标签:自己 extractor ace class 上下 sele not name bottom
这篇博文本来是想放在全系列的大概第五、六篇的时候再讲的,毕竟查询是在索引创建、索引文档数据生成和一些基本概念介绍完之后才需要的。当前面的一些知识概念全都讲解完之后再讲解查询是最好的,但是最近公司项目忙经常加班,毕竟年底了。但是不写的话我怕会越拖越久,最后会不了了之了,所以刚好上海周末下雪,天冷无法出门,就坐在电脑前敲下了这篇博文。因为公司的查询这块是我负责的所以我研究了比较多点,写起来也顺手些。那么进入正文。
前面的文章介绍过,Elasticsearch 的官方查询语言是 Query DSL,既然是官方指定的,说明最吻合 ES 的强大功能,为ES做支撑。那么我们为什么还用 SQL 查询?这是否是多此一举了呢?
其实,存在毕竟有存在的道理,存在即合理。SQL 作为一个数据库查询语言,它语法简洁,书写方便而且大部分服务端程序员都清楚了解和熟知它的写法。但是作为一个 ES 萌新来说,就算他已经是一位编程界的老江湖,但是如果他不熟悉 ES ,那么他如果要使用公司已经搭好的 ES 服务,他必须要先学习 Query DSL,学习成本也是一项影响技术开发进度的因素而且不稳定性高。但是如果 ES 查询支持 SQL的话,那么也许就算他是工作一两年的同学,他虽然不懂 ES的复杂概念,他也能很好的使用 ES 而且顺利的参加到开发的队伍中,毕竟SQL 谁不会写呢?
我们正式介绍下我们的主角 - Elasticsearch-SQL,Elasticsearch-SQL不属于 Elasticsearch 官方的,它是 NLPChina(中国自然语言处理开源组织)开源的一个 ES 插件,主要功能是通过 SQL 来查询 ES,其实它的底层是通过解释 SQL,将SQL 转换为 DSL 语法,再通过DSL 查询。
Elasticsearch-SQL目前已经支持大概所有版本的 ES,而且最近的6.5.x的也在支持的范围了,所以可以看得出来维护的还是蛮频繁的。
由于 ES 2.x 和 5.x 的版本区别(详细参考:版本选择),我们安装 ES 插件是有点区别的,
在 5.0之前的安装方式为:plugin install
./bin/plugin install https://github.com/NLPchina/elasticsearch-sql/releases/download/2.4.6.0/elasticsearch-sql-2.4.6.0.zip在5.0之后(包括6.x)的安装方式为:elasticsearch-plugin install
./bin/elasticsearch-plugin install https://github.com/NLPchina/elasticsearch-sql/releases/download/5.0.1/elasticsearch-sql-5.0.1.0.zip如果我们安装不成功,我们可以直接下载 Elasticsearch-SQL 插件的压缩包,然后解压,完成之后重命名文件夹为 sql ,放到 ES 的安装路径的 plugins目录中,例如:..\elasticsearch-6.4.0\plugins\sql。
完成此操作后,需要重新启动Elasticsearch服务器,否则会报错:Invalid index name [sql], must not start with ‘‘]; ","status":400}。
Elasticsearch-SQL 插件提供了可视化的界面,方便你执行SQL查询,界面如下:
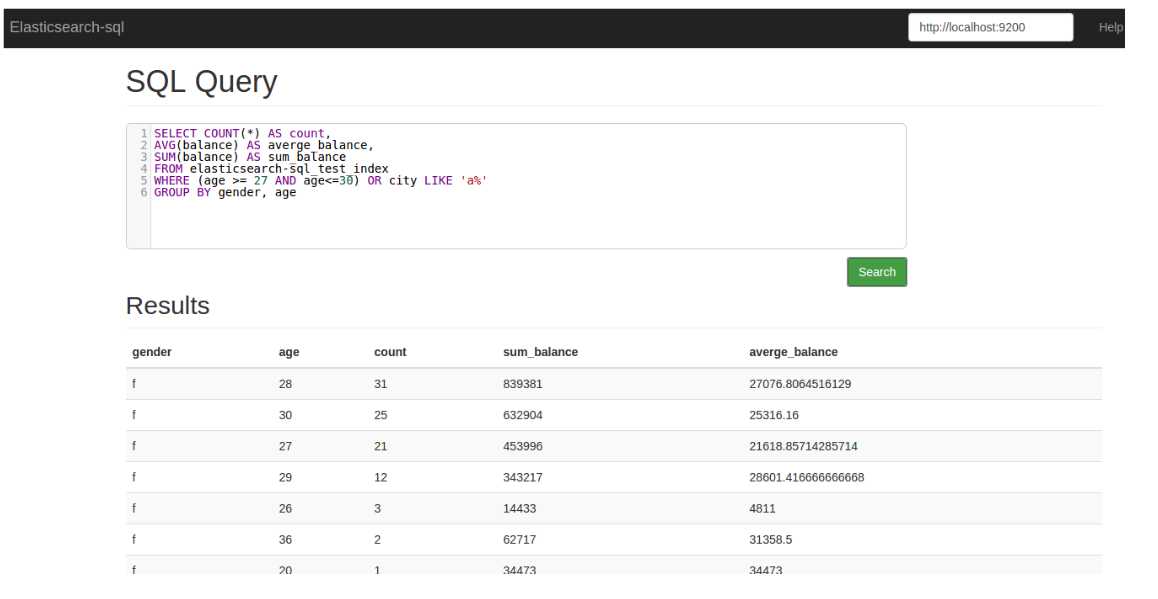
在 elasticsearch 1.x / 2.x,你可以直接访问如下地址:
http://localhost:9200/_plugin/sql/而在 elasticsearch 5.x/6.x,这需要安装 node.js 和下载及解压site,然后像这样启动web前端:
cd site-server
npm install express --save
node node-server.js 经过以上的操作之后,如果没出问题,现在就可以使用 SQL 查询 ES 了,其中有些是正常的 SQL 语法,还有些是超越SQL 语法的,相当于是对 SQL 语法的增强,ES 的查询格式是:
http://localhost:9200/_sql?sql=select * from indexName limit 10先上个简单的查询语法:
SELECT fields from indexName WHERE conditions可以看到,我们以前的查询语句中,表名 tableName 的地方现在改为了索引名 indexName,如果有索引Type ,还可以这样写:
SELECT fields from indexName/type WHERE conditions也可以同时查询索引的多个类型,语法如下:
SELECT fields from indexName/type1,indexName/type2 WHERE conditions如果想知道当前SQL是如何将SQL解释为Elasticsearch 的Query DSL,可以这样通过关键字explain。
http://localhost:9200/_sql/_explain?sql=select * from indexName limit 10聚合类函数查询
select COUNT(*),SUM(age),MIN(age) as m, MAX(age),AVG(age)
FROM bank GROUP BY gender ORDER BY SUM(age), m DESCSearch
SELECT address FROM bank WHERE address = matchQuery('880 Holmes Lane') ORDER BY _score DESC LIMIT 3Aggregations
SELECT COUNT(age) FROM bank GROUP BY range(age, 20,25,30,35,40)SELECT online FROM online GROUP BY date_histogram(field='insert_time','interval'='1d') SELECT online FROM online GROUP BY date_range(field='insert_time','format'='yyyy-MM-dd' ,'2014-08-18','2014-08-17','now-8d','now-7d','now-6d','now')Elasticsearch 可以把地理位置、全文搜索、结构化搜索和分析结合到一起。而Elasticsearch-sql 也基本支持所有地理位置相关的查询,对应 Elasticsearch的章节内容为Geolocation。
1、地理坐标盒模型过滤器
地理坐标盒模型过滤器(Geo Bounding Box Filter),指定一个矩形的顶部,底部,左边界和右边界,然后过滤器只需判断坐标的经度是否在左右边界之间,纬度是否在上下边界之间。
语法:
GEO_BOUNDING_BOX(fieldName,topLeftLongitude,topLeftLatitude,bottomRightLongitude,bottomRightLatitude)示例:
SELECT * FROM location WHERE GEO_BOUNDING_BOX(center,100.0,1.0,101,0.0)2、地理距离过滤器
地理距离过滤器( geo_distance ),以给定位置为圆心画一个圆,来找出那些地理坐标落在指定距离范围的文档。
语法:
GEO_DISTANCE(fieldName,distance,fromLongitude,fromLatitude)示例:
SELECT * FROM location WHERE GEO_DISTANCE(center,'1km',100.5,0.5)3、地理距离区间过滤器
范围距离过滤器(Range Distance filter),以给定位置为圆心,分别以两个给定的距离画圆,找出与指定点距离在给定最小距离和最大距离之间的点,和geo_distance filter的唯一差别在于Range Distance filter是一个环状的,它会排除掉落在内圈中的那部分文档。
语法:
GEO_DISTANCE_RANGE(fieldName,distanceFrom,distanceTo,fromLongitude,fromLatitude)示例:
SELECT * FROM location WHERE GEO_DISTANCE_RANGE(center,'1m','1km',100.5,0.50001)4、Polygon filter (works on points)
找出落在多边形中的点。 这个过滤器使用代价很大 。当你觉得自己需要使用它,最好先看看 geo-shapes 。
语法:
GEO_POLYGON(fieldName,lon1,lat1,lon2,lat2,lon3,lat3,...)示例:
SELECT * FROM location WHERE GEO_POLYGON(center,100,0,100.5,2,101.0,0)5、GeoShape Intersects filter (works on geoshapes)
这里需要使用WKT表示查询时的形状。
语法:
GEO_INTERSECTS(fieldName,'WKT')示例:
SELECT * FROM location WHERE GEO_INTERSECTS(place,'POLYGON ((102 2, 103 2, 103 3, 102 3, 102 2))更多关于地理的查询可以参考这里。
我们以本系列的第一篇教程中我们创建的索引 nba来作示例,如下:
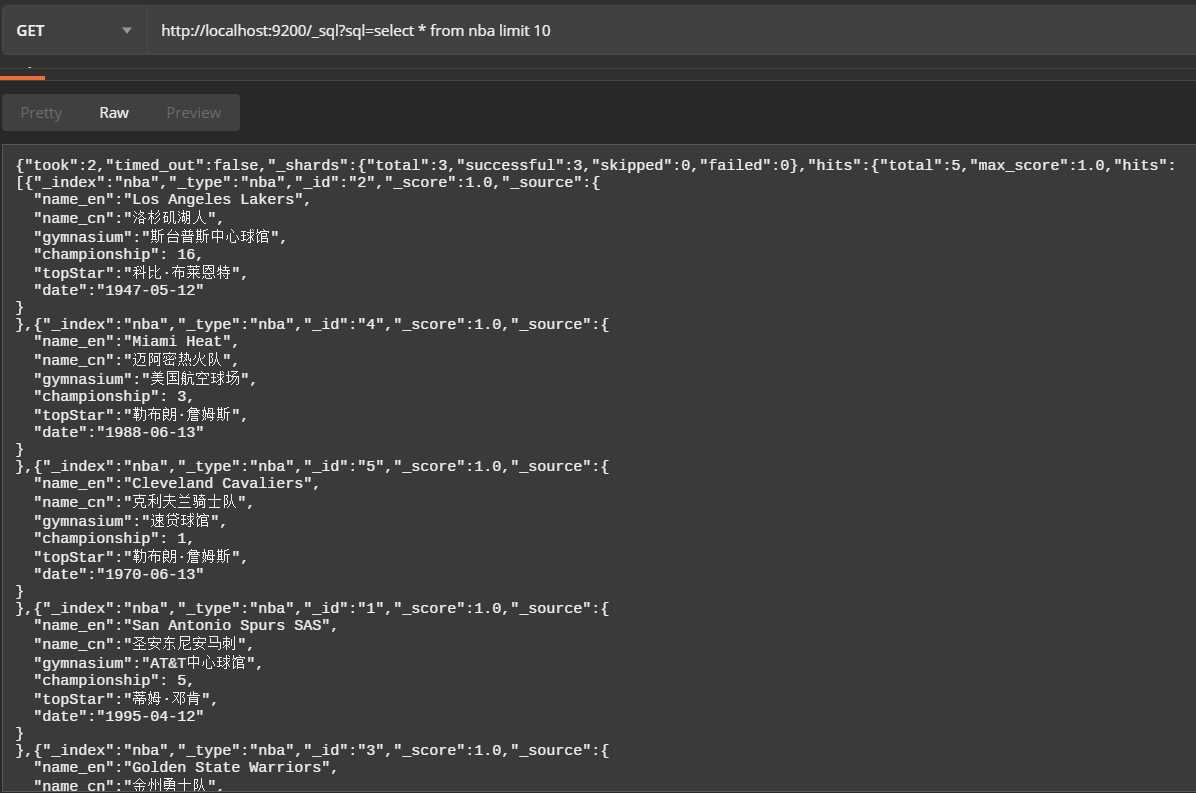
1、查询 nba 所有球队信息
http://localhost:9200/_sql?sql=select * from nba limit 10查询结果:
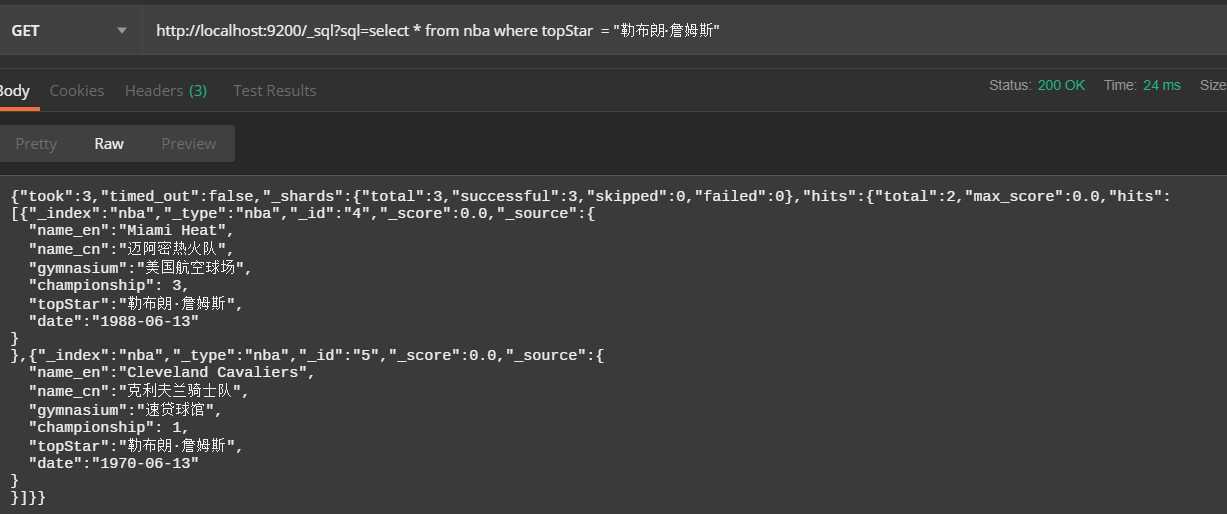
2、查询当家球星是詹姆斯的球队信息
http://localhost:9200/_sql?sql=select * from nba where topStar = "勒布朗·詹姆斯"查询结果:
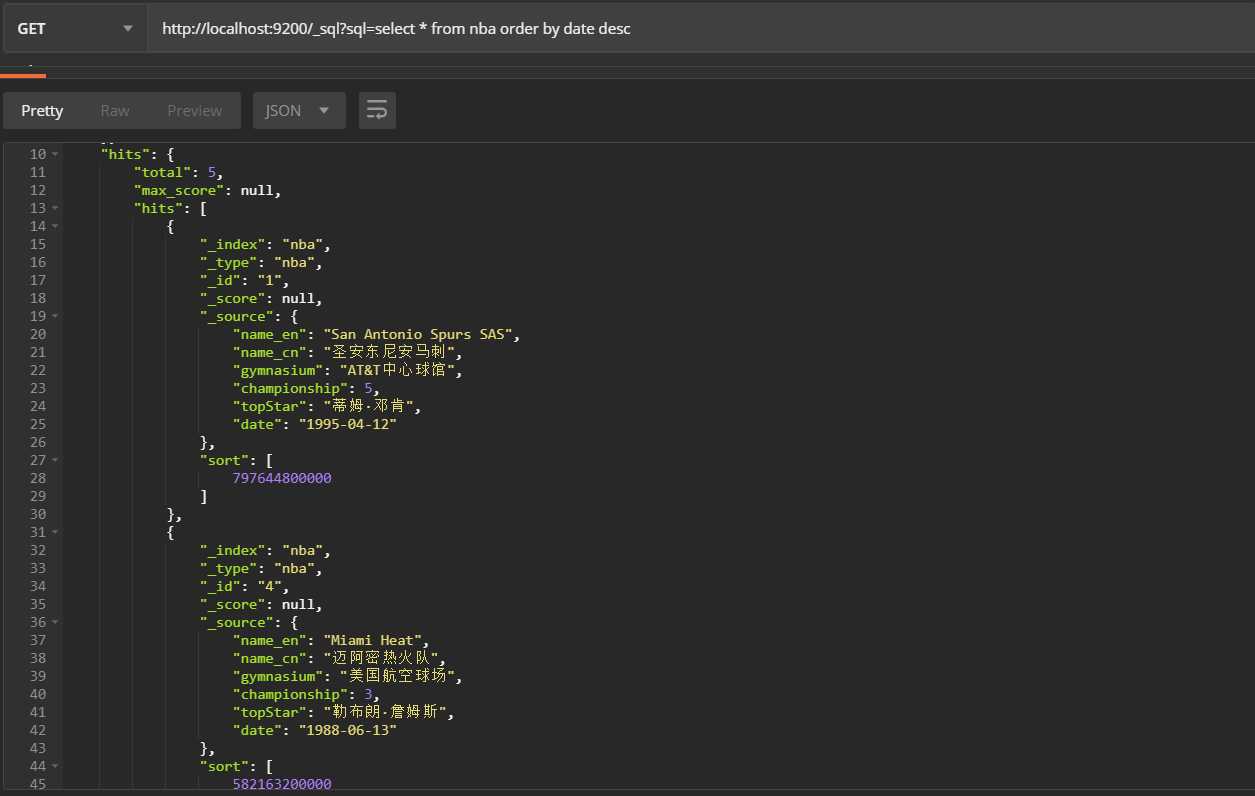
3、根据建队时间降序排列
http://localhost:9200/_sql?sql=select * from nba order by date desc查询结果:
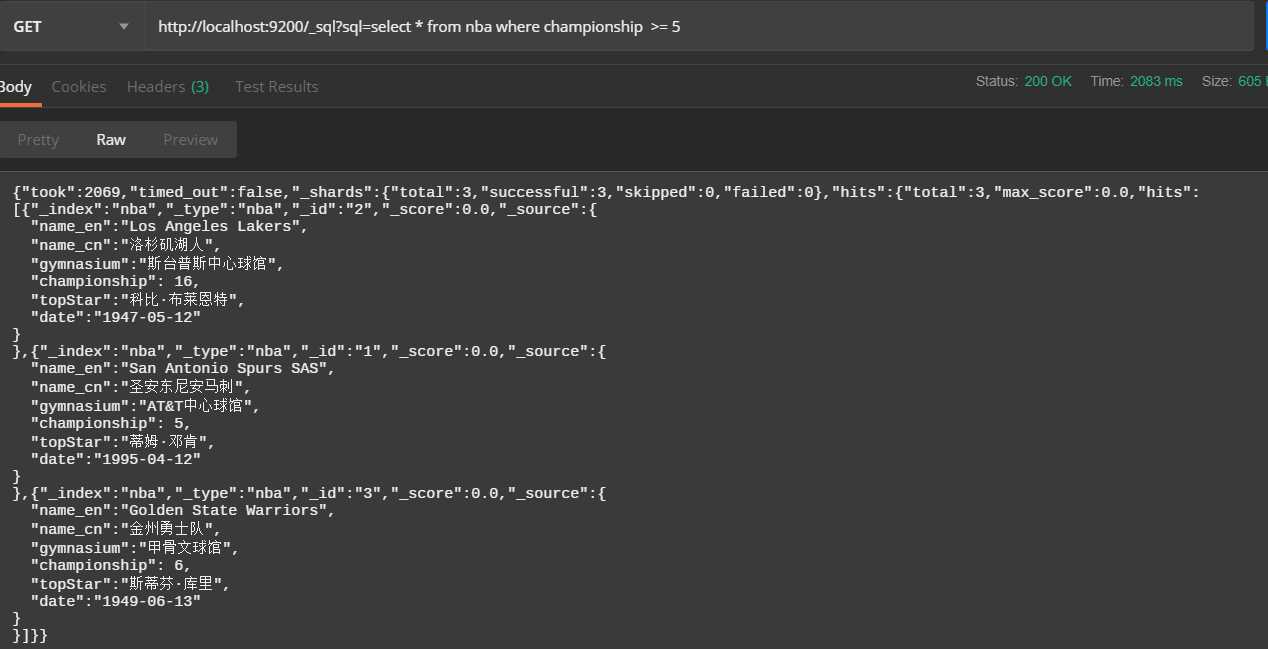
4、查询拥有总冠军超过5个的球队信息
http://localhost:9200/_sql?sql=select * from nba where championship >= 5查询结果:
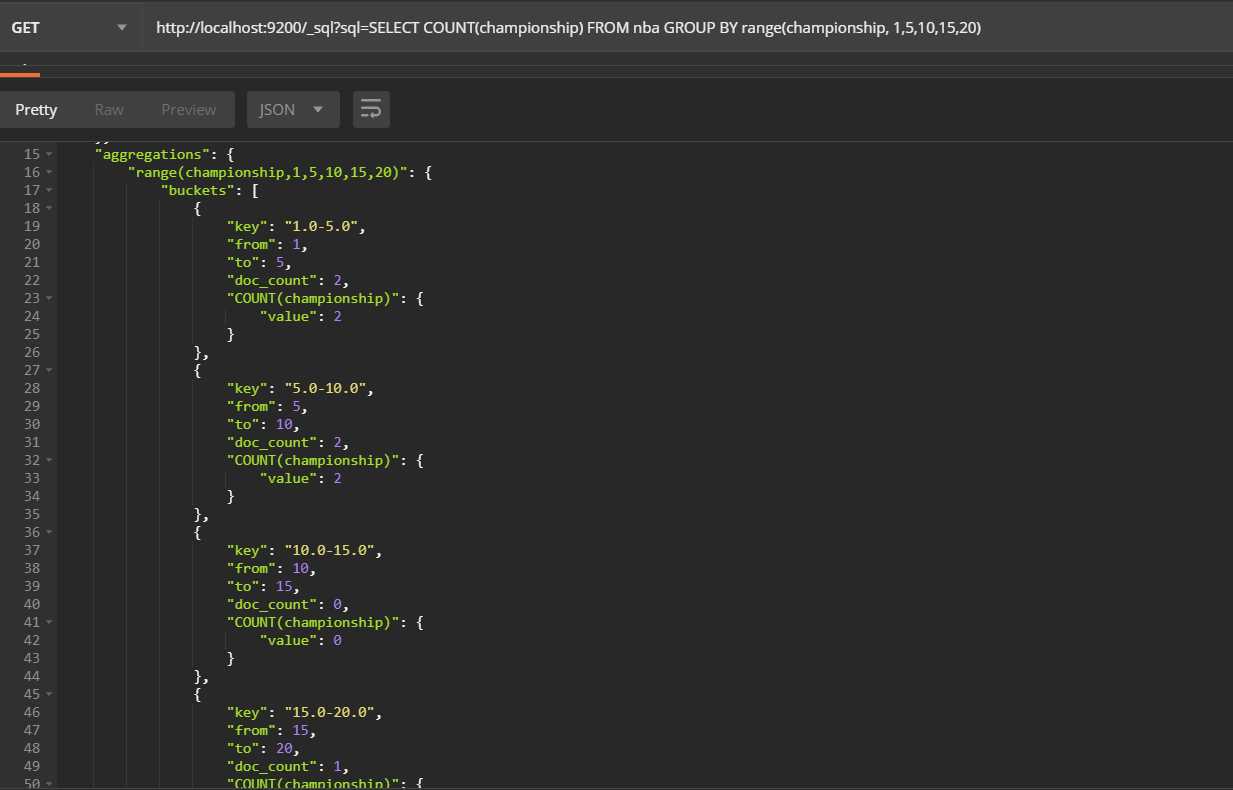
5、查询总冠军数量分别在1-5,5-10,10-15,15-20范围之间球队的数量
http://localhost:9200/_sql?sql=SELECT COUNT(championship) FROM nba GROUP BY range(championship, 1,5,10,15,20) 查询结果:
当然还有更多的写法,具体实现在这里就不多诉了,感兴趣的读者可以自己搭建个项目然后尝试下,更多特色SQL写法可以参考这里:
上面已经介绍了 Elasticsearch-SQL的安装和使用,那么我们如何在项目中使用它,Elasticsearch-SQL底层是使用Java语言开发的,通过解析SQL 转换为 DSL 语言,然后得出查询结果,解析结果成key-value的固定格式返回。
使用前我们需要先引入maven依赖
<dependency>
<groupId>org.nlpcn</groupId>
<artifactId>elasticsearch-sql</artifactId>
<version>x.x.x.0</version>
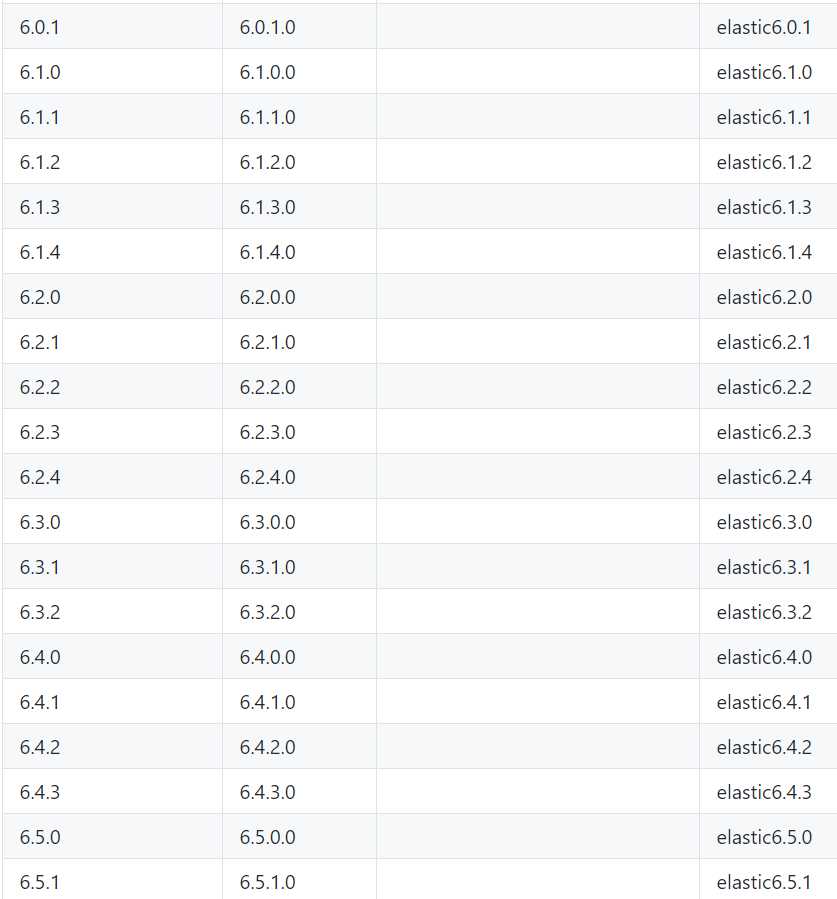
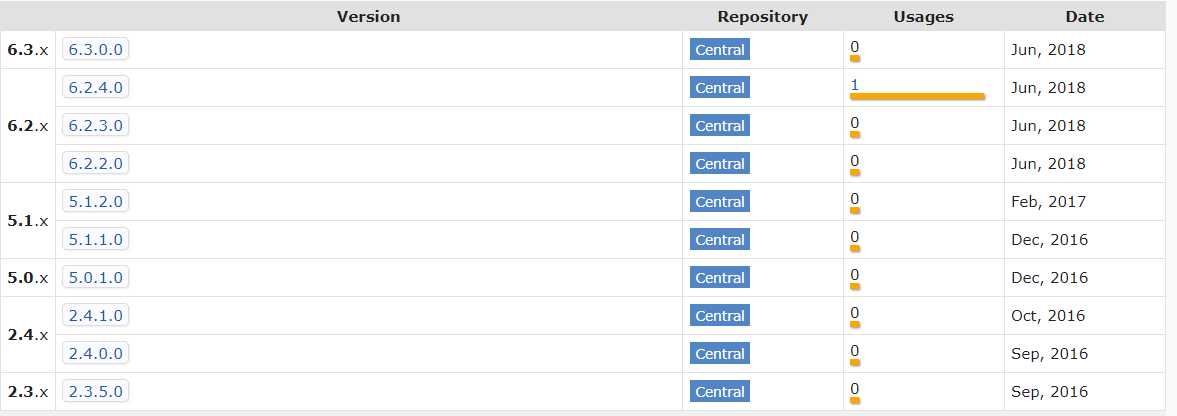
</dependency>版本号(x.x.x)需要和 Elasticsearch的版本对应上,具体的对应关系大致可以参考下图:

但是不是所有的版本,我们都可以从Maven Repository里获取到,我们如果直接从Maven 仓库里面只能获取如下几个版本的依赖,其中缺少很多版本:
那如果我们使用的是其他版本的 ES 如何解决依赖 jar包问题呢?还记得我们开始下载插件解压后的sql文件夹吗?例如6.5.0版本的插件的解压后文件夹内容如下:
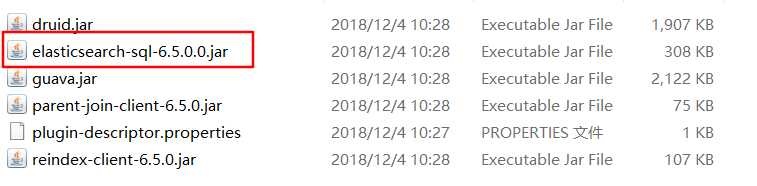
这里面就有我们需要的 jar包,有了 jar包就好办了,我们可以直接加入到项目中,当然最好的方式是上传到公司的私有仓库里面,然后通过pom文件依赖进来。
jar包问题解决之后就可以正式进入开发阶段了,新建一个springboot项目,引入各项依赖,一切准备就寻后,如何连接ES呢?
这里有两种方式可以实现我们的功能,一个是通过JDBC的方式,连接数据库一样连接ES。还有一种就是通过 tansport client 方式。
JDBC的方式
代码示例
public void testJDBC() throws Exception {
Properties properties = new Properties();
properties.put("url", "jdbc:elasticsearch://192.168.3.31:9300,192.168.3.32:9300/" + TestsConstants.TEST_INDEX);
DruidDataSource dds = (DruidDataSource) ElasticSearchDruidDataSourceFactory.createDataSource(properties);
Connection connection = dds.getConnection();
PreparedStatement ps = connection.prepareStatement("SELECT gender,lastname,age from " + TestsConstants.TEST_INDEX + " where lastname='Heath'");
ResultSet resultSet = ps.executeQuery();
List<String> result = new ArrayList<String>();
while (resultSet.next()) {
System.out.println(resultSet.getString("lastname") + "," + resultSet.getInt("age") + "," + resultSet.getString("gender"))
}
ps.close();
connection.close();
dds.close();
}这种方式是最直观的,用到了Druid连接池,所以我们还需要在项目中引入druid依赖,而且需要注意依赖的版本,否则会报错。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.15</version>
</dependency>这种方式很好理解,而且开发也方便,但是我在项目中应用了发现它有很多不足,所以我最后还是自己看了下源码,通过API的方式重新封装调用。
API方式
其实 elasticsearch-sql 没有提供开发的 文档,并没有介绍如何通过调用 Java API方式开发,我们需要阅读 elasticsearch-sql 的源代码来发现它的service,然后包装成我们需要的,通过阅读源码我们发现了如下一个功能明显的Service类。
public class SearchDao {
private static final Set<String> END_TABLE_MAP = new HashSet<>();
static {
END_TABLE_MAP.add("limit");
END_TABLE_MAP.add("order");
END_TABLE_MAP.add("where");
END_TABLE_MAP.add("group");
}
private Client client = null;
public SearchDao(Client client) {
this.client = client;
}
public Client getClient() {
return client;
}
/**
* Prepare action And transform sql
* into ES ActionRequest
* @param sql SQL query to execute.
* @return ES request
* @throws SqlParseException
*/
public QueryAction explain(String sql) throws SqlParseException, SQLFeatureNotSupportedException {
return ESActionFactory.create(client, sql);
}
}SearchDao 类中有一个explain方法,接收的参数就是一个字符串sql ,返回结果是 QueryAction ,QueryAction 是一个抽象类,它又有如下子类
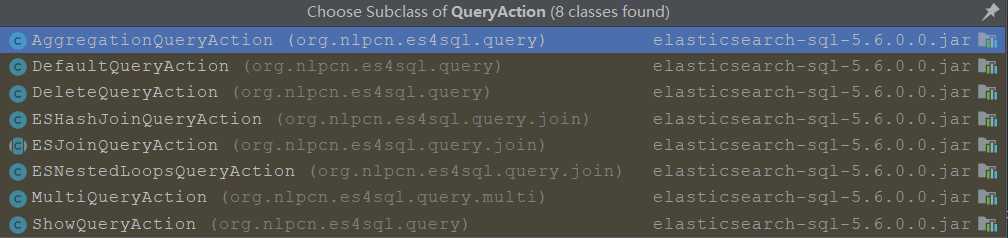
可以看出,每个子类对应的就是一个查询的功能,聚合查询,默认查询,删除,哈希连接查询,连接查询,嵌套查询等等。
获得的 QueryAction 我们可以通过 QueryActionElasticExecutor类的executeAnyAction方法来接受,并内部处理,然后就能获得相应的执行结果。
public static Object executeAnyAction(Client client , QueryAction queryAction) throws SqlParseException, IOException {
if(queryAction instanceof DefaultQueryAction)
return executeSearchAction((DefaultQueryAction) queryAction);
if(queryAction instanceof AggregationQueryAction)
return executeAggregationAction((AggregationQueryAction) queryAction);
if(queryAction instanceof ESJoinQueryAction)
return executeJoinSearchAction(client, (ESJoinQueryAction) queryAction);
if(queryAction instanceof MultiQueryAction)
return executeMultiQueryAction(client, (MultiQueryAction) queryAction);
if(queryAction instanceof DeleteQueryAction )
return executeDeleteAction((DeleteQueryAction) queryAction);
return null;
}虽然得到了查询结果,但是它是一个Object类型,我们还需要定制化一下,注意到了一个类:ObjectResultsExtractor,它的构造函数如下,构造函数包含三个布尔类型的参数。它们的作用是在结果集中是否包含score,是否包含type,是否包含ID,我们可以都设置为 false。
public ObjectResultsExtractor(boolean includeScore, boolean includeType, boolean includeId) {
this.includeScore = includeScore;
this.includeType = includeType;
this.includeId = includeId;
this.currentLineIndex = 0;
}ObjectResultsExtractor它仅有一个对外的 pulic 修饰的方法extractResults。
public ObjectResult extractResults(Object queryResult, boolean flat) throws ObjectResultsExtractException {
if (queryResult instanceof SearchHits) {
SearchHit[] hits = ((SearchHits) queryResult).getHits();
List<Map<String, Object>> docsAsMap = new ArrayList<>();
List<String> headers = createHeadersAndFillDocsMap(flat, hits, docsAsMap);
List<List<Object>> lines = createLinesFromDocs(flat, docsAsMap, headers);
return new ObjectResult(headers, lines);
}
if (queryResult instanceof Aggregations) {
List<String> headers = new ArrayList<>();
List<List<Object>> lines = new ArrayList<>();
lines.add(new ArrayList<Object>());
handleAggregations((Aggregations) queryResult, headers, lines);
// remove empty line。
if(lines.get(0).size() == 0) {
lines.remove(0);
}
//todo: need to handle more options for aggregations:
//Aggregations that inhrit from base
//ScriptedMetric
return new ObjectResult(headers, lines);
}
return null;
}至此我们就大致了解了它的查询API ,然后我们只需要在我们项目中做如下的代码调用就可以完成我们的查询功能了,最后得到的ObjectResult就是我们的最终查询结果集了。
//1.解释SQL
SearchDao searchDao = new SearchDao(transportClient);
QueryAction queryAction = searchDao.explain(sql);
//2.执行
Object execution = QueryActionElasticExecutor.executeAnyAction(searchDao.getClient(), queryAction);
//3.格式化查询结果
ObjectResult result = (new ObjectResultsExtractor(true, false, false)).extractResults(execution, true);至此,代码开发完成,我们来测试下运行结果,我对外提供了三个接口,一个是 API方式查询,一个是JDBC方式查询,还有一个解释SQL。
@RestController
@RequestMapping("/es/data")
public class ElasticSearchController {
@Autowired
private ElasticSearchSqlService elasticSearchSqlService;
@PostMapping(value = "/search")
public CommonResult search(@RequestBody QueryDto queryDto) {
SearchResultDTO resultDTO = elasticSearchSqlService.search(queryDto.getSql());
return CommonResult.success(resultDTO.getResult());
}
@PostMapping(value = "/query")
public CommonResult query(@RequestBody QueryDto queryDto) {
SearchResultDTO resultDTO = elasticSearchSqlService.query(queryDto.getSql(), queryDto.getIndex());
return CommonResult.success(resultDTO.getResult());
}
@PostMapping(value = "/explain")
public CommonResult explain(@RequestBody QueryDto queryDto) {
return CommonResult.success(elasticSearchSqlService.explain(queryDto.getSql()));
}
}请求示例:
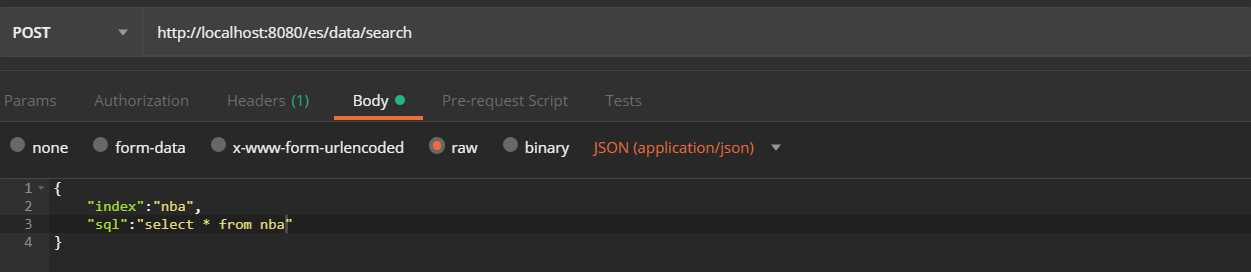
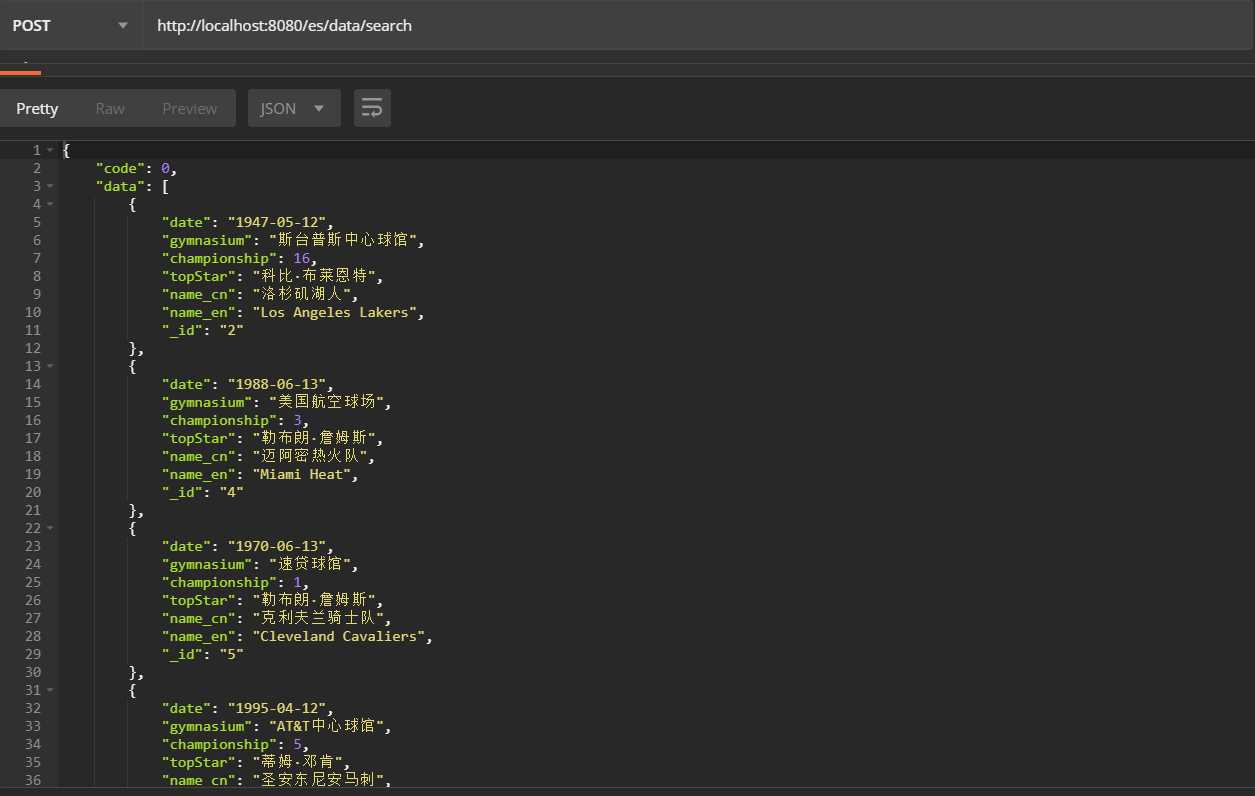
查询结果示例:
SQL 虽然不是 ES 官方推荐的查询语言,但是由于他的便捷性,ES 官方也开始意识到这块。ES 在 6.3.0版本后也开始支持 SQL了,但是他是通过引入 x-pack 的方式,如归我们可以通过 REST 方式使用,但是我们引入到开发中还是有点问题,需要铂金会员才行,不知道以后会不会放开。
另外,SQL 虽然使用起来比较方便,但是毕竟不是官方指定的,所以难免在功能上有缺陷,没有 DSL 功能强大,而且里面的坑比较多,但是基本的查询都支持。所以如果不是迫不得已,我还是建议使用 DSL,而一些简单的操作可以用SQL来辅助,本篇文章源码都已上传到本人的 Github ,如果感兴趣的读者可以关注我的 Github。
Elasticsearch通关教程(五):如何通过SQL查询Elasticsearch
标签:自己 extractor ace class 上下 sele not name bottom
原文地址:https://www.cnblogs.com/jajian/p/10053504.html