标签:des style blog http color io os 使用 ar
好久没有更新过我的博客了,主要前一阵子去了实习,现在实习进入尾声,终于有机会看看书了。
在前一阵子的实习中,用到最多就是PHP的CI框架和Jquery,所以现在再看一本有关PHP的书籍来深刻认识一下PHP吧。也推荐一下大家看这本书:http://book.douban.com/subject/2071057/
话不多说,直接总结点有用的东西吧。
许多模块提供了一些函数来处理外部事务。例如:每一个数据库扩展至少有一个函数来连接数据库,一个函数来向数据库发送查询,一个函数来关闭数据库连接。因为可以同时打开多个数据库连接,连接函数需要提供标识不同连接的办法:资源(或称句柄)。这样当你调用数据库查询和关闭函数时,才知道使用哪个链接。
资源实际上是整数。使用资源的主要好处是它会自己完成内存管理。当最后一个对资源值的引用销毁时,创建该资源的扩展被调用来为该资源释放所有内存,关闭所有连接等。
$res = database_connect(); //假定的数据库连接函数
database_query($res);
$res = "boo"; //数据库连接自动关闭
在一个函数中我们最容易发现自动清空资源的好处,将资源指派给一个局部变量,当函数调用结束时,变量的值会自动被PHP回收:
function search(){
$res = database_connect();
database_query($res);
}
当没有任何对资源的引用时,它会自动关闭。
尽管资源可以自动销毁,大多数扩展提供了一个特定的关闭或结束函数。在合适的地方显示地调用该函数,这种方式比依赖于变量作用域来触发资源销毁更好。
使用is_resource()函数可测试一个值是否为资源;
if(is_resource($x)){
//$x 是一个资源
}
PHP使用引用计数(reference counting)和写时复制(copy-on-write)来管理内存。写时复制保证了在变量间复制值时不浪费内存,引用计数保证了不再需要时将内存交还给操作系统。
要理解PHP里的内存管理,首先要知道符号表(symbol table)的思想。一个变量有两部分——变量名(如$name)何变量值(如"Fred")。符号表是一个将变量名映射到内存中变量值所在地址的数组。
当从一个变量复制值到另一个变量是,PHP没有为复制值使用更多的内存。相反,它更新了符号表来说明“这两个变量都是同一个内存块的名字”。所以下面的代码实际上并没有创建一个新数组:
$worker = array("Fred",35,"Wilma");
$other = $worker; //数组没有被复制
如果后来修改了任意一个拷贝,PHP将分配所需的内存来产生复制:
$worker[1] = 36;
通过延迟分配和复制,PHP在很多情形下节省了时间和内存,这就是写时复制。
符号表指向的每一个值都有一个引用计数(reference counting),它的数值表示取得那块内存的途径数目。在将数组初值赋给$worker和将$worker赋给$other之后,符号表中指向数组条目($worker和$other)的引用计数为2。换言之,那片内存有两种取得方式:
通过$worker或$other。但是在$worker[1]改变后,PHP为$worker创建了一个新的数组,并且每个数组的引用计数都只有1。
当一个变量离开作用域时(就像一个函数参数或局部变量到达函数结尾时),它的值的引用计数减为1。当一个变量在其他内存空间被赋值时,旧值得引用计数减1。当对一个值的引用计数到达0时,它的内存就会被释放。这就是引用计数。
引用计数是管理内存的较好方式。保持变量作用域限制于函数中,通过值来传递,并让引用计数来管理内存。如果你想要主动获得更多的信息和控制权来释放变量的值,可以使用isset()和unset()函数。
查看一个变量是否被设置甚至是空字符串,使用isset():
$s1 = isset($name); //$s1是false
$name = "Fred";
$s2 = isset($name); //是true
使用unset()来移除一个变量的值:
$name = "Fred";
unset($name); //值为NULL
PHP提供了两种结构从其他模块加载代码和HTML:require和include。两者的区别在于:尝试require一个不存在的文件将导致一个致命错误(fatal error)而停止脚本的执行;而尝试include一个不存在的文件则产生一个警告(warning),不会停止脚本的执行。如果PHP不能解析文件中用include或require包含的某些部分,将会打印出一个警告并继续执行。可以通过预先调用错误屏蔽操作符(@)来屏蔽出错警告,例如:@include。
1.可变参数的函数:通过函数func_num_args(),demo如下:
<?php
function count_list(){
if(func_num_args() == 0){
return false;
}
else{
for($i = 0;$i < func_num_args();$i++){
$count_list += func_get_arg($i);
}
}
}
echo count_list(1,5,9);
2.返回值:
PHP函数可以使用return关键字返回一个单值:
function return_one(){
return 42;
}
要返回多个值,则需要返回一个数组:
function return_two(){
return array("Fred",35);
}
默认从函数中复制出值。在函数声明时如果函数名前有“&”符号的话,则返回对其返回值的引用(别名):
$names = array("Fred","Barney","Wilma","Betty");
function &find_one($n){
global $names;
return $names[$n];
}
$person = &find_one(1); //Barney
$person = "Barnetta"; //改变了$names[1]
在这段代码中,find_one()函数返回$name[1]的别名,而不是$name[1]值的拷贝。因为我们是通过引用赋值,所以$person是$names[1]的别名,并且第二个赋值操作改变了$name[1]中的值。
这个技术有时被用于高效地从函数返回大型字符串或数组的值。然而,PHP的写时复制/浅复制(copy-on-write/shallow-copy)机制通常意味着从函数返回一个引用并不是必要的。除非你知道你可能将会改变数据,否则不必为一些大型的数据返回引用。返回引用的缺点是它比返回值慢,并且需要依赖shallow-copy的机制来确保在数据改变之前不会生成数据的副本。
1.在实际应用中,这意味着除非你需要包含转义序列或替换变量才使用双引号,否则应该使用单引号括起来的字符串。
2.大括号的经典作用是把变量名从周围的文本中分隔出来。
$n = 12; echo "You are the {$n}th Person"; You are the 12th Person
如果没有大括号的话,PHP就会尝试打印出变量$nth的值。
3.关于单括号:
在用单括号括起来的字符串中唯一可用的转义序列是\‘(把单引号放在用单引号括起来的字符串中),\\(把一个反斜杠放在用单引号括起来的字符串中)。任何其他的反斜杠只能被解释为一个反斜杠。
4.常见的字符串函数
1.关于索引数组,如果要通过变量替换得到某个数组元素,则键名不要使用引号:
//这些是错误的
print "Hello, $person[‘name‘]";
print ‘Hello, $person["name"]‘;
//这是正确的
print "Hello, $person[name]";
2.关于一些数组的常用函数:
array array_pad ( array $input , int $pad_size , mixed $pad_value )
2. 析取数组中的多个值:要把一个数组的所有值都复制到变量当中,可以使用list()结构:
<?php
$person = array("Fred",35,‘Betty‘);
list($name,$age,$wife) = $person;
?>
3. 析取数组:要析取数组的一个子集,可以使用array_slice()函数:
array array_slice ( array $array , int $offset [, int $length = NULL [, bool $preserve_keys = false ]] )
<?php
$people = array(‘Tom‘,‘Dick‘,‘Harriet‘,‘Brenda‘,‘Jo‘);
$middle = array_slice($people,2,2); //$middle为array(‘Harriet‘,‘Brenda‘)
?>
4. 数组分块:要把数组划分为小数组或固定大小的数组,可以使用array_chunk()函数:
array array_chunk ( array $input , int $size [, bool $preserve_keys = false ] )
5.检查元素是否存在:使用array_key_exists()函数:
bool array_key_exists ( mixed $key , array $search )
注意:在检查数组元素是否存在时,简单地这样进行判断是不够的:
if($person[‘name‘]){...} //这样会让人误解
即使数组中有一个元素使用了键name,它对应的值也可能是false(例如:0,NULL或空字符串),所以我们要用使用array_key_exists()来代替。
6. 在数组中删除和插入元素:
array_splice()函数可以在数组中删除或插入元素,并且可以用被删除的元素创建另一个数组:
array array_splice ( array &$input , int $offset [, int $length = 0 [, mixed $replacement ]] )
7. 在数组和变量间转换:
·从数组创建变量:extract()函数自动地从一个数组创建局部变量。数组元素的键名就是变量名:
extract($person); //变量$name,$age和$wife现在被设置。
·从变量创建数组:compact()函数和extract()函数互补。将多个变量名或单个数组作为参数传递给compact(),可合并一个数组。compact()函数创建一个关联数组,它的键是变量名并且值为变量的值。
array compact ( mixed $varname [, mixed $... ] )
8. 迭代器函数
current() —— 返回迭代器当前指向的函数;
reset() —— 移动迭代器到数组的第一个元素并返回该元素;
next() —— 移动迭代器到数组的下一个元素并返回该元素;
prev() —— 移动迭代器到数组的上一个元素并返回该元素;
end() —— 移动迭代器到数组的最后一个元素并返回该元素;
each() —— 以数组的形式返回当前元素的键和值,并移动迭代器到数组的下一个元素;
key() —— 返回当前元素的键;
9. 为数组的每个元素调用函数
PHP提供了一个函数array_walk(),用于为数组中的每个元素调用用户自定义函数;
bool array_walk ( array &$array , callable $funcname [, mixed $userdata = NULL ] )
10. 数组归纳
array_walk()的近似函数array_reduce(),用于为数组中的每个元素调用用户自定义函数:
mixed array_reduce ( array $input , callable $function [, mixed $initial = NULL ] )
11. 查找元素值
in_array()函数返回true或false,取决于第一个参数是否是第二个参数指定的数组中元素:
bool in_array ( mixed $needle , array $haystack [, bool $strict = FALSE ] )
12. 排序——*sort()函数
13. 翻转数组
array_reverse()函数翻转数组中元素的内部顺序:
$reserved = array_reserve(array);
array_flip()函数返回数组,它翻转了每个元素的键-值对的顺序(键值互换):
$flipped = array_flip(array);
(如果原数组中有几个元素的值相等,则互换后最后一个键名将作为它的值,所有其他键名的都将丢失。)
14. 随机顺序——shuffle()
15. 作用于整个数组
16. 键(Key)和值(Value):
array array_keys ( array $input [, mixed $search_value = NULL [, bool $strict = false ]] ) //键
array array_values ( array $input ) //值
1.构造函数
PHP并不支持构造函数链的自动调用,也就是说,当你实例化子类时,只有子类自己的构造函数会被调用,父类的构造函数是不会被调用的。为了使父类的构造函数也被调用,你要在子类的构造函数中显式地调用父类的构造函数。
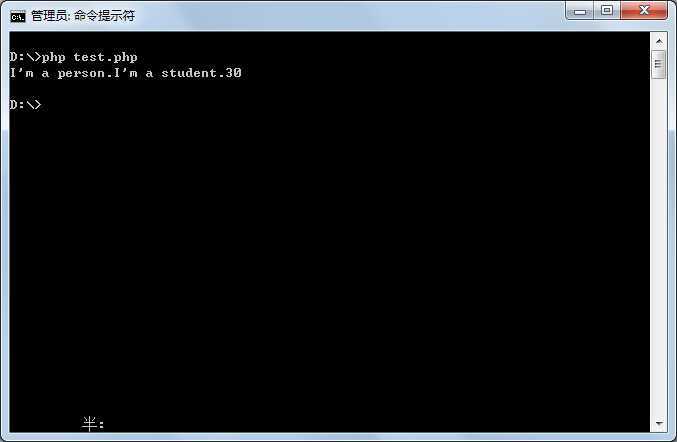
<?php
class Person {
public $age;
function __construct(){
echo "I‘m a person.";
$this->age = 30;
}
function getAge(){
$this->age = 30;
return $this->age;
}
}
class Student extends Person {
function __construct(){
parent::__construct();
echo "I‘m a student.";
}
}
$student = new Student;
echo $student->getAge()."\n";
?>
2.自省
自省是一种让程序检查对象特性的机制,可以检查对象的名称,父类(如果存在),属性和访问等。下面是相关的一些函数:
1.Get方法和Post方法:
一个Get请求把表单的参数编码成URL形式,这也称作查询字符串:
/path/to/chunkify.php?word=despicable&length=3
一个Post请求则通过http请求的主体来传递表单参数,不需要考虑url。
Get和Post方法的最明显区别在于URL行。因为Get请求的所有表单参数都编码在URL中,用户可以把一个GET请求加入浏览器收藏夹,而对POST请求却无法这样做。
GET和POST请求之间的最大不同是相当微妙的。HTTP规范指明GET请求是幂等的——也就是说,一个对于一个特定URL的GET请求(包含表单参数),与对应于这一特定URL的GET请求(包含表单参数),与对应于这一特定URL的两个或多个GET请求是一样。因此,Web浏览器可以把GET请求(包含表单请求),与对应于这一特定URL的两个或多个GET请求是一样的。因此,Web浏览器可以把GET请求得到的响应页面缓存起来。这是因为不管页面被请求了多少次,响应页面都是不变的。正因为幂等性,GET请求只适用于那些响应页面永不改变的情况,例如将一个单词分解成小块,或者对数字进行乘法运算。
POST请求不具有幂等性。这意味着它们无法被缓存。在每次刷新页面时,都会重新连接服务器。显示或者刷新页面时,你可能会看到浏览器提示“Repost from data?(重新发送表单数据)"。所以POST适用于响应内容可能会随时间改变的情况,例如:显示购物车的内容,或者在一个论坛中显示当前主题。
现实中,幂等性常常被忽略。目前浏览器的缓存功能很差,并且”刷新“按钮很容易被用户点到,所以程序员通常只考虑是否想将参数显示在浏览器的URL地址栏上,如果不想显示,就用POST方法。但你要记住,在服务器的相应页面可能会变化的情况下(例如下订单或者更新数据库),不要使用GET方法。
2.表单验证:
当你允许输入数据时,你通常需要在使用和存储这些数据之前进行验证。有多种验证用户数据的方法。首先是在客户端使用JavaScript。但是用户可以禁用JavaScript,甚至使用一个不支持JavaScript的浏览器,所以用这个方法还不够。
3.维持状态:
HTTP是一个无状态的通讯协议,这意味着一旦Web服务器完成了客户端的Web页面请求,它们之间的连接也就断开了。换句话说,我们无法使服务器识别来自于同一个客户端的一系列请求。
为了解决Web状态不维持的问题,程序员提出了不少在两次请求间跟踪状态信息的方法(这称为会话跟踪,session tracking)。其中一种方法是使用隐藏的表单字段来传递信息。因为PHP以对待正常表单字段的方式来对待隐藏表单字段,所以可以通过$_GET和$_POST数组访问隐藏表单字段的值。
另一个方法是URL重写,用户访问的每一个URL都加上附加的信息,附加信息作为URL的参数。
实现状态维持的第三种方法是使用cookie。Cookie是服务器给客户端的一些信息。在后继的请求中,客户端将把信息返回给服务器,这样就可以标识自己的身份。Cookie对于浏览器重复访问是保持客户端信息很有用,但它也有不足的地方。主要问题是有些浏览器不支持cookie,即使支持,用户也可以禁用cookie。所以使用cookie来维持状态的程序需要使用另一个叫回退的机制。
在PHP中维持状态的最好方法是使用其内置的会话跟踪系统(session-tracking system)。该系统允许你创建一个持久性变量。从程序的不同页面和同一用户对站点的不同访问都可以访问该变量。PHP的会话跟踪机制使用cookie(或URL)在后台优雅地解决了维持状态的大部分问题。
4.Cookie:
使用cookie有很多需要注意的地方。不是所有客户端支持和接受cookie,即使支持,用户可能禁用cookie功能。另外,cookie规范规定了cookie不能大于4KB,一个域只能发送20个cookie,而且一个客户端只能存储300个cookie。有的浏览器可能限制宽松一些,但你不能依赖于此。最后,你无法控制客户端浏览器使cookie过期——当浏览器有能力并且需要新增一个cookie时,它将抛弃一个没有过期的cookie。你在使cookie短时间内过期时要小心,过期时间取决于客户端机器的时钟,它未必和服务器时钟一样准。有很多用户的机器时间是不准的,所以你不能依赖于快速过期。
尽管有这么多限制,cookie仍不失为一种在浏览器重复访问时保持信息的实用方法。
1.输入过滤:
创建安全系统最基本的观念之一是:任何不在系统内部生成的信息都应被视为“污点”,即潜在的危险。由这个观念,我们可以推论出:每一个输入数据都是危险的,可能被污染的,因为它们都是在系统外部产生的。
当我们说数据被“污染”,并不代表它就不安全。只是说它可能是不安全的,如果我们无法确定它的来源,就必须要检查和判断数据的有效性以确保安全。这个检查的过程叫做过滤。你必须确保只有安全有效的数据进入你的程序。
下面列举一些在过滤过程中的最佳实践的法则:
在过滤之前,不要相信任何数据的安全性。
2.SQL注入和转义输出:
转义是一种当数据进入另外的上下文环境时,仍然保持原有的数据的技术。PHP常常被用作不同的数据源之间的桥梁。当发送数据到一个远端的数据源时,你有责任保持正确的数据,使它不会被错误地解析。
PHP应用程序会发送到两个主要的数据源是:解析HTML,Javascript和其他客户端技术的HTTP客户端和解析SQL的数据库。对于前者,PHP提供了htmlentities()函数:
<?php $html = array(); $html[‘username‘] = htmlentities($clean[‘username‘],ENT_QUOTES,‘UTF-8‘); echo "<p>Welcome back, {$html[‘username‘]}.</p>"; ?>
而对于后者,大多数数据库提供原生的数据转义函数。例如MySQL扩展提供mysql_real_escape_string()函数。
3.总是初始化你的变量,这在当register_globals指令打开时尤其重要。
4.关闭register_globals,magic_quotes_gpc和allow_url_fopen。
5.每次使用用户提供的数据构造一个文件名时,都要用basename()和realpath()来检查其组成。
6.将包含的文件存储在网页跟目录(document root)之外,最好不要用.inc为扩展名来命名你要包含的文件。而用.php为扩展名来命名它们,或者是其他并不明显的扩展名。
7.每当用户的权限等级改变时,都要调用session_regenerate_id()函数。
8.不要创建一个文件然后在修改它的权限。相反,设置umask()以便文件使用正确的权限来创建。
9.不要在eval(),带有/e选项的preg_replace()以及任何系统命令(exec(),system(),popen(),passthru()和反引号操作符)中使用用户提供的数据。
1.代码库
常用的三个函数:require(),require_once(),include()和include_once();
2.模板系统
网上一大堆,诸如smarty之类的,不说了。
3.输出及缓冲区
可以看我转的另外一篇文章,看完非常够用。http://www.cnblogs.com/sysu-blackbear/p/4022238.html
4.压缩输出:
现在的浏览器都可以压缩和解压缩Web页面中的文本信息;服务器端可把已经压缩的文本信息发送到客户端浏览器并在浏览器端解压缩。要自动压缩你的Web页面,要像这样对它进行包装:
<?php ob_start(‘ob_gzhandler‘); ?>
对短小的页面进行压缩是没有太大意义的,因为压缩和解压缩所花费的时间将会超过它发送的时间。但是,对于较大的web页面(大于5kb)来说压缩传输是非常有意义的。
如果不想在每个PHP页面的顶部调用ob_start(),你也可以在你的php.ini文件中设定output_handler选项的值为一个回调函数来使他对于每一个页面都生效。如果要进行压缩的话,该选项的值应该设定为ob_gzhandler。
5.错误处理
·错误报告:int error_reporting ([ int $level ] )
·禁止出错信息:$value = @(2/0); error_reporting(0);
·触发错误:可以用trigger_error()函数在脚本中抛出一个错误:bool trigger_error ( string $error_msg [, int $error_type = E_USER_NOTICE ] )
function divider($a,$b) { if($b == 0) { trigger_error(‘$b cannot be 0", E_USER_ERROR); } return ($a / $b); } echo divider(200,3); echo divider(10,0);
·打印错误日志:bool error_log ( string $message [, int $message_type = 0 [, string $destination [, string $extra_headers ]]] )
6.代码优化
优化执行时间(Optimizing Execution Time):
·如果echo可以满足你的需求,避免使用printf();
·避免在循环里面重新计算数值,因为PHP解释器不会移除循环中的不变的量。例如:如果$array的大小没有变化,请不要这么做:
for ($i = 0; $i < count($array); $i++) { /* do something */ }
相反,要像这样做:
$num = count($array); for ($i = 0; $i < $num; $i++) { /* do something */ }
·只包含(include)你需要的文件,将要包含的文件切分成只包含要用到的函数。虽然这样代码可能会有一点难于管理,但可以降低不少代码解析时的开销。
·当一个简单的字符串操作函数可以满足需要时,不要使用正则表达式,例如,将字符串中的一个字符转换为另外的字符,使用str_replace(),而不是preg_replace();
优化内存需求(Optimizing Memory Requirements):
这里有一些技巧,可以帮助你减少脚本的内存需求:
·尽可能使用数字代替字符串
for($i = 0; $i < "10"; $i++) //不好的作法 for($i = 0; $i < 10; $i++) //好的作法
·使用完一个很大的字符串,请将容纳那个字符串的变量设置为一个空字符串。这样可以释放内存以便重新利用。
·只include或者require实际需要的文件,使用include_once或者require_once代替include和require。
·如果使用MySQL并且产生了很大的数据集,考虑使用MySQL专用的数据库扩展,你可以使用mysql_unbuffered_query()函数。该函数并不会立刻将整个数据集载入到内存中,而是在需要时逐行进行读取。
·当使用完MySQL或其他数据库的数据集后,尽快释放它们。在用完它们之后还在内存中维持这些数据是没有任何好处的。
7.反向代理和数据同步
虽然添加硬件通常是获得更高性能的最快的方式,但最好还是先对你的软件进行性能测试,通常来说,修改软件比购买新的硬件成本更低。以下是3种常见的针对高流量瓶颈的解决方案:反向代理缓存,负载均衡服务器和数据库同步。
反向代理缓存:
反向代理(reserve proxy)是位于Web服务器前的一个程序,它处理从客户端浏览器发来的所有连接。代理经过优化,可以快速处理静态页面。大多数的动态站点都可以在一小段时间内缓存起来而不会影响服务。通常,你要用Web服务器之外的一台独立的机器来运行反向代理程序。
举个例子,假设有一个繁忙的站点,它的首页每秒钟被访问50次。如果首页页面中包含两个数据库查询,并且数据库更新的频率是一分钟两次,那么通过使用Cache-Control头信息告诉反向代理对页面缓存30秒,每分钟你可以避免5994次数据库查询。这样做最坏的结果是从数据库更新到用户,看到这个新的信息有30秒的延迟。对于大多数应用来说,30秒并不是很严重的延迟,而且给性能提升带来很大的益处。
反向代理甚至可以智能地缓存那些根据浏览器类型,接受的语言或者类似特性进行个性化的或者定制的内容。典型的解决方法是发送不同的头信息给缓存,告诉它哪些请求的参数会影响缓存过程。
现在有不少可用的硬件实现的代理缓存,同时也有非常好的软件实现的代理缓存。如:Squid。
负载均衡和重定向:
提高性能的另一种方法是把负载分摊到一组机器上。一个负载均衡系统(load-balancing system)可以均匀地分配负载或者将传入的请求发送到负载最小的机器上。重定向器(redirector)则是一个对传入的URL地址进行重写的程序,它可以精细控制分配请求到单个服务器的过程。
再次强调,完成重定向和负载均衡的软件是SquidGuard。
MySQL同步:
有时候数据库服务器是整个应用的瓶颈——大量并发请求可以让数据库服务器陷入瘫痪状态,从而导致性能下降。同步是最好的解决方案之一,它让一个数据库中所有发生的事情很快地同步到一台或更多其他的服务器上,这样你就得到了多个完全一样的数据库。这可以让你将查询分散到很多数据库服务器中,而不总是查询一台服务器。
最有效的模型是使用单向同步(one-way replication):系统中只有一台主数据库(master),将数据复制到几个从数据库(slave)。所有的数据库写操作都在主数据库进行,数据库读操作(即select)则平衡分布到多个从数据库上。这个技术针对于那些进行大量的读操作但是写操作很少的架构。大多数Web应用程序正好适合这种情况。
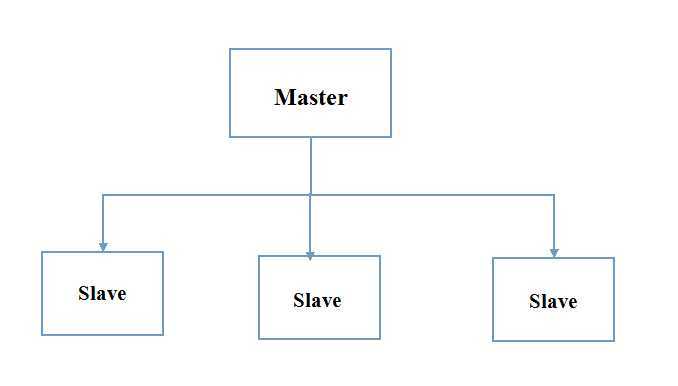
综合运用:
对于一个实际应用的高效的系统架构,我们需要综合应用以上提到的各种概念,来完成如图配置:
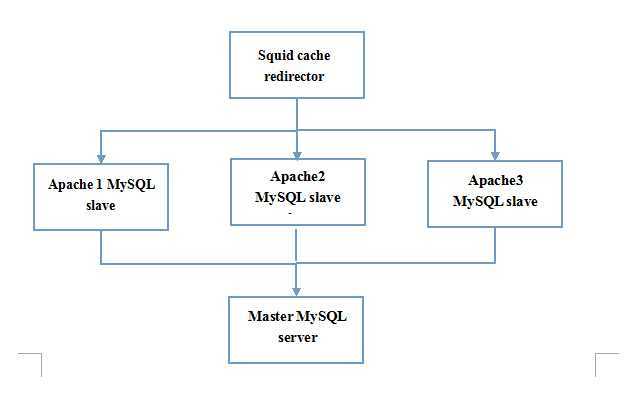
我们使用5个独立的服务器——一个用于反向代理和重定向器,3个Web服务器和1个主数据库。这个架构可以处理非常庞大数量的请求,其精确数量仅仅取决于两个瓶颈——单个的代理和单个的数据库主服务器。你可以试着做一些创新:将这两台服务器也切分成多个服务器。除此之外,如果你的应用程序是可以缓存的并且主要是进行数据库读操作的,那么这样的系统架构将是一个相当完美的解决方案。
每一个Apache服务器有它自己的只读MySQL服务器,PHP程序中所有的数据库读请求都经过一个UNIX-domain的本地socket连接到专门的MySQL实例上。在这个系统框架下面,你可以加入你所需要的任何数量的Apache/PHP/MySQL服务器。任何来自PHP脚本的数据库写操作请求将经过TCP socket到达MySQL的主服务器。
标签:des style blog http color io os 使用 ar
原文地址:http://www.cnblogs.com/sysu-blackbear/p/3991226.html