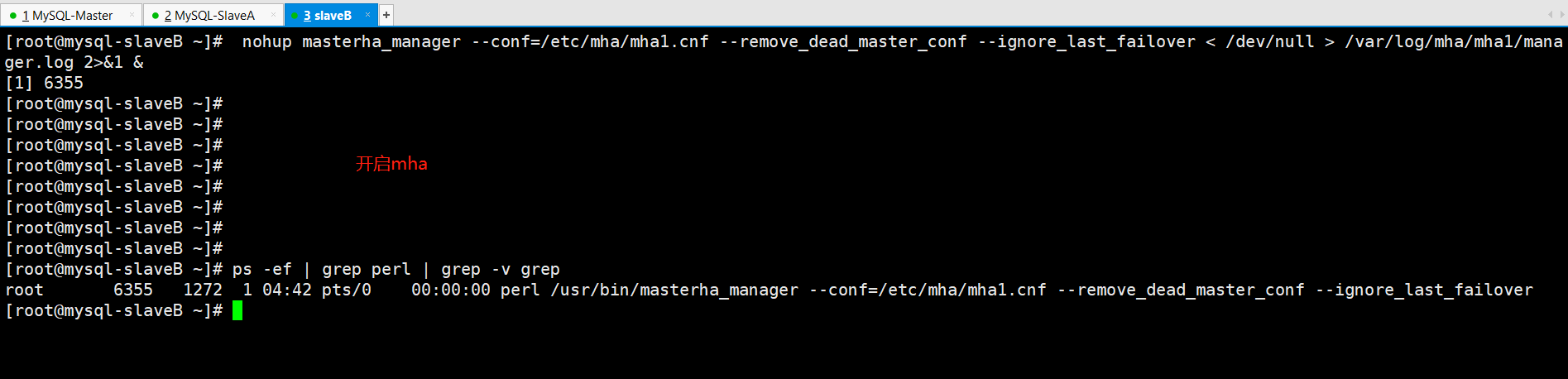
注:如果发现从库没有mha账户需要将主库的mha账户删除后从新授权一个,这样从库就自动复制过来了。一般情况下不会这样,我可能出现bug了!!!
(4)停掉mysql-slaveA上的MySQL服务
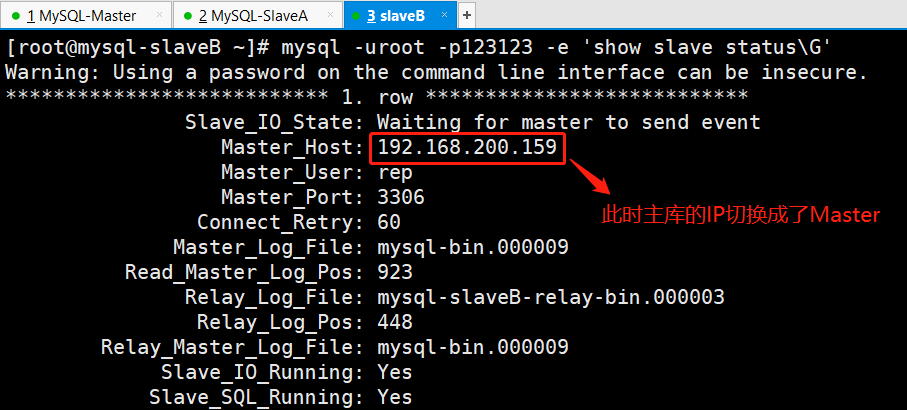
(5)查看mysql-slaveB上的主从同步状态:
(6)启动mysql-slaveA上的MySQL服务
[root@MySQL-SlaveA ~]# /etc/init.d/mysqld startStarting MySQL.. SUCCESS![root@MySQL-SlaveA ~]# mysql -uroot -p123123mysql> CHANGE MASTER TO MASTER_HOST=‘192.168.200.159‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘rep‘, MASTER_PASSWORD=‘123123‘;mysql> start slave;mysql> show slave status\G 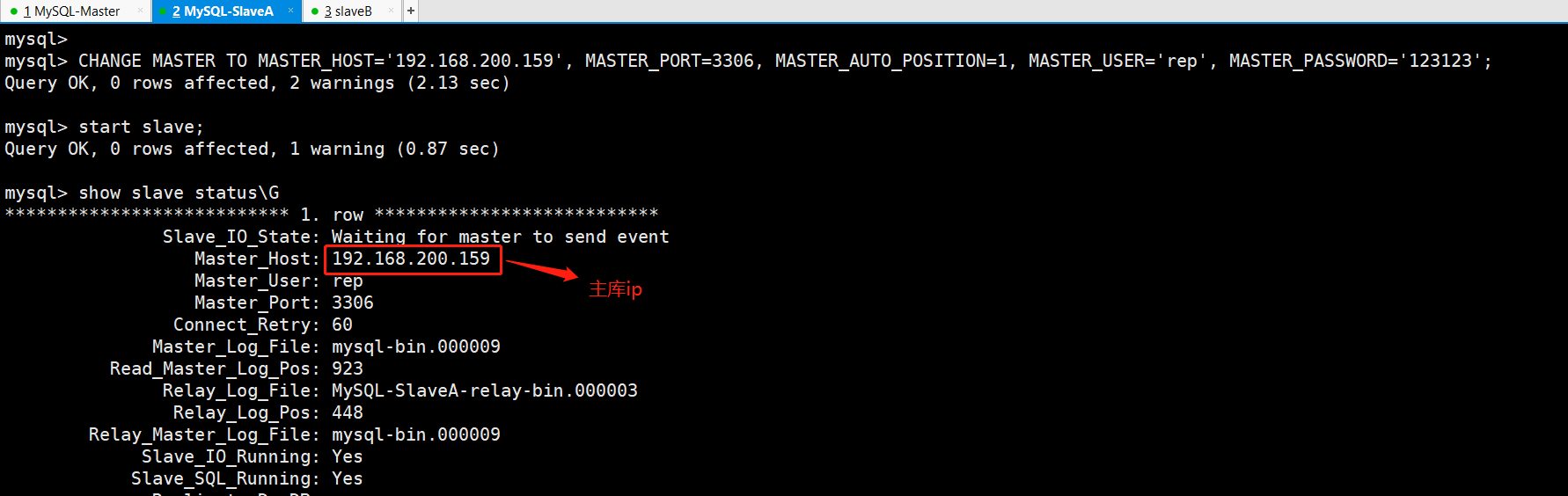
(7)再次补全mha配置文件后,启动mha进程

注:这次上述没有自动复制mha账户的问题没有发生,可能真的遇到了bug!!!
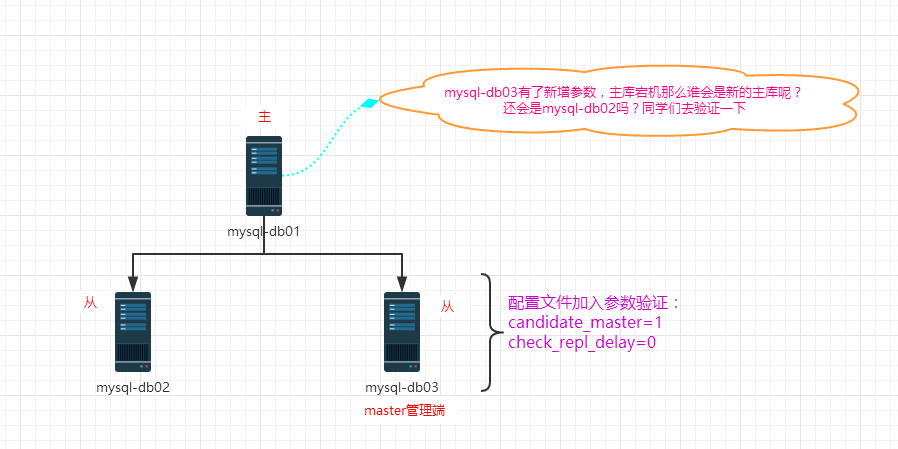
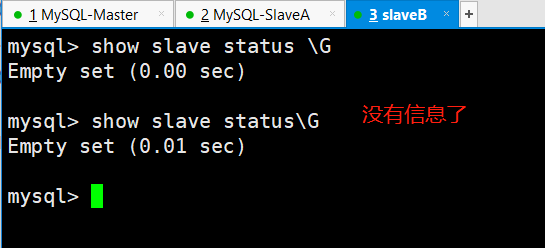
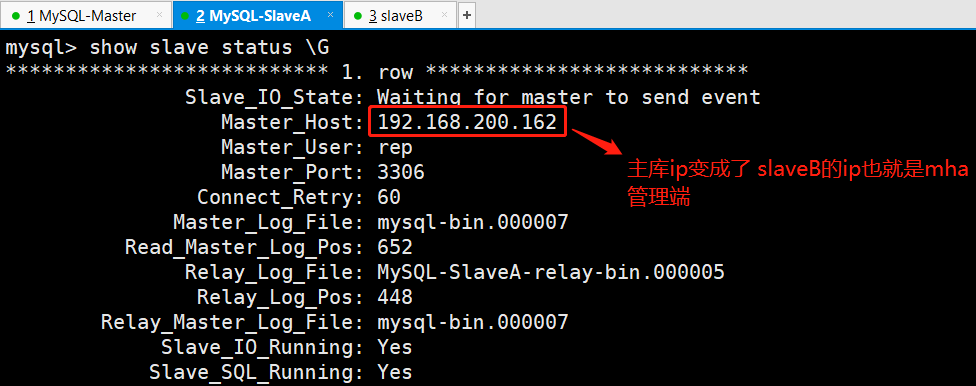
综上实验,当slaveB新加了参数验证,主库再次宕机的话,新的主库变成了自己。
标签:out enforce cli https 索尼 err 文件目录 sid binlog
原文地址:https://www.cnblogs.com/mendermi/p/10087992.html