标签:test .sql author rgs 通过 组件 抽象 alt unit
spark SQL官网:http://spark.apache.org/docs/latest/sql-programming-guide.html
sparkSQL是构建在sparkCore之上的组件,用于处理结构化的数据。它将数据抽象为DataFrame并提供丰富的API,并且sparkSQL允许使用SQL脚本进行操作,使得数据查询变得非常的容易使用。
同时,sparkSQL除了操作简单,API丰富之外,对于数据源的支持也很强大。你可以从,如:
1)HDFS
2)Parguet文件
3)json文件
4)JDBC
5)ODBC
6)HIVE
等多种数据源来创建dataFrame,也可以从spark的RDD转换成dataFrame。
下面是scala的代码示例:
import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Row, SQLContext} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.{SparkConf, SparkContext} /** * @Description spark sql demo * @Author lay * @Date 2018/12/09 21:33 */ object SparkSQLDemo { var conf: SparkConf = _ var sc: SparkContext = _ var userData: Array[String] = Array("1 lay 23", "2 marry 24", "3 gary 25") var userRDD: RDD[Row] = _ var sqlContext: SQLContext = _ var df: DataFrame = _ def init(): Unit = { conf = new SparkConf().setAppName("spark sql demo").setMaster("local") sc = new SparkContext(conf) // 创建sqlContext sqlContext = new SQLContext(sc) // 创建schema var structFields = Array(StructField("id", IntegerType), StructField("name", StringType), StructField("age", IntegerType)) var schema = new StructType(structFields) // 创建RDD userRDD = sc.parallelize(userData).map{x => val lines = x.split(" ");Row(lines(0).toInt, lines(1), lines(2).toInt)} // 创建dataFrame df = sqlContext.createDataFrame(userRDD, schema) } def main(args: Array[String]): Unit = { init() // dataFrame方式查询:查询年龄大于23岁的用户的姓名 df.select("name").where("age > 23").show() // 注册为t_user表 df.createOrReplaceTempView("t_user") // SQL方式查询:年龄大于23岁的用户的姓名 sqlContext.sql("SELECT name FROM t_user WHERE age > 23").show() } }
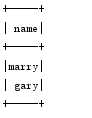
以上代码将RDD通过StructType转换成了dataFrame,然后分别采用dataFrame的API和SQL两种方式查询出了结果,如图:
标签:test .sql author rgs 通过 组件 抽象 alt unit
原文地址:https://www.cnblogs.com/lay2017/p/10093736.html