标签:step 限流 变化 主从 先来 暂停 做了 class 占用
原文:gh-ost: GitHub‘s online schema migration tool for MySQL
http://github.com/github/gh-ost
MySQL在线更改schema的工具很多,如Percona的pt-online-schema-change、 Facebook的 OSC 和 LHM 等,但这些都是基于触发器(Trigger)的,今天咱们介绍的 gh-ost 号称是不需要触发器(Triggerless)支持的在线更改表结构的工具。

本文先介绍一下当前业界已经存在的这些工具的使用场景和原理,然后再详细介绍
gh-ost的工作原理和特性。
今天我们开源了GitHub内部使用的一款 不需要触发器支持的 MySQL 在线更改表结构的工具 gh-ost
开发 gh-ost 是为了应付GitHub在生产环境中面临的持续的、不断变化的在线修改表结构的需求。gh-ost 通过提供低影响、可控、可审计和操作友好的解决方案改变了现有的在线迁移表工具的工作模式。
MySQL表迁移及结构更改操作是业界众所周知的问题,2009年以来已经可以通过在线(不停服务)变更的工具来解决。迅速增长,快速迭代的产品往往需要频繁的需改数据库的结构。增加/更改/删除/ 字段和索引等等,这些操作在MySQL中默认都会锁表,影响线上的服务。 向这种数据库结构层面的变更我们每天都会面临多次,当然这种操作不应该影响用户的正常服务。
在开始介绍 gh-ost 工具之前,咱们先来看一下当前现有的这些工具的解决方案。
如今,在线修改表结构可以通过下面的三种方式来完成:
在从库上修改表结构,操作会在其他的从库上生效,将结构变更了的从库设置为主库
使用 MySQL InnoDB 存储引擎提供的在线DDL特性
使用在线修改表结构的工具。现在最流行的是 pt-online-schema-change 和 Facebook 的 OSC;当然还有 LHM 和比较原始的 oak-online-alter-table 工具。
其他的还包括 Galera 集群的Schema滚动更新,以及一些其他的非InnoDB的存储引擎等待,在 GitHub 我们使用通用的 主-从 架构 和 InnoDB 存储引擎。
为什么我们决定开始一个新的解决方案,而不是使用上面的提到的这些呢?现有的每种解决方案都有其局限性,下文会对这些方式的普遍问题简单的说明一下,但会对基于触发器的在线变更工具的问题进行详细说明。
基于主从复制的迁移方式需要很多的前置工作,如:大量的主机,较长的传输时间,复杂的管理等等。变更操作需要在一个指定的从库上或者基于sub-tree的主从结构中执行。需要的情况也比较多,如:主机宕机、主机从早先的备份中恢复数据、新主机加入到集群等等,所有这些情况都有可能对我们的操作造成影响。最要命的是可能这些操作一天要进行很多次,如果使用这种方法我们操作人员每天的效率是非常高的(译者注:现如今很少有人用这种方式了吧)
MySQL针对Innodb存储引擎的在线DDL操作在开始之前都需要一个短时间排它锁(exclusive)来准备环境,所以alter命令发出后,会首先等待该表上的其它操作完成,在alter命令之后的请求会出现等待waiting meta data lock。同样在ddl结束之前,也要等待alter期间所有的事务完成,也会堵塞一小段时间,这对于繁忙的数据库服务来说危险系数是非常高的。另外DDL操作不能中断,如果中途kill掉,会造成长时间的事务回滚,还有可能造成元数据的损坏。它操作起来并不那么的Nice,不能限流和暂停,在大负载的环境中甚至会影响正常的业务。
我们用了很多年的 pt-online-schema-change 工具。然而随着我们不断增长的业务和流量,我们遇到了很多的问题,我们必须考虑在操作中的哪些 危险操作 (译者注:pt工具集的文档中经常会有一些危险提示)。某些操作必须避开高峰时段来进行,否则MySQL可能就挂了。所有现存的在线表结构修改的工具都是利用了MySQL的触发器来执行的,这种方式有一些潜藏的问题。
所有在线表结构修改工具的操作方式都类似:创建与原表结构一致的临时表,该临时表已经是按要求修改后的表结构了,缓慢增量的从原表中复制数据,同时记录原表的更改(所有的 INSERT, DELETE, UPDATE 操作) 并应用到临时表。当工具确认表数据已经同步完成,它会进行替换工作,将临时表更名为原表。
pt-online-schema-change, LHM 和 oak-online-alter-table 这些工具都使用同步的方式,当原表有变更操作时利用一些事务的间隙时间将这些变化同步到临时表。Facebook 的工具使用异步的方式将变更写入到changelog表中,然后重复的将changelog表的变更应用到临时表。所有的这些工具都使用触发器来识别原表的变更操作。
当表中的每一行数据有 INSERT, DELETE, UPDATE 操作时都会调用存储的触发器。一个触发器可能在一个事务空间中包含一系列查询操作。这样就会造成一个原子操作不单会在原表执行,还会调用相应的触发器执行多个操作。
在基于触发器迁移实践中,遇到了如下的问题:
触发器是以解释型代码的方式保存的。MySQL 不会预编译这些代码。 会在每次的事务空间中被调用,它们被添加到被操作的表的每个查询行为之前的分析和解释器中。
锁表:触发器在原始表查询中共享相同的事务空间,而这些查询在这张表中会有竞争锁,触发器在另外一张表会独占竞争锁。在这种极端情况下,同步方式的锁争夺直接关系到主库的并发写性能。以我们的经验来说,在生产环境中当竞争锁接近或者结束时,数据库可能会由于竞争锁而被阻塞住。触发锁的另一个方面是创建或销毁时所需要的元数据锁。我们曾经遇到过在繁忙的表中当表结构修改完成后,删除触发器可能需要数秒到分钟的时间。
不可信:当主库的负载上升时,我们希望降速或者暂停操作,但基于触发器的操作并不能这么做。虽然它可以暂停行复制操作,但却不能暂停出触发器,如果删除触发器可能会造成数据丢失,因此触发器需要在整个操作过程中都要存在。在我们比较繁忙的服务器中就遇到过由于触发器占用CPU资源而将主库拖死的例子。
并发迁移:我们或者其他的人可能比较关注多个同时修改表结构(不同的表)的场景。鉴于上述触发器的开销,我们没有兴趣同时对多个表进行在线修改操作,我们也不确定是否有人在生产环境中这样做过。
测试:我们修改表结构可能只是为了测试,或者评估其负载开销。基于触发器的表结构修改操作只能通过基于语句复制的方式来进行模拟实验,离真实的主库操作还有一定的距离,不能真实的反映实际情况。
gh-ost GitHub 的在线 Schema 修改工具,下面工作原理图:
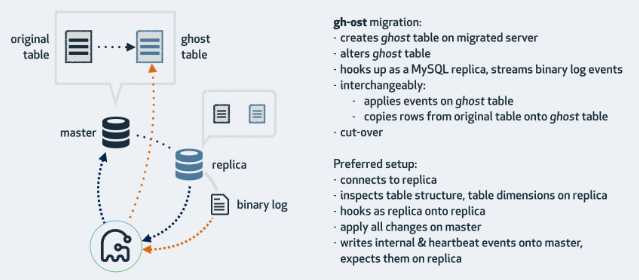
gh-ost 具有如下特性:
无触发器
轻量级
可暂停
可动态控制
可审计
可测试
值得信赖
gh-ost 没有使用触发器。它通过分析binlog日志的形式来监听表中的数据变更。因此它的工作模式是异步的,只有当原始表的更改被提交后才会将变更同步到临时表(ghost table)
gh-ost 要求binlog是RBR格式 ( 基于行的复制);然而也不是说你就不能在基于SBR(基于语句的复制)日志格式的主库上执行在线变更操作。实际上是可以的。gh-ost 可以将从库的 SBR日志转换为RBR日志,只需要重新配置就可以了。
由于没有使用触发器,因此在操作的过程中对主库的影响是最小的。当然在操作的过程中也不用担心并发和锁的问题。 变更操作都是以流的形式顺序的写到binlog文件中,gh-ost只是读取他们并应用到gh-ost表中。实际上,gh-ost 通过读取binlog的写事件来进行顺序的行复制操作。因此,主库只会有一个单独连接顺序的将数据写入到临时表(ghost table)。这和ETL操作有很大的不同。
所有的写操作都是由gh-ost控制的,并且以异步的方式读取binlog,当限速的时候,gh-ost可以暂停向主库写入数据,限速意味着不会在主库进行复制,也不会有行更新。当限速时gh-ost会创建一个内部的跟踪(tracking)表,以最小的系统开销向这个表中写入心跳事件
gh-ost 支持多种方式的限速:
负载: 为熟悉 pt-online-schema-change 工具的用户提供了类似的功能,可以设置MySQL中的状态阈值,如 Threads_running=30
复制延迟: gh-ost 内置了心跳机制,可以指定不同的从库,从而对主从的复制延迟时间进行监控,如果达到了设定的延迟阈值程序会自动进入限速模式。
查询: 用户可以可以设置一个限流SQL,比如 SELECT HOUR(NOW()) BETWEEN 8 and 17 这样就可以动态的设置限流时间。
标示文件: 可以通过创建一个标示文件来让程序限速,当删除文件后可以恢复正常操作。
用户命令: 可以动态的连接到 gh-ost (下文会提到) 通过网络连接的方式实现限速。
现在的工具,当执行操作的过程中发现负载上升了,DBA不得不终止操作,重新配置参数,如 chunk-size,然后重新执行操作命令,我们发现这种方式效率非常低。
gh-ost 可以通过 unix socket 文件或者TCP端口(可配置)的方式来监听请求,操作者可以在命令运行后更改相应的参数,参考下面的例子:
echo throttle | socat - /tmp/gh-ost.sock 打开限速,同样的,可以使用 no-throttle 来关闭限流。
改变执行参数: chunk-size=1500, max-lag-millis=2000, max-load=Thread_running=30 这些参数都可以在运行时变更。
同样的,使用上文提到的程序接口可以获取 gh-ost 的状态。gh-ost 可以报告当前的进度,主要参数的配置以及当前服务器的标示等等。这些信息都可以通过网络接口取到,相对于传统的tail日志的方式要灵活很多。
因为日志文件和主库负载关系不大,因此在从库上执行修改表结构的操作可以更真实的体现出这些操作锁产生的实际影响。(虽然不是十分理想,后续我们会做优化工作)。
gh-ost 內建支持测试功能,通过使用 --test-on-replica 的参数来指定: 它可以在从库上进行变更操作,在操作结束时gh-ost 将会停止复制,交换表,反向交换表,保留2个表并保持同步,停止复制。可以在空闲时候测试和比较两个表的数据情况。
这是我们在GitHub的生产环境中的测试:我们生产环境中有多个从库;部分从库并不是为用户提供服务的,而是用来对所有表运行的连续覆盖迁移测试。我们生产环境中的表,小的可能没有数据,大的会达到数百GB,我们只是做个标记,并不会正在的修改表结构(engine=innodb)。当每一个迁移结束后会停止复制,我们会对原表和临时表的数据进行完整的checksum确保他们的数据一致性。然后我们会恢复复制,再去操作下一张表。我们的生产环境的从库中已经通过 gh-ost 成功的操作了很多表。
上文提到说了这么多,都是为了提高大家对 gh-ost 的信任程度。毕竟在业界它还是一个新手,类似的工具已经存在了很多年了。
在第一次试手之前我们建议用户先在从库上测试,校验数据的一致性。我们已经在从库上成功的进行了数以千计的迁移操作。
如果在主库上使用 gh-ost 用户可以实时观察主库的负载情况,如果发现负载变化很大,可以通过上文提到的多种形式进行限速,直到负载恢复正常,然后再通过命令微调参数,这样可以动态的控制操作风险。
如果迁移操作开始后预完成计时间(ETA)显示要到夜里2点才能完成,结束时候需要切换表,你是不是要留下来盯着?你可以通过标记文件让gh-ost推迟切换操作。gh-ost 会完成行复制,但并不会切换表,它会持续的将原表的数据更新操作同步到临时表中。你第二天来到办公室,删除标记文件或者通过接口 echo unpostpone 告诉gh-ost开始切换表。我们不想让我们的软件把使用者绑住,它应该是为我们拜托束缚。
说到 ETA, --exact-rowcount 参数你可能会喜欢。相对于一条漫长的 SELECT COUNT(*) 语句,gh-ost 会预估出迁移操作所需要花费的时间,还会根据当前迁移的工作状况更新预估时间。虽然ETA的时间随时更改,但进度百分比的显示是准确的。
gh-ost 可以同时连接多个服务器,为了获取二进制的数据流,它会作为一个从库,将数据从一个库复制到另外一个。它有各种不同的操作模式,这取决于你的设置,配置,和要运行迁移环境。
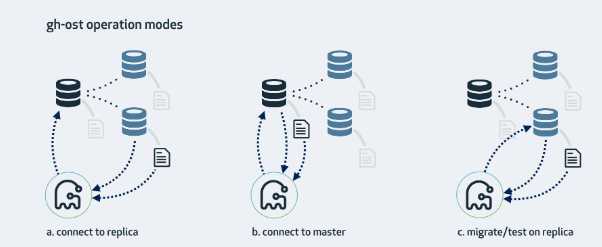
这是 gh-ost 默认的工作方式。gh-ost 将会检查从库状态,找到集群结构中的主库并连接,接下来进行迁移操作:
行数据在主库上读写
读取从库的二进制日志,将变更应用到主库
在从库收集表格式,字段&索引,行数等信息
在从库上读取内部的变更事件(如心跳事件)
在主库切换表
如果你的主库的日志格式是 SBR,工具也可以正常工作。但从库必须启用二级制日志(log_bin, log_slave_updates) 并且设置 binlog_format=ROW ( gh-ost 是读取从库的二级制文件)。
如果直接在主库上操作,当然也需要二进制日志格式是RBR。
如果你没有从库,或者不想使用从库,你可以直接在主库上操作。gh-ost 将会直接在主库上进行所有操作。你需要持续关注复制延迟问题。
你的主库的二进制日志必须是 RBR 格式。
在这个模式中你必须指定 --allow-on-master 参数
该模式会在从库执行迁移操作。gh-ost 会简单的连接到主库,此后所有的操作都在从库执行,不会对主库进行任何的改动。整个操作过程中,gh-ost 将控制速度保证从库可以及时的进行数据同步
--migrate-on-replica 表示 gh-ost 会直接在从库上进行迁移操作。即使在复制运行阶段也可以进行表的切换操作。
--test-on-replica 表示 迁移操作只是为了测试在切换之前复制会停止,然后会进行切换操作,然后在切换回来,你的原始表最终还是原始表。两个表都会保存下来,复制操作是停止的。你可以对这两个表进行一致性检查等测试操作。
我们已经在所有线上所有的数据库在线操作中使用了gh-ost ,我们每天都需要使用它,根据数据库修改需求,可能每天要运行多次。凭借其审计和控制功能我们已经将它集成到了ChatOps流程中。我们的工程师可以清醒的了解到迁移操作的进度,而且可以灵活的控制其行为。
虽然gh-ost在使用中很稳定,我们还在不断的完善和改进。我们将其开源也欢迎社会各界的朋友能够参与和贡献。随后我们会发布 贡献和建议的页面。
我们会积极的维护 gh-ost 项目,同时希望广大的用户可以尝试和测试这个工具,我们做了很大努力使之更值得信赖。
******************** ******************** ********************
作为一个DBA,大表的DDL的变更大部分都是使用Percona的pt-online-schema-change,本文说明下另一种工具gh-ost的使用:不依赖于触发器,是因为他是通过模拟从库,在row binlog中获取增量变更,再异步应用到ghost表的。在使用gh-ost之前,可以先看GitHub 开源的 MySQL 在线更改 Schema 工具【转】文章或则官网了解其特性和原理。本文只对使用进行说明。
1)下载安装:https://github.com/github/gh-ost/tags

Usage of gh-ost: --aliyun-rds:是否在阿里云数据库上执行。true --allow-master-master:是否允许gh-ost运行在双主复制架构中,一般与-assume-master-host参数一起使用 --allow-nullable-unique-key:允许gh-ost在数据迁移依赖的唯一键可以为NULL,默认为不允许为NULL的唯一键。如果数据迁移(migrate)依赖的唯一键允许NULL值,则可能造成数据不正确,请谨慎使用。 --allow-on-master:允许gh-ost直接运行在主库上。默认gh-ost连接的从库。 --alter string:DDL语句 --approve-renamed-columns ALTER:如果你修改一个列的名字,gh-ost将会识别到并且需要提供重命名列名的原因,默认情况下gh-ost是不继续执行的,除非提供-approve-renamed-columns ALTER。 --ask-pass:MySQL密码 --assume-master-host string:为gh-ost指定一个主库,格式为”ip:port”或者”hostname:port”。在这主主架构里比较有用,或则在gh-ost发现不到主的时候有用。 --assume-rbr:确认gh-ost连接的数据库实例的binlog_format=ROW的情况下,可以指定-assume-rbr,这样可以禁止从库上运行stop slave,start slave,执行gh-ost用户也不需要SUPER权限。 --check-flag --chunk-size int:在每次迭代中处理的行数量(允许范围:100-100000),默认值为1000。 --concurrent-rowcount:该参数如果为True(默认值),则进行row-copy之后,估算统计行数(使用explain select count(*)方式),并调整ETA时间,否则,gh-ost首先预估统计行数,然后开始row-copy。 --conf string:gh-ost的配置文件路径。 --critical-load string:一系列逗号分隔的status-name=values组成,当MySQL中status超过对应的values,gh-ost将会退出。-critical-load Threads_connected=20,Connections=1500,指的是当MySQL中的状态值Threads_connected>20,Connections>1500的时候,gh-ost将会由于该数据库严重负载而停止并退出。 Comma delimited status-name=threshold, same format as --max-load. When status exceeds threshold, app panics and quits --critical-load-hibernate-seconds int :负载达到critical-load时,gh-ost在指定的时间内进入休眠状态。 它不会读/写任何来自任何服务器的任何内容。 --critical-load-interval-millis int:当值为0时,当达到-critical-load,gh-ost立即退出。当值不为0时,当达到-critical-load,gh-ost会在-critical-load-interval-millis秒数后,再次进行检查,再次检查依旧达到-critical-load,gh-ost将会退出。 --cut-over string:选择cut-over类型:atomic/two-step,atomic(默认)类型的cut-over是github的算法,two-step采用的是facebook-OSC的算法。 --cut-over-exponential-backoff --cut-over-lock-timeout-seconds int:gh-ost在cut-over阶段最大的锁等待时间,当锁超时时,gh-ost的cut-over将重试。(默认值:3) --database string:数据库名称。 --debug:debug模式。 --default-retries int:各种操作在panick前重试次数。(默认为60) --discard-foreign-keys:该参数针对一个有外键的表,在gh-ost创建ghost表时,并不会为ghost表创建外键。该参数很适合用于删除外键,除此之外,请谨慎使用。 --dml-batch-size int:在单个事务中应用DML事件的批量大小(范围1-100)(默认值为10) --exact-rowcount:准确统计表行数(使用select count(*)的方式),得到更准确的预估时间。 --execute:实际执行alter&migrate表,默认为noop,不执行,仅仅做测试并退出,如果想要ALTER TABLE语句真正落实到数据库中去,需要明确指定-execute --exponential-backoff-max-interval int --force-named-cut-over:如果为true,则‘unpostpone | cut-over‘交互式命令必须命名迁移的表 --force-table-names string:在临时表上使用的表名前缀 --heartbeat-interval-millis int:gh-ost心跳频率值,默认为500 --help --hooks-hint string:任意消息通过GH_OST_HOOKS_HINT注入到钩子 --hooks-path string:hook文件存放目录(默认为empty,即禁用hook)。hook会在这个目录下寻找符合约定命名的hook文件来执行。 --host string :MySQL IP/hostname --initially-drop-ghost-table:gh-ost操作之前,检查并删除已经存在的ghost表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。 --initially-drop-old-table:gh-ost操作之前,检查并删除已经存在的旧表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。 --initially-drop-socket-file:gh-ost强制删除已经存在的socket文件。该参数不建议使用,可能会删除一个正在运行的gh-ost程序,导致DDL失败。 -> gh-ost执行时会创建socket文件,退出时不会删除,下次执行gh-ost时会报错,加上这个参数会删除老的socket文件,重新创建。 --master-password string :MySQL 主密码 --master-user string:MysQL主账号 --max-lag-millis int:主从复制最大延迟时间,当主从复制延迟时间超过该值后,gh-ost将采取节流(throttle)措施,默认值:1500s。 --max-load string:逗号分隔状态名称=阈值,如:‘Threads_running=100,Threads_connected=500‘. When status exceeds threshold, app throttles writes --migrate-on-replica:gh-ost的数据迁移(migrate)运行在从库上,而不是主库上。 --nice-ratio float:每次chunk时间段的休眠时间,范围[0.0…100.0]。0:每个chunk时间段不休眠,即一个chunk接着一个chunk执行;1:每row-copy 1毫秒,则另外休眠1毫秒;0.7:每row-copy 10毫秒,则另外休眠7毫秒。 --ok-to-drop-table:gh-ost操作结束后,删除旧表,默认状态是不删除旧表,会存在_tablename_del表。 --panic-flag-file string:当这个文件被创建,gh-ost将会立即退出。 --password string :MySQL密码 --port int :MySQL端口,最好用从库 --postpone-cut-over-flag-file string:当这个文件存在的时候,gh-ost的cut-over阶段将会被推迟,数据仍然在复制,直到该文件被删除。 --quiet:静默模式。 --replica-server-id uint : gh-ost的server_id --replication-lag-query string:弃用 --serve-socket-file string:gh-ost的socket文件绝对路径。 --serve-tcp-port int:gh-ost使用端口,默认为关闭端口。 --skip-foreign-key-checks:确定你的表上没有外键时,设置为‘true‘,并且希望跳过gh-ost验证的时间-skip-renamed-columns ALTER --skip-renamed-columns ALTER:如果你修改一个列的名字(如change column),gh-ost将会识别到并且需要提供重命名列名的原因,默认情况下gh-ost是不继续执行的。该参数告诉gh-ost跳该列的数据迁移,让gh-ost把重命名列作为无关紧要的列。该操作很危险,你会损失该列的所有值。 --stack:添加错误堆栈追踪。 --switch-to-rbr:让gh-ost自动将从库的binlog_format转换为ROW格式。 --table string:表名 --test-on-replica:在从库上测试gh-ost,包括在从库上数据迁移(migration),数据迁移完成后stop slave,原表和ghost表立刻交换而后立刻交换回来。继续保持stop slave,使你可以对比两张表。 --test-on-replica-skip-replica-stop:当-test-on-replica执行时,该参数表示该过程中不用stop slave。 --throttle-additional-flag-file string:当该文件被创建后,gh-ost操作立即停止。该参数可以用在多个gh-ost同时操作的时候,创建一个文件,让所有的gh-ost操作停止,或者删除这个文件,让所有的gh-ost操作恢复。 --throttle-control-replicas string:列出所有需要被检查主从复制延迟的从库。 -> 和--max-lag-millis参数相结合,这个参数指定主从延迟的数据库实例 --throttle-flag-file string:当该文件被创建后,gh-ost操作立即停止。该参数适合控制单个gh-ost操作。-throttle-additional-flag-file string适合控制多个gh-ost操作。 --throttle-http string --throttle-query string:节流查询。每秒钟执行一次。当返回值=0时不需要节流,当返回值>0时,需要执行节流操作。该查询会在数据迁移(migrated)服务器上操作,所以请确保该查询是轻量级的。 --timestamp-old-table:在旧表名中使用时间戳。 这会使旧表名称具有唯一且无冲突的交叉迁移 --tungsten:告诉gh-ost你正在运行的是一个tungsten-replication拓扑结构。 --user string :MYSQL用户 --verbose --version
3)使用说明:条件是操作的MySQL上需要的binlog模式是ROW。如果在一个从上测试也必须是ROW模式,还要开启log_slave_updates。根据上面的参数说明按照需求进行调整。
环境:主库:192.168.163.131;从库:192.168.163.130

① 检查有没有外键和触发器。 ② 检查表的主键信息。 ③ 检查是否主库或从库,是否开启log_slave_updates,以及binlog信息 ④ 检查gho和del结尾的临时表是否存在 ⑤ 创建ghc结尾的表,存数据迁移的信息,以及binlog信息等 ---以上校验阶段 ⑥ 初始化stream的连接,添加binlog的监听 ---以下迁移阶段 ⑥ 创建gho结尾的临时表,执行DDL在gho结尾的临时表上 ⑦ 开启事务,按照主键id把源表数据写入到gho结尾的表上,再提交,以及binlog apply。 ---以下cut-over阶段 ⑧ lock源表,rename 表:rename 源表 to 源_del表,gho表 to 源表。 ⑨ 清理ghc表。
1. 单实例上DDL: 单个实例相当于主库,需要开启--allow-on-master参数和ROW模式。
gh-ost --user="root" --password="root" --host=192.168.163.131 --database="test" --table="t1" --alter="ADD COLUMN cc2 varchar(10),add column cc3 int not null default 0 comment ‘test‘ " --allow-on-master --execute
2. 主从上DDL:
有2个选择,一是按照1直接在主上执行同步到从上,另一个连接到从库,在主库做迁移(只要保证从库的binlog为ROW即可,主库不需要保证):
gh-ost --user="root" --password="root" --host=192.168.163.130 --database="test" --table="t" --initially-drop-old-table --alter="ADD COLUMN y1 varchar(10),add column y2 int not null default 0 comment ‘test‘ " --execute
此时的操作大致是:
行数据在主库上读写
读取从库的二进制日志,将变更应用到主库
在从库收集表格式,字段&索引,行数等信息
在从库上读取内部的变更事件(如心跳事件)
在主库切换表
在执行DDL中,从库会执行一次stop/start slave,要是确定从的binlog是ROW的话可以添加参数:--assume-rbr。如果从库的binlog不是ROW,可以用参数--switch-to-rbr来转换成ROW,此时需要注意的是执行完毕之后,binlog模式不会被转换成原来的值。--assume-rbr和--switch-to-rbr参数不能一起使用。
3. 在从上进行DDL测试:
gh-ost --user="root" --password="root" --host=192.168.163.130 --database="test" --table="t" --alter="ADD COLUMN abc1 varchar(10),add column abc2 int not null default 0 comment ‘test‘ " --test-on-replica --switch-to-rbr --execute
参数--test-on-replica:在从库上测试gh-ost,包括在从库上数据迁移(migration),数据迁移完成后stop slave,原表和ghost表立刻交换而后立刻交换回来。继续保持stop slave,使你可以对比两张表。如果不想stop slave,则可以再添加参数:--test-on-replica-skip-replica-stop
上面三种是gh-ost操作模式,上面的操作中,到最后不会清理临时表,需要手动清理,再下次执行之前果然临时表还存在,则会执行失败,可以通过参数进行删除:
--initially-drop-ghost-table:gh-ost操作之前,检查并删除已经存在的ghost表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。 --initially-drop-old-table:gh-ost操作之前,检查并删除已经存在的旧表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。 --initially-drop-socket-file:gh-ost强制删除已经存在的socket文件。该参数不建议使用,可能会删除一个正在运行的gh-ost程序,导致DDL失败。 --ok-to-drop-table:gh-ost操作结束后,删除旧表,默认状态是不删除旧表,会存在_tablename_del表。
还有其他的一些参数,比如:--exact-rowcount、--max-lag-millis、--max-load等等,可以看上面的说明,具体大部分常用的参数命令如下:
gh-osc --user= --password= --host= --database= --table= --max-load=Threads_running=30, --chunk-size=1000 --serve-socket-file=/tmp/gh-ost.test.sock --exact-rowcount --allow-on-master/--test-on-replica --initially-drop-ghost-table/--initially-drop-old-table/--initially-drop-socket-file --max-lag-millis= --max-load=‘Threads_running=100,Threads_connected=500‘ --ok-to-drop-table
4)额外说明:终止、暂停、限速
gh-ost --user="root" --password="root" --host=192.168.163.131 --database="test" --table="t1" --alter="ADD COLUMN o2 varchar(10),add column o1 int not null default 0 comment ‘test‘ " --exact-rowcount --serve-socket-file=/tmp/gh-ost.t1.sock --panic-flag-file=/tmp/gh-ost.panic.t1.flag --postpone-cut-over-flag-file=/tmp/ghost.postpone.t1.flag --allow-on-master --execute
① 标示文件终止运行:--panic-flag-file
创建文件终止运行,例子中创建/tmp/gh-ost.panic.t1.flag文件,终止正在运行的gh-ost,临时文件清理需要手动进行。
② 表示文件禁止cut-over进行,即禁止表名切换,数据复制正常进行。--postpone-cut-over-flag-file
创建文件延迟cut-over进行,即推迟切换操作。例子中创建/tmp/ghost.postpone.t1.flag文件,gh-ost 会完成行复制,但并不会切换表,它会持续的将原表的数据更新操作同步到临时表中。
③ 使用socket监听请求,操作者可以在命令运行后更改相应的参数。--serve-socket-file,--serve-tcp-port(默认关闭)
创建socket文件进行监听,通过接口进行参数调整,当执行操作的过程中发现负载、延迟上升了,不得不终止操作,重新配置参数,如 chunk-size,然后重新执行操作命令,可以通过scoket接口进行动态调整。如:
暂停操作:
#暂停 echo throttle | socat - /tmp/gh-ost.test.t1.sock #恢复 echo no-throttle | socat - /tmp/gh-ost.test.t1.sock
修改限速参数:
echo chunk-size=100 | socat - /tmp/gh-ost.t1.sock echo max-lag-millis=200 | socat - /tmp/gh-ost.t1.sock echo max-load=Thread_running=3 | socat - /tmp/gh-ost.t1.sock
4)和pt-online-schema-change对比测试
1. 表没有写入并且参数为默认的情况下,二者DDL操作时间差不多,毕竟都是copy row操作。
2. 表有大量写入(sysbench)的情况下,因为pt-osc是多线程处理的,很快就能执行完成,而gh-ost是模拟“从”单线程应用的,极端的情况下,DDL操作非常困难的执行完毕。
结论:虽然gh-ost不需要触发器,对于主库的压力和性能影响也小很多,但是针对高并发的场景进行DDL效率还是比pt-osc低,所以还是需要在业务低峰的时候处理。相关的测试可以看gh-ost和pt-osc性能对比。
5)封装脚本:
环境:M:192.168.163.131(ROW),S:192.168.163.130/132
封装脚本:gh-ost.py
运行:
gh-ost 放弃了触发器,使用 binlog 来同步。gh-ost 作为一个伪装的备库,可以从主库/备库上拉取 binlog,过滤之后重新应用到主库上去,相当于主库上的增量操作通过 binlog 又应用回主库本身,不过是应用在幽灵表上。
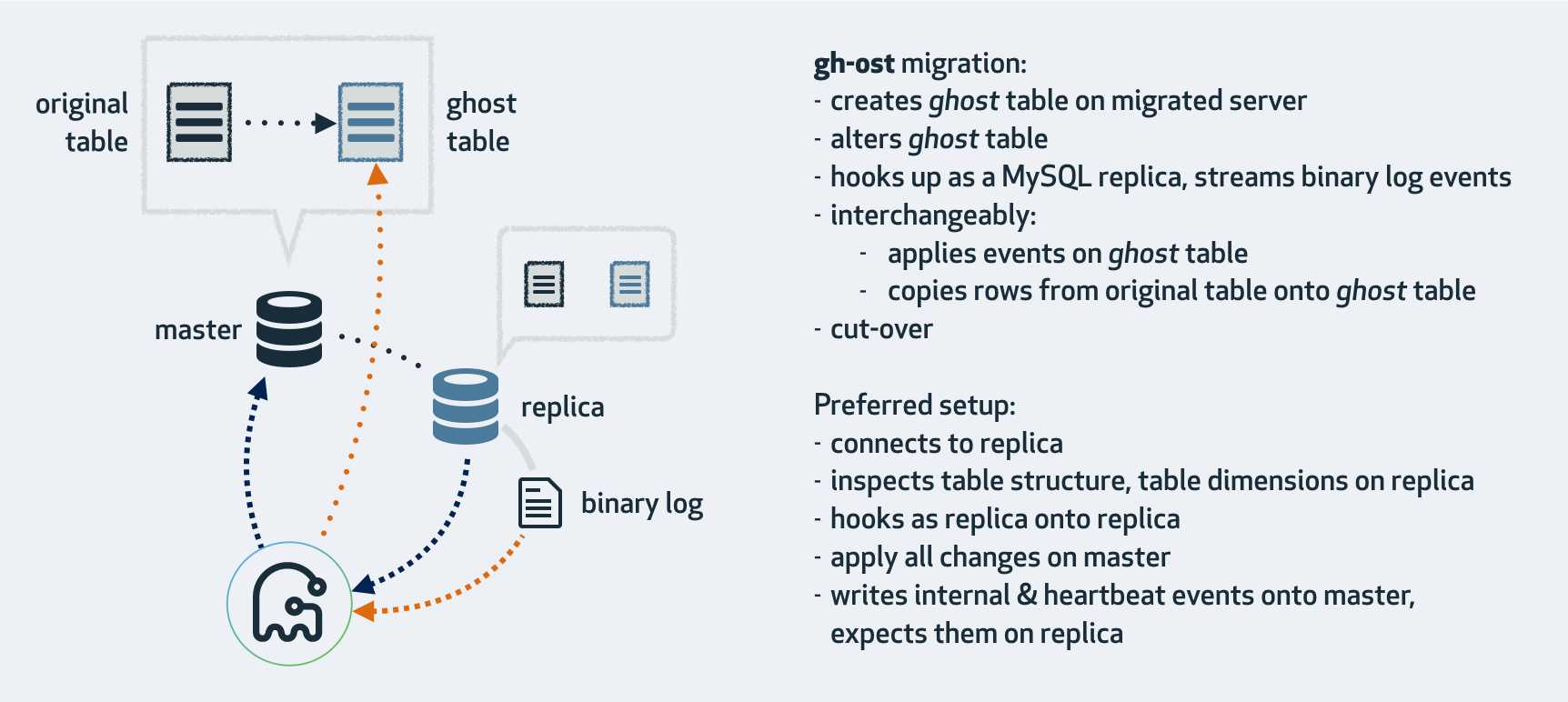
gh-ost 首先连接到主库上,根据 alter 语句创建幽灵表,然后作为一个”备库“连接到其中一个真正的备库上,一边在主库上拷贝已有的数据到幽灵表,一边从备库上拉取增量数据的 binlog,然后不断的把 binlog 应用回主库。图中 cut-over 是最后一步,锁住主库的源表,等待 binlog 应用完毕,然后替换 gh-ost 表为源表。gh-ost 在执行中,会在原本的 binlog event 里面增加以下 hint 和心跳包,用来控制整个流程的进度,检测状态等。这种架构带来诸多好处,例如:
https://github.com/github/gh-ost
GitHub 开源的 MySQL 在线更改 Schema 工具
Online DDL 工具 gh-ost 支持阿里云 RDS
GitHub开源MySQL Online DDL工具gh-ost参数解析
标签:step 限流 变化 主从 先来 暂停 做了 class 占用
原文地址:https://www.cnblogs.com/DataArt/p/10095685.html