标签:com 有一个 文字 如何 现象 模型 基础 缺点 诗词
数学基础与语言学基础内容:
数学基础:概率论,(从大规模预料中统计较小的语言单位的相关的统计信息,然后运用统计推理技术计算更高一级的语言单位出现的概率)
语言学基础
实用知识
统计自然语言处理的步骤:
收集自然语言词汇的分布情况;
根据这些分布情况进行统计推导。(最典型的例子:构造统计语言模型)
数学基础:理论基础才--->上层建筑
概率论是研究随机现象的分支,随机现象指当人们观察它时,所得到的观察结果不是确定的,而是许许多多可能结果中的一种。
概率(Probability)是衡量该事件发生的可能性的量度。
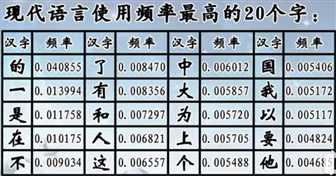
汉字的信息熵(香农1948,选择概率论为数学工具,提出用不确定的量度来计算信息量的数学公式):汉字是当今世界上信息量最大的文字符号系统;汉字是世界上硕果仅存的象形文字,对汉文化的传承和发展作出了巨大的贡献。既有固有的缺点,也有优越性,将式一种长期的客观存在。
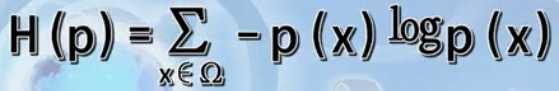
条件概率(Condition probability):已知B为真的条件下A为真的概率可以表示文P(A|B)。——后验概率(posterior probability),与此相反,非条件概率被称为先验概率(prior probability)。
联合概率:P(A,B)=P(A)P(B|A)=P(B)P(A|B);联合概率的链式规则P(A,B,C,D,...)=P(A)P(B|A)P(C|A,B)P(D|A,B,C)...
独立:两个时间A与B相互对立,当且仅当P(A)=P(A|B)<-->P(A,B)=P(A)*P(B)存在。
贝叶斯定理:贝叶斯公式使我们能够交换事件之间条件依赖的顺序。应用实例:音字转换
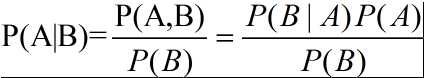
随机变量:离散型随机变量、连续型随机变量
数学期望和方差:
阈值:(越少越好,有阈值的方法都比较复杂)
构造语言模型P(T)的两类方法:
基于频度的统计:事件μ发生的次数与所有事件总次数的比率f(μ)=C(μ)/N,常用分布有:二元分布(Binomial distribution)、泊松分布(Poisson distribution)、正态/高斯分布(Normal distribution)
贝叶斯统计:实质是可信度的数量化
语言学基础:
朱德熙(1920-1992)语言、语法学家,著有《语法讲义》
面向信息处理的词语分类体系:实词(分为体词、谓词)、虚词(包括介词、连词、助词、语气词)、拟声词、叹词、其他类
各类词语的特点:
实词的主要特点:开放类、单独充当某种句法成分、位置不固定、具有较强的构词力、有比较具体的词义;体词(主语、宾语)和谓词(主要是做谓语、可做主宾)
名词主要特点:典型的体词、一般不受副词的修饰、可以受数量词的修饰、名词可以修饰名词、名词不能带表示时态的助词、名词不能做状语(这些特点都有例外,也正说明里语言的不确定性)
动词主要特点:最典型最主要的谓词、动名兼类、能愿动词有形态变化;
形容词:一类重要的谓词、能直接受“很”一类程度副词修饰、形容词可以带准宾语、绝大多数形容词可以接受否定副词“不”修饰、名形兼类、形动兼类、具有形态变化
虚词的主要特点:封闭类、不能充当句法成分、粘着性(实词的辅助作用)、位置比较固定、没有具体的词义、经常可以被省略;(虚词可以作为汉语语言分析的一个线索)
汉语句法分析的特点:(语言学分类角度可划分为:孤立语、屈折语、黏着语)
特殊性(孤立语的代表)、同一词类可担任多种句法成分且无形态变化、汉语句子的构造规则与短语的构造规则基本一致
汉语的语序特点:
短语内部语序严格固定、短语间语序比较灵活、
语言知识库:
北大计算语言研究所的相关工作:现代汉语语法信息词典、大规模现代汉语基本标注语料库、面向汉英机器翻译的现代汉语语义词典、英汉、日汉对照双语语料库、(各个)专业领域术语库、现代汉语短语结构规则库、中国古代诗词语料库;
音字转换系统语言知识库:如:机器ji1qi4、激起ji1qi3、吉期ji2qi1、及其ji2qi2等
在语言处理中发挥作用的知识库:现代汉语语义词典:安乐/形 D378、安理会/名 L16、安谧/形 D405、……(后面的编号为语义分类编号)
Ontology:不仅包含概念的集合,它还含某一领域里的公理体系,特别包含某一特定领域里面概念和概念之间的关系;可以理解为关于词汇的语义知识库。不同领域有不同的ontology
Hownet--知网(语义知识库):目前,作为从事中文词汇语义学研究的大型语义词典,董振东先生和他的儿子历经10年、创作了以汉语和英语的词语所代表的概念为对象,以揭示概念和概念以及概念所具有的属性的关系为基本内容的常识知识库;其中每一个词汇都给出了丰富的语法和语义的定义,如下:(Hownet是一个Ontology)

其中上述内容为:NO.:词号、W_C:词形、G_C:中文词性、E_C:中文语义举例、W_E:英语翻译、G_E:英语词性、E_E:英文语义举例,进一步下面义素分析法才可以真正说明Hownet是一个Ontology、

Hownet靠目标词汇,通过义原以及定义该义原与该词汇分关系,来说明一个词汇,如:人为一个义原。
知网可以告诉我们:
词汇的同义、反义、对义集合,上下位的概念

语义相似度计算:
基于语言知识库的语义相似度计算:(两个词汇之间的语义有一个通路,其通路越短,语义相似度越高);
基于统计的语义相似度计算:两个词汇具有一定的相似程度,当且仅当它们出现在相似的语言环境中,上下文出现的情况越接近,语义的相似度就越高。
如何构造比较专业的语言知识库:
机器可读词典(Machine readable dictionary、Lexicon:特指应用于自然语言处理的应用中的词表,只是关于词汇的读音等等这方面的信息)
构造lexicon的方法:文本文件方式(该方式太显而易见了,不利于知识产权的保护)、数据库方式(保密性高,存储效率高)、二进制文件方式(比较好)


二进制文件库的读取:fread
二进制文件库的更新:内存指针操作
二进制文件库的访问:Binary Search、Hash
标签:com 有一个 文字 如何 现象 模型 基础 缺点 诗词
原文地址:https://www.cnblogs.com/han-bky/p/10088692.html